







在MySQL世界中,排序是一个常见而重要的操作。但你是否了解MySQL内部排序的神奇算法?本文将带你深入了解order by语句的几种算法流程,重点详解全字段排序和rowid排序,并对它们的适用场景进行对比分析。
首先来看一下这张思维导图,对本文内容有个直观的认识。

接下来进入正文。
假设有如下表结构:
SQL复制代码CREATE TABLE t (
id int(11) NOT NULL,
city varchar(16) NOT NULL,
name varchar(16) NOT NULL,
age int(11) NOT NULL,
addr varchar(128) DEFAULT NULL,
PRIMARY KEY (id),
KEY city (city)
) ENGINE=InnoDB;
使用存储过程来初始化数据:
SQL复制代码DELIMITER ;;
CREATE PROCEDURE init_t()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE j INT DEFAULT 0;
DECLARE k INT DEFAULT 0;
DECLARE city_list VARCHAR(200) DEFAULT '杭州,上海,武汉,北京';
DECLARE name_len INT DEFAULT 0;
DECLARE city VARCHAR(16);
DECLARE namef VARCHAR(16);
DECLARE age INT;
DECLARE addr VARCHAR(128);
SET name_len = LENGTH('abcdefghijklmnopqrstuvwxyz');
-- 第一层循环:按照city遍历
loop_city: LOOP
SET i = i + 1;
SET city = SUBSTRING_INDEX(SUBSTRING_INDEX(city_list, ',', i), ',', -1); -- 获取城市
-- 第二层循环:生成数据
while(k<=4000) do
SET j = j + 1;
SET namef = CONCAT(
SUBSTR('abcdefghijklmnopqrstuvwxyz', FLOOR(RAND() * name_len) + 1, 1),
SUBSTR('abcdefghijklmnopqrstuvwxyz', FLOOR(RAND() * name_len) + 1, 1),
SUBSTR('abcdefghijklmnopqrstuvwxyz', FLOOR(RAND() * name_len) + 1, 1)
); -- 随机生成姓名
SET age = FLOOR(RAND() * 60) + 18; -- 随机生成年龄
SET addr = CONCAT(
CASE FLOOR(RAND() * 5)
WHEN 0 THEN '杭州市某某区某某街道'
WHEN 1 THEN '上海市某某区某某街道'
WHEN 2 THEN '武汉市某某区某某街道'
ELSE '北京市某某区某某街道' END,
city,
CASE FLOOR(RAND() * 5)
WHEN 0 THEN '西路'
WHEN 1 THEN '东路'
WHEN 2 THEN '南路'
ELSE '北路' END,
FLOOR(RAND() * 100) + 1,
'号'
); -- 随机生成地址
-- 插入数据
INSERT INTO t VALUES(j, city, namef, age, addr);
SET k = k + 1;
end while;
SET k = 0;
IF i = 4 THEN -- 第一层循环结束
LEAVE loop_city;
END IF;
END LOOP loop_city;
END ;;
DELIMITER ;
执行如下 SQL 语句:
SQL复制代码select city,name,age from t where city='杭州' order by name limit 1000;
全字段排序
为避免全表扫描,在 city 字段上创建索引之后,我们用 explain 命令来看看这个语句的执行情况。

Extra 这个字段中的“Using filesort”表示 MySQL 需要进行额外的排序操作,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
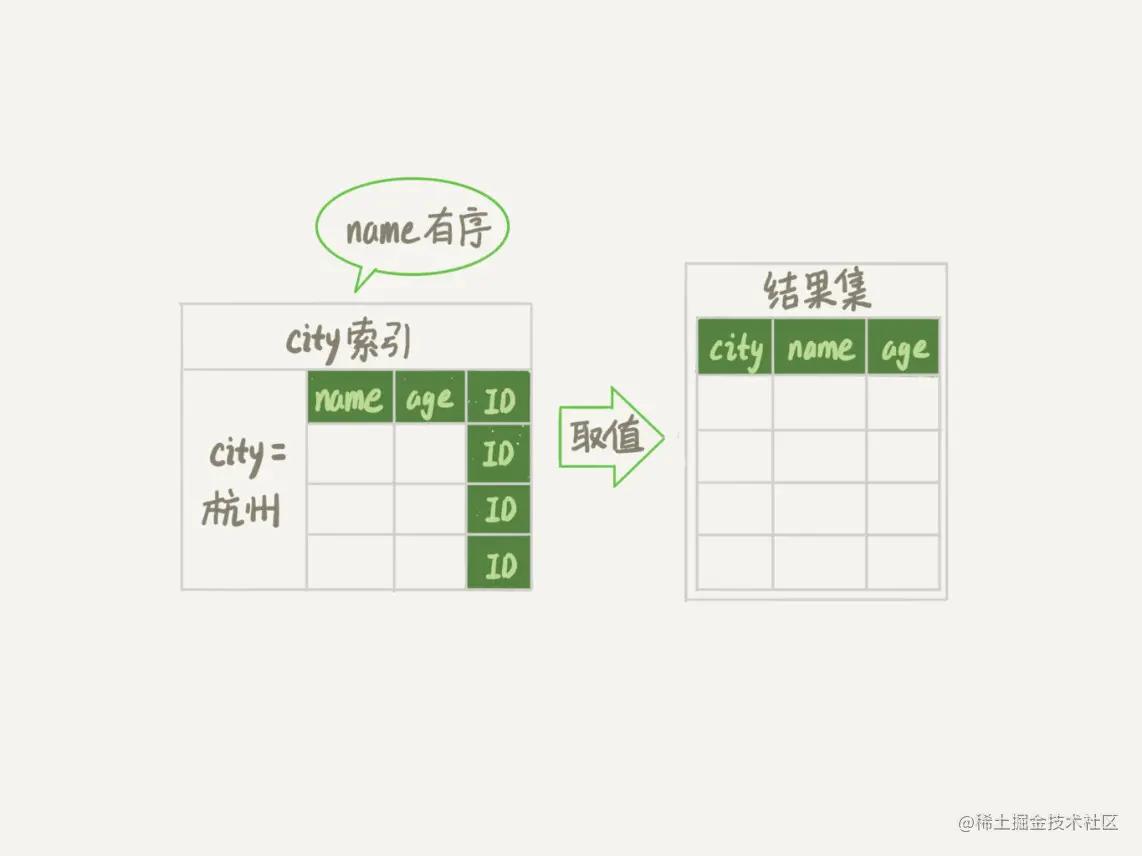
查询示意图如下:

该语句执行流程如下:
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;
- 按照排序结果取前 1000 行返回给客户端。
图中“按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
sort_buffer_size 最小值为:32768,32KB,不能设置为0,默认值为 262144,256KB。所以,一般情况下都会容下 rowid+其他排序字段的。
接下来我们演示如何判断排序语句是否使用了临时文件。
如何确定一个排序语句是否使用了临时文件
SQL复制代码/* 打开optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a保存Innodb_rows_read的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
/* 查看 OPTIMIZER_TRACE 输出 */
select city, name,age from t where city='杭州' order by name limit 1000;
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
/* @b保存Innodb_rows_read的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算Innodb_rows_read差值 */
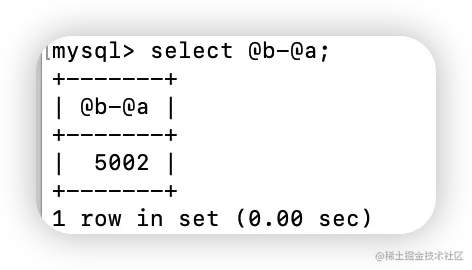
select @b-@a;
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。
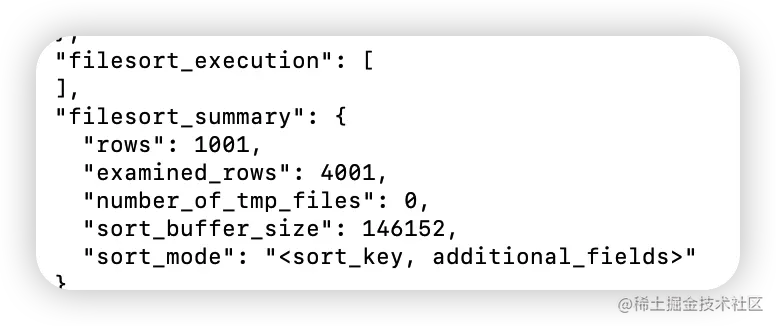
可以看到此时的 number_of_tmp_files 值为0,说明sort_buffer_size 超过了需要排序的数据量的大小,number_of_tmp_files 就是 0,表示排序可以直接在内存中完成。
为了验证临时文件的使用,我们修改 sort_buffer_size 大小,仅在当前会话生效。
SQL复制代码SET sort_buffer_size = 4 * 1024;
全字段排序的 OPTIMIZER_TRACE 部分输出
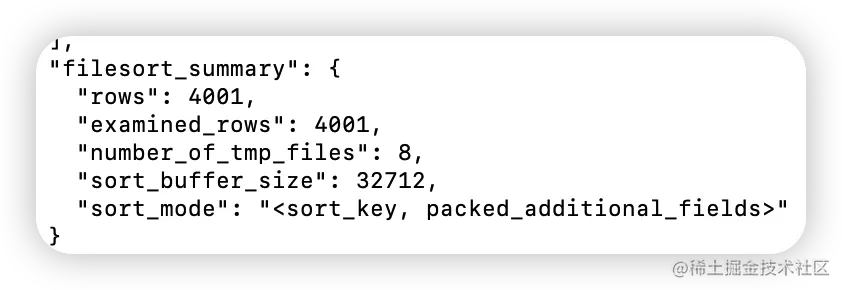
number_of_tmp_files 表示的是,排序过程中使用的临时文件数。内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 8 份,每一份单独排序后存在这些临时文件中。然后把这 8 个有序文件再合并成一个有序的大文件。
上图中的其它参数含义:
- 我们的示例表中有 4001 条满足 city='杭州’的记录,所以你可以看到 examined_rows=4001,表示参与排序的行数是 4001 行。
- sort_mode 里面的 packed_additional_fields 的意思是,排序过程对字符串做了“紧凑”处理。即使 name 字段的定义是 varchar(16),在排序过程中还是要按照实际长度来分配空间的。
最后执行select @b-@a,结果为:
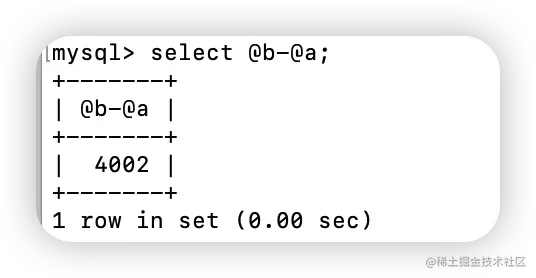
需要注意的是,上述 select @b-@a 的结果显示为 4002,原因如下:
因为查询 OPTIMIZER_TRACE 这个表时,需要用到临时表,而 internal_tmp_disk_storage_engine 的默认值是 InnoDB。如果使用的是 InnoDB 引擎的话,把数据从临时表取出来的时候,会让 Innodb_rows_read 的值加 1。 所以需要把 internal_tmp_disk_storage_engine 设置成 MyISAM。否则,select @b-@a 的结果会显示为 4002。
rowid 排序
全字段排序的缺点是如果查询的字段过多,sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
我们来看看 MySQL 是如何处理的?max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。
city、name、age 这三个字段的定义总长度是 36,那么只需要设置将 max_length_for_sort_data 设置的比 36小一点。
SQL复制代码SET max_length_for_sort_data = 16;
-- 更改sort_buffer的大小
SET sort_buffer_size = 4 * 1024;
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
如下图所示:
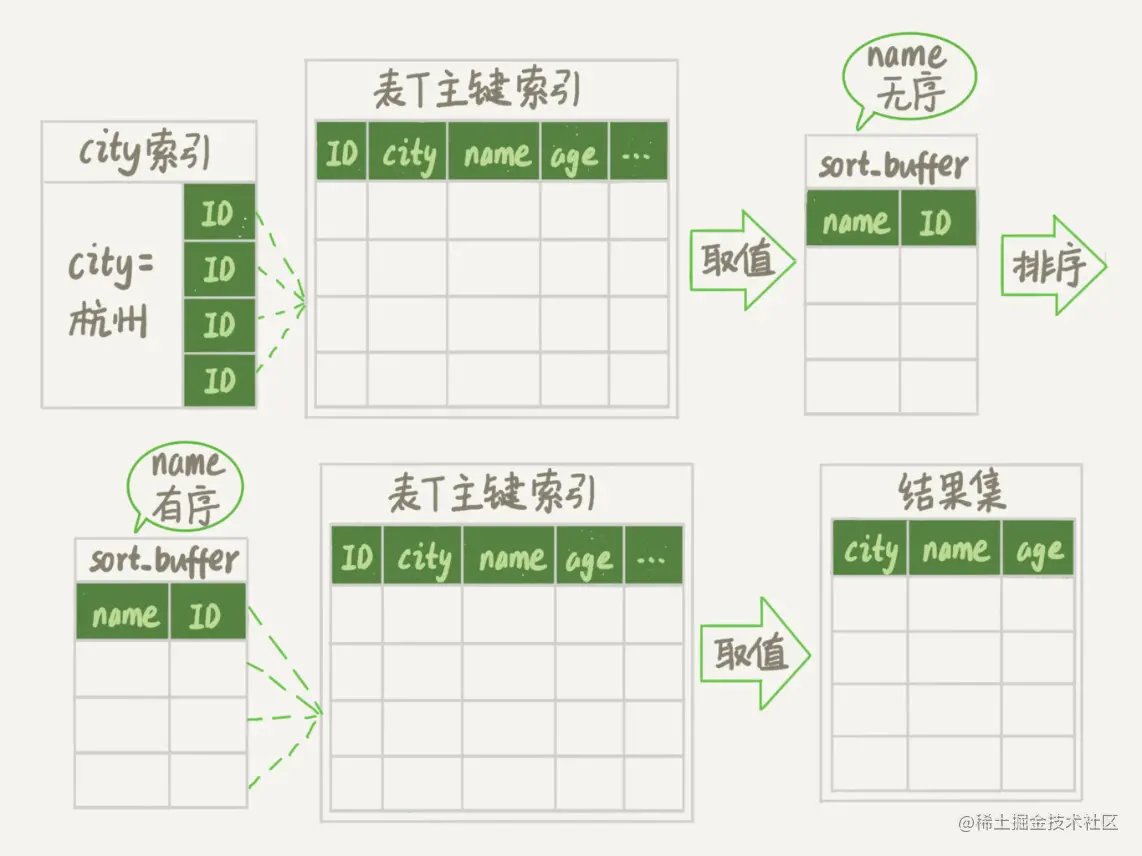
详细执行步骤如下:
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city='杭州’条件为止,也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
该排序算法,称之为 rowid 排序。与全字段排序相比,rowid 排序多访问了一次表 t 的主键索引。
需要说明的是,最后的“结果集”是一个逻辑概念,实际上 MySQL 服务端从排序后的 sort_buffer 中依次取出 id,然后到原表查到 city、name 和 age 这三个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的。
你可以想一下,这个时候执行 select @b-@a,结果会是多少呢?
rowid 排序的 OPTIMIZER_TRACE 部分输出
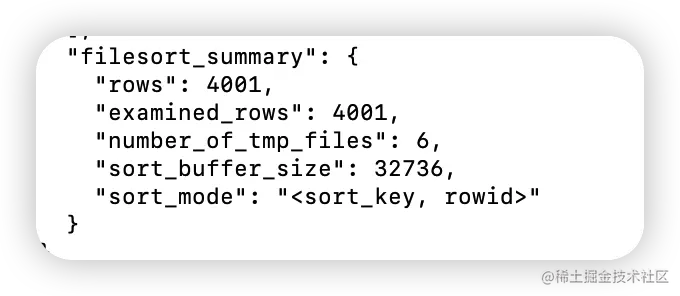
首先,图中的 examined_rows 的值还是 4001,表示用于排序的数据是 4001 行。但是 select @b-@a 这个语句的值变成 5002 了。
因为这时候除了排序过程外,在排序完成后,还要根据 id 去原表取值。由于语句是 limit 1000,因此会多读 1000 行。
从 OPTIMIZER_TRACE 的结果中,你还能看到另外两个信息也变了。
- sort_mode 变成了 sort_key, rowid,表示参与排序的只有 name 和 id 这两个字段。
- number_of_tmp_files 变成 6 了,是因为这时候参与排序的行数虽然仍然是 4001 行,但是每一行都变小了,因此需要排序的总数据量就变小了,需要的临时文件也相应地变少了。
全字段排序 VS rowid 排序
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要回表查询。
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用回表查询。
不管是全字段排序还是 rowid排序,如果仅发生在内存 sort_buffer 中,采用的是快排算法;如果依赖磁盘临时文件,采用的是归并排序。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择;执行全字段排序会减少磁盘访问,因此会被优先选择。
字段索引排序
当然,并不是所有的 order by 语句,都需要排序操作的。从上面分析的执行过程,我们可以看到,MySQL 之所以需要生成临时表,并且在临时表上做排序操作,其原因是原来的数据都是无序的。
如果我们给 name 字段创建索引,效果会变成什么样子:
SQL复制代码alter table t add index idx_name(name);
explain select city,name,age from t where city='杭州' order by name limit 1000;

可以看到 Extra 中仍然存在 Using filesort,name 字段创建索引后不就是有序的吗?
原因在于:在查询时只会遍历 city 索引对数据进行过滤,不会用到 name 列索引,将符合条件的数据返回到server层,在server对数据通过快排算法进行排序,Extra列会出现 filesort;应该利用索引的有序性,在city和name列建立联合索引,这样根据city过滤后的数据就是按照name排好序的(即直接利用索引的顺序),避免在server层排序。
所以仅靠给 name 创建索引是没法保证数据有序的。
如果我们建立一个 city 和 name 的联合索引,对应的 SQL 语句是:
SQL复制代码alter table t add index city_user(city, name);
select city,name,age from t where city='杭州' order by name limit 1000;
查询流程变为这样:
- 从索引 (city,name) 找到第一个满足 city='杭州’条件的主键 id;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name) 取下一个记录主键 id;
- 重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。

原来的查询语句不需要临时表,也不需要排序。接下来,我们用 explain 的结果来印证一下。

从图中可以看到,Extra 字段中没有 Using filesort 了,也就是不需要排序了。而且由于 (city,name) 这个联合索引本身有序,所以这个查询也不用把 4001 行全都读一遍,只要找到满足条件的前 1000 条记录就可以退出了。也就是说,在我们这个例子里,只需要扫描 1000 次。
虽然使用了联合索引(city,name) 可以简化排序,但是由于需要根据主键 id 查询 age 数据(回表查询),所以还有优化的余地。
针对这个查询,我们可以创建一个 city、name 和 age 的联合索引,对应的 SQL 语句就是:
SQL复制代码alter table t add index city_user_age(city, name, age);
select city,name,age from t where city='杭州' order by name limit 1000;
整个查询语句的执行流程就变成了:
- 从索引 (city,name,age) 找到第一个满足 city='杭州’条件的记录,取出其中的 city、name 和 age 这三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
- 重复执行步骤 2,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。
explain 结果如下:

Extra 字段里面多了“Using index”,表示的就是使用了覆盖索引,性能上会快很多。
上述查询语句中需要 city,name,age 三个字段,为了提升排序效率就创建联合索引,但维护索引也是需要代价的,所以需要慎重考虑。
扩展
order by limit使用何种排序?
- 直接利用索引避免排序:用于有索引且回表效率高的情况下
- 快速排序算法:如果没有索引大量排序的情况下
- 堆排序算法:如果没有索引排序量不大的情况下
推荐阅读:MySQL:关于排序order by limit值不稳定的说明
根据时间排序是否会排序?
1、无条件查询如果只有 order by create_time,即便create_time上有索引,也不会使用到。因为优化器认为走二级索引再去回表成本比全表扫描排序更高。所以选择走全表扫描,然后根据具体情况选择全字段排序或是 rowid排序。
SQL复制代码-- 没有索引的情况下
explain select * from t_user_recharge order by f_create_time;

SQL复制代码alter table t_user_recharge add index idx_time(f_create_time);
增加索引后,查看执行计划,仍然走的是全表扫描。

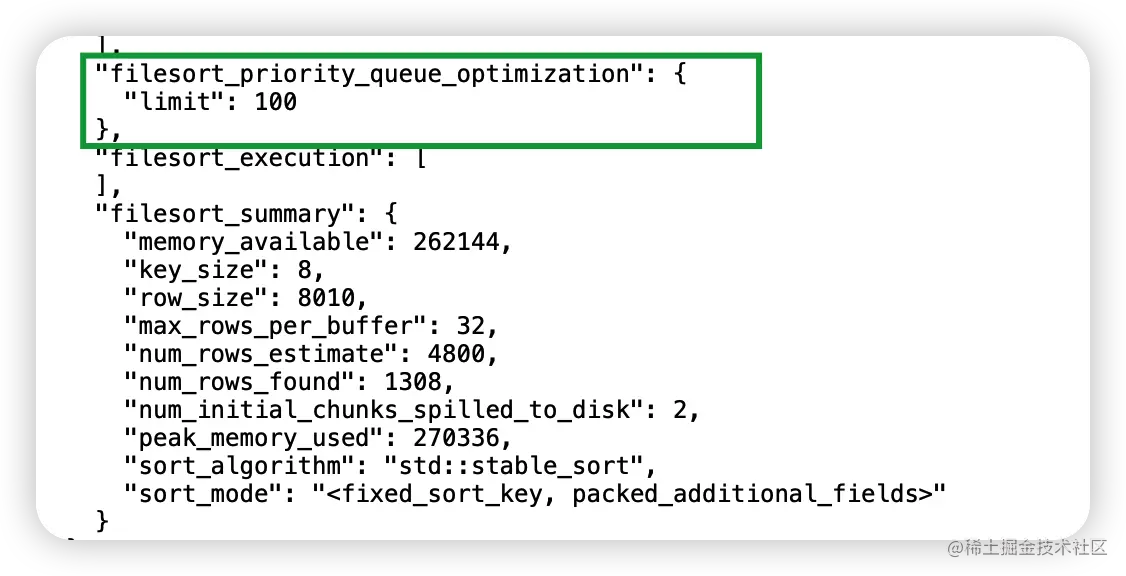
2、无条件查询但是是 order by create_time limit m。如果m值较小,是可以走索引的。因为优化器认为根据索引有序性去回表查数据,然后得到m条数据,就可以终止循环,那么成本比全表扫描小,则选择走二级索引。即便没有二级索引,mysql 针对 order by limit 也做了优化,采用堆排序。
SQL复制代码explain select * from t_user_recharge order by f_create_time limit 10;

SQL复制代码SET optimizer_trace='enabled=on';
select * from t_user_recharge order by f_create_time limit 100;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
查看 OPTIMIZER_TRACE 部分结果如下图所示:
字段加上 group by,如何走排序?
在MySQL中,如果在GROUP BY语句后没有指定排序方式,那么MySQL将按照分组的字段进行升序排序(ASC)。如果需要使用不同的排序方式对结果进行排序,则可以使用ORDER BY子句来指定。
还是以上文的表t作为测试表,来验证下述情况。
1、如果是 group by a,a上不能使用索引的情况,是走 rowid 排序。
SQL复制代码SET optimizer_trace='enabled=on';
select name,count(name) from t group by name;
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
查看 OPTIMIZER_TRACE 部分结果如下图所示:

- 2、如果是 group by a limit,a不能使用索引的情况,是走堆排序。
SQL复制代码SET optimizer_trace='enabled=on';
select name,count(name) from t group by name limit 100;
SELECT * FROM information_schema.OPTIMIZER_TRACE\G

select * from t where city in (“杭州”," 苏州 ") order by name limit 100; 这个 SQL 语句是否需要排序?有什么方案可以避免排序?
虽然有 (city,name) 联合索引,对于单个 city 内部,name 是递增的。但是由于这条 SQL 语句不是要单独地查一个 city 的值,而是同时查了"杭州"和" 苏州 "两个城市,因此所有满足条件的 name 就不是递增的了。也就是说,这条 SQL 语句需要排序。
这里,我们要用到 (city,name) 联合索引的特性,把这一条语句拆成两条语句,执行流程如下:
- 执行 select * from t where city=“杭州” order by name limit 100; 这个语句是不需要排序的,客户端用一个长度为 100 的内存数组 A 保存结果。
- 执行 select * from t where city=“苏州” order by name limit 100; 用相同的方法,假设结果被存进了内存数组 B。
- 现在 A 和 B 是两个有序数组,然后你可以用归并排序的思想,得到 name 最小的前 100 值,就是我们需要的结果了。 ( 不能拘泥于MySQL本身,或者SQL语句本身,完全可以分开获取数据,在应用程序内存里面进行处理 )














 2349
2349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









