










最近研究ComfyUI的过程中,一直困惑我的点就是:
为什么大语言模型不能更好赋能ComfyUI呢?
大语言模型(LLMs)和文生图模型(SD)两者结合起来一定能发挥更大的价值,于是,我开始寻找网上的教程和资料。终于发现了一套还算比较完美的解决方案;这套方案既可以用API的方式直接调用模型,也可以通过本地部署的方式直接将LLMs模型部署到你本地,然后通过接入到本地ComfyUI中实现调用;
**这样我就相当于在ComfyUI中拥有了一个智能助手,它可以帮你识图,写Prompt,翻译,反推工作流……一系列的工作,真的是事半功倍啊;
**

今天我们重点介绍一下第一种方式:通过API的方式接入进ComfyUI中,实现大语言模型和ComfyUI的结合;
01
效果演示
1)识图能力
以前构建工作流的时候,对于新手比较不友好的地方在于,如果我想要一种照片的风格,或者一种照片的服饰;怎么才能快速的将这张照片应用到我要生成的图像上呢,传统方法必须得通过复杂的控制模型,识图模型,整体串联到一起才能实现效果;但有了大语言模型后,我们只需要反推一下就可以搞定;
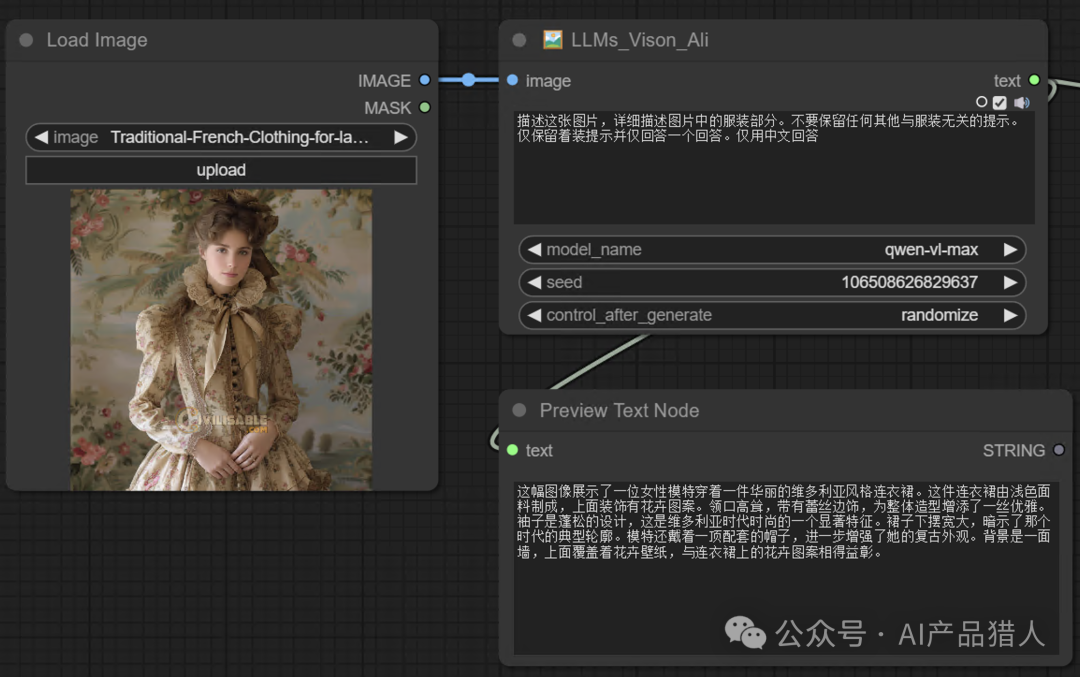
这里我让LLMs扮演的是一个识图的AI提示词助手,让它帮我总结这套衣服的特点,并提炼出关键的提示词;剩下的我只需要将生成的关键词喂给生图的流程就可以了;是不是很简单。
同理,照片风格,姿态,服饰,表情……一系列都可以这么应用;
当然,出来的效果肯定跟通过Contronet或者iPAdater效果有一定的差异,但在大部分精度要求没那么高的场景,这已经足够简单好用了;
2)总结助手,提示词增强助手
写提示词(prompt)相信也是大部分玩家头痛的地方,如何能写出一个符合预期的提示词,往往很费心思,有了这个LLMs助手之后,它可以帮你从一个简单的提示词,逐步的往你理想的提示词上去过渡;
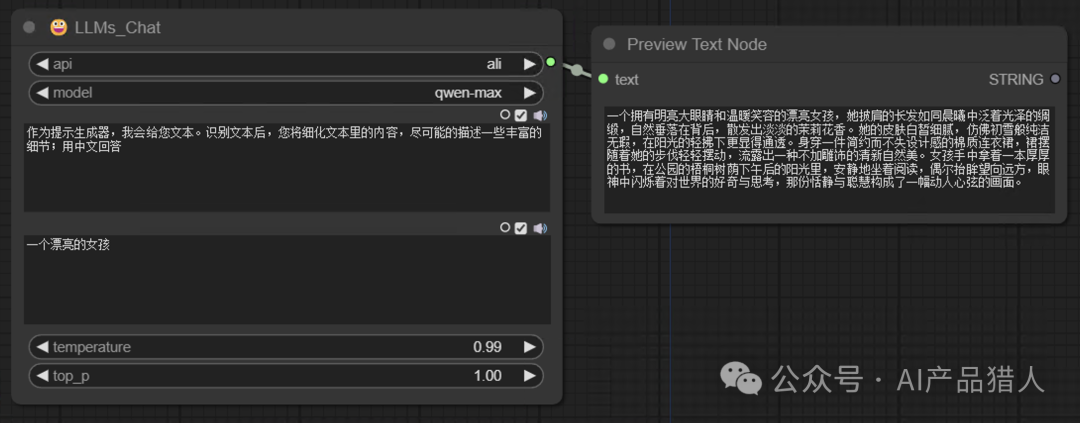
这里我只写了“一个漂亮的女孩”,让它帮我完善出一个完整的提示词,它给出的答案非常细致,剩下的就是我们删改一下,就可以直接输出给生图流程的Clip节点了;
当然,这里你也可以直接用中文写Prompt,然后让LLMs帮你翻译成英文直接输入给生图流程,具体使用方法都很简单;
3)翻译预览
如同第2)步讲的内容,当我们拿到一批以英文为主的prompt的时候,通过翻译软件去翻译,再修改往往折腾又麻烦,这里我同样可以通过LLMS帮我直接做好中英文对照翻译,等我调整好了,再输出给下一步节点即可;
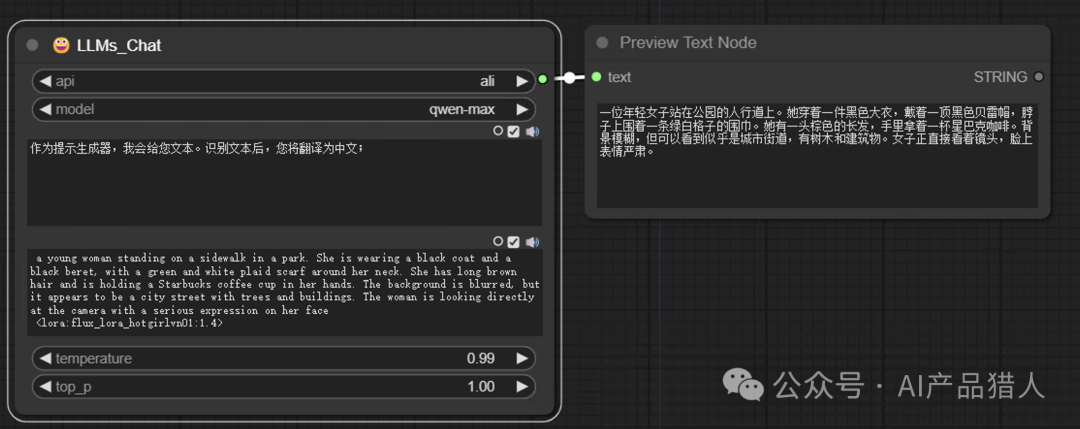
当然,这里还可以衍生出更多的玩法,时间有限,仅以几个我自己最常用的案例做分享;其他也希望大家努力去发掘后分享出来;
02
如何安装
1)安装LLMS的ComfyUI插件
这里推荐安装的是ComfyUI-LLMs这个节点;他提供了四种大语言模型,包含ChatGPT,通义千问,智谱AI,Gemini。在国内也比较好用,算是比较全面了;
GitHub地址:https://github.com/leoleelxh/ComfyUI-LLMs
安装几种方式都可以:
一是通过Manager直接搜索“ComfyUI-LLMs”,然后直接安装就可以,因为里面的节点数比较少,安装起来还是非常快的;

二是直接找到ComfyUI下的custom_nodes文件夹,cmd运行后,通过Git clone的方式直接将上面的地址复制到这个文件夹下;
三也可以直接下载上面地址的ZIP包,解压到custom_nodes这个文件夹里就可以;
2)申请大语言模型的API-key
因为我们使用的是通过调用API的方式来实现大语言模型的接入;这里就需要准备你所要使用的大语言模型的api了;
这里提供几个大模型申请API的地址,大家根据需要自行申请即可。
ChatGPT:(这里我用的是代理)
https://openai-hk.com/v3/ai/key
阿里通义千问:
https://bailian.console.aliyun.com/?accounttraceid=0422731a2107421699bd5f7cb030ad0engmq#/model-market
智谱AI:
https://bigmodel.cn/
Gemini:暂时不推荐,国内不好用;
03
部署调试
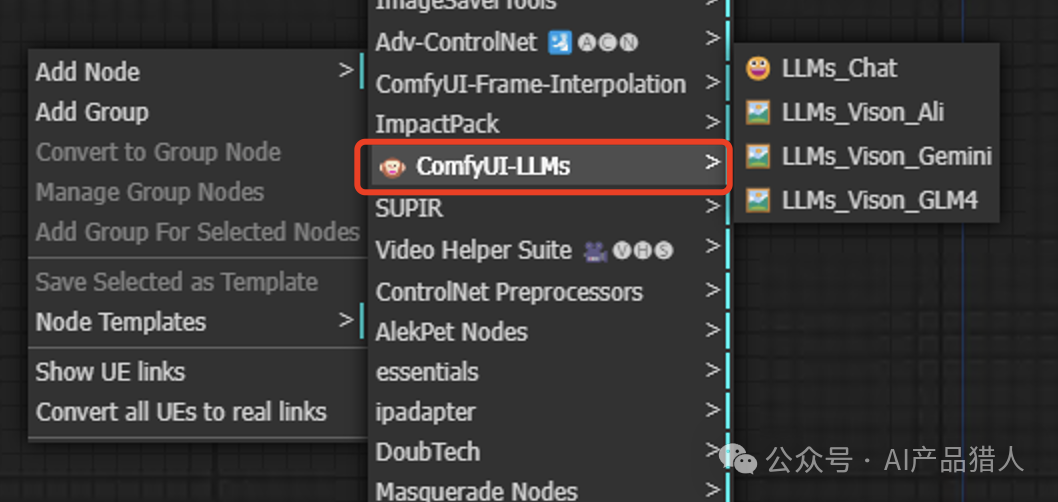
1)几个节点的用途介绍
当安装部署好之后,ComfyUI里面就会多这个节点,然后我们根据需要自行选择即可;
-
LLMs-Chat:文本处理的节点,上面案例的提示词增强,翻译都是这个节点来处理的;很通用
-
LLMs-Vison-Ali:阿里通义千问的识图节点,案例里第一个就是用的这个,可以直接外接一个图片来做识图能力;
-
LLMs-Vison-Gemini:同理,只是模型换成了Gemni
-
LLMs-Vison-GLM4:同理,模型换成了智谱AI
**2)如何配置API-key的文件
**
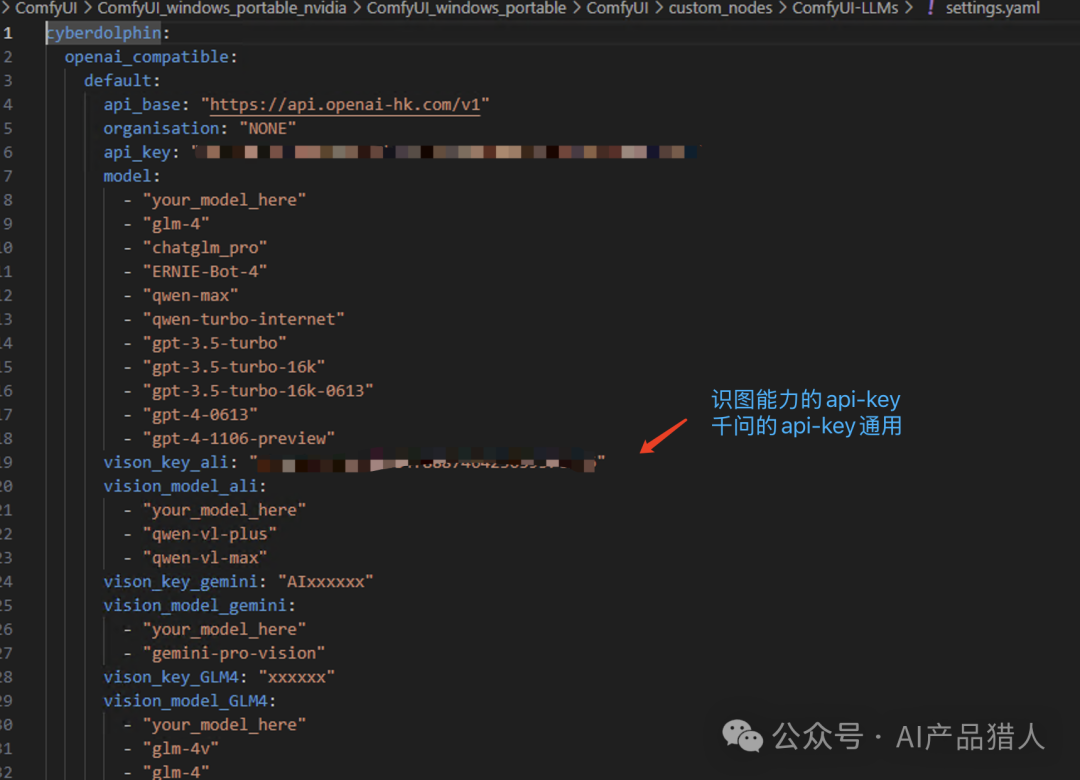
当申请好API-key,并也能成功调用这几个节点之后,我们就可以配置关键的API-Key了;在custom_nodes文件下找到ComfyUI-LLMs文件下的settings.yaml文件,用记事本打开,将申请下来的API-key填入进去;
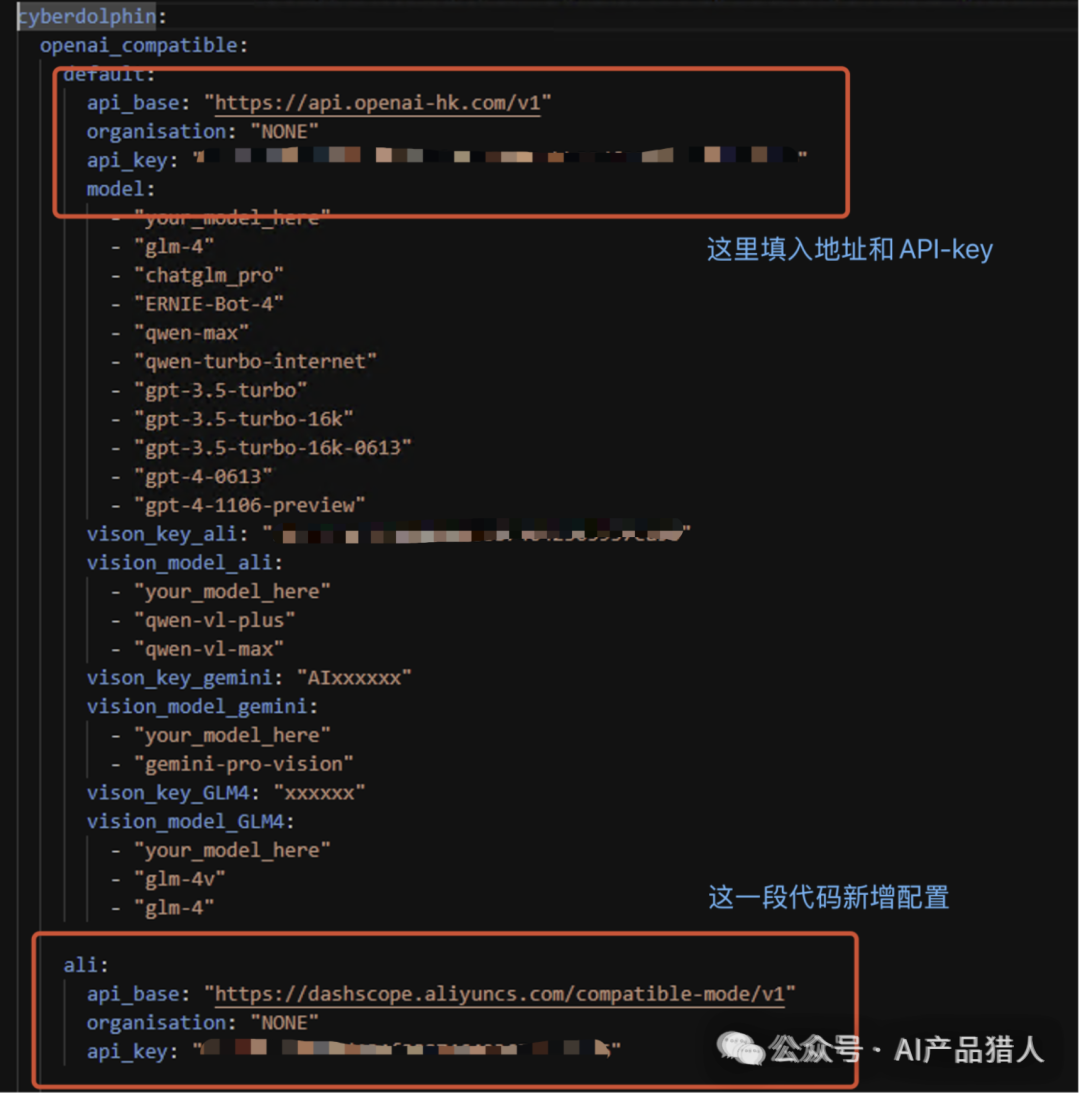
这里需要填写的地址如下:
如果你也跟我用的是上面说到的ChatGPT代理,那么ChatGPT的地址如下:
https://api.openai-hk.com/v1
阿里通义千问的api访问地址如下:
https://dashscope.aliyuncs.com/compatible-mode/v1
智谱的我还未配置,大家自行根据需要配置即可;
大家记得,如果要用识图的能力,这里的api-key别忘了配置;跟之前申请的千问的api-key一样;
3)重启ComfyUI,开始测试效果


这是我通过LLMs识图能力,将图片的衣服换到要替换的模特身上的效果;我们之前文章的一键换装效果,就很轻松的实现了图生图换装效果了;要实现完全1:1换装还是不太可能,但可以很接近类似效果了;可以用于前期的模特换装的快速尝试;
写到最后
当然,我们这套接入api的方式虽然简单,但也会面临api后续收费的;通义千问和智谱前期都比较友好,基本前一个月免费送的token完全够用;后续大家再看要不要续费继续玩,或者有兴趣,我们也可以出一个将LLMs模型部署到本地教程;
不同模型之间的结合越来越好玩,而且随着模型库越来越丰富,不同的模型之间扮演的角色也越来越细致,如何应用好这些模型,将他们调教成最适合自己的角色的能力,会在今后的技能树里越来越重要
为了帮助大家更好地掌握 ComfyUI,我花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









