






基于常规DQN算法(无算法层面的优化)实现CartPole-v1无限步数
唯一的改动就是把奖励和当前位置产生了联系,从零开始的话大概训练1000轮左右就能无限步数
这段代码比较核心的改进也就是reward -= abs(state[0])*5这句话了,因为CartPole位置离中心太远(超出边界)的话就会寄掉,加上这句话能让模型一直保持在中间的位置,同时极大的提高了收敛速度
视频时长只有22分是因为只能存这么长,再长的话就会out of memory了
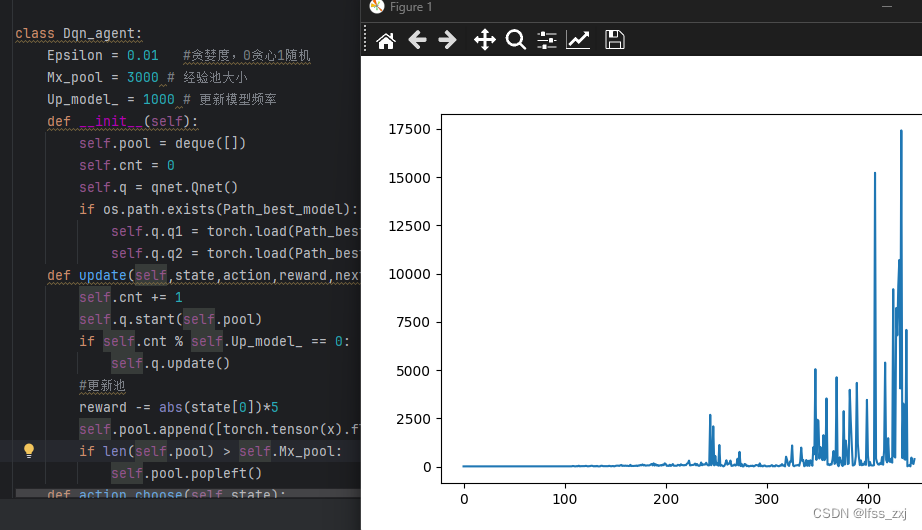
q网络的代码(参数不是特别重要,改成别的大概也能拟合),保存为qnet.py
import os
import random
import torch
import torch.nn as nn
device = torch.device("cuda")
Batch_size = 64 # 每次训练的样本数
LR = 1e-3 # 学习率
FCN_size = (256,256)
Path = 'cache/qnet'
class FCN(nn.Module):
def __init__(self):
super().__init__()
self.sequense = nn.Sequential(
nn.Linear(4, FCN_size[0]),
nn.ReLU(),
nn.Linear(FCN_size[0], FCN_size[1]),
nn.ReLU(),
nn.Linear(FCN_size[1], 2)
)
def forward(self, x):
return self.sequense(x)
class Qnet:
def __init__(self):
self.q1 = FCN().to(device)
self.q2 = FCN().to(device)
if os.path.exists(Path):
self.q1 = torch.load(Path)
self.q2 = torch.load(Path)
self.optimizer = torch.optim.Adam(self.q1.parameters(), lr=LR)
self.loss_fn = nn.MSELoss().to(device)
def update(self):
torch.save(self.q1,Path)
self.q2 = torch.load(Path)
def start(self,pool):
if len(pool) < Batch_size:return
da = random.sample(pool,Batch_size)
s0,a0,r1,s1 = zip(*da)
s0,a0,r1,s1 = torch.stack(s0),torch.stack(a0),torch.stack(r1),torch.stack(s1)
self.q1.train()
y_p = self.q1(s0).gather(1,a0.long().reshape(-1,1))
q_val = self.q1(s1).max(1)[1].view(-1,1)
next_q_val = self.q1(s1).gather(1,q_val)
y = r1.reshape(-1,1)+next_q_val
loss = self.loss_fn(y_p, y)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.q1.eval()
dqn的代码(这里需要注意的是经验池大小,太小的话容易卡在几千回合就结束了;还有就是贪婪度也别太高,不然容易因为运气太差中途寄掉,其他没什么特别重要的了),保存为dqn.py
import os
import random
import time
import torch
from collections import deque
import gymnasium as gym
import qnet
device = torch.device("cuda")
Start_time = time.time()
Episode = 2*10**6 # 训练次数
Path_best_model = 'cache/dqn_best'
class Dqn_agent:
Epsilon = 0.01 #贪婪度,0贪心1随机
Mx_pool = 3000 # 经验池大小
Up_model_ = 1000 # 更新模型频率
def __init__(self):
self.pool = deque([])
self.cnt = 0
self.q = qnet.Qnet()
if os.path.exists(Path_best_model):
self.q.q1 = torch.load(Path_best_model)
self.q.q2 = torch.load(Path_best_model)
def update(self,state,action,reward,next_state,terminated):
self.cnt += 1
self.q.start(self.pool)
if self.cnt % self.Up_model_ == 0:
self.q.update()
#更新池
reward -= abs(state[0])*5
self.pool.append([torch.tensor(x).float().to(device) for x in (state,action,reward,next_state)])
if len(self.pool) > self.Mx_pool:
self.pool.popleft()
def action_choose(self,state):
if random.random() < self.Epsilon:
action = random.randint(0,1)
else:
lin = self.q.q2(torch.tensor(state).float().to(device)).tolist()
action = lin.index(max(lin))
return action
agent = Dqn_agent()
env = gym.make('CartPole-v1', render_mode='human') #, render_mode='human'
total_mx = 0
for episode in range(1,Episode+1):
state = env.reset()[0]
total_reward = 0
terminated = False
while not terminated:
action = agent.action_choose(state)
next_state, reward, terminated, *_ = env.step(action)
total_mx += reward
agent.update(state, action, reward, next_state, terminated)
state = next_state
if total_reward > total_mx:# 更新最优模型
torch.save(agent.q.q2,Path_best_model)
total_mx = total_reward
env.close()














 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









