








在我们的日常设计工作中,设计师会经常接到3D的设计需求,根据以往的工作模式来看,我们需要在3D软件里面进行建模,渲染再进行输出。这样复杂的工作,会让工作时间变长,影响我们的工作效率。结合如今的AI工具,我们采用AIGC的能力,也许会有不同的解决方案,减少总设计时长。本文通过探索stable diffusion模型训练,浅谈一下lora训练的步骤,欢迎大家一起交流。

LoRA的全称是LoRA: Low-Rank Adaptation of Large Language Models,可以理解为stable diffusion(SD)模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。LoRA最初应用于领域,用于微调GPT-3等模型(也就是ChatGPT的前生)。由于GPT参数量超过千亿,训练成本太高,因此LoRA采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。用数据公式表达如下,其中 W0 是初始SD模型的参数(Weights), BA 为低秩矩阵也就是LoRA模型的参数, W 代表被LORA模型影响后的最终SD模型参数。整个过程是一个简单的线性关系,可以认为是原SD模型叠加LORA模型后,得到一个全新效果的模型。
你看到这里,可能会觉得有些晕,下面将直观的图例进行示意!

以上这些风格相同,特点一致的图片都是通过lora训练后产出的。同学们,看到这里,你是不是觉得很神奇呢?下面我将通过简单的人物IP训练,带大家简单了解lora的训练模式!

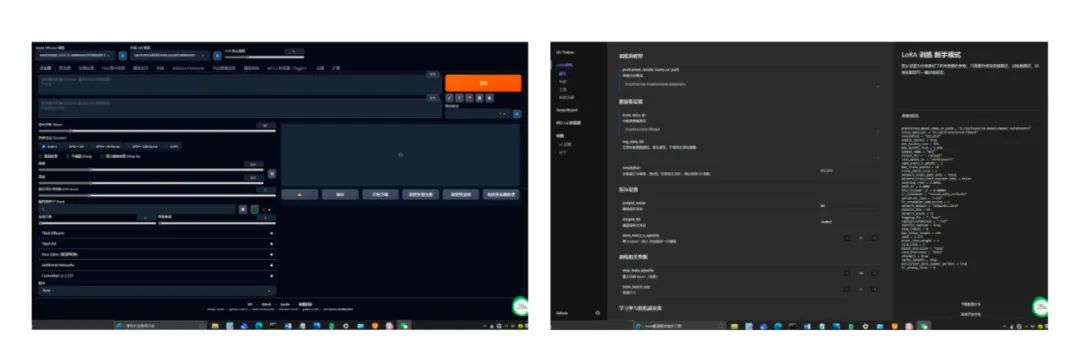
插件准备:stable diffusion
lora模型训练器
这里的安装推荐使用秋叶大佬的安装包,省心简单~ 安装文件内置python,解压打开即可使用,同样还享受大佬的后续更新。
训练素材准备:
最近比较喜欢可可爱的IP,所以我先从网上找到了一些我比较心仪的ip形象。他们都有一个共同点就是构图相同,角度一致,风格统一,有很高的识别度!千万注意的是不要混其他类型的图片素材进去,例如像大透视、仰视这种角度的。否则会影响我们后续的生图,污染设计产出!我们将这样的素材准备5-10张!
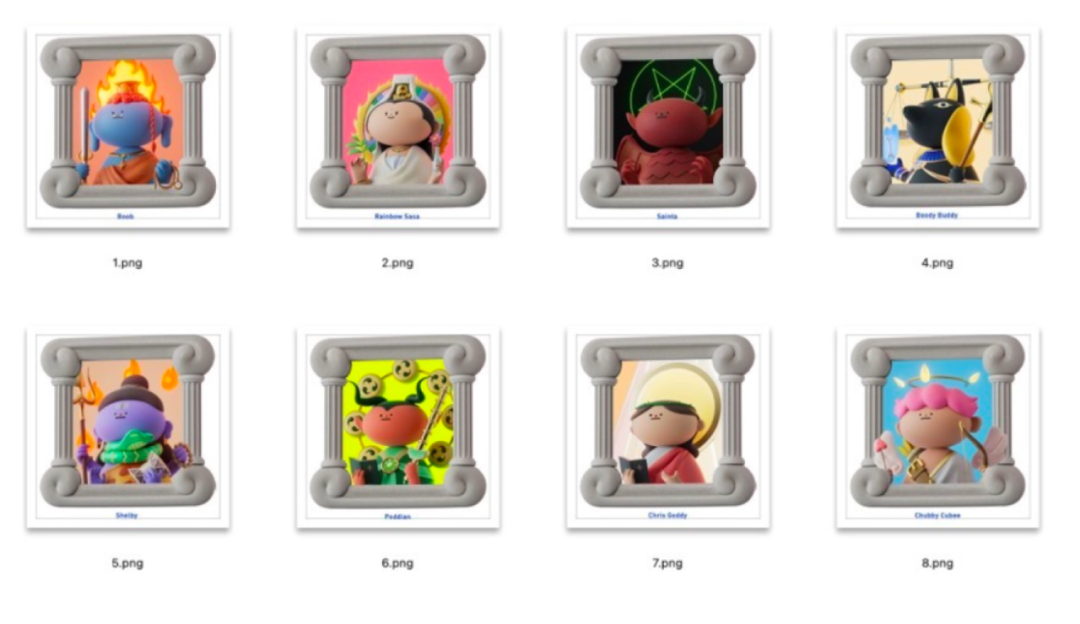
图片素材来源于网络
标签操作:
想要完成比较好的训练效果的话,我们需要严格按照以下步骤操作,否则是不会产出训练标签的哦~
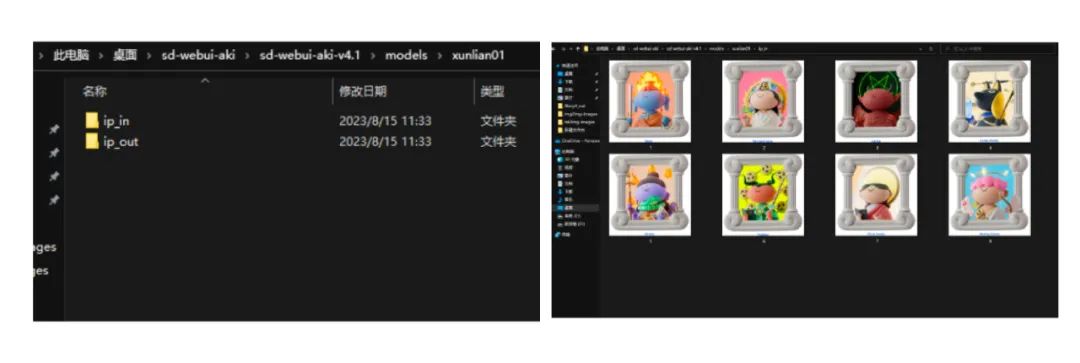
命名规则+训练分组
我们需要在SD中的models文件中建立train的文件,在文件中建立2个分组,分组规则如下。我们把训练素材放到ip-in文件里。
尺寸设置
我们每一张图设置为512x512即可,像素超过512会影响打标加载进度,像素小于512会导致图片质量下降
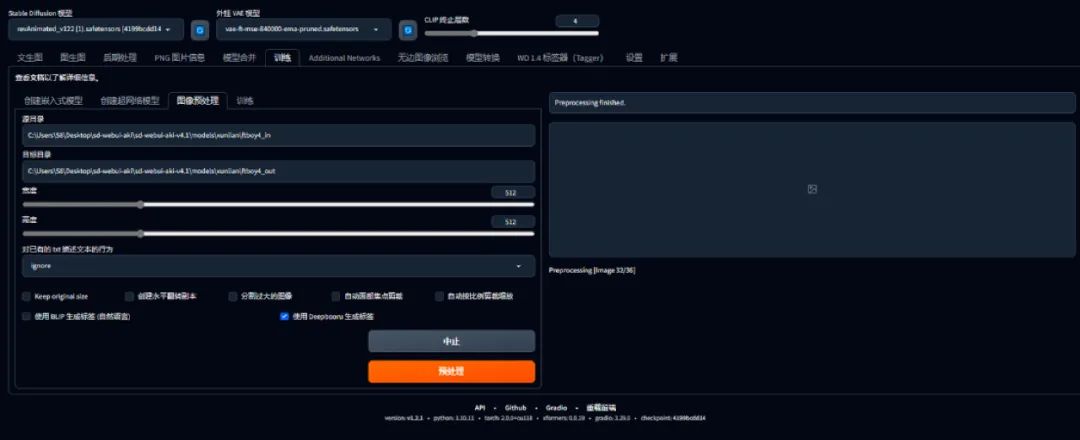
生成注意事项
在WEB UI界面点击训练—图像预处理-点击预处理。生成标签时,我们需要点选的是deepbooru按钮。
训练过程
复制训练集放置lora模型训练器,分别设置输出路径和输入路径。
结果展示
将我们训练好的lora放置到SD-models文件里面,点击刷新,放置于关键词的填写框中。然后我们输入一些想生成的关键词,进行生成。神奇的效果就有啦~例如,这里我写的是生成佛像/女巫/等有趣形象。电脑生成的效果还是蛮有意思的,同时也保存了训练的特点。
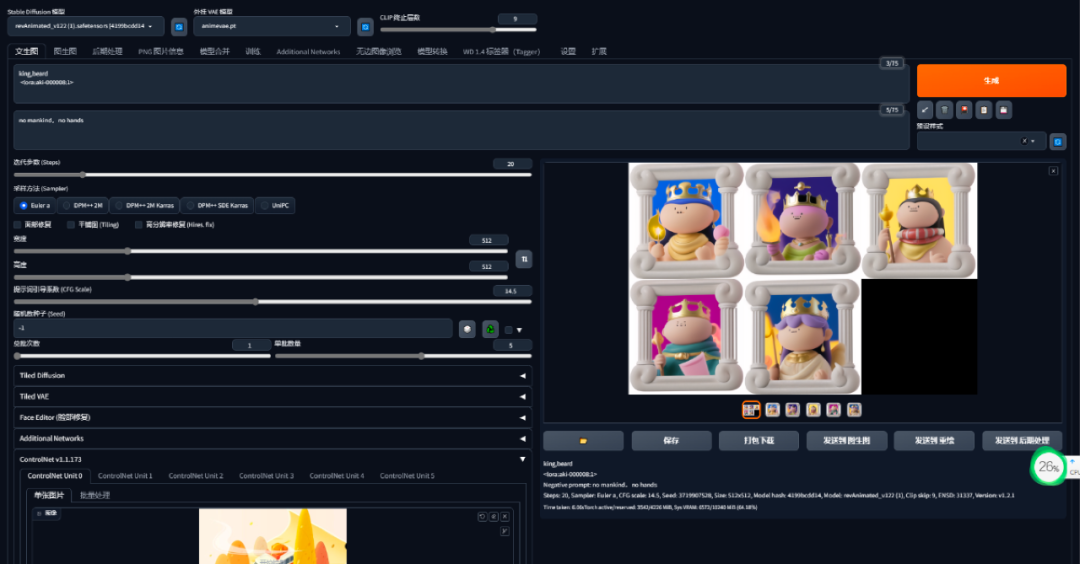
生成画面如下:

通过训练模型,可以生成不同类型的人物,也可以跨界生成一些小动物的样式,例如小猪、小猫等,整体还是蛮可爱的!

改变颜色
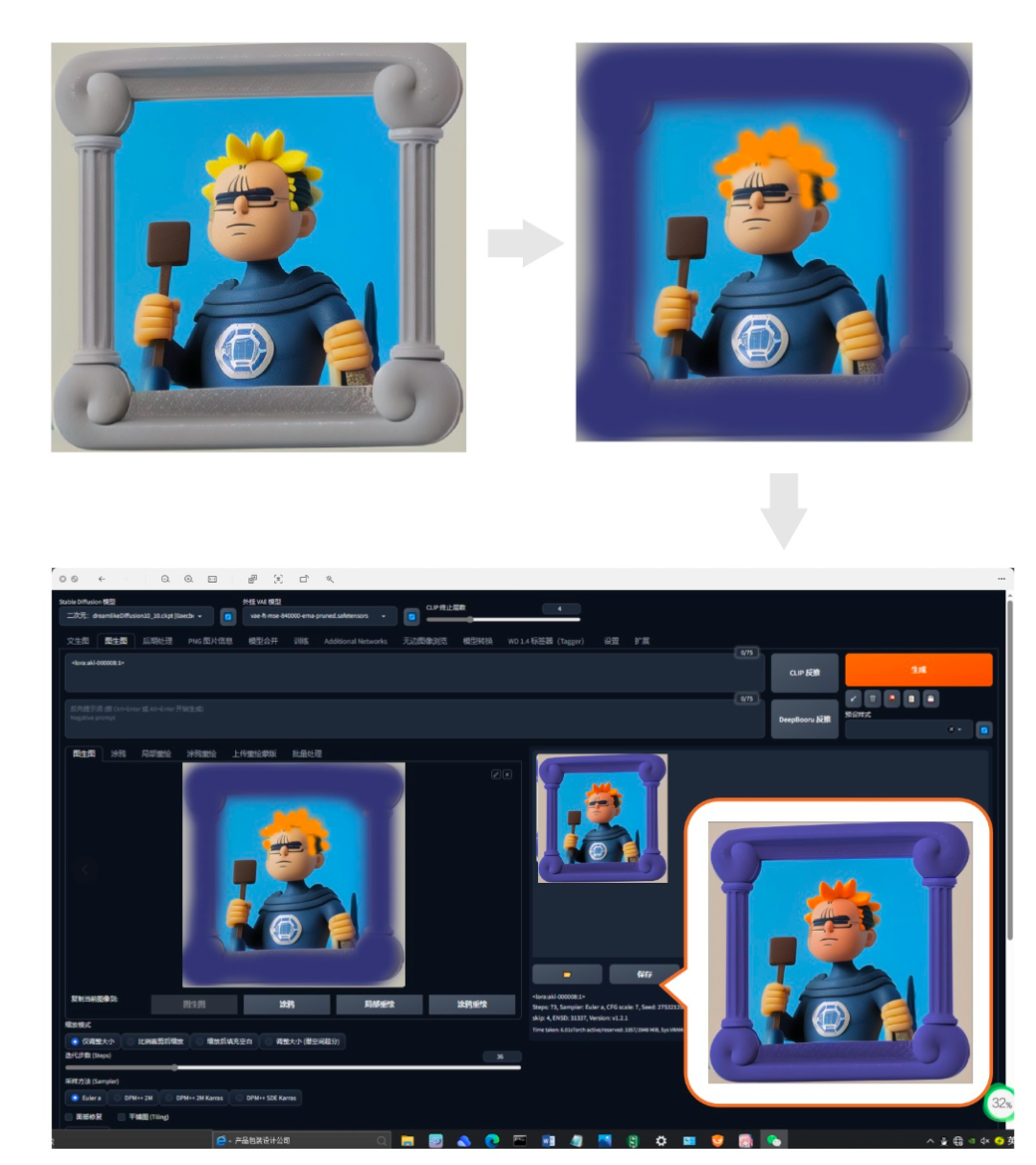
看到这里,也许小伙伴们又有一些疑问啦,生成的图片我想改变颜色怎么办呢?我希望外框变成蓝色,人物衣服变成红色。我们需要将生成的图放到PS里面,进行色彩调整。
我们需要把调整好的色彩图放置于图生图中,调整引导范围,我们就会得出以下换色后的图。整体来说可控性还够好的。

我们现在基本知道训练模型的流程了,那我们可以利用模型训练还可以做哪些事呢?我们在设计中会使用大量3D化的icon,我想如果用模型训练,让我可以大批量生产3D-icon该多好。因此,我用到家App的3D icon作为训练图集,力求训练出风格统一、透视一致、且有辨识度的3D-Icon。
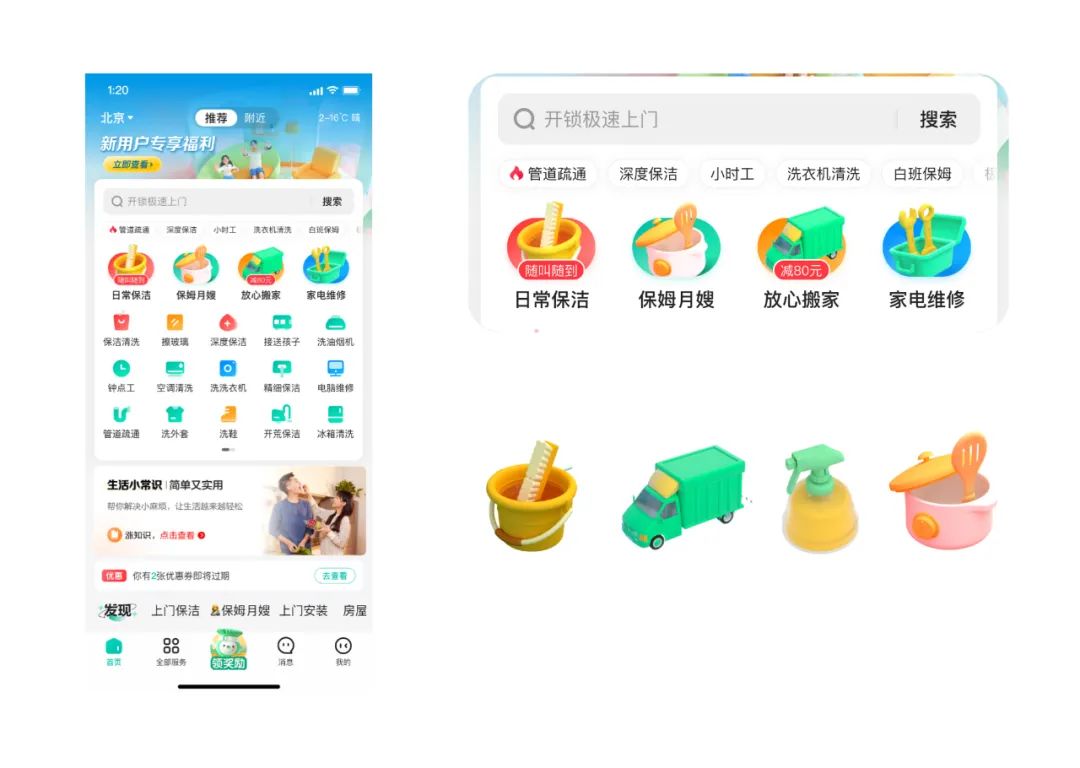
训练过程就不再重复展现了。我们把训练好的lora放置于sd中。此时我觉得之前的搬家的ICON美观度比较低,我希望能够根据训练的模型重新产出风格一致的搬家ICON。让我们试试效果吧~首先,我从网上随便找到了一个简单的平面草图;之后放置于SD的图生图中;输入关键词car,点击生成。效果如下,整体来看生成的风格和之前的3个icon保持一致,细节丰富。


总结:
随着AIGC的高速发展,想做出差异化的设计,模型训练也显得尤为重要。现在模型训练处于探索期,整体流程相对比较复杂,需要搜索大量的资料,本文仅仅是训练流程中的冰山一角,期待和大家有更深层的交流哦~
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!


篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!
















 1640
1640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









