







一、BaseURL基础路径封装
如果基础路径中需要用到变量:
方法一:通过自带的substitute进行实现,${变量名}
#对应的数据源
all_val = {"VAR_TOKEN": "a6e7edd962bc952e51d24ed9c66a0321", "XXX":"xxx"}
# 对应的变量:${变量名}
PROJECT_URL = "http://shop-xo.hctestedu.com?"
BaseURL = "s=api/cart/save&token=${VAR_TOKEN}"
# 进行拼接并且进行替换成:all_val 值, 没有需要替换的也没有影响
url = Template(F'{PROJECT_URL}{BaseURL}').substitute(all_val)方法二:通过之前封装的replace_variable_references方法进行实现,"{{变量名}}"
在FileDataDriver.py中的FileReader类新增这个方法:
@staticmethod
def replace_variable_references(data, variables):
"""
把data当中{{变量}} 转换成字典数据中的数据
:param data: 把当中{{变量}} 转换成字典数据中的变量
:param variables: 字典数据
:return:
"""
if isinstance(data, str):
# 替换字符串中的变量引用
for key, value in variables.items():
# 将值转换为字符串,避免数据源有整形的情况,而造成replace()报错
value = str(value)
data = data.replace('{{' + key + '}}', value)
return data
elif isinstance(data, list):
# 递归替换列表中的元素
return [FileReader.replace_variable_references(item, variables) foritem in data]
elif isinstance(data, dict):
# 递归替换字典中的值
return {key: FileReader.replace_variable_references(value, variables) for key, value in data.items()}
else:
return data二、MySQL数据库数据断言封装
api_key.py中ApiKey/类徐新增sql_check检查
@allure.step(">>>>>>进行数据库的获取数据,利于断言或者提取数据")
def sql_check(self, sql):
connection = pymysql.connect(
host=HOST, # 数据库地址
port=PORT,
user=USER, # 数据库用户名
password=PWD, # 数据库密码
db=DB, # 数据库名称
)
# 2.使用该对象去进行操作- 谁?-- 游标对象
cursor = connection.cursor()
# 4. 执行SQL
cursor.execute(sql)
# 5.得到第一行数据
res = cursor.fetchone() # 元组
# 6.关闭数据库连接
cursor.close()
connection.close()
return res数据库进行断言及处理

# 4. 数据库进行断言及处理--SQL预期结果字段[20]/SQL[21]/SQL[22] 都不为空的情况
if CaseData["sqlKey"] and CaseData["sqlValue"] andCaseData["sqlExpectResult"]:
try:
# 避免SQL引用参数的情况
# sqlValue = FileReader.replace_variable_references(CaseData["sqlValue"], self.all_val)
# 进行拿取数据并且执行
sqlValue = CaseData["sqlValue"]
sqlValue = self.ak.sql_check(sqlValue)
all_sql_value = set(sqlValue) # 拿到的数据是元组,转成集合格式
except:
value = MSG_MySQL_ERROR
else:
# 两个集合的交叉差集为0 ,则代表数据没有差异, 也就是 s == 0
s = len(eval(CaseData["sqlExpectResult"]).symmetric_difference(all_sql_value))
if s == 0:
value = MSG_SUCCESS
else:
value = MSG_EXECUTE_FAILURE
finally:
FileReader.writeDataToExcel(row=row, column=cell, value=value)
assert s == 0
else:
if is_assert is True:
# 当is_assert为True则代表进行响应断言则无需写入数据
print(value)
else:
value = MSG_MySQL_NULL
FileReader.writeDataToExcel(row=row, column=cell, value=value)SQL的提取关联变量,方法封装:__sql_extraction()
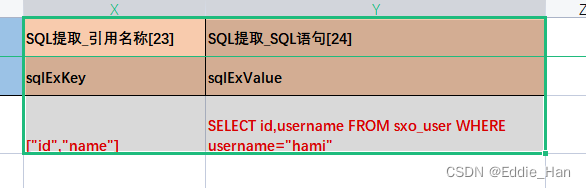
def __sql_extraction(self, CaseData, res):
# JSON提取器
if CaseData["sqlExKey"] and CaseData["sqlExValue"]:
# 获取对应:JSON提取_引用名称;把存储列表(excel)中是字符串,进行类型转换
varStrList = eval(CaseData["sqlExKey"])
jsonList = res
# 获取列表长度,进行遍历
length = len(varStrList)
# 循环输出列表值
for i in range(length):
# 1. 获取对应的key 和 valure
key_data = varStrList[i]
value_data = jsonList[i]
print(f"key:{key_data},sqlvalue:{value_data}")
# 3. 持续添加参数,只要参数名不重复,重复的后面就会覆盖前面的参数
self.all_val[key_data] = value_data
print("res:", self.all_val)判断字段是否为空,当不为空则进行全量对比。添加到 【3. 数据进行断言及处理--校验字段/预期 结果】的else分支中。
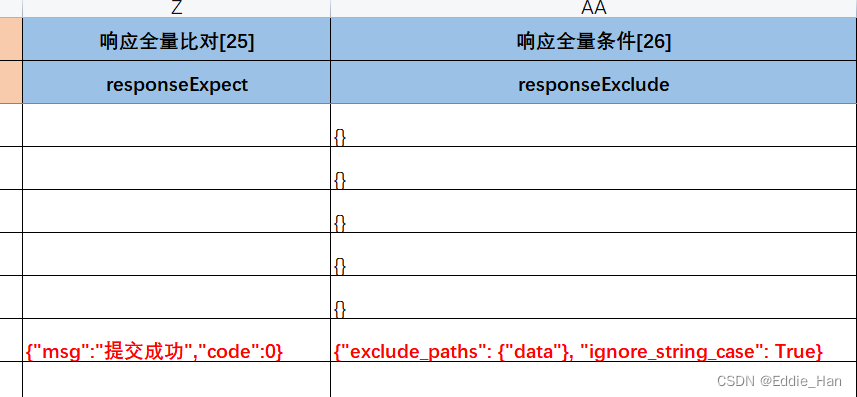
# 确定是否需要进行全量比对
if CaseData["responseExpect"]:
# 期望结果:
try:
json1 = eval(CaseData["responseExpect"])
other = eval(CaseData["responseExclude"])
res2 = self.ak.jsonDeepDiff(json1, res.json(), **other)
if not res2:
value = "全量断言失败"
else:
value = "全量断言成功"
except:
print("不需要进行响应全量断言。")api_key中ApiKey类方法jsonDeepDiff:
def jsonDeepDiff(self, json1, json2, **kwargs):
"""
对比两个json的差异
:param json1: 期望结果
:param json2: 实际结果
:param exclude_paths:需要排除的字段,集合的类型,比如{“id”,...}
:param ignore_order: 忽略顺序,一般用户有序数据类型,比如列表
:param ignore_string_case:忽略值的大小写,默认Flase
:return: 当数据没有差异则返回空集合
"""
diff = DeepDiff(json1, json2, **kwargs)
if len(diff) == 0:
value = True
else:
value = False
return value三、数字签名原理:
工作原理通常涉及以下步骤:
1. 创建数据:要签名的数据可以是任意形式的信息,如文本、文件、数据记录等。
2. 哈希函数:使用哈希函数对数据进行处理,生成一个固定长度的哈希值。哈希函数是一种将任意大 小的输入数据映射为固定长度输出的算法,它具有单向性(不可逆)和唯一性的特性。
3. 加 密:使用私钥对哈希值进行加密,生成数字签名。私钥是数字签名方的秘密密钥,只有数字 签名方拥有。
4. 验 证:其他人可以使用相应的公钥对数字签名进行解密和验证。公钥是与私钥对应的公开密 钥,任何人都可以访问。
5. 哈希比较:验证者对原始数据应用相同的哈希函数,生成哈希值。然后,它将使用公钥解密数字签 名,得到解密后的哈希值。
6. 比 较:验证者将解密后的哈希值与自己计算的哈希值进行比较。如果两个哈希值匹配,则数据 的完整性和真实性得到确认;否则,数据可能已被篡改或签名无效。
主要目的是确保以下内容:
数据完整性:任何对数据进行更改或篡改的尝试都会导致签名验证失败,因为哈希值将不匹配。
身份认证:由于私钥只有签名方拥有,通过验证签名,可以确认数据的发送者身份。
不可否认性:一旦签名被验证为有效,签名方不能否认对数据的签名。
















 2509
2509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









