







温馨提示:
白底为例子
绿底为注释解析
---文章有点长,可通过左侧目录跳转功能辅助阅读
进制转换:
任意进制 ----》 十进制 : 权位相加
十进制 ----》 任意进制 : 除以该进制数,逆向取余
变量、常量数据类型:
基本类型
整型常量:
二进制(0b,0B) 八进制(0) 十进制 十六进制(0x,0X)
整型变量:
signed char unsigned char 1个字节
(signed) short unsigned short 2个字节
(signed) int unsigned int 4个字节
(signed) long unsigned long 4/8
(signed) long long unsigned long long 8
signed char uc = 10;
short s = 0x12;
int i = 012;
long l = 0b10101011;
整型的存储:
以补码的形式保存在计算机中 (原码 反码 补码)
浮点型常量:
12.5 12.5e4
浮点型变量:
float 4 个字节
double 8个字节
float f = 12.5;
double d = 12.5e4;
字符型常量:
直接是打印了字符
'a' '\a' '\r' '\\' '\n' '\ddd' '\xdd'
字符型变量:
char
char c = 'a';
char c = 97 ; //最高位是0 确定一定是正数 字符的最高位都是 0
char c = 202; //最高位为1 ,无法确定正数还是负数,已经超出了字符的范围,该写法可能有问题
若为signed char c = 202; //一定是负数
字符串常量:
一个一个字符组成,最后以 '\0' 结束
"abc" // 4个字符
符号常量:(宏定义)
#define PI 3.14
类型转换: 强制转换/自动转换
自动转换
由低精度向高精度转换,数据基本不会丢失
隐式类型转换(“小”类型向“大”类型转换)
signed char /char ---> unsigned char ---> short ---> unsigned short
----> int ----> unsigned int ---> long ----> unsigned long --->
long long ---> unsigned long long ---> float ---> double ---> long double
short s = 20; //在内存中占用2个字节空间,该空间命名为s,cpu将int类型的20自动转换为short类型的20 存入s空间 中
int i = 12.5; //在内存中占用4个字节空间,该空间命名为i,cpu将doule类型的12.5自动转换为int类型的12 存入i空间 中
强制转换
由高精度向低精度转换,数据可能丢失
类型1 变量1;
类型2 变量2 = (类型2)变量1;
例子:
short s = 0x1122;
short *pp;
int *p = (int *)pp;
格式化输入输出
输出
printf
#include <stdio.h>
int printf(const char *format, ...);
printf是可以四舍五入的
format:(常用)
%d : 以 int 类型的方式打印
%hd: 以 short 类型的方式打印
%hhd : 以 signed char 类型的方式 打印
%ld : 以 long 类型的方式打印
%lld: 以 long long 类型的方式打印
%u : 以 unsigned int 类型的方式打印
%hu: 以 unsigned short 类型的方式打印
%hhu : 以 unsigned char 类型的方式 打印
%lu: 以 unsigned long 类型的方式打印
%llu : 以 unsigned long long 类型的方式打印
%c : 以 char 类型的方式 打印
%s : 输出字符串“china”printf(“%s”,“china”);
%f : 以 float 类型方式打印 (保留6位小数)
%lf : 以 double 类型的方式打印 (保留6位小数)
%e/E : 以浮点型指数形式打印
%o : 以 八进制 方式 打印 不带标志
%x/X : 以 16进制 方式 打印 不带标志
%#o : 以 八进制 方式 打印 带标志
%#x/X : 以 16进制 方式 打印 带标志
%g : 以浮点型打印
%G : 以浮点型打印
* 特殊显示:
printf("%md",);
…………………………
m : 显示的宽度 ,如果m无法正确表达数据宽度,则无效
printf("%10d",12345);
m是一个正数 ,右对齐,显示的宽度为10
开始位置: 12345
printf("%-10d",12345);
m是一个负数 ,左对齐,显示的宽度为10
m可以省略
===================================
printf("%m.nf");
…………………………
m : 显示的宽度 ,如果m无法正确表达数据宽度,则无效
n : 保留的小数位数
m和n都可以省略
===================================
printf("%*.*f");
…………………………
printf("%*.*f\n",20,2,12.456789);
====> 12.46 右对齐,显示的宽度为20
===================================
printf("%*d",m);
…………………………
那么m就会作为参数传入
printf("%*d \n",10,12345);
===> 12345 右对齐,显示的宽度为10
===================================
printf("%.*f");
…………………………
printf("%.*f\n",2,12.456789);
====> 12.46 右对齐
===================================
printf("%*f");
…………………………
printf("%*f\n",20,12.456789);
====> 12.456789 右对齐,显示的宽度为20
===================================
输入
scanf : 从键盘输入
#include <stdio.h>
int scanf(const char *format, ...);
…………………………
format:
int a;
scanf("%d",&a);
阻塞等待键盘输入 ,当输入了int类型的值,将该值存入a地址中
format错误写法:
scanf("%d\n",&a);
=============相关拓展=================
stdin :0
标准输出流 -- 屏幕
stdout:1
标准输入流 -- 键盘
stderr:2
标准错误流 -- 屏幕
============一些相关的库函数=================
getchar
只能读取用户输入缓存区的一个字符,包括回车
从键盘去读取一个字符
#include <stdio.h>
int getchar(void);
putchar
给屏幕发送一个字符
#include <stdio.h>
int putchar(int c);
====================================
运算符
运算顺序:
括单术,移关位,逻三赋逗
括: 括号: () [] -> .
单: 单目: ++ -- ! ~ & * (强转) sizeof()
只能修饰某一个内存空间:int a=20,b=10;b++; (a+b)++; //不正确,因为a+b不是内存中的一块空
===================================
sizeof() :不是函数,是个关键字,用于求字节数
例子:
int a = 10;
sizeof(a); // 通过变量a去得到它的类型,然后通过类型知道其字节数
sizeof(int);
术: 算术: + - * / %
%只能用于整数之间并且前后必须是整数
移: 移位: << >>
将值取出来,放入32位cpu寄存器中,cpu将其移位,得到一个新的值
32位cpu寄存器:
(......|......|......|......|32768 16384 8192 4096 | 2048 1024 512 256 | 128 64 32 16 | 8 4 2 1)
关: 关系: > >= < <= == !
==判断真假而=是赋值
===================================
位:位运算: & | ^ ~
位与&: 相同位置上的数据 都是1 结果才是 1
int a = 121;
int b = 250;
a : 00000000 00000000 00000000 01111001
b : 00000000 00000000 00000000 11111010 &
================================================
00000000 00000000 00000000 01111000 ===> 120
位或 | 同一位置上的数据,有1则为1
int a = 121;
int b = 250;
a : 00000000 00000000 00000000 01111001
b : 00000000 00000000 00000000 11111010 |
================================================
00000000 00000000 00000000 11111011 ===》 251
异或 ^ : 同一位置上的数据 不同 则为 1
int a = 121;
int b = 250;
a : 00000000 00000000 00000000 01111001
b : 00000000 00000000 00000000 11111010 ^
================================================
00000000 00000000 00000000 10000011 ===> 131
取反 ~ : 对某一个表达式的值,二进制数 0变1 1变0
int a = 121;
a : 00000000 00000000 00000000 01111001
============================================
~a: 11111111 11111111 11111111 10000110
反码: 11111111 11111111 11111111 10000101
原码: 10000000 00000000 00000000 01111010 ==》 -122
逻: 逻辑: && || // 逻辑运算 有智能算法
例子:
int a=10,b=20;
a+b && a-b || a+b && a++ || a-- && b;
1&&1 ||1 &&1||1&&1 1
三: 三目: ? :
表达式1 ? 表达式2 : 表达式3
表达式1成立则选择表达式2
表达式1不成立,则选择表达式3
赋: 赋值: = += -= *= /= ....
int a = 10;
a = a+1; ===> 简写为: a+=1;
逗: 逗号: ,
控制流
顺序结构 (程序一行一行往下走)
程序一行一行从上到下从左往右往下走
分支结构 (if,switch)
if 语句:
表达式成立则执行语句A
表达式不成立则不执行语句A
if 和 程序块 结合
表达式情况如下:
一选一
if(条件表达式)
{
//代码;
}
二选一
if else 和 程序块 结合:
if(条件表达式)
{
//代码;
}else
{
//代码;
}
多选一
if(条件表达式1)
一条语句A ;
else if(条件表达式2)
一条语句B ;
else if(条件表达式3)
一条语句C ;
else if(条件表达式4)
一条语句D ;
.....
else
//代码;
解释:
判断表达式1,如果成立,则执行语句A ,整个if都结束了
判断表达式1,如果不成立,去判断表达式2 ....
if else if else 和代码块 结合
if(条件表达式1)
{
}
else if(条件表达式2)
{}
else if(条件表达式3)
{}
else if(条件表达式4)
{}
.....
else
{}
switch语句:
选项 只能是 整数(字符)
选项值不能重复
表达式的值是多少,就会去下面选择该值选项,将其下的语句执行
如果没有选项匹配,就执行 default , default 可以省略
break : 和 switch 结合 ,结束 switch 语句
表达式如下:
switch(表达式)
{
case 选项:
多条语句;
break;
case 选项:
多条语句;
break;
case 选项:
多条语句;
break;
case 选项:
多条语句;
break;
case 选项:
多条语句;
break;
default :
多条语句;
break;
}
循环结构 (for,while,do while)
for循环语句:
for 要和 代码块(程序块) 结合
for(赋值表达式1;判断表达式3;赋值表达式2)
{
}
for 循环中的三个表达式都可以省略
当判断表达式3省略之后,代表死循环 for(;;);
第一步:执行 赋值表达式1
第二步:判断表达式3 的真假
如果是真,则继续往下执行
如果是假,则退出for循环
第三步:执行一条语句A
第四步:执行赋值表达式2 ,然后再去执行 第二步
continue :
continue 和 for 循环联合使用, continue 可以立马结束 所在的for循环的当次循环(立马结束了代码块),进入到下一次循环中
即结束for循环中的“当前”循环轮次,直接跳到下一轮for的循环轮次
break :
break 和 for 循环联合使用, break 可以结束 其所在 的 for 循环
while循环语句:
while里面不要定义变量,不然会瞬间爆炸
while 和 代码块 结合 :
while(表达式)
{
}
continue:
continue 和 while 配合 :
continue 结束当次循环(结束代码块(语句)),进入到下一次循环中
break :
break 和 while 配合:
break 结束 所在的 while 循环
while(1)
{
while(2)
{
while(3)
{
}
break; //结束 while(2)
}
}
do while :
do
一条语句A;
while(表达式);
先 执行 语句A
再去判断 表达式 是否成立
do while 和 代码块结合
do
{
很多条语句;
}while(表达式);
goto跳转
这个跳转少用
goto可以理解为一个标签
标签:语句;
当程序遇到goto 标签,程序就会跳转到标签所在的位置执行
注意!标签不能重复
万不得已的情况:
for(1)
{
for(2)
{
for(3)
{
if(出错1)
goto error1;
else if(出错2)
goto error2;
}
}
}
error1 :
printf("this is error1\n");
return;
error2:
printf("this is error2\n");
return;
goto 语句的 标签 只在 同一个 函数中 有效
函数
函数是一组一起执行一个任务的语句
int main(void) 返回值类型 函数名字(函数参数)
{ {
return 0; 函数体;
} return 返回值;
}
例子
干炒牛河类型 炒它(牛肉,河粉) // 形参
{
疯狂翻炒;
return 干炒牛河;
}
干炒牛河类型 bb = 炒干炒牛河(牛肉,河粉);
===============详细介绍=====================
函数的名字- - - - - - - - - - -----------------------------------------------
函数的名字就是函数的首地址
函数的名字遵循标识符的命名规则
标识符- - - - - - - - - - - - - -----------------------------------------------
浮点型常量:小数形式,指数形式
浮点型变量: float double long double
float 存储: 1 8 23
double 存储: 1 11 52
字符型常量:可见字符 不可见字符 转义字符
字符型变量: char signed char unsigned char
字符串常量:"abc" ==> 'a' 'b' 'c' '\0'
符号常量: 宏定义 #define
函数的参数(形参)- - - - - - - ----------------------------------------------
函数的参数:
称之为 形参 是一个列表
例子:int a,int b,int c
如果没有形参,写一个 void 或者省略不写
函数体- - - - - - - - - - - - ------------------------------------------------
函数体:
实现函数的具体功能的
return - - - - - - - - - - - - ------------------------------------------------
return :
表示 函数的 返回 ,其后 跟随的 数值 必须 与 返回值类型 相呼应
如果不需要返回,return 后面不跟随任何东西 return; 或者return省略不写
return : 结束函数的意思
返回值类型- - - - - - - - - - -----------------------------------------------
返回值类型:
函数调用之后会返回的数据的类型
如果不需要返回,则 返回值类型 给 void
* 调用函数:
函数名称(实参);
函数声明- - - - - - - - - - - ------------------------------------------------
函数声明:
告诉编译器,我有该函数,避免编译器警告
直接将函数的定义拷贝上去,后面加一个 分号即可
例子:
int sum(int a,int b)
{
int s = a + b;
return s;
}
声明函数:
int sum(int a,int b);
或者:
int sum(int,int);
局部变量、全局变量 - - - - ------------------------------------------------
局部变量(在后续的指针中涉及野指针):
定义在函数内部的变量,
如果没有给该变量赋初始值,那么该变量里面保存的是 垃圾值
只在该函数中有效,随着函数的消亡而消亡
全局变量:
定义在函数外面的变量
如果没有给该变量赋初始值,那么该变量里面保存的是 0 或者 NULL
在整个.c文件中有效,不会随着函数的消亡而消亡的,只有在程序结束的时候才结束
值传递、址传递- - - - - - - ------------------------------------------------
值传递:就是将 变量的 值 传递给 别的函数(形参)
址传递:将变量取地址 传递给 别的函数(形参)
总的来说- - - - - - - - - - - ------------------------------------------------
函数的定义:(造模型)
int sum(int a,int b)
{
return a+b;
}
函数的声明:
int sum(int a,int b);
函数的调用:
sum(10,20);
============一些常用的库函数以及关键字=============
strlen------s的字节长度("\0"前结束)
#include <string.h>
size_t strlen(const char *s);
计算s的长度(字节数),碰到'\0'才结束,不包含'\0'
参数:其中s是指针(数组)
返回值:size_t:unsigned long //s中字符的个数
strcmp------比较s1与s2
#include <string.h>
int strcmp(const char *s1, const char *s2);
int strncmp(const char *s1, const char *s2, size_t n);
将s1 和 s2 进行比较 ,返回一个 小于 等于 大于0 的数
char s1[10] = "ILXVEU";
char s2[10] = "ILOVEU";
strcmp(s1,s2);
先从左往右,对应字符进行比较,如果相等继续往后,如果不相等,就停下来结束,返回
返回值:
char s1[10] = "ILOVEU";
char s2[10] = "ILOVEU";
如果两个完全相等,返回0
char s1[10] = "ILXVEU";
char s2[10] = "ILOVEU";
X比O大,s1比s2大,返回大于0的数
char s1[10] = "ILAVEU";
char s2[10] = "ILOVEU";
A比O小,s1比s2小,返回小于0的数
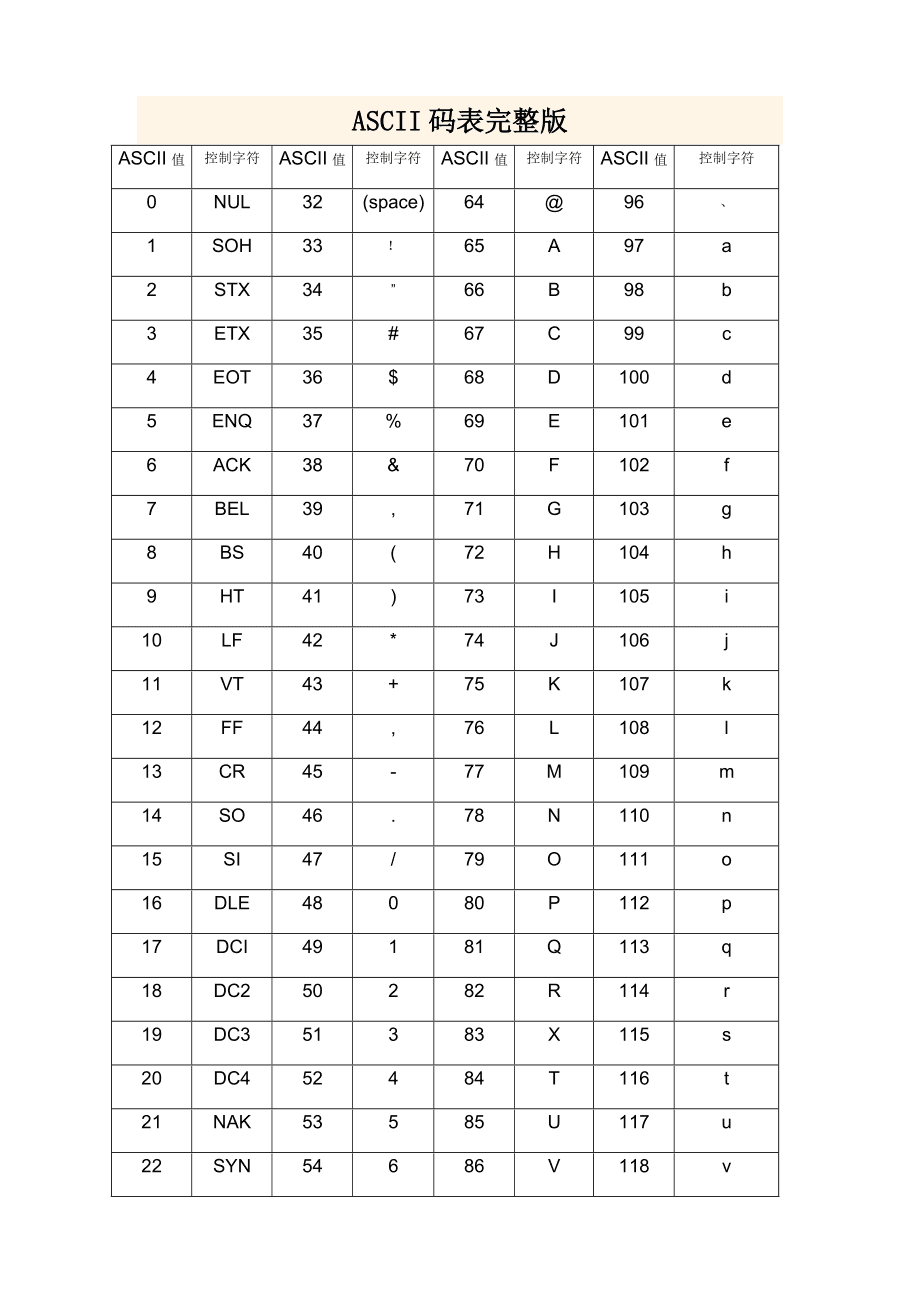
strcpy------s在d中(前,即从下标为0开始)
#include <string.h>
char *strcpy(char *dest, const char *src);
char *strncpy(char *dest, const char *src, size_t n);
将字符串src包含'\0' 拷贝到 dest 中 (从下标为0开始)
dest的容量要比src大
参数: dest 为 目标字符串 src 为 源字符串
返回值: dest
strcat------s在d后
#include <string.h>
char *strcat(char *dest, const char *src);
char *strncat(char *dest, const char *src, size_t n);
将src追加到 dest 的后面 ,覆盖dest 的 '\0'
dest 必须足够大
参数: dest 为 目标字符串 src 为 源字符串
返回值: dest
bzero------s前n字节,用0填充
#include <string.h>
void bzero(void *s, size_t n);
将s的前n个字节用 0 '\0' 来填充
参数: s 为 void * n 为字节个数
其中void * : 万能指针 (小心使用)
任何类型的指针都可以直接赋值给它,无需进行强制类型转换
例子:
int a = 10;
short b = 20;
long c = 30;
int *p = &a;
short *pp = &b;
long *ppp = &c;
void *xx = p;
xx = pp;
xx = ppp;
char *xp = (char *)xx;
memset------s前n字节用c的最后一个字节替换
#include <string.h>
void *memset(void *s, int c, size_t n);
将s 中 的前 n个字节 用 c 来填充 (用c的最后一个字节替换)
参数: 返回值为返回s n为字节数
bool------做判断
#include <stdbool.h>
bool isXX = true;
bool isYY = false;
-- -- --关键字 -- -- --
const------不变的
不变的意思
const int a = 10;
const修饰的a 不能以 a=20; 来修改a空间,可以以其他方式来修改
int b = 20;
const int *p = &b;
const修饰的是 *p 代表不能以 *p = 30 这种方式 来修改值,p的值是可以改的
int c = 30;
int d = 40;
int * const p = &c;
const 修饰的是p 所以 p = &d 是不被允许的
int a = 10;
int b = 20;
const int * const p = &a;
*p = 40; 不被允许
p = &b; 不被允许
volatile-----易变的
阻止编译器优化
volatile int a;
int b = a;
int c = a;
int d = a;
保证一直取得a的值放入到cpu内存当中
typedef------取别名
取别名
typedef 某类型 别名;
typedef int xx; // 从此以后,xx就是一个类型,一个int类型
xx a; // int a;
typedef int *a; //a 代表 int *类型
a b; // int *b;
int a,*b,c; // int a; int *b; int c;
typedef int a,*b,c;
===> typedef int a; typedef int * b; typedef int c;
define------宏定义
#define PI 3.14
#define XX int
XX a; //int a;
XX b; // int b;
typedef和define的区别
typedef int *yy;
#define tt int *
yy a,b,c; === yy a; yy b; yy c; ===> int *a; int *b; int *c;
tt a,b,c; int * a,b,c; ===> int *a; int b; int c;
==========================================
数组
存储同一种任意类型的数据
存储的类型 数组名字[元素个数]; short arr[20];
数组的名字就是数组的首地址
数组有一维数组,二维数组多维数组等等
arr 的两个类型:
数组类型:short [10]
指针类型:将其作为一维数组来看待,其所谓的第一个元素的地址就是arr的值
当你要是使用arr里面 保存的值 的时候,就是指针类型,其他情况就是数组类型
short arr[10]={1,2,3,4,5,6,7,8,9,0};
arr : short [10];
arr + 1; short * + 1
以short *p = arr ;为例
数组名字 的 值 不允许发生 改变
arr++ ; ----》 这是错误的
p++; 没有问题
指针和数组的加减运算
int * 加或者减 一个 数字的时候,跳过n的管辖范围
short * + n ===> short * + n个short 字节数
short * : 0x11223344
short * + 2 ===》 short * + 2个short字节数
===》 short * + 4个字节
===》 0x11223348
short * 指向 一个 short ,称该地址 管辖 该空间
short * + n ===》 跳过n个管辖空间 ,跳过n*short 个字节
long long * + 3 ===》 跳过24个字节
字符数组
char arr[5];
赋值
char arr[5];
arr[0] = 'a';
初始化
非完全初始化
char arr[5]={'a'}; // 下标为0的是'a' 其他全部都是数字0 也就是 '\0'
char arr[5]={[1]='b',[2]='c'};
char arr[5]="abc"; 'a' 'b' 'c' '\0' '\0'
完全初始化
char arr[5]={'a','b','c','d','e'};
char arr[] = {'a','b','c','d','e'};
char arr[5]="abcd"; 'a' 'b' 'c' 'd' '\0'
数组传参
一维数组传参:
int arr[5];
fun(arr);
===>
fun(int *p){ }
fun(int p[ ]){ }
fun(int p[5]){ }
二维数组传参:
int arr[2][3]; ===> arr: 指针: int (*)[3]
fun(arr);
===>
fun(int (*p)[3]){ }
fun(int p[ ][3]){ }
fun(int p[2][3]){ }
四维数组传参:
int arr[2][3][4][5]; // int (*)[3][4][5]
fun(arr);
===>
fun(int (*p)[3][4][5]){ }
fun(int p[ ][3][4][5]){ }
fun(int p[2][3][4][5]){ }
指针
就是地址
定义
指针类型 指针变量; 指针类型一定带*
int *p;
变量名字: p
变量类型: int *
类型之间相加减的情况
相同类型的指针 进行运算 结果为 long 类型
int *p;
int *a;
short *b;
p - a ===> 得到 long 类型值
不同类型的指针,不能进行运算
p - b ===》 出错
指针 与 整型 进行运算
p + 2 ===》 跳过2个管辖区域
arr + 1
&arr + 1
赋值
int a = 10;
int *p;
p = &a; //p是a的地址 ,称 p 指向 a
初始化
int a;
int *p = NULL;
int *p = &a;
//NULL : 就是 门牌 号为 :0x00000000的位置
操作
取地址&
short a;
short *p = &a;
解引用 *
*p ===> a这块空间
局部变量(野指针)
野指针是不能做 解引用 操作的 ,否则会 段错误
int a; a里面存的是垃圾值
int *p; p里面存的也是垃圾值,称p 为 野指针
野指针很坑,为避免它,可以:
1)用指针时要初始化;
2)用完指针后要记得释放并且给指针赋值为NULL;
3)假如指针为是函数的输入参数时,在引用该参数前要先检查指针的参数;
4)尽量用引用代替指针;
5)用智能指针;
内存管理
堆空间
由程序员自己控制的空间,自己去占用和自己去释放
对堆空间的管理
malloc
#include <stdlib.h>
void *malloc(size_t size);
在堆中占用 size 个字节大小,返回了一个指向该空间的指针
size 个字节没有被初始化
如果size是0,可能返回NULL或者返回唯一的可以被释放的指针
参数: size 为 字节数
返回值:void * ---》 万能指针
成功返回一个地址
失败返回NULL
size为0的时候成功也有可能返回NULL
如果失败,设置 errno 的值 为 12
开辟的字节数一定要是 强转指针类型所指 空间大小的 整数倍
例子:
int *p = (int *)malloc(19);
===> 有问题:强转为int * 那么4字节对齐
===> 19 并不是 4的整数倍,顾 该方法 有问题
++++》 改:
int *p = (int *)malloc(20);
calloc
#include <stdlib.h>
void *calloc(size_t nmemb, size_t size);
开辟 nmemb 个元素,每一个元素都是 size 个字节
该空间都设置 为 0
如果 nmemb 或者 size 设置为 0 ,那么要么返回NULL或者唯一的可被释放的地址
参数:nmemb 为 元素个数 size 为 每个元素的字节数
返回值:
成功返回 地址
失败返回 NULL 并设置 errno
realloc
#include <stdlib.h>
void *realloc(void *ptr, size_t size);
将 ptr 的字节数 变成 size 个大小
从开始到 最新或者旧的 位置 ,内容不变
如果新的比旧的大,新增的区域没有被初始化
如果 ptr 是NULL,相当于 malloc(size)
如果 size 为0 ,ptr 不为 NULL ,相当于 free(ptr);
如果ptr是NULL ,该 NULL 必须是 malloc calloc realloc 的返回值
如果 ptr 被移动了,则会释放 ptr
参数:
ptr 为 必须是 malloc calloc realloc 的返回值 (必须是堆空间的)
size 为 新的空间大小
返回值:
成功返回 旧的 或者 新的 首地址
失败 返回 NULL 并设置 errno
free
#include <stdlib.h>
void free(void *ptr);
释放 ptr ,ptr 必须是 malloc calloc realloc 的返回值
如果 ptr 已经被释放,或者 ptr 是NULL,不做任何操作
参数:
ptr 为 malloc calloc realloc 的返回值
char arr[10] = "i love u";
fun(arr);
==================>
fun(char *p){}
fun(char p[]){}
fun(char p[10]){}
fun(char p[20]){}
perror
#include <stdio.h>
void perror(const char *s);
去标准出错 打印 s 的信息,后面跟 冒号 和 空格
perror --去读取 errno 的值,得到errno对应的错误信息
gets
#include <stdio.h>
char *gets(char *s);
从(stdin)读取一行数据 存入 s 中
成功返回 s
失败 返回 NULL 该函数已经不再使用,因为 很危险
puts
#include <stdio.h>
int puts(const char *s);
给 stdout 输入 s ,相当于在屏幕打印的意思
返回值:
成功返回 非负整数
失败返回 EOF (-1) (end of file)
存储类型
静态存储: ---------程序没静态就没
从产生开始,一直到程序结束才会消亡
动态存储:---------函数没动态就没
随着函数的执行而产生,随着函数的结束而消亡
定义变量:---------存储类型 数据类型 变量名字;
===============详细说明================
auto
auto 数据类型 变量名字;
只修饰局部变量 ,默认省略不写
在内存中定义该变量
定义的变量初始值 为 垃圾值
作用范围: 从定义开始,到所在的代码块(所在的大括号)结束
生命周期: 从生成开始,到函数结束
register
register 数据类型 变量名字;
只修饰局部变量
在cpu寄存器中
定义的变量初始值 为 垃圾值
作用范围: 从定义开始,到所在的代码块(所在的大括号)结束
生命周期: 从生成开始,到函数结束
static
修饰局部变量 ---》 静态变量
修饰全局变量
修饰函数
修饰局部变量时
void fun(void)
{
static int a; //未初始化的静态变量,在 .bss 中,默认为0
static int b = 20; //已初始化的静态变量,在 .data 中
static int *p; //未初始化的静态变量,在 .bss 中,默认为NULL
}
静态变量特点: 只会被定义或者初始化一次
修饰全局变量时
全局变量: 定义在函数以外的变量
全局变量的作用范围:从定义开始,到文件的末尾
定义全局变量 : 保存在 .bss 中
初始化全局变量: 保存在 .data中
全局变量不可以 被 外部引用
修饰函数时
该函数只在本文件中使用,不能被外部引用
extern
外部引入的意思
从外部引入全局变量,这是一个声明操作
extern 变量类型 变量名字;
例子:
extern int a; // 将 a 引入到 本文件中
有个必须的前提就是这个全局变量 一定 要存在
extern int x; 中如果你不使用该x,那么x存不存在无所谓,编译不会报错
也就是说用不用无所谓,但前提是一定要存在
从外部引入函数
extern 返回值类型 函数名字(形参);
例子:
extern int fun(void); // 外部声明
extern 只能做 引入操作 ,不能定义变量或者定义函数
=================总结=================
auto : 修饰局部变量,垃圾值,从定义开始到所在的大括号结束,从生成开始到函数结束
register则是 类似 auto ,修饰的变量存储在 寄存器 里面的
static :
修饰局部变量,变成静态变量,只会被定义或者初始化一次
修饰全局变量,该变量无法被外部引用,只在当前文件中有效(从定义开始到文件结束)
修饰函数,该函数不能被外部引用,只能在当前文件中使用
extern :
从外部引入的意思 (一个是全局变量,一个是函数)
引入的位置决定你的使用方式:
引入全局变量,放在函数里面,作为局部使用,放在函数外,作为全局使用
引入函数,放在函数里面,作为局部使用,放在函数外,作为全局使用
=====================================
结构体
构建新的类型
struct{成员变量;成员变量;成员变量;成员变量;}
例子:
struct{int a;short b;char c;} xx; // float xx; double xx;
struct 标签{成员变量;成员变量;成员变量;成员变量;}
例子:
struct stu{int a;short b;char c;} xx;
// 设置了一个类型,并生成了一个标签 struct stu ,创建了一个变量xx
struct stu xx; // 使用标签的形式来代表类型
在结构体中,生成的标签不能重复
struct stu{int a;short b;char c;};
// 设置了一个类型,并生成了一个标签 struct stu
位域
带有预定宽度的变量称为位域
struct 标签{
位域类型 位域变量名:位域宽度;
位域类型 位域变量名:位域宽度;
};
例子:
struct xx{
int a:2; //占2位 00 01 10 11 即-2 -1 0 1
unsigned b:4; //占4个位 unsigned int b : 4
};
struct xx sx;
sx.a = 5; //错误
位域类型:
位域类型为整型
例: char short int unsigned int(简写为 unsigned )
位域宽度:
不能超过该类型的的大小
例子:
int a:33 //错误
赋值时不能超过该类型的承受范围
例子:
unsigned char a:2 // 那么a只能存 0 1 2 3 这几个数字
a = 5; //错误
位域对齐:
位域类似结构体,按照最大类型对齐
空域:
位域宽度为0的位域称为空域,其作用是:该次对齐空间剩余部分全部补0
例子:
struct xx{
int b:1
int :0 // 32位对齐,b用了1位,所以该处共有31个0
int c:3 // 新的对齐行
}
无名位域:
位域没有名字,仅仅占用空间,无名位域不能调用,其作用是隔开两个位域
例子:
struct xx{
unsigned a:2
unsigned: 3 //无名位域,将a和c隔开3个位,该3个位不能使用
unsigned c:2
}
位域大小计算(存储规则):
1>如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止
2>如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍
3>如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式,Dev-C++,GCC采取压缩方式
4>如果位域字段之间穿插着非位域字段,则不进行压缩
联合体
所有的成员 公用 一块空间
union{成员变量;成员变量;成员变量;};
union 标签{成员变量;成员变量;成员变量;};
定义变量:
union{int x;short s;char c;} xx;
union yy{int x;short s;char c;} uu;
例子:
union{int x;short s[5];char c;} xx;
取最大的字节数成员作为该联合体的容量(字节数)
联合体的字节数 一定 要是 每个成员类型字节数的 整数倍
例子:
double 类型: 怎么存储??
1位符号位 11位指数位 52位小数位
指数0 : 01111111111
double d = 12.5;
1100.1 ===> 1.1001 * 2^3
0 100 0000 0010 1001 00000000...
0x4029000000000000
枚举
enum{枚举常量,枚举常量,枚举常量,枚举常量};
enum 标签{枚举常量,枚举常量,枚举常量,枚举常量};
例子:
enum fruit{APPLE,PEAR,CHERRY,GRAPE};
===>
生成了一个 enum fruit 标签类型
类似 #define APPLE 0
#define PEAR 1
enum fruit{APPLE=10,PEAR,CHERRY=15,GRAPE};
定义变量
enum fruit bb; //4个字节
//bb 只能在 APPLE=10,PEAR,CHERRY=15,GRAPE 中选择值
赋值:
bb= CHERRY;
初始化:
enum fruit bb = GRAPE;
条件编译
有选择的编译程序
有以下几种情况:
#if 能够确定值的表达式
#endif
-- -- -- -- -- -- --
#if 确定值
#else
#endif
-- -- -- -- -- -- --
#if 确定值
#elif 确定值
#elif 确定值
#else
#endif
-- -- -- -- -- -- --
#ifdef 宏
语句A;
#endif
===》 如果 宏 存在则成立,然后将语句A编译进程序
-- -- -- -- -- -- --
#ifndef 宏
语句A;
#endif
===》 如果 宏 不存在则成立,然后将语句A编译进程序
-- -- -- -- -- -- --
#if defined(宏1) || defined(宏2) || defined(宏3)
语句A;
#endif
====》 这些宏,只要定义了其中一个,就能编译 语句A 到程序中
-- -- -- -- -- -- --















 2921
2921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









