










一 RPG基础型号:SD1.5 类型:大模型
角色大模型侧重于角色扮演游戏肖像,类似于《魔兽世界》《龙与地下城》、《冰风谷》以及更现代风格的RPG角色。·
风格: 幻想
二·MajicMIX v7.2 基础型号:SD1.5 类型:大模型
麦橘现实写实大模型,可以提供很好的人物写实效果。融合了多种模型,可以生成好看的脸部,也能有效应对暗部处理。远距离脸部生成需要inpaint以达成最好效果。也可以使用after detailer。推荐采样器: Euler a、Euler,迭代步数:20~40,高清修复: ESRGAN 4X或 4x-UltraSharp。
风格:写实/真人
三 ToonYou - Beta 6 基础型号:SD1.5 类型:大模型
时尚卡通大模型,带有可爱风格。推荐采样器: DPM++ SDE Karras,选代步数: 30+ 时尚卡通大模型,带有可爱风格。推荐采样器: DPM++ SDE Karras,选代步数: 30+CFG scale:8, VAE: ft-mse-840000-ema,高清修复: R-ESRGAN 4x+ Anime6B。
·风格: 动画
四 I****P DESIGN4 基础型号:SD1.5 类型:大模型
针对皮克斯风格训练的大模型,可以输出皮克斯3D的感觉,类似于泡泡玛特的Q版风格也可以将图的2D画面进行3D化,主要生成偏向于卡通风格的可爱风Q版。推荐采样器DDIM, 迭代步数: 20~30, CFG scale:7,VAE: cute vae.safetensors。
·风格: 3D艺术
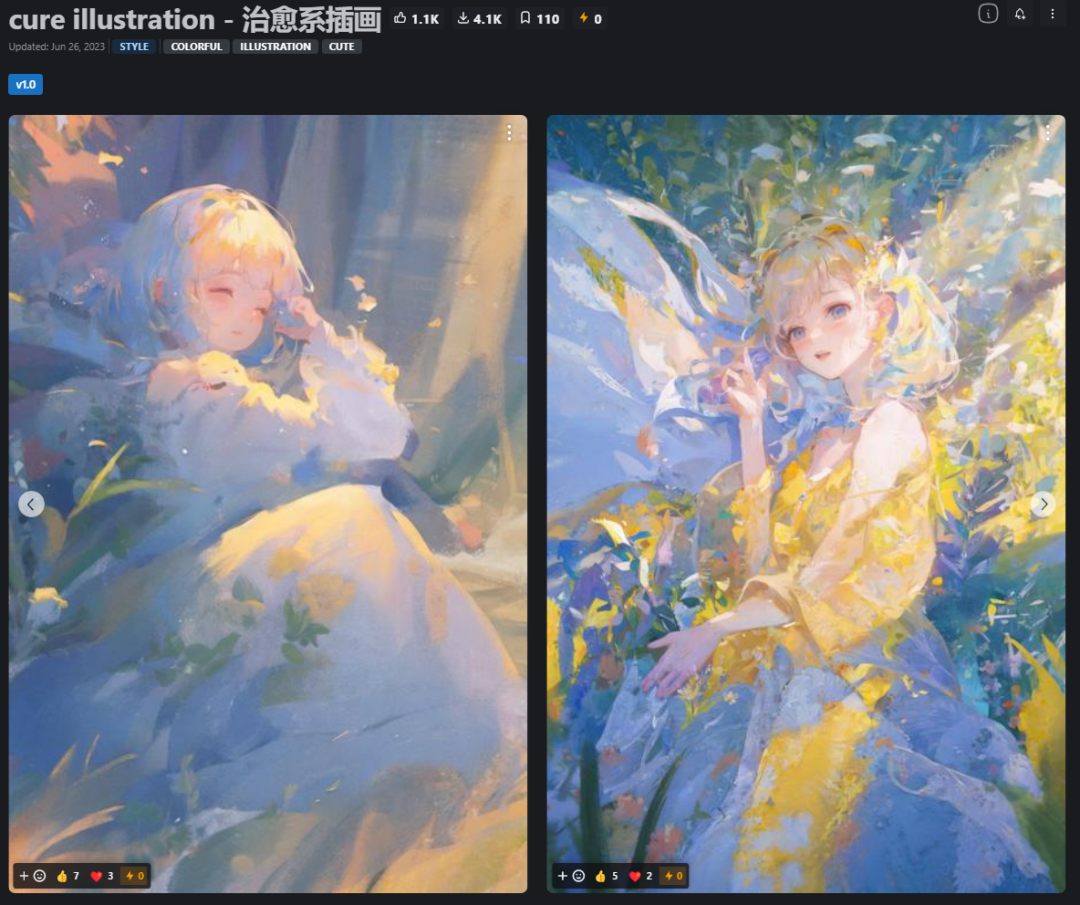
五· Cure illustratio 基础型号:SD1.5 类型:LORA
治愈系插画的lora模型,色彩比较梦幻活泼。使用大模型SHMILY v1.0 CXSYH有更好的效果,推荐采样器: DPM++ 2M Karra,迭代步数: 20~30,CFG scale: 7。
·风格: 厚涂
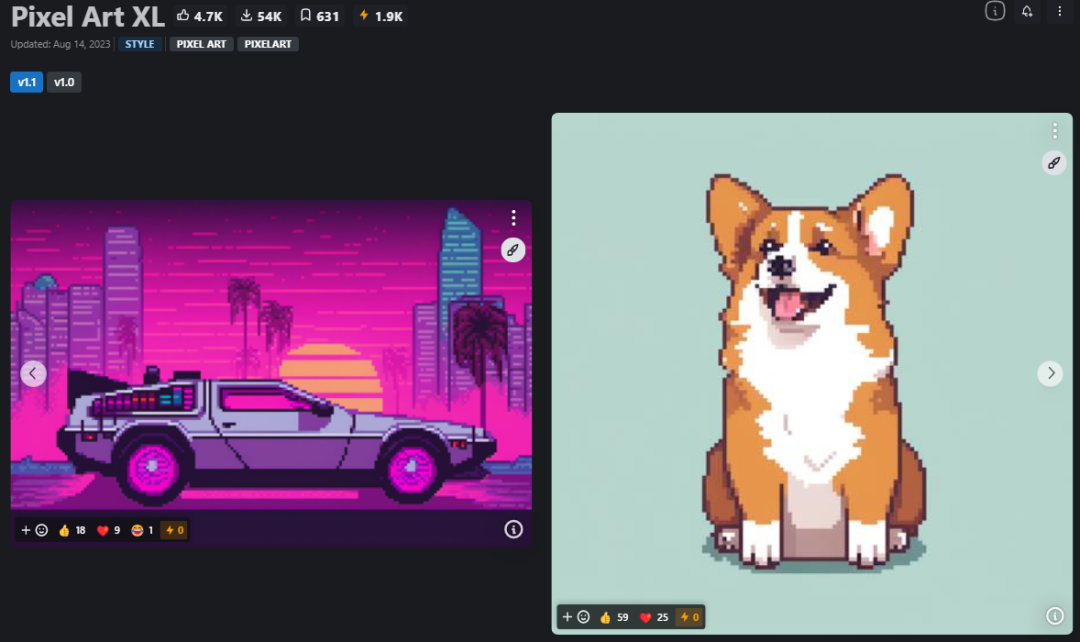
六 Pixel Art X 基础型号:SDXL 1.0 类型:大模型
像素艺术风格lora模型。它能够生成各种像素艺术风格的图像,制作出美丽且富有创意的艺术品。擅长提供具有独特像素艺术风格的图像,提供诸如鲜艳的色彩饱和度和较短提示的便利性等优势。推荐采样器: DPM++ 2M Karra,迭代步数: 30~50,CFG scale:7VAE: XL VAE C。
·风格: 像素艺术
七 SakushiMix 基础型号:SD1.5 类型:大模型
现实主义插画lora模型,颜色多样化。推荐采样器: DPM++ 2M Karra,迭代步数: 20~30,CFG scale: 7~12,高清修复: RealESRGAN x4plus anime 6B, VAE:840000。
·风格:二次元

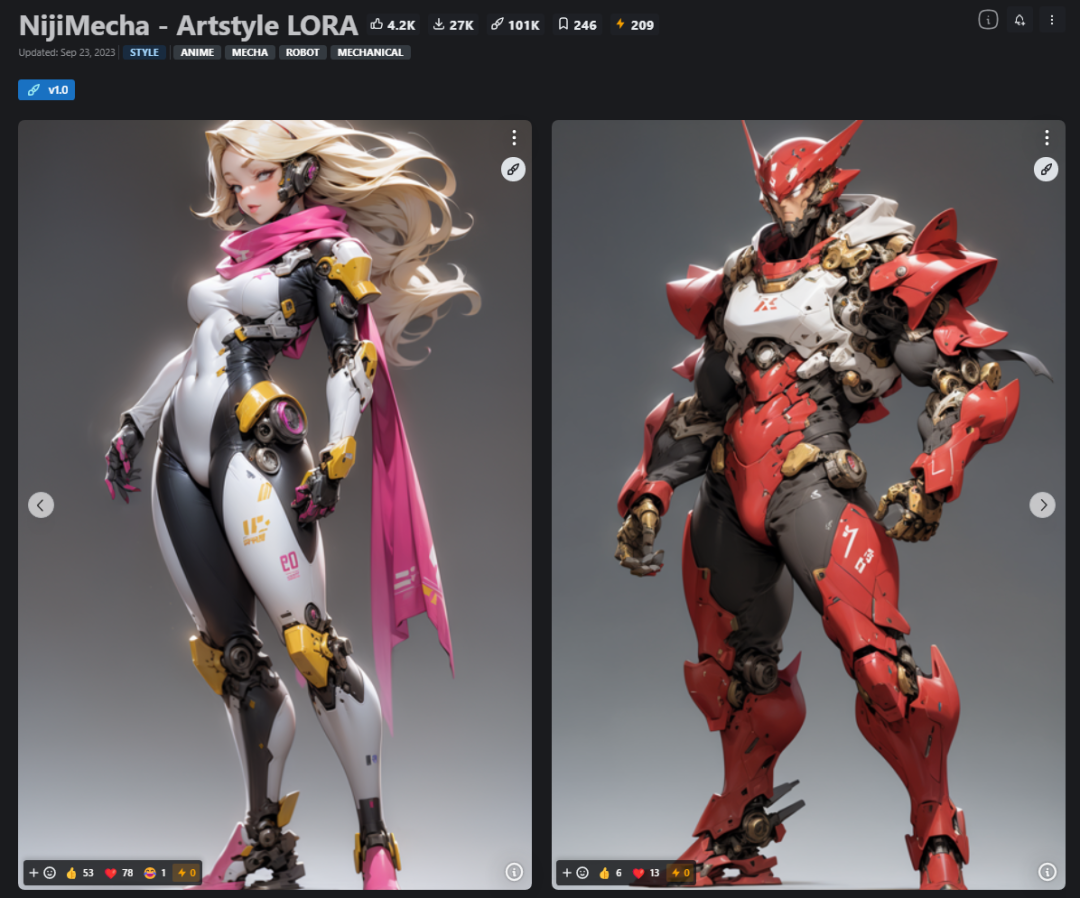
八 NijiMecha - Artstyle LORA 类型:LORA
基于nijijourney 训练的机甲风格lora。权重介于 0.8-1 之间有最佳结果。使用大模型Based64mix-V3有更好的效果,推荐采样器: DPM++ 2M Karra,迭代步数: 20~30.CFGscale: 7.
风格: 机甲
CivitAI模型分类要分为四类:
Checkpoint: 这是最常见的基础大模型,也被称为“主模型”、“底模型”或“Checkpoint模型”。它包含了文本编码器、U-net网络和图像编码器三个部分,能够将文本描述转换为逼真的图像。
LoRA: LoRA(Low-Resolution Representation Adaptation)是一种可以用于微调Stable Diffusion模型的技术。它可以通过添加一个额外的LoRA层来调整模型的输出,从而生成具有特定风格或特色的图像。例如,可以训练一个LoRA模型来生成二次元人物图像,或者生成具有特定艺术风格的图像。
Textual Inversion: Textual Inversion是一种可以用于将特定图像嵌入到Stable Diffusion模型中的技术。通过Textual Inversion,用户可以将自己喜欢的图片上传到CivitAI,并训练一个新的模型来生成与该图片风格相似的图像。
Hypernetwork: Hypernetwork是一种可以用于控制Stable Diffusion模型生成图像细节的技术。通过Hypernetwork,用户可以指定图像的某些细节,例如眼睛的颜色、头发的样式或背景的元素。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 9973
9973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









