










前言
今天!
当然这次先从最简单的一种微调手段开始学习,那就让我们废话少说开始今天的学习吧!

文本反演训练
文本反演这个东西第一反应听着会有些模式,但是换一个词:Embeddings这个就会熟悉很多。
Embeddings是在出图过程中经常使用到的东西,正如上篇笔记中提到的,这是一种轻量且小巧的微调模型格式。
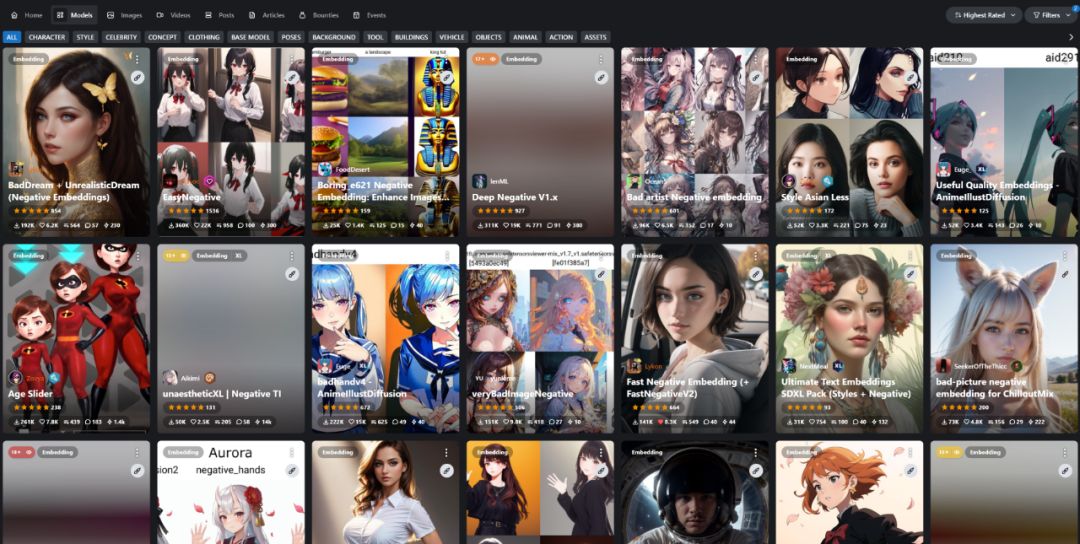
这类文件的后缀一般会有个.pt或者.safetensor
一个Embedding文件的大小大多数都在几KB到几百KB左右。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取
~
之所以一个Embedding文件这么小,还得看它翻译的意思-词嵌入。它会把额外训练集里的图片特征“浓缩”在一起,从而提取出额外的嵌入向量,并且在生成图片时加入到提示词生成的那些词向量里共同发挥作用。
在很早很早的笔记中提到过Embeddings像是书签一样,需要用到时就会跳转到那一页。
比起上百上千张图训练好几天的CheckPoint,Embedding只需要几张图和几个小时就能有不错的效果,并且可以用来塑造某一特定形象或者风格。
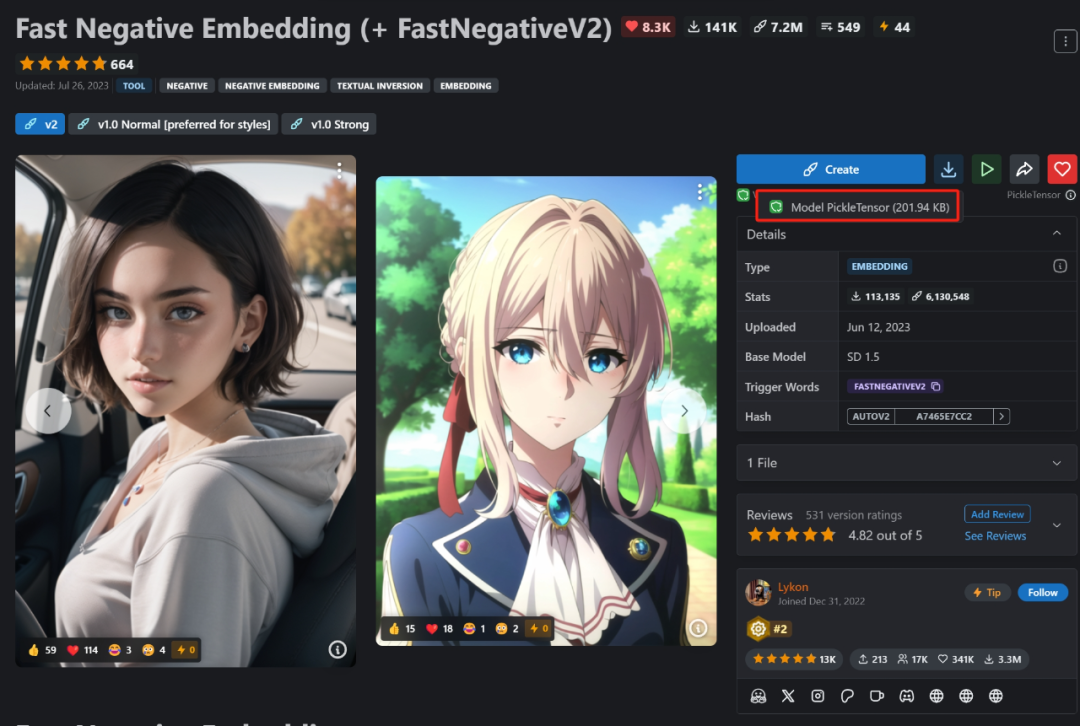
虽然效果不比后来的LoRA那么令人惊艳,但是现在Embeddings仍被用于提供负面词嵌入来优化生成质量或者是修复错手等的问题。

https://civitai.com/images/283901
Embeddings甚至还可以用来灵活调节年龄、性别、人物表情等画面构成的元素。
训练实践
说实话一开始我以为训练模型需要超级多复杂的工序准备、贼拉厉害的电脑配置等等,直到有一天我看见了个略有点眼熟的东西。


其实这个就是一个简单的模型训练功能,里面的功能可以让用户在WebUI里面轻松训练一个Embedding或者Hypernetwork。
其实Stable Diffusion本身的基地模型就很厉害,毕竟是已经经历过上亿次训练而成的结果。像是大部分生活常见的物品,或者是一些比较出门的电影ip、人物、动漫角色都能画出来。
如果有一个东西AI它从来没见过,那么它肯定画不出来,提示词能控制的东西其实是有限的。一些比较新或者冷门的角色物品如果恰好不在训练模型的数据集里,那么只通过提示词AI是画不出来的。
训练其实也不难,在WebUI里面训练一个Embedding其实只需要三步。
第一步:准备训练集
如果想要让AI认识某一个物体或者人的时候就需要喂给它对应的“图片”,炼制Embedding的时候只需要10-20张图片就够了。
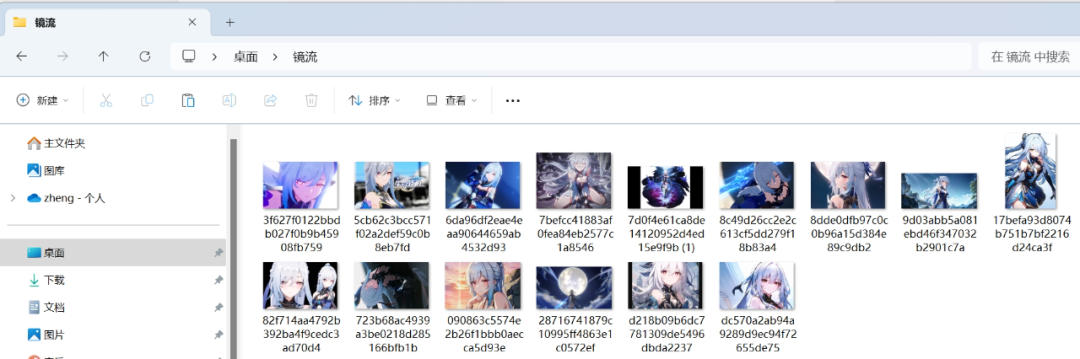
常见的图片格式jpg、png、ebp都可以,将其都装在一个文件夹中。
第二步:图片预处理
预处理的意义就是让训练集更符合模型训练本身的“规范”,而预处理需要做的一般有两件事情,分别是给图像做“裁剪”和“打标”。
裁剪很好理解,因为从网上下载下来的图片初始的图片大小都是不一致的。

所以需要将其缩放裁剪为512*512像素的正方形图片,而这个尺寸正是Stable Diffusion的图片生成默认尺寸,这个尺寸也是SD之前几十亿张图片训练的尺寸。
所以在使用SD微调模型的时候选择1:1的正方形比例并且把初始尺寸设置为512*512,这样呈现出来的画面内容才是最为“精准”的。
到这里,不要像我一样一开始楞不拉几去找各种缩放裁剪软件,这里WebUI有提供智能裁剪的功能!
**如果是旧版本的WebUI的话其图像预处理功能会在这里,不要用这里的功能先更新到最近的1.7.0版本!
**
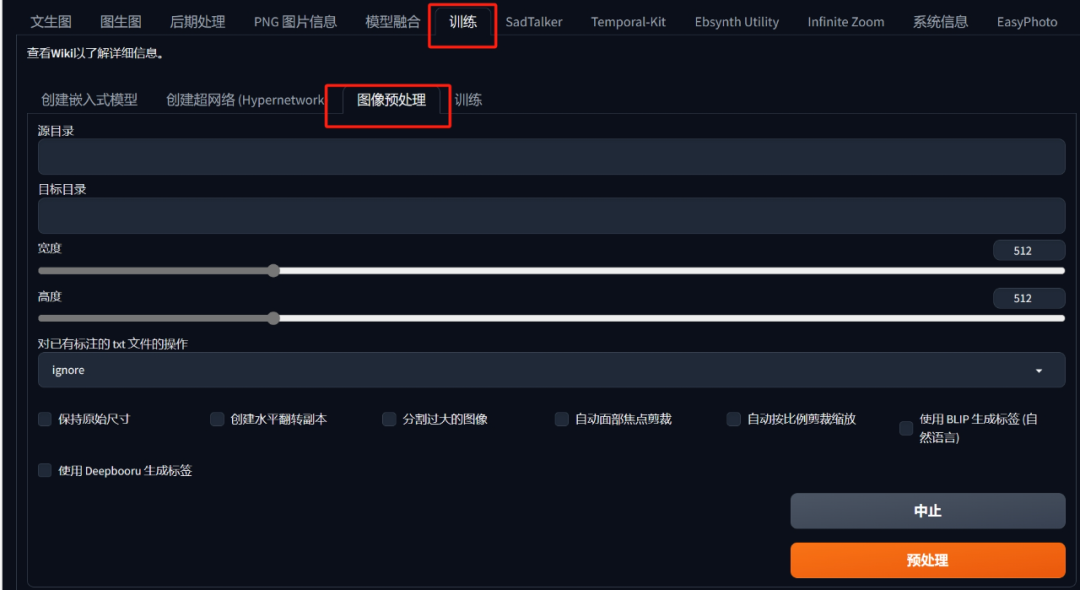
不要用这个↑
更新!更新!先更新到最新版本!
更新后的后期处理部分
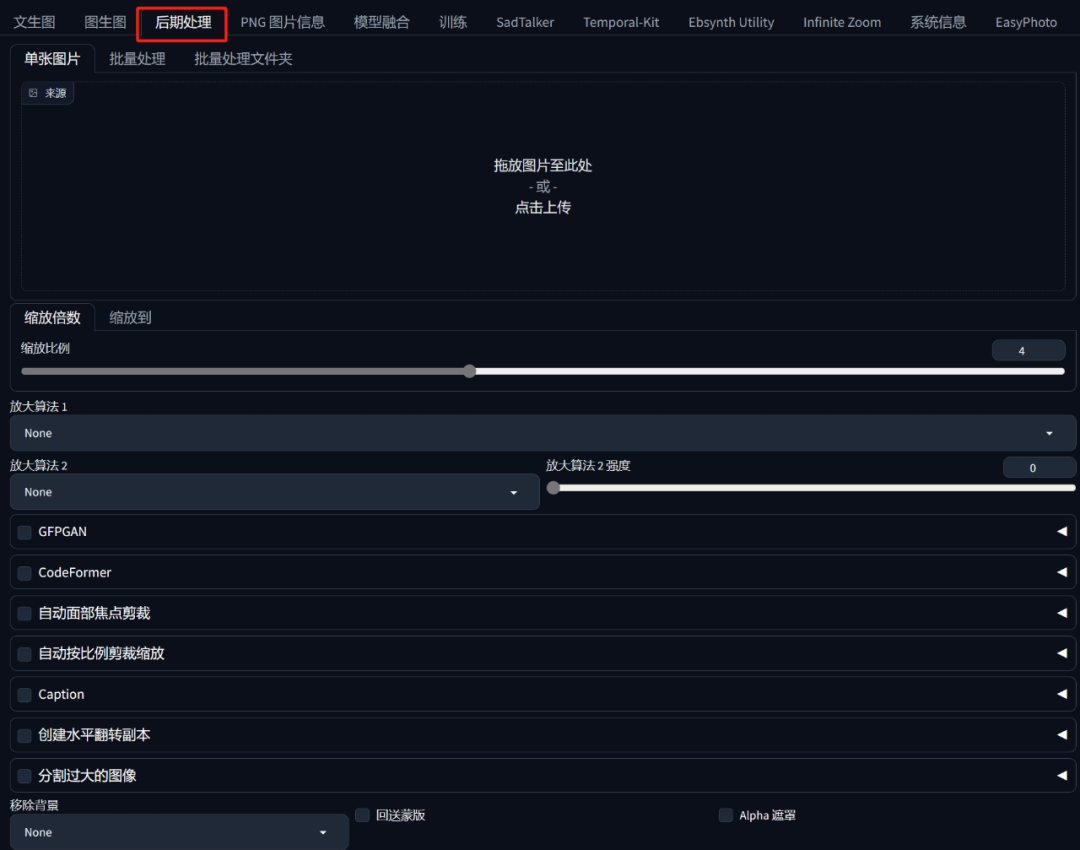
选择批量处理文件夹模式,然后在上面输入文件夹目录,下面输入要放置裁剪后的图片目录。
参数调整按照下图所示:
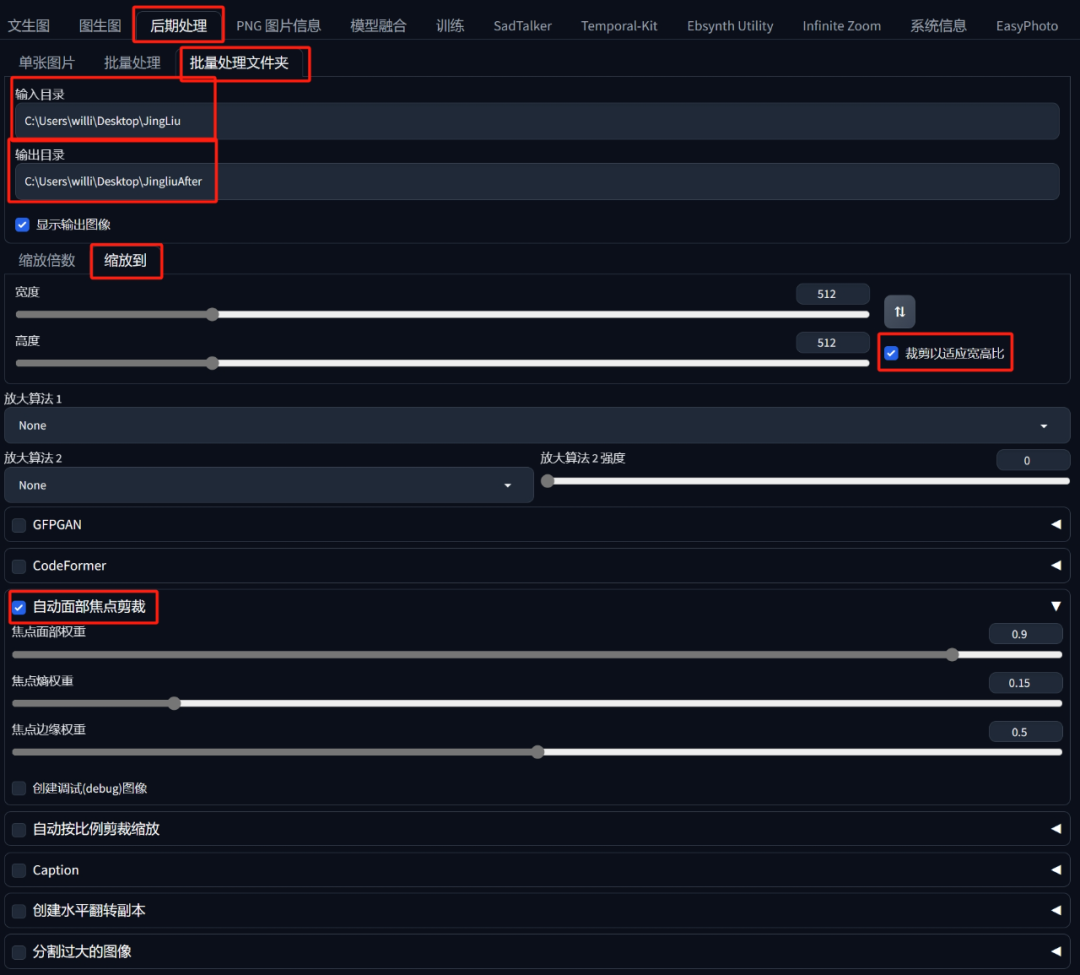
这里勾选自动面部焦点裁剪可以让AI更好识别图片中的人脸,并以人脸为中心规范裁切范围。
另一个要做的事情就是打标了,打标其实很好理解,就是给每个图片贴上一个标签,这样AI才可以学习里面的内容。
像这样的说明文字一般被称为训练里的标注Caption:
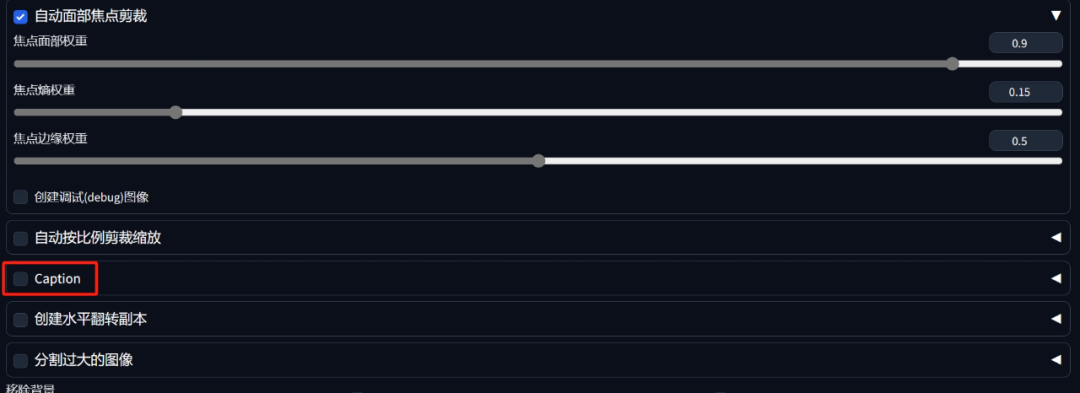
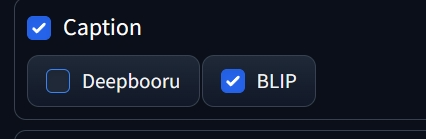
Caption点开一般分为两种,一种是BLIP一种是Deepbooru,如果选择的主体对象是偏二次元一些的则推荐选择Deepbooru。
BLIP和DeepBooru都是WebUI中搭载的两个自动标注工具,BLIP的全称是“统一视觉语言理解与生成的自引导语言-图像预训练”(Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation),可以高效识别图像内容并以自然语言给出对应描述。DeepBooru则是会以Danbooru词库中的“标签”对图像进行标注
之后点击生成就会发现目标文件夹中已经装好了裁剪好的文件:
注意!在这个过程中可能会遇到点小问题
有的同学可能会碰到这样的报错提示:
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.al
这是一个1.7.0版本的小BUG,有几率会碰到。解决方法有两个,要么等待启动器开发者秋葉大佬更新最新的版本(目前2024年1月9号最新的开发者版本也有着BUG),另一个方法就是在上方取消勾选自动面部焦点裁剪。
还有另一个问题:
AttributeError: ‘str’ object has no attribute ‘to’
这个问题我暂时没有搜索到合适的解决方案,最好的方法就是等新版本的启动器了。
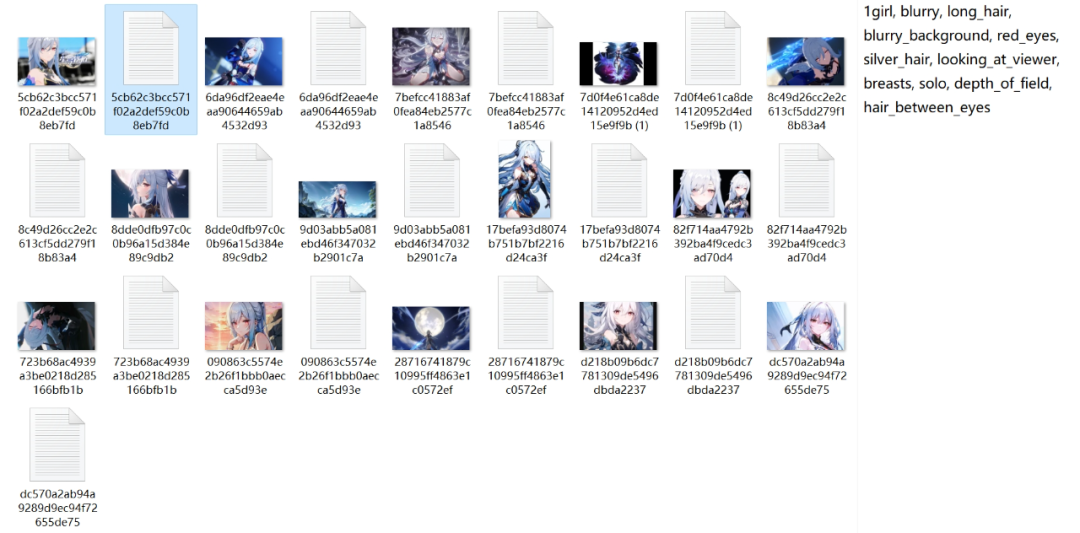
在裁剪好的图片右边有一个以.txt为尾缀的文档,里面放着的就是描述图片的“标注”。
第三步:调节训练参数
这最后一步就去到WebUI的训练界面:
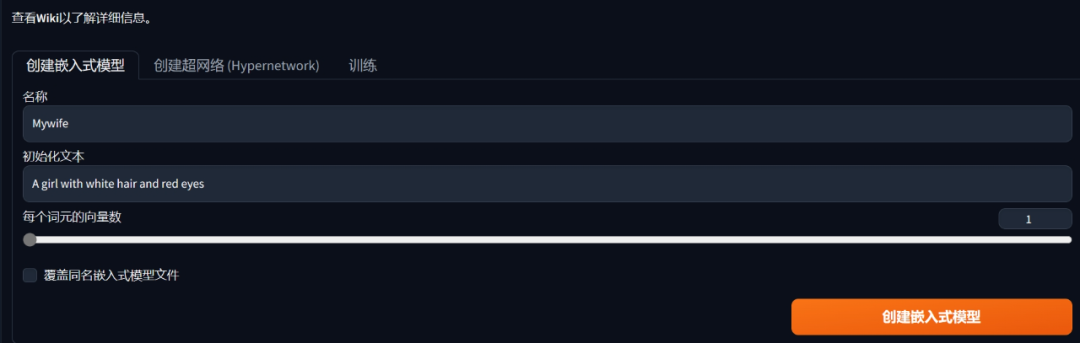
名称就起一个自己喜欢的名字,因为后续调用这个模型都是需要在提示词中输入这个名字。
初始化文本可以放着默认不管,其本质上就是用来描述训练主题的。
每个词元的向量数则需要结合文本编码器的作用来解释,即将这个初始化文字拆成最小的Token之后,每个Token对应的嵌入向量个数。向量个数越多,它最终能去描述的图像内容就越复杂。
不过这个可以放着默认1就行,如果对于产出结果不满意再进行调整,但是最多不要超过12。
点击创建嵌入式模型:
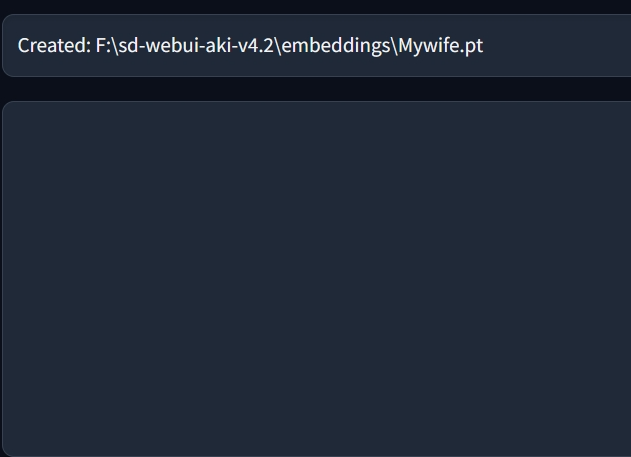
这个创建好的Embeddings文件会被放在WebUI根目录下的Embeddings文件夹内,和之前其他在网上下载的Embeddings放在一起。
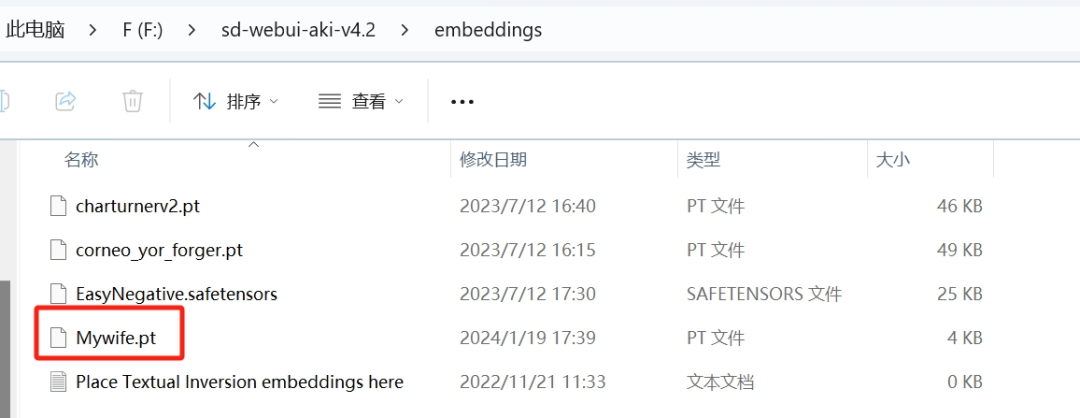
但是现在的模型里面是空的,不包含任何数据。
而开启训练的地方,在这里↓
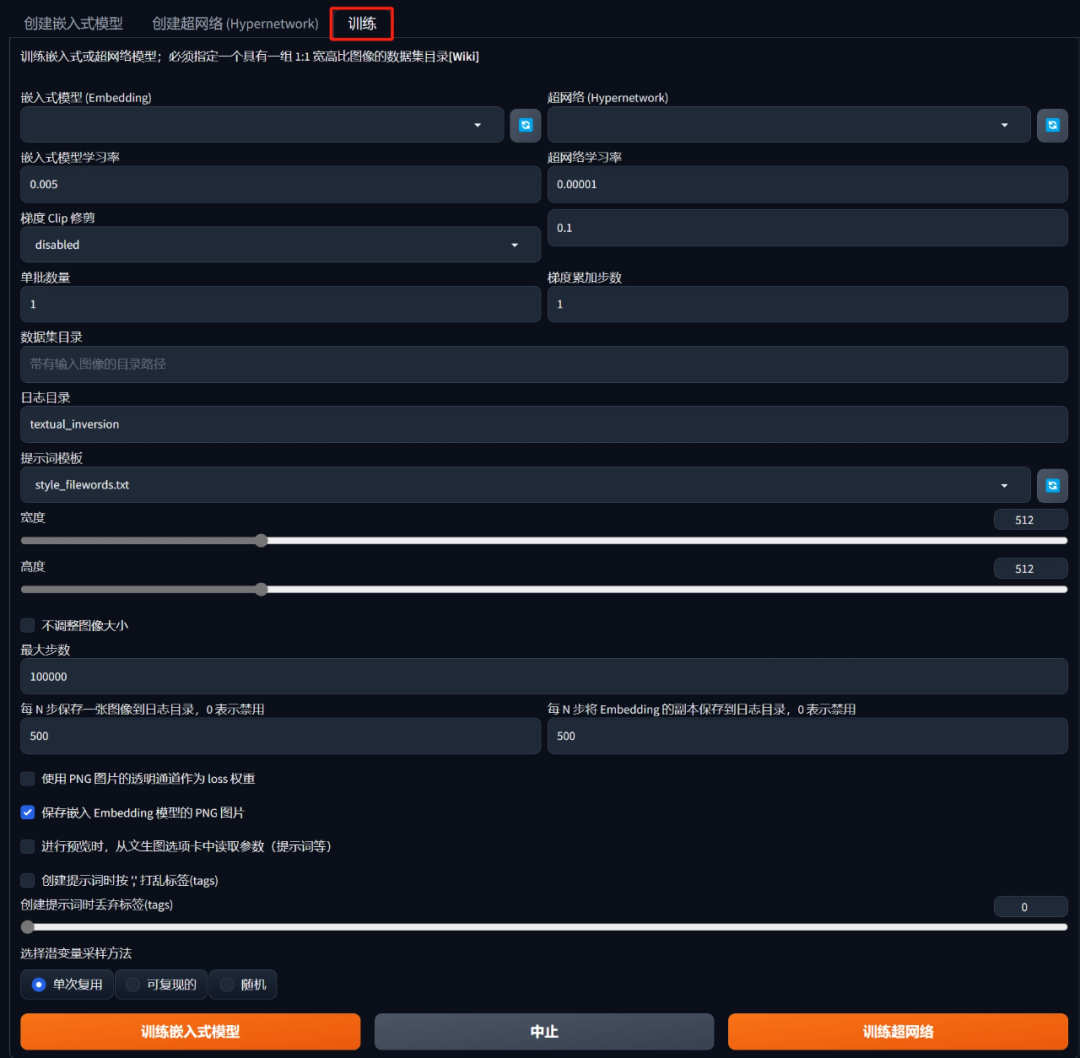
这里的参数很多,但是只需要一小部分进行调整即可。
首先是最上方的嵌入式模型,这里面选择刚刚创建好的Embeddings(没有的话点击右侧的刷新按钮)

然后在下方的数据集目录中填入刚刚预处理的输出文件夹,就是图片右侧有.txt文件的那个文件夹。
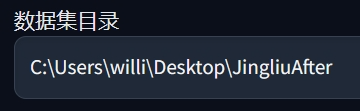
下面还有一个提示词模板,这个东西的作用是向AI输入标注信息时与创作者提供的标注文本随机结合。

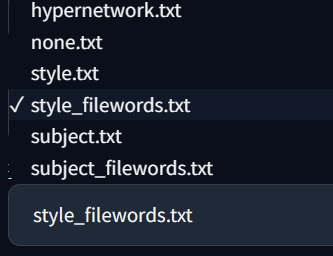
“Subject”一般用于训练对象(人物)、“style”用于训练风格。所以在这里选择Subject即可,其他选项默认不变。
提示词模板存储的位置在WebUI根目录下的"textual_inversion_templates" 文件夹内,在这里可以找到所有模板并预览,修改模板内容或按照类似的格式添加新的模板。

最后一个重要的东西就是训练的底模,由于是在WebUI上进行训练的,所以训练的底模会默认设置成左上角用来出图的这个CheckPoint。
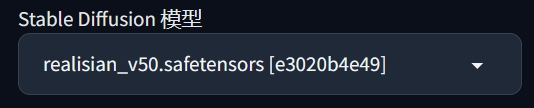
选择底模的原则是尽可能使用最原始的预处理模型来进行微调,这样可以最大程度保证学习效果与模型的泛用性。
之后点击最下方的训练嵌入模型,然后就会进入到一个相对漫长的等待。
AI的训练逻辑
恰好我等着也是等着,就来简单学习一下AI的训练逻辑。
AI会利用创作者输入的描述成分(标注)来生成图像,并将它们与训练数据集中的图像进行比较,通过生成的差异程度引导AI不断微调嵌入向量。
这样就可以让AI的生成结果越来越接近于训练图像的副本,最终让微调模型能够指向一个完全等同于训练图片的效果。
例如我先让AI根据标注信息生成一个叫做“Mywife”的人,但是AI一开始是不知道Mywife是啥,所以就生成了个和Mywife完全没关系的人出来。

这个时候我就不开心了,镜流那么漂亮怎么给了我这么个歪瓜裂枣。那我就会给AI一个大逼斗并且拿训练集里的图片给AI看,指出哪里修改一下可以更像Mywife,让它照着改。

这个过程重复多次后AI就会在“Mywife”这个词组和我们展示的图片之间建立起关联,并且画得越来越像。
在训练过程会需要较长时间,总时长取决于设备条件。
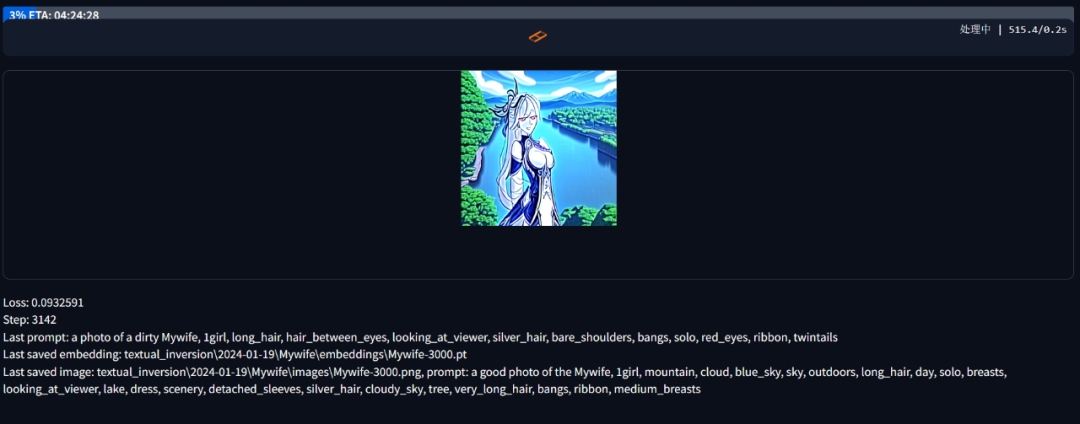
页面右侧会显示大概总时长,训练步数以及一张预览图来让创作者们可以看到AI在这一步根据标注画出来的结果。
按照初始设置,训练步数到10万步的时候会自然停止,当然一般也不需要这么久,大约1-2万步觉得画得差不多像了就可以了。
只需要点击标签页面最下方的中止,系统就会把到目前为止的训练结果保存到Embeddings中。
至于怎么使用,那就是在输入提示词后添加进“Mywife”(训练Embeddings的名称)就好啦。
这样一个完整的模型训练流程就结束啦!
今天的内容还是稍微有点多的,毕竟是一个完整的流程包括可能出现的问题都得写进去。
之后好几天我可能都没法更新文章,如果感兴趣后续课程的小伙伴可以关注B站UP主:Nenly同学,毕竟我是从它那学习的。
我是接下来好几天都没有电脑可以用,所以可能要小鸽一阵子,好抱歉我前一篇文章那么多人看我就得当鸽了。
那么大伙下篇笔记见吧!拜了个拜!

这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









