



 本文介绍了MySQL如何利用索引优化排序,以及内部排序的四种模式:常规排序、优化排序、打包数据排序和优先队列排序。通过案例分析了排序不一致的问题,并给出了解决方案。重点探讨了外部排序的两路和多路排序算法,并解释了sort_merge_passes参数的意义。
本文介绍了MySQL如何利用索引优化排序,以及内部排序的四种模式:常规排序、优化排序、打包数据排序和优先队列排序。通过案例分析了排序不一致的问题,并给出了解决方案。重点探讨了外部排序的两路和多路排序算法,并解释了sort_merge_passes参数的意义。
前言
排序是数据库中的一个基本功能,MySQL也不例外。用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序。本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个“奇怪”排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因。
一、排序优化与索引使用
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度。下面我通过一些典型的SQL来说明哪些SQL可以利用索引减少排序,哪些SQL不能。假设t1表存在索引key1(key_part1,key_part2),key2(key2)
a.可以利用索引避免排序的SQL
SELECT * FROM t1 ORDER BY key_part1,key_part2;
SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2;
SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC;
SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
b.不能利用索引避免排序的SQL
//排序字段在多个索引中,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1,key_part2, key2;
//排序键顺序与索引中列顺序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part2, key_part1;
//升降序不一致,无法使用索引排序
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
//key_part1是范围查询,key_part2无法使用索引排序
SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
二、排序模式
对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。
MySQL内部实现排序主要有四种模式。
摘录5.7.13中sql/filesort.cc源码如下:
Opt_trace_object(trace, "filesort_summary")
.add("rows", num_rows)
.add("examined_rows", param.examined_rows)
.add("number_of_tmp_files", num_chunks)
.add("sort_buffer_size", table_sort.sort_buffer_size())
.add_alnum("sort_mode",
param.using_packed_addons() ?
"" :
param.using_addon_fields() ?
"" : "");
< sort_key, rowid >”和“< sort_key, additional_fields >看过其他介绍介绍MySQL排序文章的同学应该比较清楚,< sort_key, packed_additional_fields >相对较新。
< sort_key, rowid >对应的是MySQL 4.1之前的“常规排序模式”
< sort_key, additional_fields >对应的是MySQL 4.1以后引入的“优化排序模式”
< sort_key, packed_additional_fields >是MySQL 5.7.3以后引入的进一步优化的”打包数据排序模式”
除上述三种之外,再介绍一个“优先队列排序”:
相对于优化排序模式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
假设表结构和SQL语句如下:
CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), col3 varchar(64), PRIMARY KEY(id),key(col1,col2));
SELECT col1,col2,col3 FROM t1 WHERE col1>100 ORDER BY col2;
2.1.常规排序模式
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用磁盘外部排序,将row id写入到结果文件中;
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).根据结果文件中的row id按序读取用户需要返回的数据,扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO。
2.2.优化排序模式
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式。
2.3.打包数据排序模式
打包数据排序模式的改进仅仅在于将char和varchar字段存到sort buffer中时,更加紧缩。
在之前的两种模式中,存储了“yes”3个字符的定义为VARCHAR(255)的列会在内存中申请255个字符内存空间,但是5.7.3改进后,只需要存储2个字节的字段长度和3个字符内存空间(用于保存”yes”这三个字符)就够了,内存空间整整压缩了50多倍,可以让更多的键值对保存在sort buffer中。
2.4.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
2.5.前三种模式比较
第二种模式是第一种模式的改进,避免了二次回表,采用的是用空间换时间的方法。但是由于sort_buffer就那么大,如果用户要查询的数据非常大的话,很多时间浪费在多次磁盘外部排序,导致更多的IO操作,效率可能还不如第一种方式。
所以,MySQL给用户提供了一个max_length_for_sort_data的参数。当“排序的键值对大小” > max_length_for_sort_data时,MySQL认为磁盘外部排序的IO效率不如回表的效率,会选择第一种排序模式;反之,会选择第二种不回表的模式。
第三种模式主要是解决变长字符数据存储空间浪费的问题,对于实际数据不多,字段定义较长的改进效果会更加明显。
很多文章写到这里可能就差不多了,但是大家忘记关注一个问题了:“如果排序的数据不能完全放在sort buffer内存里面,是怎么通过外部排序完成整个排序过程的呢?”
要解决这个问题,我们首先需要简单查看一下外部排序到底是怎么做的。
三、外部排序
3.1 普通外部排序
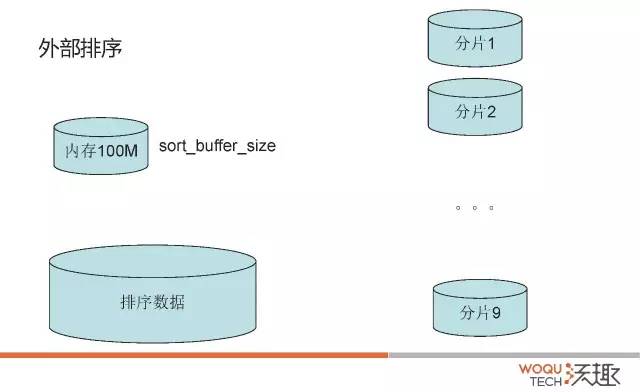
3.1.1 两路外部排序
我们先来看一下最简单,最普遍的两路外部排序算法。
假设内存只有100M,但是排序的数据有900M,那么对应的外部排序算法如下:
从要排序的900M数据中读取100MB数据到内存中,并按照传统的内部排序算法(快速排序)进行排序;
将排序好的数据写入磁盘;
重复1,2两步,直到每个100MB chunk大小排序好的数据都被写入磁盘;
每次读取排序好的chunk中前10MB(= 100MB / (9 chunks + 1))数据,一共9个chunk需要90MB,剩下的10MB作为输出缓存;
对这些数据进行一个“9路归并”,并将结果写入输出缓存。如果输出缓存满了,则直接写入最终排序结果文件并清空输出缓存;如果9个10MB的输入缓存空了,从对应的文件再读10MB的数据,直到读完整个文件。最终输出的排序结果文件就是900MB排好序的数据了。
3.1.2 多路外部排序
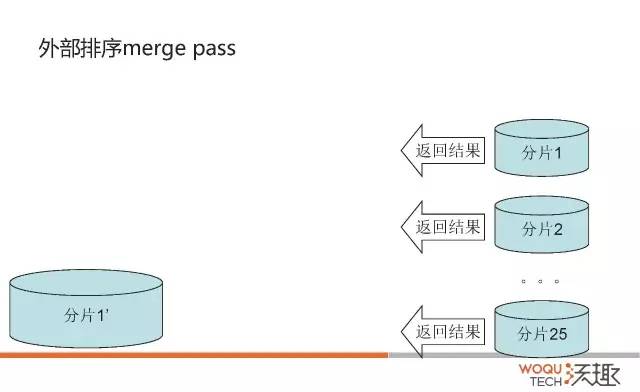
上述排序算法是一个两路排序算法(先排序,后归并)。但是这种算法有一个问题,假设要排序的数据是50GB而内存只有100MB,那么每次从500个排序好的分片中取200KB(100MB / 501 约等于200KB)就是很多个随机IO。效率非常慢,对应可以这样来改进:
从要排序的50GB数据中读取100MB数据到内存中,并按照传统的内部排序算法(快速排序)进行排序;
将排序好的数据写入磁盘;
重复1,2两步,直到每个100MB chunk大小排序好的数据都被写入磁盘;
每次取25个分片进行归并排序,这样就形成了20个(500/25=20)更大的2.5GB有序的文件;
对这20个2.5GB的有序文件进行归并排序,形成最终排序结果文件。
对应的数据量更大的情况可以进行更多次归并。
3.2 MySQL外部排序
3.2.1 MySQL外部排序算法
那MySQL使用的外部排序是怎么样的列,我们以回表排序模式为例:
根据索引或者全表扫描,按照过滤条件获得需要查询的数据;
将要排序的列值和row ID组成键值对,存入sort buffer中;
如果sort buffer内存大于这些键值对的内存,就不需要创建临时文件了。否则,每次sort buffer填满以后,需要直接用qsort(快速排序模式)在内存中排好序,作为一个block写到临时文件中。跟正常的外部排序写到多个文件中不一样,MySQL只会写到一个临时文件中,并通过保存文件偏移量的方式来模拟多个文件归并排序;
重复上述步骤,直到所有的行数据都正常读取了完成;
每MERGEBUFF (7) 个block抽取一批数据进行排序,归并排序到另外一个临时文件中,直到所有的数据都排序好到新的临时文件中;
重复以上归并排序过程,直到剩下不到MERGEBUFF2 (15)个block。
通俗一点解释:
第一次循环中,一个block对应一个sort buffer(大小为sort_buffer_size)排序好的数据;每7个做一个归并。
第二次循环中,一个block对应MERGEBUFF (7) 个sort buffer的数据,每7个做一个归并。
…
直到所有的block数量小于MERGEBUFF2 (15)。
最后一轮循环,仅将row ID写入到结果文件中;
根据结果文件中的row ID按序读取用户需要返回的数据。为了进一步优化性能,MySQL会读一批row ID,并将读到的数据按排序字段要求插入缓存区中(内存大小read_rnd_buffer_size)。
这里我们需要注意的是:
MySQL把外部排序好的分片写入同一个文件中,通过保存文件偏移量的方式来区别各个分片位置;
MySQL每MERGEBUFF (7)个分片做一个归并,最终分片数达到MERGEBUFF2 (15)时,做最后一次归并。这两个值都写死在代码中了……
3.2.2 sort_merge_passes
MySQL手册中对Sort_merge_passes的描述只有一句话
Sort_merge_passes
The number of merge passes that the sort algorithm has had to do. If this value is large, you should consider increasing the value of the sort_buffer_size system variable.
这段话并没有把sort_merge_passes到底是什么,该值比较大时说明了什么,通过什么方式可以缓解这个问题。
我们把上面MySQL的外部排序算法搞清楚了,这个问题就清楚了。
其实sort_merge_passes对应的就是MySQL做归并排序的次数,也就是说,如果sort_merge_passes值比较大,说明sort_buffer和要排序的数据差距越大,我们可以通过增大sort_buffer_size或者让填入sort_buffer_size的键值对更小来缓解sort_merge_passes归并排序的次数。
对应的,我们可以在源码中看到证据。
上述MySQL外部排序的算法中第5到第7步,是通过sql/filesort.cc文件中merge_many_buff()函数来实现,第5步单次归并使用merge_buffers()实现,源码摘录如下:
int merge_many_buff(Sort_param *param, Sort_buffer sort_buffer,
Merge_chunk_array chunk_array,
size_t *p_num_chunks, IO_CACHE *t_file)
{
...
for (i=0 ; i < num_chunks - MERGEBUFF * 3 / 2 ; i+= MERGEBUFF)
{
if (merge_buffers(param, // param
from_file, // from_file
to_file, // to_file
sort_buffer, // sort_buffer
last_chunk++, // last_chunk [out]
Merge_chunk_array(&chunk_array[i], MERGEBUFF),
0)) // flag
goto cleanup;
}
if (merge_buffers(param,
from_file,
to_file,
sort_buffer,
last_chunk++,
Merge_chunk_array(&chunk_array[i], num_chunks - i),
0))
break; /* purecov: inspected */
...
}
截取部分merge_buffers()的代码如下,
int merge_buffers(Sort_param *param, IO_CACHE *from_file,
IO_CACHE *to_file, Sort_buffer sort_buffer,
Merge_chunk *last_chunk,
Merge_chunk_array chunk_array,
int flag)
{
...
current_thd->inc_status_sort_merge_passes();
...
}
可以看到:每个merge_buffers()都会增加sort_merge_passes,也就是说每一次对MERGEBUFF (7)个block归并排序都会让sort_merge_passes加一,sort_merge_passes越多表示排序的数据太多,需要多次merge pass。解决的方案无非就是缩减要排序数据的大小或者增加sort_buffer_size。
打个小广告,在我们的qmonitor中就有sort_merge_pass的性能指标和参数值过大的报警设置。
四、排序不一致问题案例
4.1.案例1
Mysql从5.5迁移到5.6以后,发现分页出现了重复值。
测试表与数据:
create table t1(id int primary key, c1 int, c2 varchar(128));
insert into t1 values(1,1,'a');
insert into t1 values(2,2,'b');
insert into t1 values(3,2,'c');
insert into t1 values(4,2,'d');
insert into t1 values(5,3,'e');
insert into t1 values(6,4,'f');
insert into t1 values(7,5,'g');
假设每页3条记录,第一页limit 0,3和第二页limit 3,3查询结果如下:

我们可以看到 id为4的这条记录居然同时出现在两次查询中,这明显是不符合预期的,而且在5.5版本中没有这个问题。产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by c1 asc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于c1为2的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上唯一值,比如主键id,这样由于id是唯一的,确保参与排序的key值不相同。将SQL写成如下:
select * from t1 order by c1,id asc limit 0,3;
select * from t1 order by c1,id asc limit 3,3;
4.2.案例2
两个类似的查询语句,除了返回列不同,其它都相同,但排序的结果不一致。
测试表与数据:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1));
insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255));
insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255));
insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255));
insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255));
insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255));
insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255));
insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分别执行SQL语句:
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status;
select id,status from t2 force index(c1) where c1>='b' order by status;
执行结果如下:

看看两者的执行计划是否相同

为了说明问题,我在语句中加了force index的hint,确保能走上c1列索引。语句通过c1列索引捞取id,然后去表中捞取返回的列。根据c1列值的大小,记录在c1索引中的相对位置如下:
(c1,id)===(b,6),(b,3),(c,5),(c,2),对应的status值分别为2 3 2 4。从表中捞取数据并按status排序,则相对位置变为(6,2,b),(5,2,c),(3,3,c),(2,4,c),这就是第二条语句查询返回的结果,那么为什么第一条查询语句(6,2,b),(5,2,c)是调换顺序的呢?这里要看我之前提到的a.常规排序和b.优化排序中标红的部分,就可以明白原因了。由于第一条查询返回的列的字节数超过了max_length_for_sort_data,导致排序采用的是常规排序,而在这种情况下MYSQL将rowid排序,将随机IO转为顺序IO,所以返回的是5在前,6在后;而第二条查询采用的是优化排序,没有第二次捞取数据的过程,保持了排序后记录的相对位置。对于第一条语句,若想采用优化排序,我们将max_length_for_sort_data设置调大即可,比如2048。

转自:
https://www.cnblogs.com/cchust/p/5304594.html
http://geek.csdn.net/news/detail/105891

















 2990
2990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









