







一、线程数量 如何确定?
-
通过基准测试获取基准响应时间:
15ms -
单线程产生的并发量(理论上是tps) = 1000ms/响应时间(ms):
1000/15🟰66 -
线程数量 = 目标并发量 / 单线程产生并发量:
800 / 66= 12
目标并发量上浮取15个线程 -
实际性能测试过程中 - 线程数往往是过载:
20个 -
还有一种算法
能接受的最大响应时间 去代入上面的公式:
1000 / 200 = 5
800 / 5 = 160个线程
二、如何定义所谓的瓶颈
-
程序性能指标不达标
-
吞吐量
-
响应时间
-
错误率
-
资源占用率
-
三、网络瓶颈分析与调优方向
3.1 检查网络速度 - iperf3
工具 iperf3 测试两个服务器 之间的 带宽速度 测速
3.2 由吞吐量计算网络带宽
计算 -- 520/s 吞吐量 占用多大网络带宽(吞吐量 * 响应大小 * 8bit)
-
传输内容大小(响应头+响应体)
-
单词响应内容大小0.33KB
-
http头大小普遍1KB左右,有些响应头还会更大
-
每次传输响应数据在,1.3KB左右
-
-
实测过程中占用网络带宽
-
520*1.3 = 网络每秒传输676KB
-
占用带宽 = 676KB * 8 = 5408kbps 约等于5Mbps左右
-
-
检查网络带宽
-
应用服务器带宽 -- 只有 5M兆
-
推测 -- 性能瓶颈的原因在这
-
验证 -- 提高性能测试环境的带宽
-
3.3 网络监控 - iftop
iftop (全称应该是 interface top) 是查看网络实时流量的工具,可以监控各个应用程序的流量
常用命令:iftop -i enp0s8 -n
3.4 优化建议
硬件:升级机器,
软件:优化程序
-
压缩数据传输的大小
-
压缩源数据
-
服务器层面 gzip压缩传输
-
减少不必要数据传输
-
四、磁盘瓶颈分析与调优方向
4.1 程序使用场景
-
日志文件
-
附件上传存储
-
数据库系统 - 表数据读写
-
程序本身的代码,配置文件 都是在磁盘存放起来,需要加载到内存
4.2 磁盘监控 iotop
iotop -- only 查看某进程磁盘读写情况
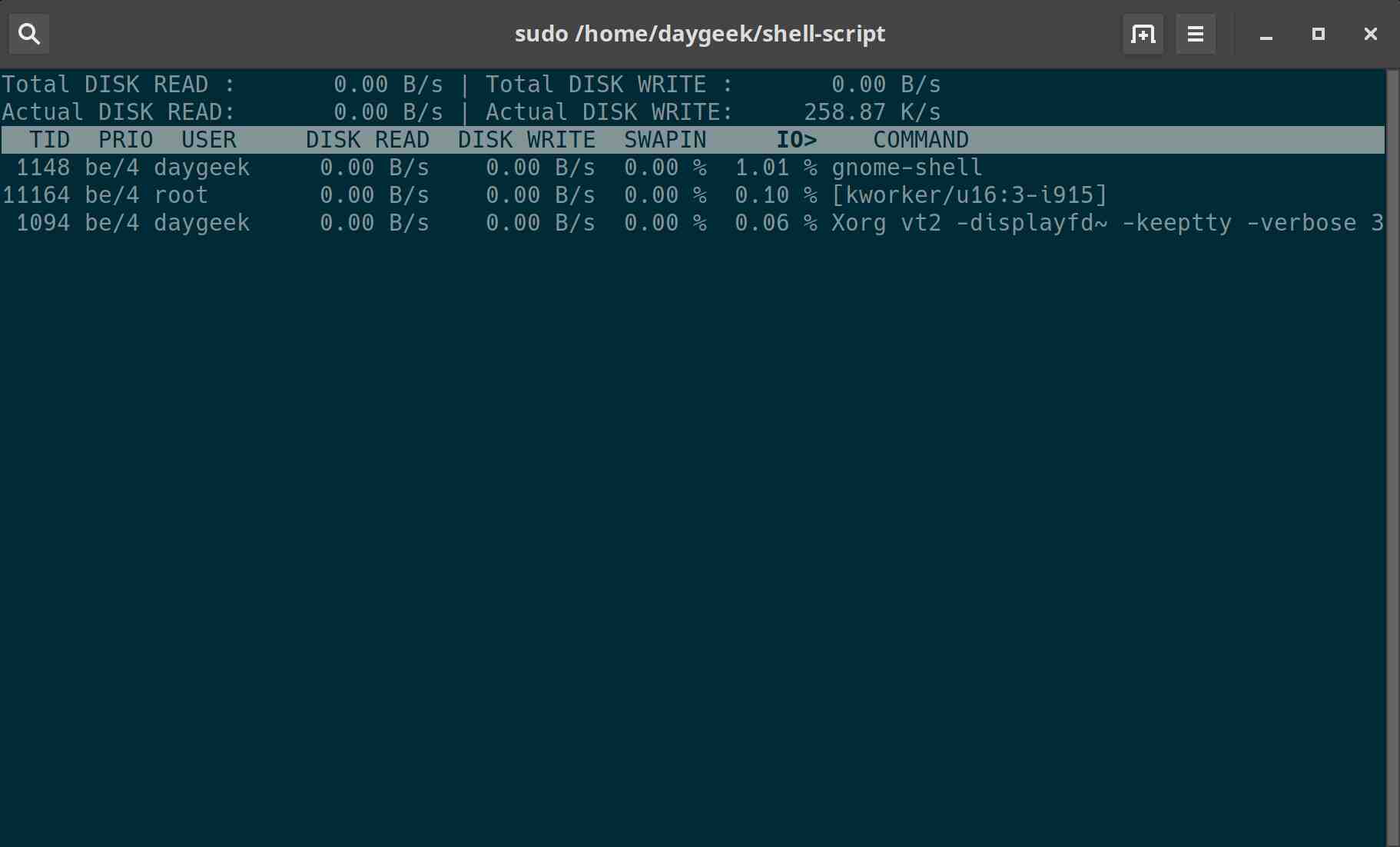
3.3 优化建议
WEB网站 -- 每一张图片 很大
-
同时也会占用大量的 网络带宽
-
占用大量的磁盘 I/O
日志 -- 控制详细程度
-
不同的日志级别
-
生产 warn/error
-
开发 info/debug
-
-
磁盘空间是有限的, 监控 磁盘空间的占用增长情况
-
目前的系统里边 - 主要 还是 数据库系统 用磁盘比较多
五、CPU瓶颈分析与调优方向
5.1 top查看CPU运行情况
5.2 性能测试过程:
负载测试下:
-
如果吞吐量达到了瓶颈,而CPU资源占用不高,当你增加了并发量,而CPU并没有随之变高:就要考虑程序代码或者操作系统配置问题,例如:涉及Jvm 程序 多线程机制
性能测试过程中,CPU占用已经很高
六、JAVA程序调优实战分析
6.1 JVM 核心知识:
程序计数器(线程私有,记录线程上次执行到哪里,下一步执行什么):下一条需要执行的字节码指令:分支、跳转、循环、异常处理、线程恢复等基础操作都会依赖计数器来完成。每个线程都有独立的程序计数器,用来在线程切换后能恢复到正确的执行位置,各条线程之间的计数器互不影响,独立存储。
栈(线程私有):后进先出,记录当前正在执行的方法
方法区/元数据区(线程共有):存储已被虚拟机加载的类信息、常量、静态变量、JIT(just in time,即时编译技术)编译后的代码等数据
堆(线程共有):存储Java对象实例的内存区域
6.2 JVM 资源监控工具
jmap,jconsole,jvisualvm
JVM集群监控体系-测试过程/结果分析中看grafana(需要开发配合采集)
6.3 优化建议
1. 性能测试过程 - 服务器内存资源够用,但是程序性能达到了瓶颈
可疑原因:内存配置太小,没有榨干服务器内存资源。或者是测试场景中的并发量不够(要监控 测试过程中,JVM自身的内存是否被用完,如果没用完,就加大并发量)
通过查看 JVM的 内存配置 ,是否用到了 机器的大部分内存
验证:
-
1. 加大并发 -- 排查性能测试并发不够的问题
-
2. 加大内存 -- 在加大内存之后,性能是否有提升,-Xms(堆内存最小值)-Xmx(堆内存最大值)
2. 性能测试过程 - 服务器CPU资源够用,但是程序性能达到了瓶颈
可疑原因:程序配置的线程数太少,没有榨干服务器硬件资源。或者是测试场景中的并发量不够
请求处理的线程池大小线程参数调整
-
WEB服务 --- 处理请求时候,会用到线程池
-
不限于Tomcat,jetty,netty,weblogic,包括其他语言 也有类似的机制
-
-
比如tomcat的3个参数:acceptCount、maxConnections、maxThreads
-
accept队列的长度;当accept队列中连接的个数达到acceptCount时,队列满,进来的请求一律被拒绝。默认值是100
-
Tomcat在任意时刻接收和处理的最大连接数。当Tomcat接收的连接数达到maxConnections时,Acceptor线程不会读取accept队列中的连接;这时accept队列中的线程会一直阻塞着,直到Tomcat接收的连接数小于maxConnections。如果设置为-1,则连接数不受限制。
-
请求处理线程的最大数量。默认值是200
-
3. 并发量少,但是CPU资源占用量大
可疑原因:少量线程占用了大量的系统资源例如: 1. 单线程占用CPU 100% (死循环、数据太多循环N多次处理)2. 1个请求会导致大量的线程被创建 (开发人员写业务逻辑代码也用到多线程)
排查方式:
- top+jstack寻找最耗CPU的进程和线程
- 基于arthas阿里提供的,dashboard 整体仪表盘,thread -n 5 展示最忙的前5个线程
七、JAVA程序GC机制及性能稳定性调优分析

1. 分代
-
新生代 - ede,(8:1:1)
-
新生代-survivor 1
-
新生代-survivor 2
-
-
老年代(新:老= 1:2)
-
老年代 - 超级大的对象 和 经历多次新生代GC依然存在的对象。
-
-
特殊 - 永久代【元数据空间】
2. STW概念(stop the world)
-
和性能有关,GC时程序停止
-
一个请求 -- 处理时间业务代码 执行时间 + GC垃圾回收时间
3.GC
-
minor gc 小范围GC
-
新生代
-
时间一般比较短
-
-
full gc 大范围GC
-
所有的堆空间、元数据空间
-
导致 程序中断的时间比较长
-
7.1 StackOverflowError-栈内存溢出
可疑原因:递归调用
方法:尝试修改配置增加JVM每个线程栈内存的大小
7.2 实战:OutOfMemoryError
可疑原因:持久性压力测试,程序内存占用逐步增高,最终挂掉突然大量并发,内存不够用
-
java.lang.OutOfMemoryError: unable to create new native thread
-
Java应用程序已经达到了它可以启动的线程数的限制
-
-
java.lang.OutOfMemoryError: Metaspace1.8+ java.lang.OutOfMemoryError: PermGen space
-
-XX:MaxPermSize=512m
-
加大元数据空间的内存,或者检查元数据空间占用是否合理
-
class 类加载的太多,动态创建了很多class类
-
-
java.lang.OutOfMemoryError: Java heap spacejava.lang.OutOfMemoryError:GC overhead limit exceeded
-
加大堆内存,或者检查内存占用是否合理
-
程序调优 - 获取内存快照 - 找到内存占用比较大的对象,让开发去修改
-
7.3 性能测试中,吞吐量呈现出波浪状。性能稳定性调优
可疑原因: JVM 垃圾回收 导致STW,产生时间停顿
调整GC参数
八、Mysql数据库性能测试及瓶颈分析调优思路
8.1 Mysql 独立的监控指标
grafana + prometheus + mysql
8.2 数据库调优思路汇总
瓶颈:
-
资源不够用CPU,网络资源,磁盘资源,内存
-
响应时间 - 慢查询日志
-
数据库连接池线程数量
-
查询-调优分析:
-
使用索引
-
减少表关联join
-
搜索场景严禁左模糊或者全模糊
-
大量更新可以用批处理,及时关闭事务,非必要不要主动锁数据
-
九、Nginx负载均衡集群架构性能测试及瓶颈分析调优思路
Nginx 性能监控
grafana + prometheus + nginx
可疑原因:
-
Nginx 瓶颈分析
-
资源占用:磁盘网络内存CPU
-
请求是否堆积:write,wait,read,active
-
Nginx 调优方向:
- Nginx运行工作进程数量
- Nginx运行CPU绑定
- 三种方式:轮询,权重,ip_hash
十、Redis高并发缓存架构性能测试及瓶颈分析调优思路
10.1 Redis 监控体系
grafana + prometheus + redis
10.2 Redis 调优建议
缓存预热,缓存击穿,缓存雪崩
Redis本身的性能足够逆天,大部分的问题在于 开发人员没有用好Redis
十一、MQ高并发异步消息架构性能测试及瓶颈分析调优思路
activemq,rabbitmq,kafka
监控体系:官方
不同的消息模式:
-
sync同步模式
-
发送消息采用同步模式,这种方式只有在消息完全发送完成之后才返回结果,此方式存在需要同步等待发送结果的时间代价
-
具有内部重试机制
-
-
async异步模式
-
发送消息采用异步发送模式,消息发送后立刻返回,当消息完全完成发送后,会调用回调函数sendCallback来告知发送者本次发送是成功或者失败。异步模式通常用于响应时间敏感业务场景,即承受不了同步发送消息时等待返回的耗时代价
-
同步发送一样,异步模式也在内部实现了重试机制,默认次数为2
-
测试的时候:要注意, 如果发送完毕之后,程序就挂掉了, 那么对于数据处理是否存在问题
-
程序在收到 MQ 处理失败的callback回调消息之后,要进行相对应重试设计
-
-
-
one-way生产者单向发送
-
采用one-way发送模式发送消息的时候,发送端发送完消息后会立即返回,不会等待来自broker的ack来告知本次消息发送是否完全完成发送。这种方式吞吐量很大,但是存在消息丢失的风险,所以其适用于不重要的消息发送,比如日志收集
-
MQ 出问题的情况还是比较少的
-
















 46
46











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









