










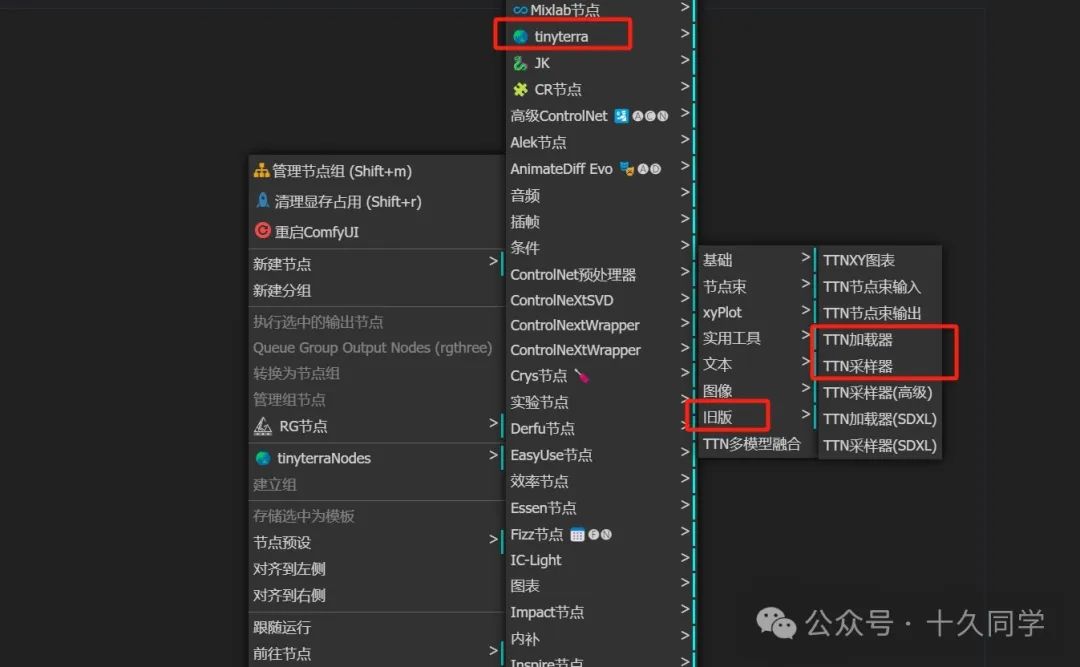
一、搭建基础框架文生图
1、新建基础工作流,这里用TTN节点包。加载“TTN加载器”,“TTN采样器”。
新建/tinyterra/旧版
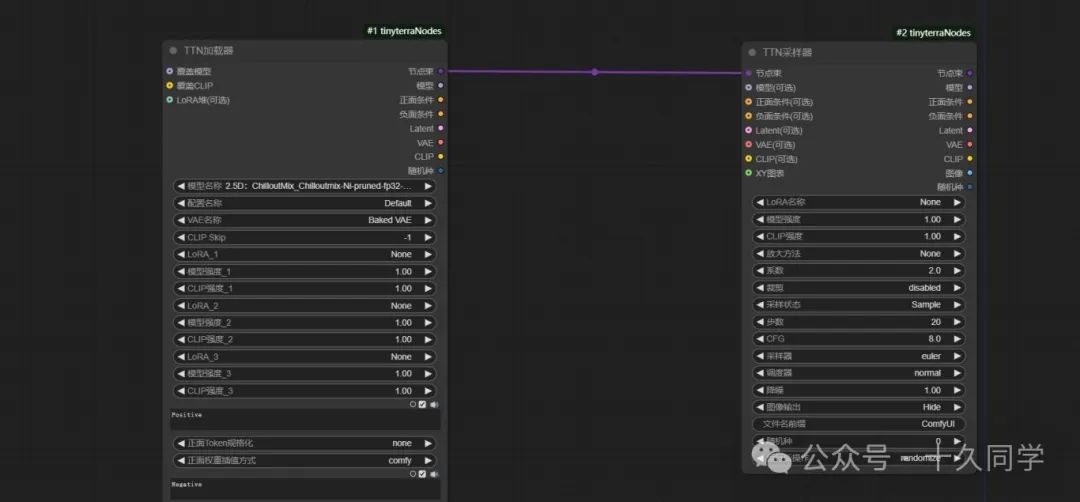
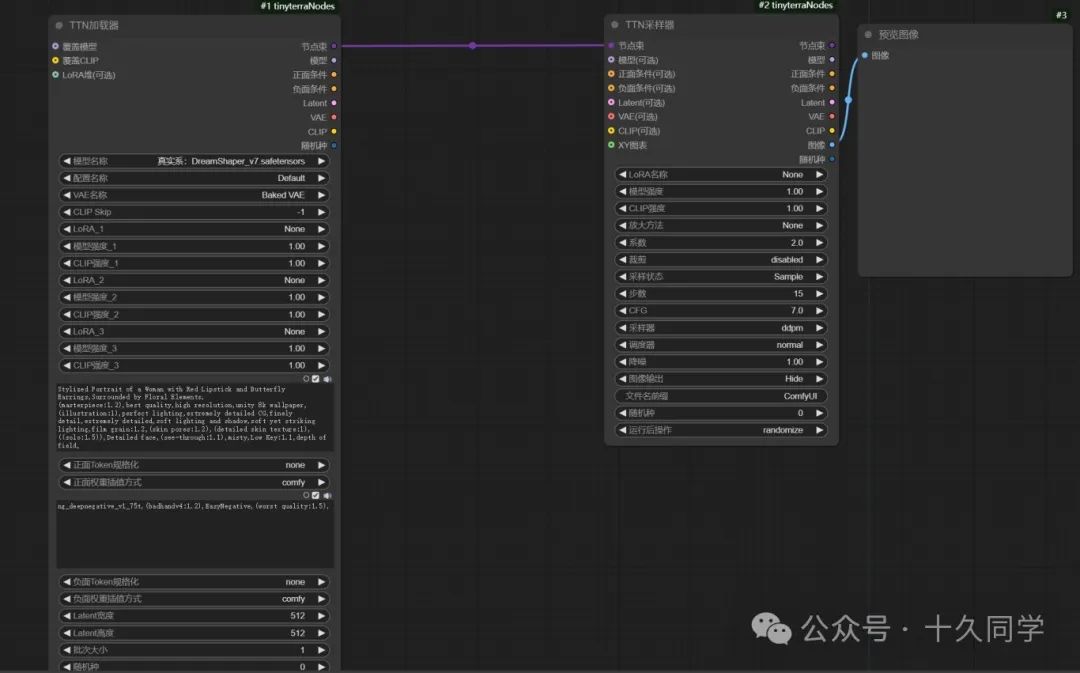
2.修改参数
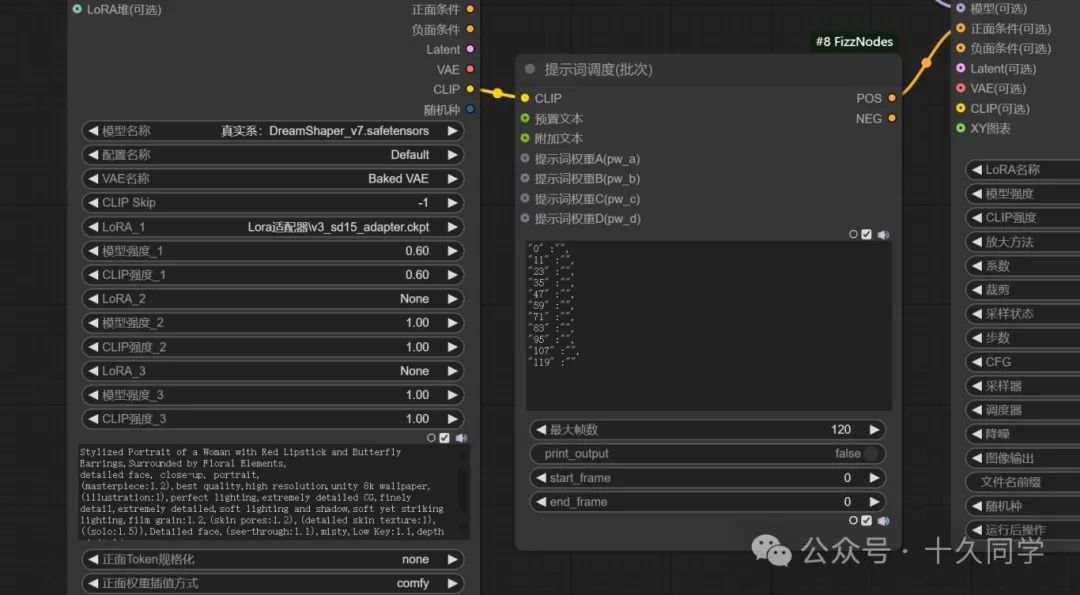
【加载器】:
大模型:Dreamshaper_V7
提示词:
01

正面:
Stylized Portrait of a Woman with Red Lipstick and Butterfly Earrings,Surrounded by Floral Elements,detailed face, close-up, portrait,
(masterpiece:1.2),best quality,high resolution,unity 8k wallpaper,(illustration:1),perfect lighting,extremely detailed CG,finely detail,extremely detailed,soft lighting and shadow,soft yet striking lighting,film grain:1.2,(skin pores:1.2),(detailed skin texture:1),((solo:1.5)),Detailed face,(see-through:1.1),misty,Low Key:1.1,depth of field,
02
负面:
ng_deepnegative_v1_75t,(badhandv4:1.2),EasyNegative,(worst quality:1.5),
(提示词来源于LIblibAI)
【采样器】:
步数:15
CFG:7
采样器:ddpm
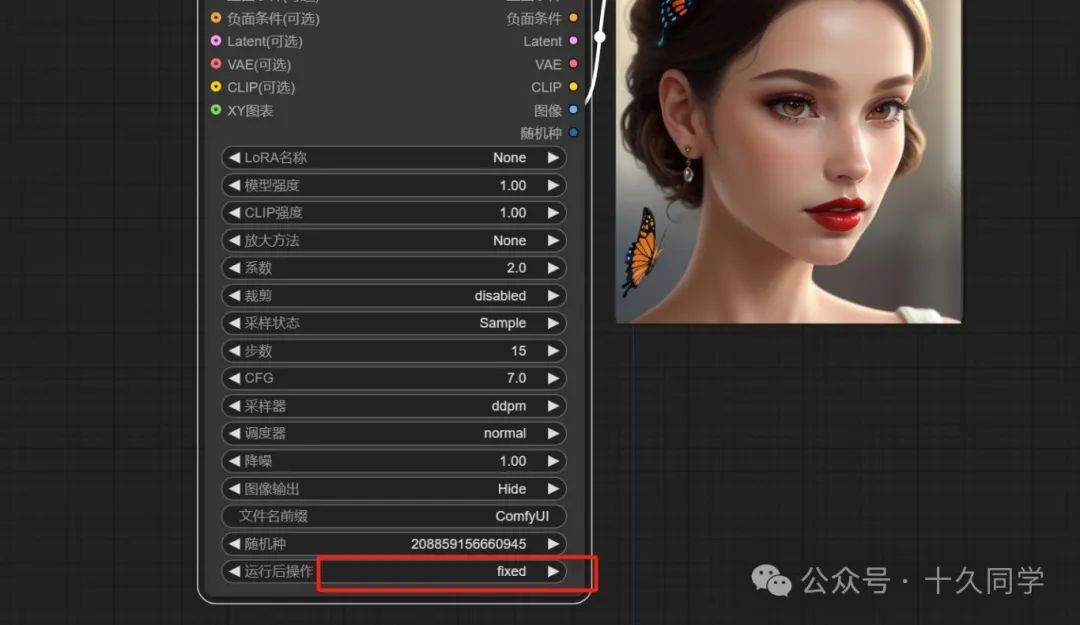
3.出图抽卡看效果,不满意可以多抽几次,抽到满意的图片,固定随机种子。

二、加载视频节点
1.新建/AnimateDiff Evo/Gen1节点/动态扩散加载器
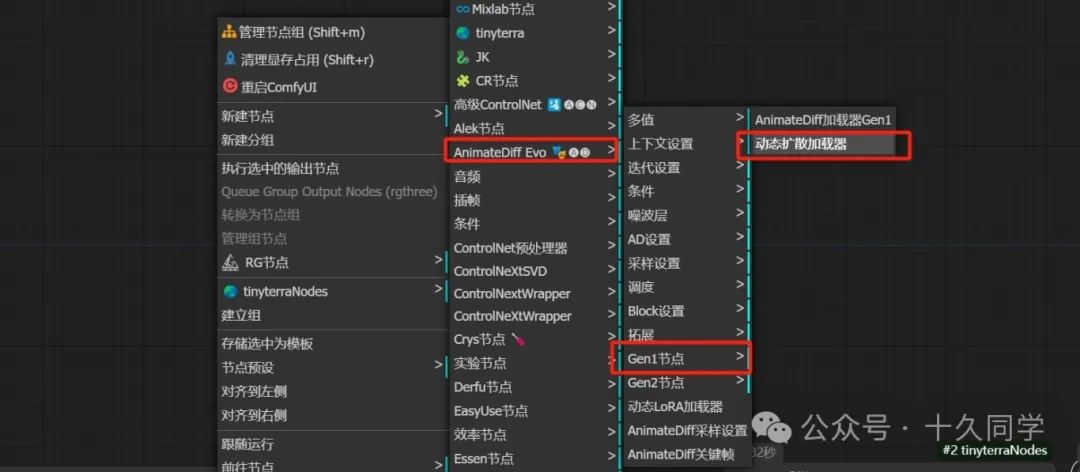
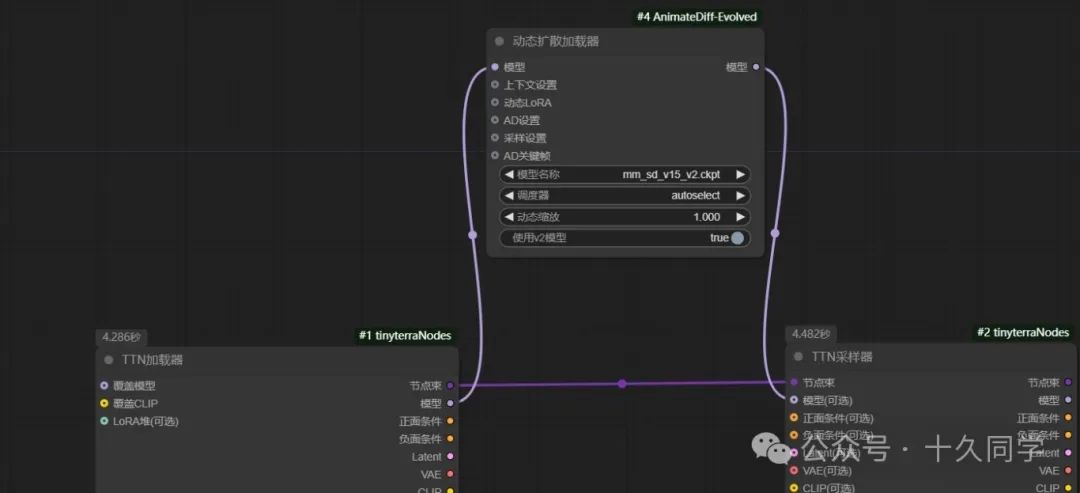
2.动态扩散器走的是模型管道,连接模型走通管道。
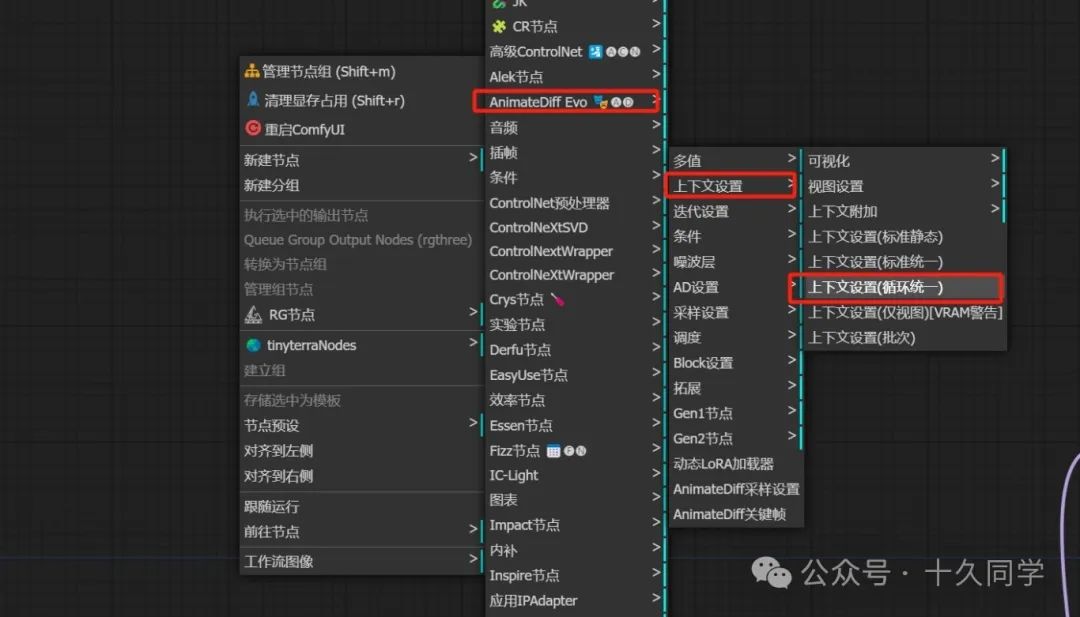
3.加载“上下文设置”节点
新建/AnimateDiff Evo/上下文设置/上下文设置(循环统一)
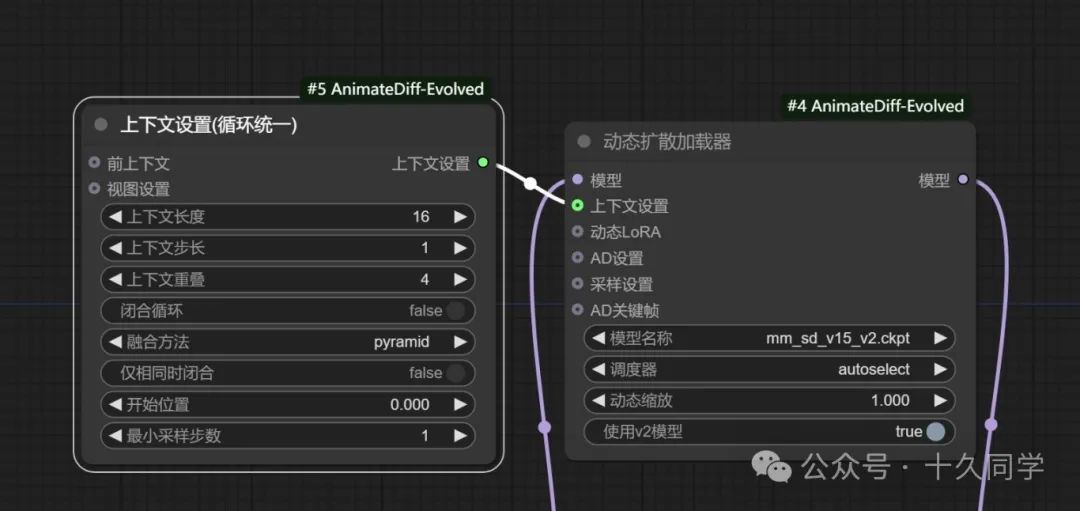
4.修改参数:
【动态扩散加载器】:
模型名称:V3_sd15
调度器:sqrt_linear(AnimateDiff)
【上下文设置】:
上下文重叠:2
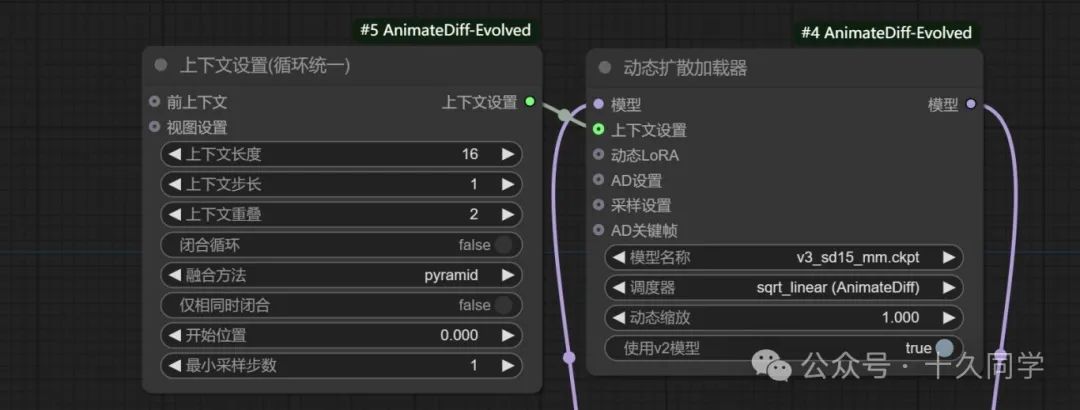
【TTN加载器】
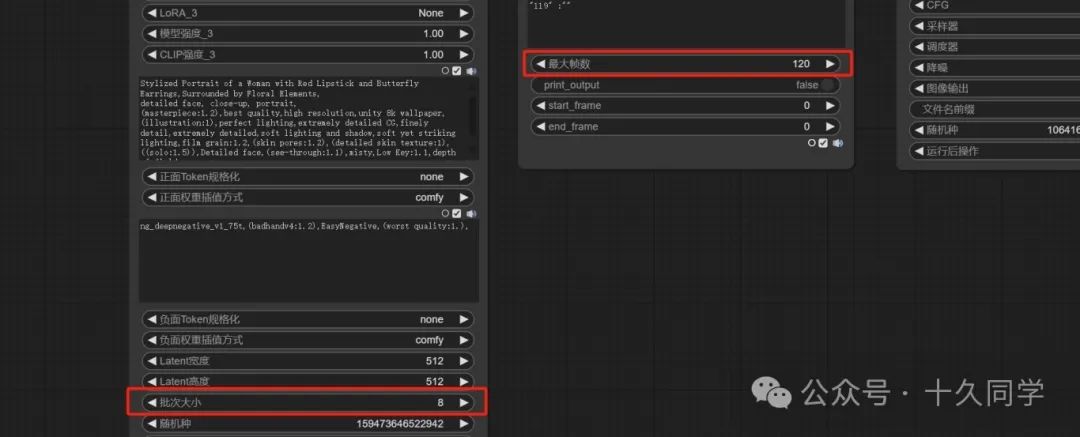
批次大小:8
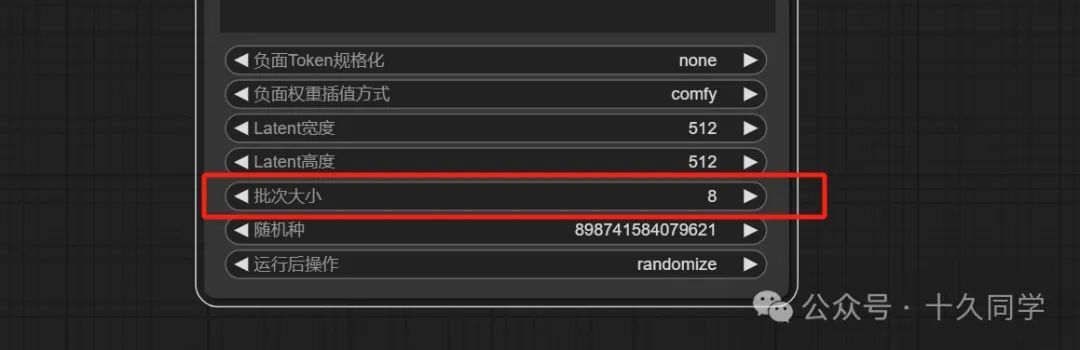
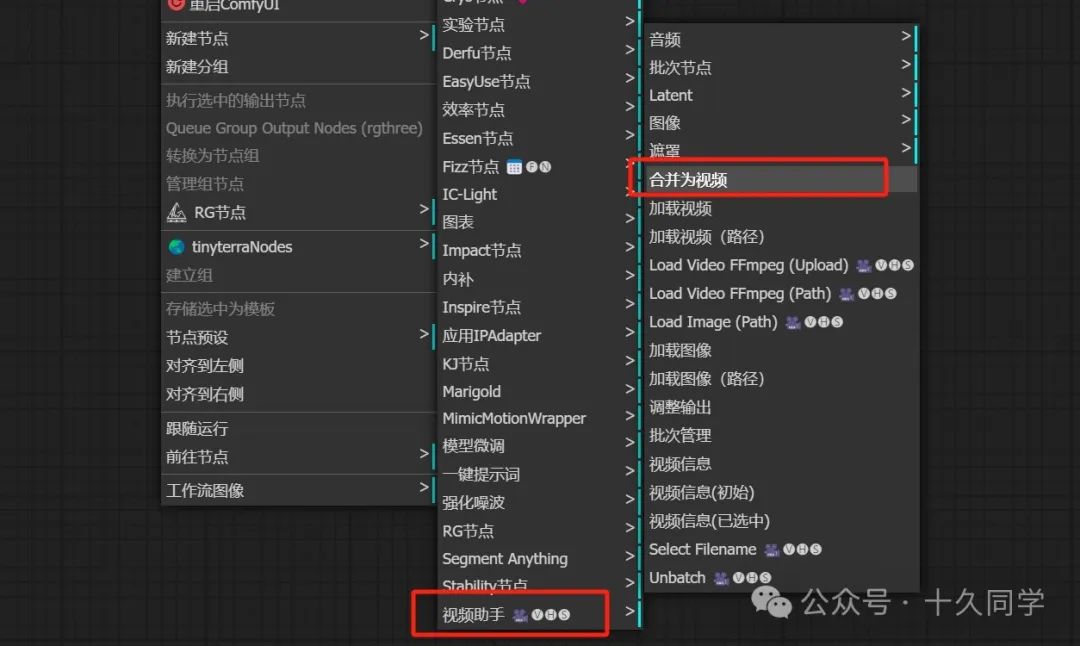
5.加载视频节点,修改参数
新建/视频助手/合并为视频
参数修改:
格式:video/h264-mp4
crf:22
把保存/保存到输出文件夹都关掉,先预览效果。
这里采样器已经给图片解码,可直接连接图像管道。
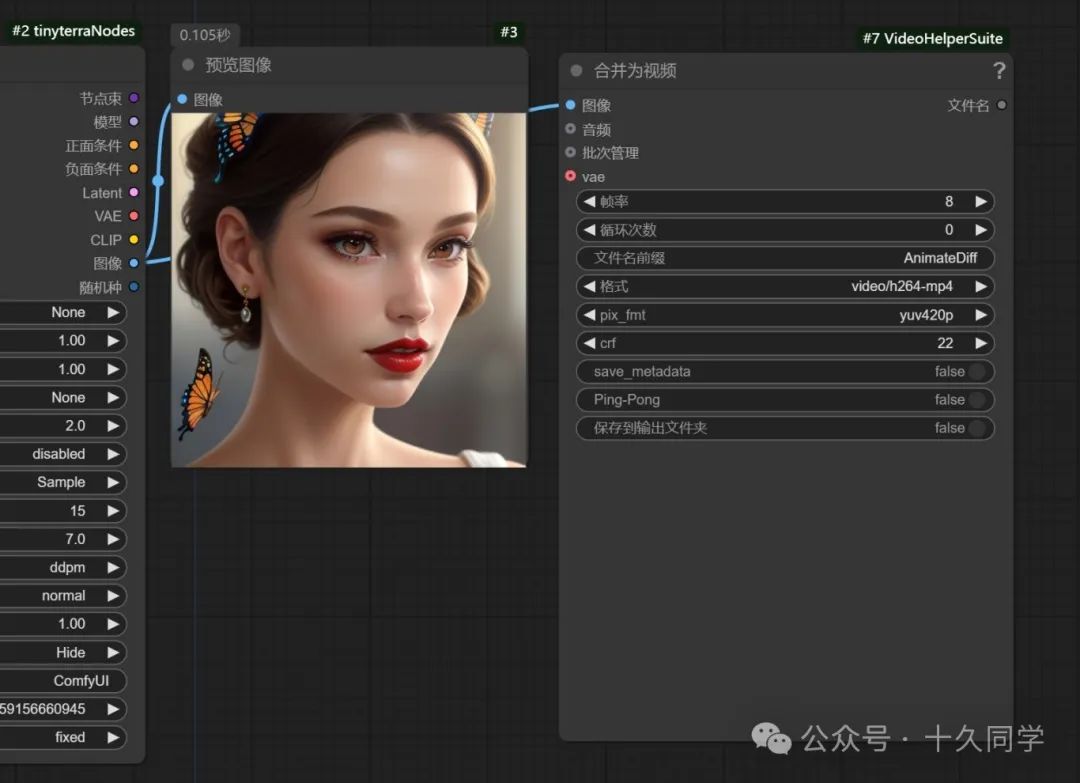
6.这里虽然固定住随机种子了,但它在生成视频时还是重新抽了一张。
虽然动的幅度不是很大,但效果感觉还不错。
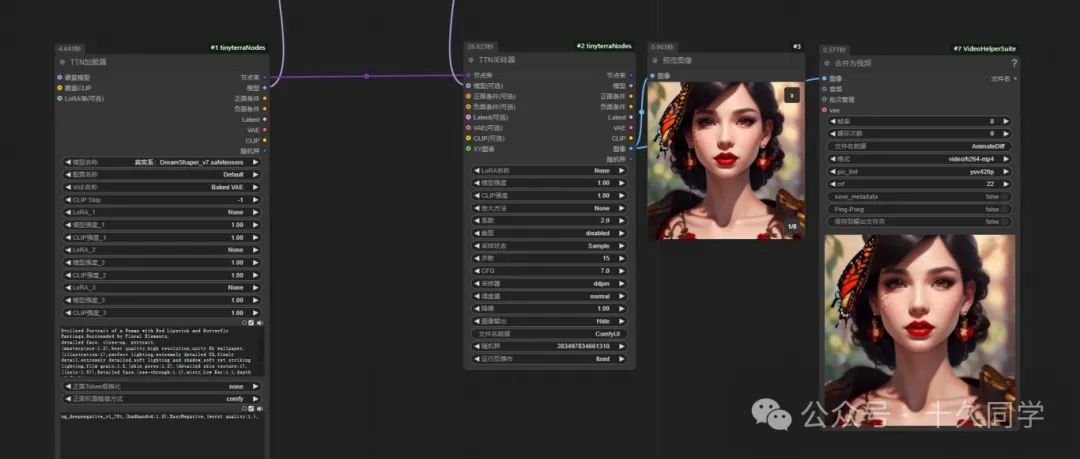
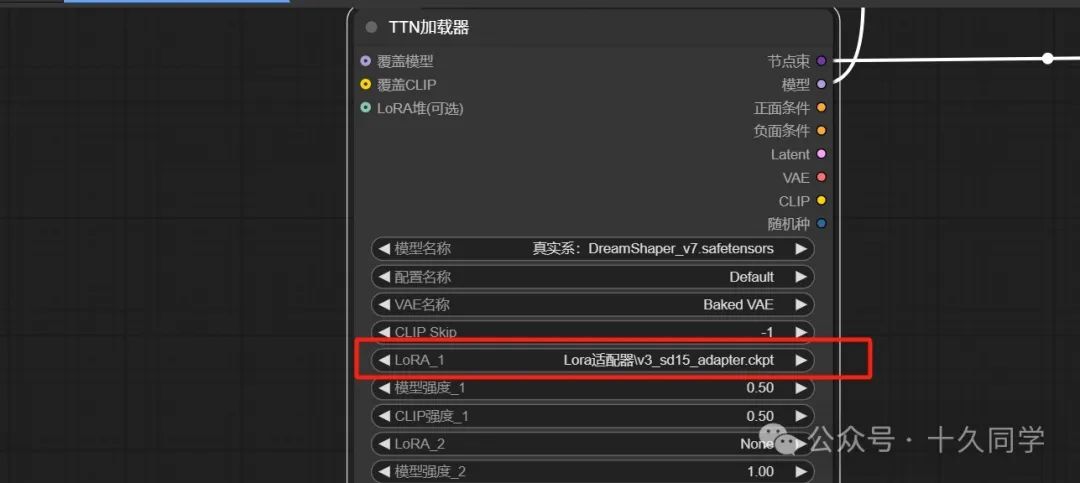
7.加载器里我们加个lora适配器,强度先不给那么高,改成0.5,动态扩散器里的动态缩放改成1.1,看下效果,明显幅度比之前稍微好点。
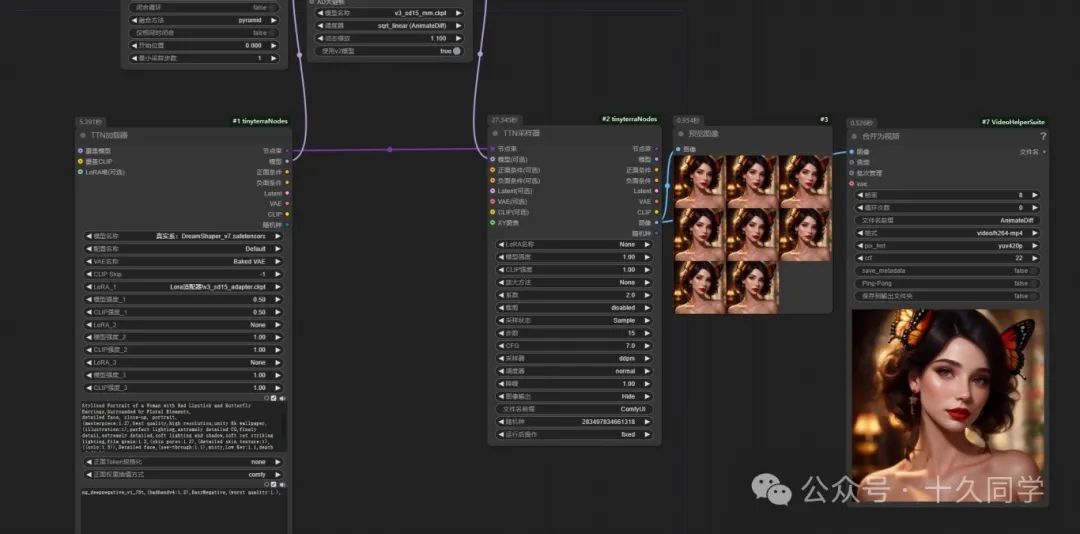
三、如何控制人物微表情?
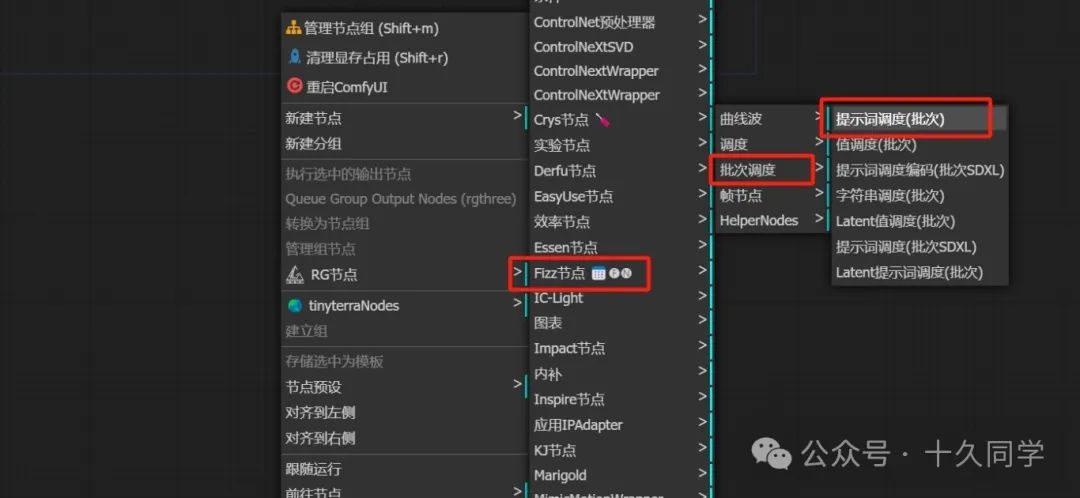
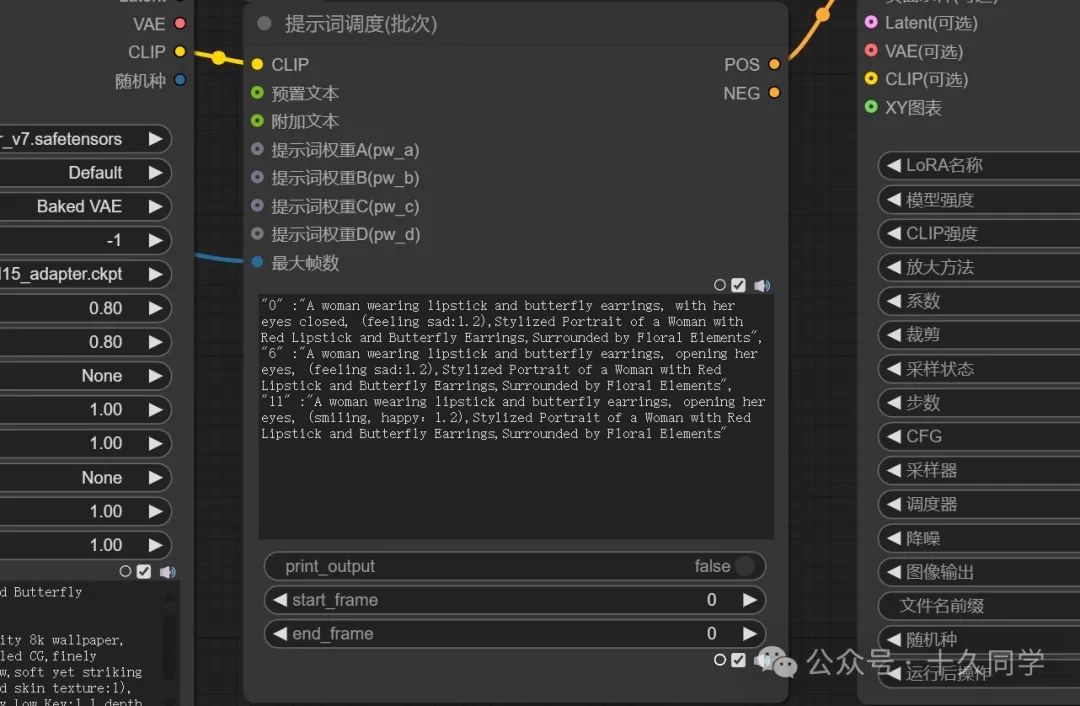
1.加载一个调度节点
新建/Fizz节点/批次调度/提示词调度(批次)
2.调度节点走的是clip管道,连线。这里只需要连接正面提示词管道就行。
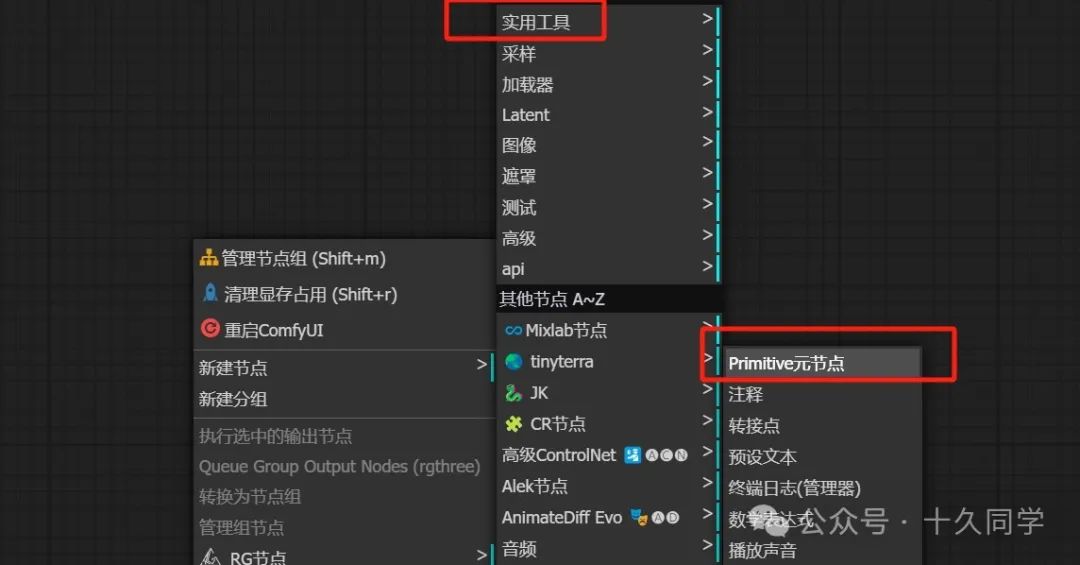
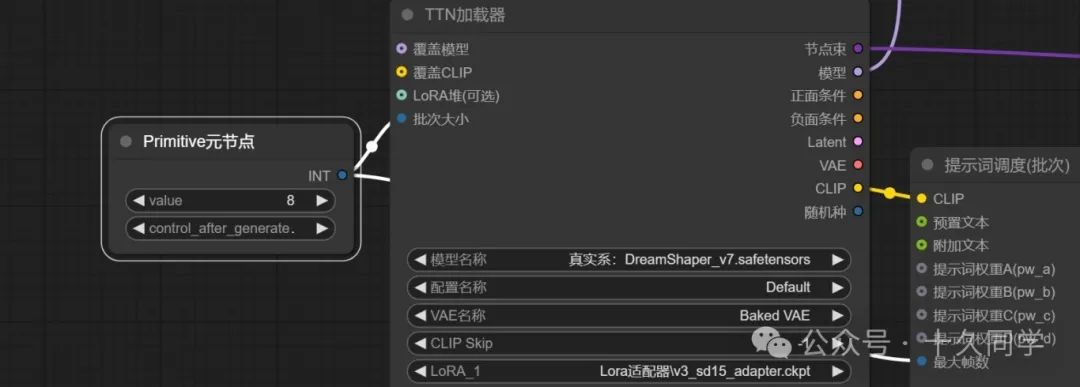
3.把提示词调度里的最大帧数提升为变量,加载器里的批次大小也提升为变量。为它们一个元节点,方便统一修改。
4.在提示词调度(批次)里填写提示词。
01

“0” :“A woman wearing lipstick and butterfly earrings, with her eyes closed, (feeling sad:1.2),Stylized Portrait of a Woman with Red Lipstick and Butterfly Earrings,Surrounded by Floral Elements”,
“6” :“A woman wearing lipstick and butterfly earrings, opening her eyes, (feeling sad:1.2),Stylized Portrait of a Woman with Red Lipstick and Butterfly Earrings,Surrounded by Floral Elements”,
“11” :“A woman wearing lipstick and butterfly earrings, opening her eyes, (smiling, happy:1.2),Stylized Portrait of a Woman with Red Lipstick and Butterfly Earrings,Surrounded by Floral Elements”
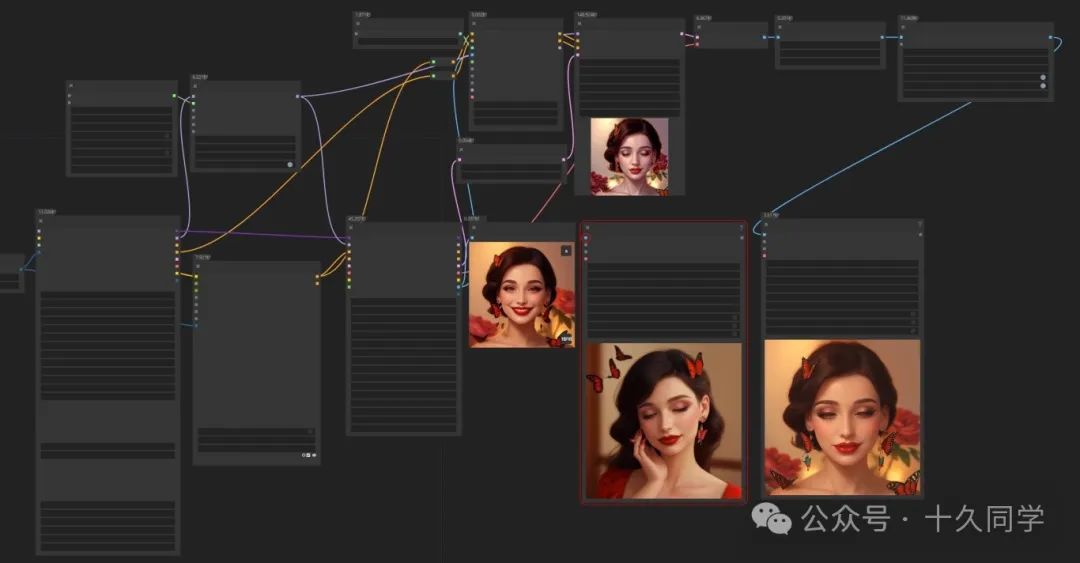
5.渲染看下效果,微表情控制感觉很不错。如果不满意,还可以继续抽卡。
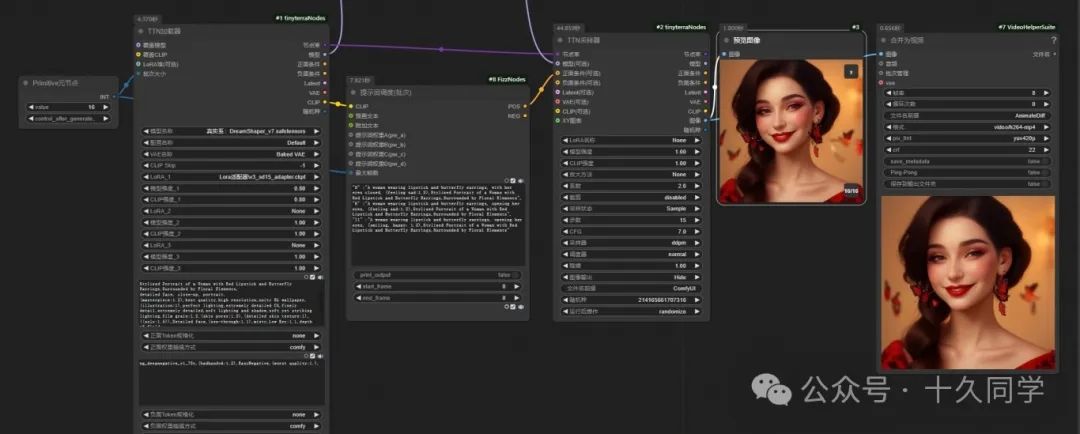
四、视频最终处理
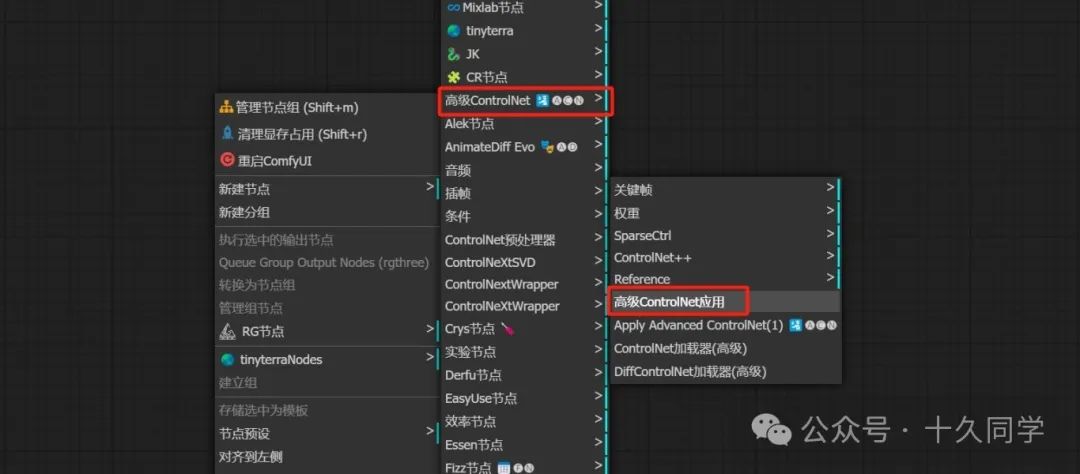
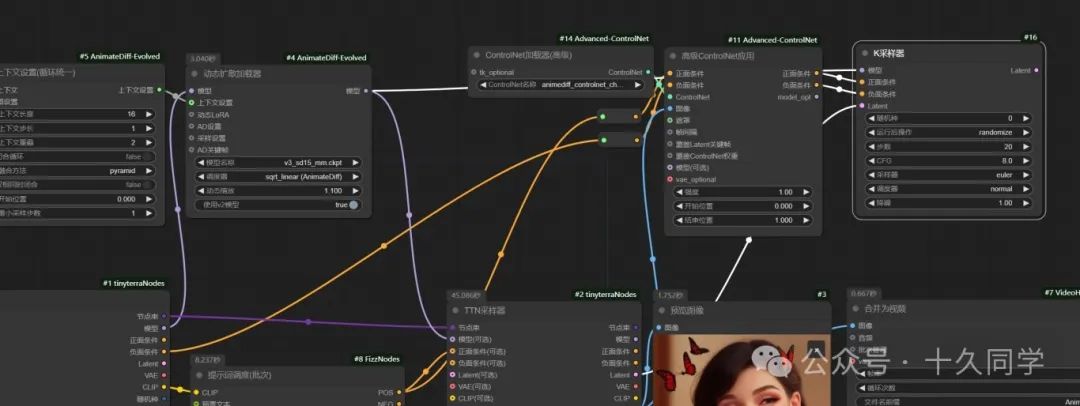
1.通过controlnet调用一个模型,专门用来稳定AnimateDiff。
人物的稳定,动画的二次采样,可以理解为动画的refiner,稳定通过AnimateDiff直接生成的动态错误。
新建/高级controlnet/高级controlnet应用
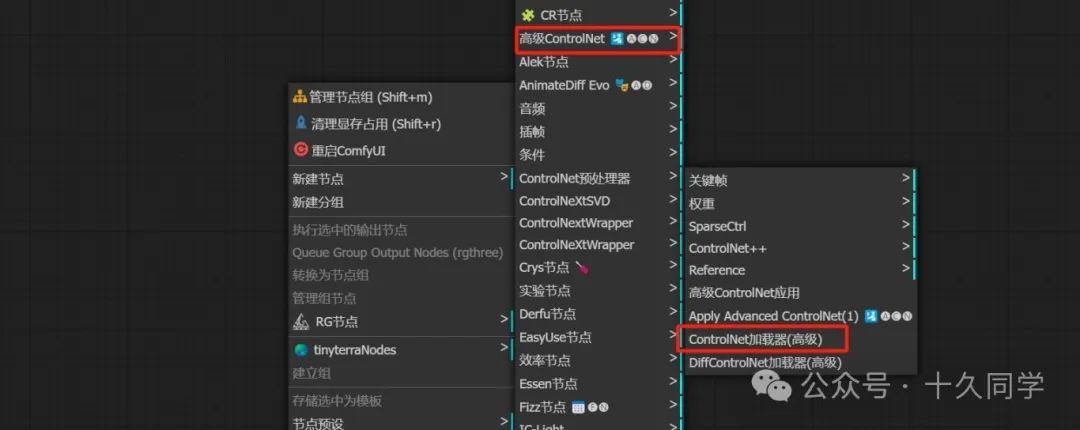
2.调出controlnet模型
新建/高级controlnet/controlnet加载器
controlnet
加载器模型:animediff_controlnet_checkpoint
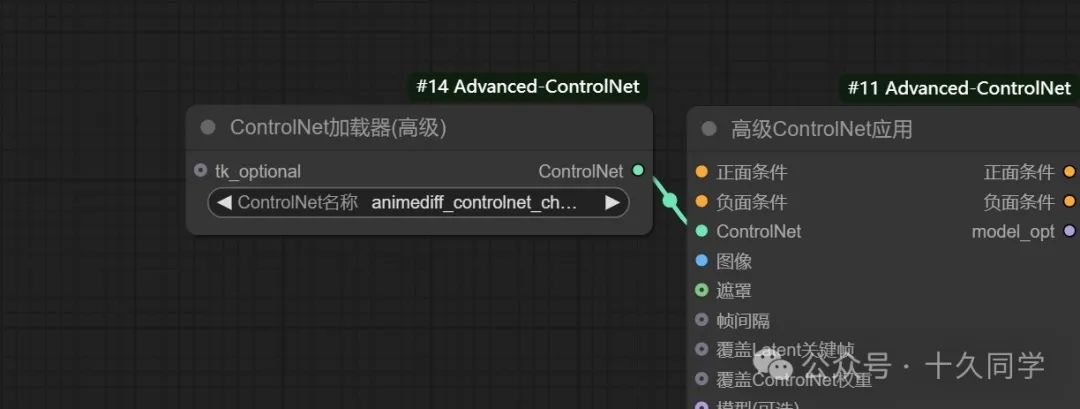
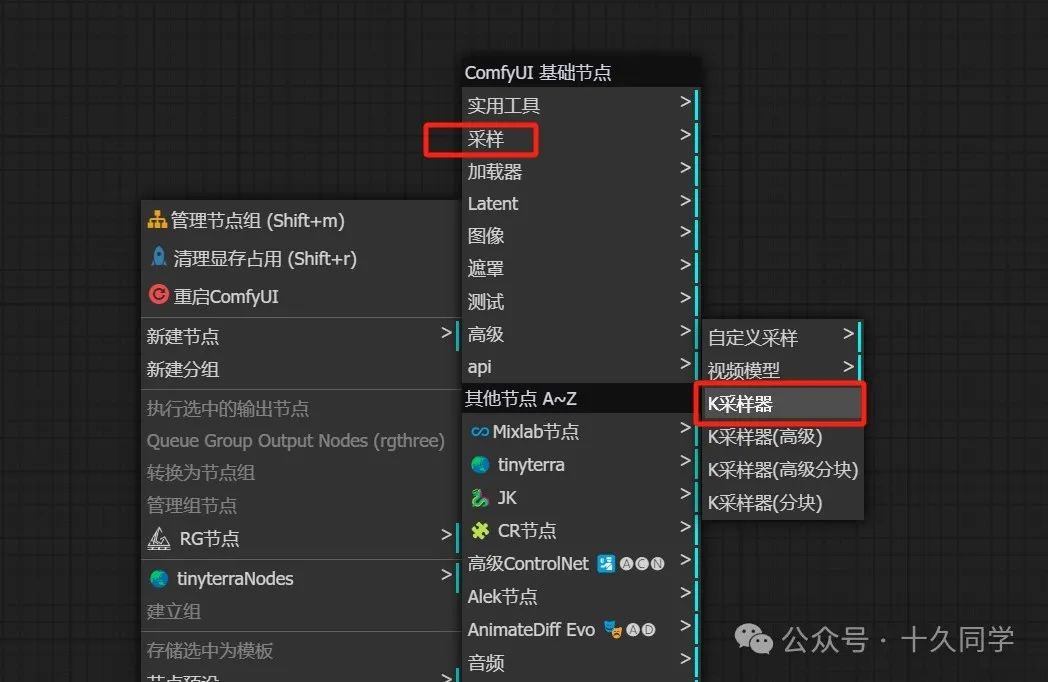
3.加载一个普通的K采样器,连线
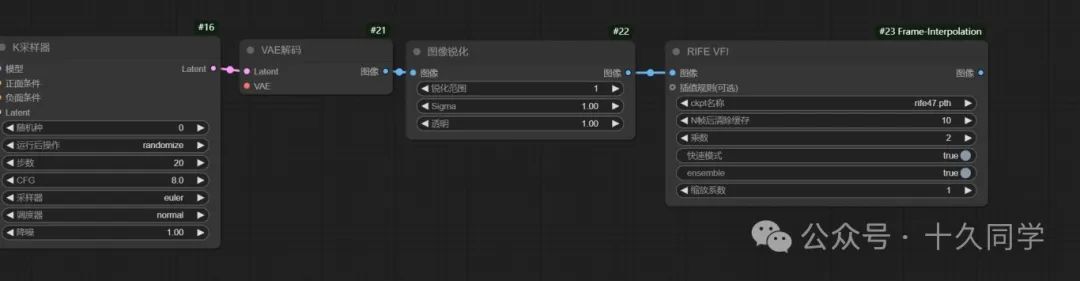
新建/采样/K采样器
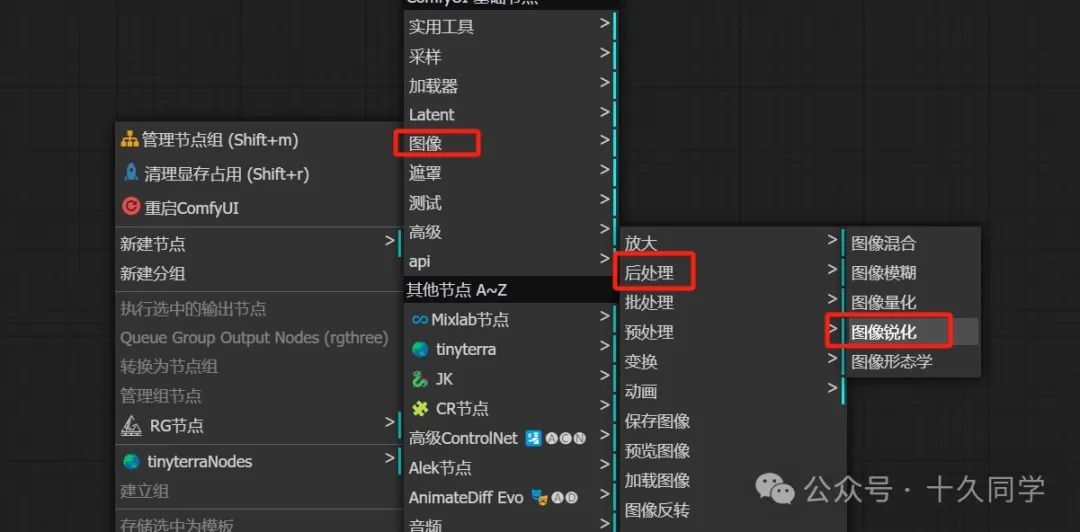
4.K采样器出来给它一个VAE解码,给图像添加一个锐化。
新建/图像/后处理/图像锐化
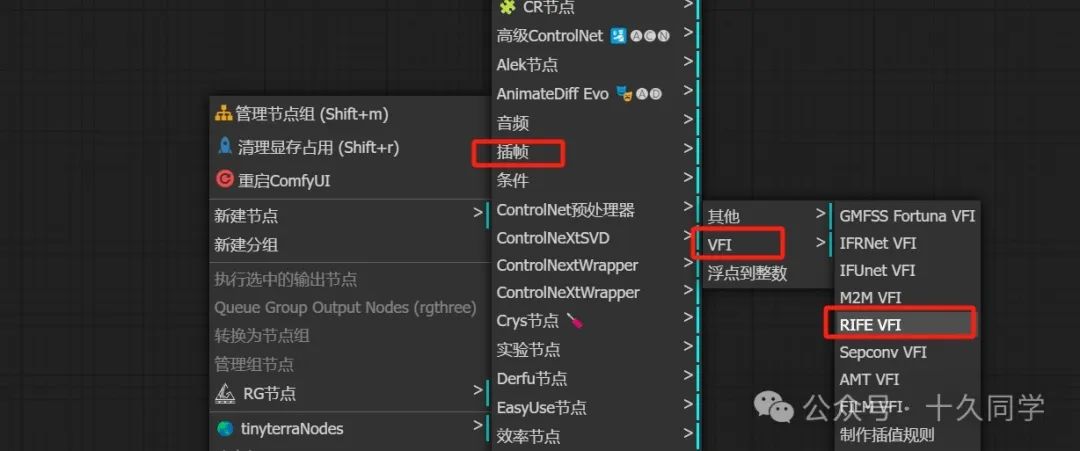
5.给视频插帧
新建/插帧/VFI/RIFE VFI
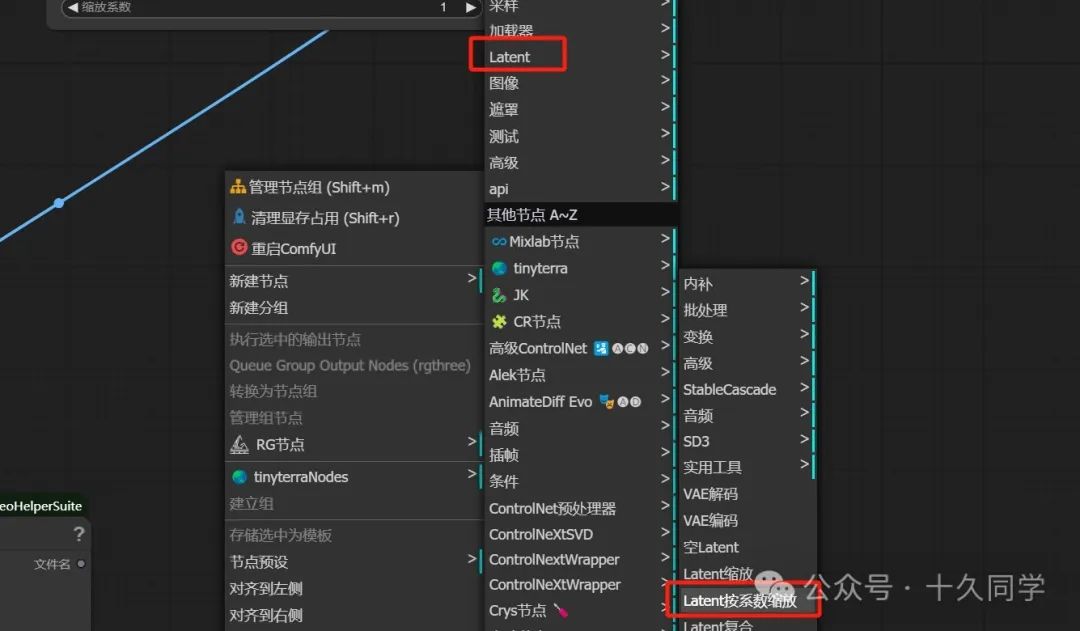
6.加载“Latent按系数缩放”节点
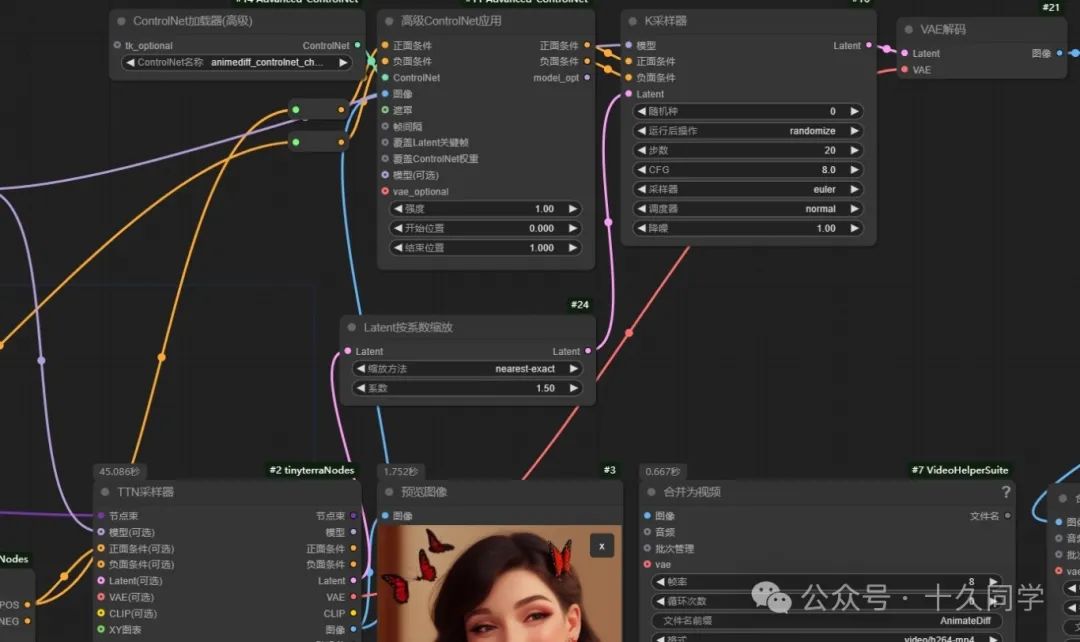
7.连线修改参数
0****1
-
高级controlnet:强度:0.8
-
结束位置参数:0.8
-
K采样器:采样器:ddim
-
降噪:0.7
-
图像锐化:sigma:0.5
-
透明:0.6
-
RIFE VFI:乘数:3(24帧动画帧)
-
合并为视频:帧率:24
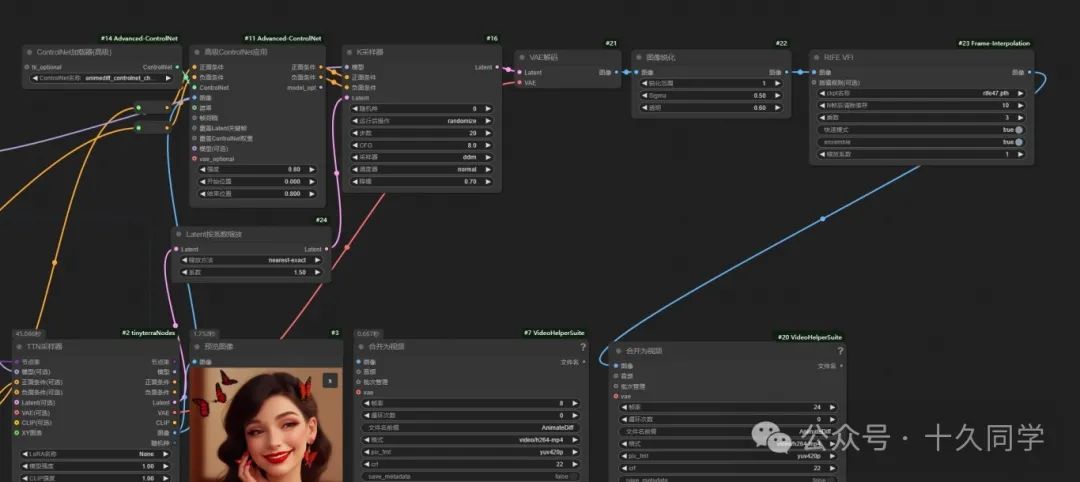
8.渲染看效果,感觉完善后的好多了。

为了帮助大家更好地掌握 ComfyUI,我花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









