







1 内容简介
Nmap是一款流行的网络扫描软件,有着强大的功能,包括主机发现、端口扫描、操作系统识别、服务识别、traceroute、dns解析、漏洞扫描、暴力破解等,这使它成为了安全研究员的必备武器之一,但是许多研究员使用Nmap扫描的速度并不理想,甚至有时可以说是很慢,本文就带你从Nmap的源码出发,并结合实验验证,挖掘Nmap扫描性能方面的内在逻辑,探索提升Nmap性能的路径。
本文主要涉及主机、端口扫描、操作系统识别、服务版本识别扫描,关于脚本扫描的性能未涉及。
2 nmap扫描基本实现简介
在了解Nmap关于扫描性能方面细节之前,我们需要知道一些Nmap如何实现主机、端口、操作系统识别、服务识别的基本技术。懂的都懂,端口扫描常用到半开放式扫描技术,这样可以提升扫描速度和减少IO消耗,比如tcp端口开发扫描常使用syn扫描,而对于服务版本识别这种基于TCP握手的扫描,则只能建立完整TCP握手后再发包,再提取回复中的关键字识别服务的版本。Nmap也是如此。
2.1 无TCP连接的扫描
对于主机发现、端口扫描、操作系统识别nmap使用无TCP连接的扫描(端口可能是udp,和此类似),主机发现使用arp、icmp协议,端口扫描使用tcp的syn、ack、fin等,操作系统识别则是直接从tcp层构造cookie、tcp
id、option等根据回复特征以完成识别,这几个技术都有个共同点就是只需要发一次包收一次包即可完成识别,所以nmap都使用了send()来发包,然后pcap设置规则收包。
2.2 TCP连接的扫描
对于tcp
connect扫描和服务版本识别nmap就需要进行完整tcp连接,就要采用其他的提升扫描速度的技术了,因为nmap是单线程扫描,可以说仅使用单线程nmap能把扫描性能做到目前这样已经是很强了。nmap对于tcp
connect扫描使用select设置超时来实现。对于服务版本识别这种基于tcp的应用层扫描,则使用epoll,传入超时时间和执行应用层交互的回调函数来实现。
3 nmap中无TCP连接的扫描性能分析
3.1 实验
实验 : 先看一个实验,我们使用nmap默认参数对256个IP的100个端口进行端口扫描,看下时间:


可以看到花了11秒。显然这个时间是比较长的,如果使用自己写的扫描器,我们每秒发包可以超过30000个,把所有端口进行一次发包总共时间为100*256/30000=0.85,设置1秒的等待(内网中等待一秒远远足够,nmap使用等待比这个低很多),然后重试一次,那么总共时间不超过(0.85+1)*2
=3.7秒。
通过wireshark抓包看下nmap发包速率怎样:

看到nmap只向目标网段发送了七千多个包,而不是预计的100*256个包,这是因为nmap在端口扫描前会先进行主机发现探测,如果发现这个主机不在线那么就不会发起端口扫描:
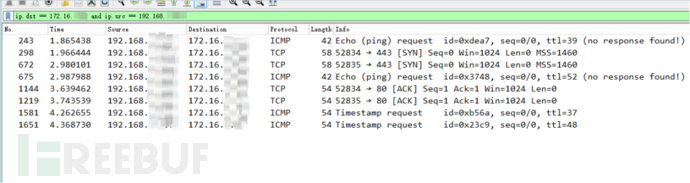
比如上图筛选的这个IP就没有发起端口扫描(80、443是主机发现的策略)(当然这样会带来一个问题,如果一个主机禁了ICMP并且没有开启80和443,但开启了其他端口,那么就会被漏掉)。就如这样比较节省流量的扫描方式依然耗时11秒,nmap这中间经历了什么是让人好奇的。
3.2 源码分析
就如我们所知,端口扫描技术的性能,无非就在于发包速度、发包间隔、收包超时、收包处理速度、重试次数、网卡带宽、网络拥塞度等,这些因素在nmap源码中都有体现,而且体现的可以说有些智能。
定位nmap主机发现、端口扫描分组循环处代码,位于nmap_main()->ultra_scan():
......
while (!USI.incompleteHostsEmpty()) {
doAnyPings(&USI);
doAnyOutstandingRetransmits(&USI); // Retransmits from probes_outstanding
/* Retransmits from retry_stack -- goes after OutstandingRetransmits for
memory consumption reasons */
doAnyRetryStackRetransmits(&USI);
doAnyNewProbes(&USI);
gettimeofday(&USI.now, NULL);
// printf("TRACE: Finished doAnyNewProbes() at %.4fs\n", o.TimeSinceStartMS(&USI.now) / 1000.0);
printAnyStats(&USI);
waitForResponses(&USI);
gettimeofday(&USI.now, NULL);
// printf("TRACE: Finished waitForResponses() at %.4fs\n", o.TimeSinceStartMS(&USI.now) / 1000.0);
processData(&USI);
......
}
......
从函数名称就可以看出它的大致过程:一个分组USI对象,先ping,如果有会尝试重传,再发起探测发包,然后等待收包,最后处理本次更新的数据。当所有端口都扫完,就退出切换下一个分组。
其中doAnyNewProbes()就是进行端口扫描的函数,以此举例分析,主机发现的ICMP发包是在doAnyPings(&USI)中,所有无TCP连接扫描的性能逻辑大致一致。
static void doAnyNewProbes(UltraScanInfo *USI) {
HostScanStats *hss, *unableToSend;
gettimeofday(&USI->now, NULL);
unableToSend = NULL;
hss = USI->nextIncompleteHost();
while (hss != NULL && hss != unableToSend && USI->gstats->sendOK(NULL)) {
if (hss->freshPortsLeft() && hss->sendOK(NULL)) {
ultrascan_host_timeout_init(USI, hss);
sendNextScanProbe(USI, hss);
unableToSend = NULL;
} else if (unableToSend == NULL) {
unableToSend = hss;
}
hss = USI->nextIncompleteHost();
}
}
在这可以看到,每个主机对象hss在进行sendNextScanProbe发包前会进行一次判断,主要是sendOK()和freshPortsLeft(),后者显然就是判断是否还存在待发包的端口,而两个sendOK()里面有什么,经过我的实验在端口扫描阶段hss->sendOK()非常频繁的返回了
false。
bool HostScanStats::sendOK(struct timeval *when) {
......
//判断当前主机是否超时
if (target->timedOut(&USI->now) || completed()) {
......
}
......
//是否达到最小发包速率
if (o.min_packet_send_rate != 0.0) {
......
}
//是否通过速度现在检测
if (rld.rld_waiting) {
......
}
//是否满足发包延迟要求
if (sdn.delayms) {
......
}
//主要判断是否发生TCP拥塞避免
getTiming(&tmng);
if (tmng.cwnd >= num_probes_active + .5 &&
(freshPortsLeft() || num_probes_waiting_retransmit || !retry_stack.empty())) {
......
}
if (!when)
return ...
TIMEVAL_MSEC_ADD(earliest_to, USI->now, 10000);
return ...
}
这是HostScanStats::sendOK()简略代码,可以看到每次发一个包前nmap都会作这些判断,其实就是这些判断决定了nmap发包速度。经过分析,这些函数所判断的条件主要就是:判断当前主机是否超时、是否达到最小发包速率、是否通过速度限制检测、是否满足发包延迟要求、是否拥塞。
接下来我们依次来看看这些判断条件的值究竟是从哪里来的,代表着怎样的实际含义,能不能通过nmap扫描参数设置来影响它们,影响它们会带来什么变化。
3.2.1 主机超时
target->timedOut看声明注释:
/* Returns whether the host is timedout. If the timeoutclock is
running, counts elapsed time for that. Pass NULL if you don't have the
current time handy. You might as well also pass NULL if the
clock is not running, as the func won't need the time. */
bool Target::timedOut(const struct timeval *now) {
unsigned long used = htn.msecs_used;
struct timeval tv;
if (!o.host_timeout) return false;
if (htn.toclock_running) {
if (now) tv = *now;
else gettimeofday(&tv, NULL);
used += TIMEVAL_MSEC_SUBTRACT(tv, htn.toclock_start);
}
return (used > o.host_timeout);
}
它就是字面意思,一台主机超时时间。也就是说,如果 nmap
花在这台主机上的时间超过host_timeout全局变量中的值就会终止对它的后续扫描。没错,nmap 扫描的性能参数中有一个--host- timeout的参数,我们如果指定它为1秒,那么一秒后这台主机无论能扫出什么数据都会不再继续,包括进行服务版本探测。可以说这是比较暴力的,特别是对于进行完整TCP连接的服务版本探测。
实验 :


指定进行服务版本探测,最多时间3秒钟,然后三秒之后就立即停止了,并且甚至连前面的端口扫描都没有完成,除了发现了主机在线,没有输出任何后续扫描结果。
用户没设置时默认为0,也就不构成影响。
3.2.2 最小/最大发包速率
/* The requested minimum packet sending rate, or 0.0 if unset. */
float min_packet_send_rate;
全局变量 min_packet_send_rate,也没错,它和nmap扫描参数--min-rate对应,还有一个--max- rate,分别表示用户要求的发包最小最大速度,这是两个强硬指标参数。
-
对于最小发包速率,不管网卡带宽,网卡拥塞程度,nmap会按照自己的计时不顾其他条件(比如设置的发包延迟)来满足这个要求,除非
--min-rate设置太大,cpu和IO跟不上无法满足。 -
对于最大发包速率,可以理解为nmap直接按计时来控制发包速度不超过这个值,在上面函数中没有这个条件判断,但其实它在
doAnyNewProbes的另一个发包判断条件中:USI->gstats->sendOK(NULL),在这不贴出函数源码,和hss->sendOK(NULL)不一样的是,前者针对于一个分组(里面可能有多个主机),后者针对单个主机。在doAnyNewProbes中先判断一个分组发包是否满足发包要求,再判断单个主机发包是否满足要求。
这是用户指定参数,没设置时默认为0,也就不构成影响。
3.2.2.1 最小发包速率实验
我们就拿前面的例子做对比实验,对前面实验的256个IP的100个端口进行扫描:


一秒钟完成了7000多个包的扫描。设置为50000时这个时间又缩短了点,但再往后变大,这个时间就不变了,因为已经达到了IO最大限度:


3.2.2.2 最大发包速率实验
再试试最大发包速率,设置为500


前面需要11秒,现在是14秒这两个时间是很稳定的,可见最大发包速率拖延了整体扫描进度。
3.2.3 速率限制检测
条件rld.rld_waiting,查看声明:
/* To test for rate limiting, there is a delay in sending the first packet
of a certain retransmission number. These values help track that. */
struct rate_limit_detection_nfo {
unsigned int max_tryno_sent; /* What is the max tryno we have sent so far (starts at 0) */
bool rld_waiting; /* Are we currently waiting due to RLD? */
struct timeval rld_waittime; /* if RLD waiting, when can we send? */
};
看这里我没有太理解它的意思,再看看rld_waittime的值来源,在doAnyOutstandingRetransmits()中:
do {
probeI--;
probe = *probeI;
if (probe->timedout && !probe->retransmitted &&
maxtries > probe->tryno && !probe->isPing()) {
/* For rate limit detection, we delay the first time a new tryno
is seen, as long as we are scanning at least 2 ports */
if (probe->tryno + 1 > (int) host->rld.max_tryno_sent &&
USI->gstats->numprobes > 1) {
host->rld.max_tryno_sent = probe->tryno + 1;
host->rld.rld_waiting = true;
TIMEVAL_MSEC_ADD(host->rld.rld_waittime, USI->now, 1000);
} else {
host->rld.rld_waiting = false;
retransmitProbe(USI, host, probe);
retrans++;
}
break; /* I only do one probe per host for now to spread load */
}
} while (probeI != host->probes_outstanding.b 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









