







引言
在我们的MoodVine项目中,我们需要识别用户的语音并将其转换为文字,然后交由情绪小助手AI进行分析处理。
技术选型历程
计划一 RealtimeSTT
最初,我们考虑使用RealtimeSTT模型,因为它承诺能够实时进行语音翻译:
conda install -c conda-forge pyaudio
pip install RealtimeSTT
然而,在实际安装过程中,我们遇到了各种依赖问题和安装失败的情况。经过多次尝试后,我们决定放弃这一方案。
计划二 SenseVoice
FunAudioLLM/SenseVoice:多语言语音理解模型 --- FunAudioLLM/SenseVoice: Multilingual Voice Understanding Model
最终我们选择了FunAudioLLM团队开发的SenseVoice模型,这是一个多语言语音理解模型,具有以下特点:
- 语音识别(ASR)
- 语种识别(LID)
- 语音情感识别(SER)
- 声学事件分类/检测(AEC/AED)
虽然SenseVoice不支持实时翻译(需要录制完成后再处理),但其额外的情感识别和声学事件检测功能完美契合了我们项目的需求,能够为后续的情绪分析提供更丰富的数据。
实现方案如下:
我们构建了一个sense_voice类来封装模型功能:
MODEL_PATH = "/models_shared/SenseVoiceSmall"
class SenseVoiceService:
def __init__(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = self._load_model()
def _load_model(self):
return AutoModel(
model=MODEL_PATH,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device=self.device,
disable_update=True,
)
def transcribe(self, audio_path):
try:
result = self.model.generate(
input=audio_path,
language="auto",
batch_size_s=30,
)
return result[0]["text"]
except Exception as e:
raise RuntimeError(f"处理失败: {str(e)}")
sense_voice_service = SenseVoiceService() # 单例实例
我们使用Flask框架构建了一个RESTful API端点:
sense_voice_bp = Blueprint('sense_voice', __name__)
ALLOWED_EXTENSIONS = {'mp3', 'wav', 'm4a'}
def allowed_file(filename):
return '.' in filename and \\
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@sense_voice_bp.route('/transcribe', methods=['POST'])
def transcribe_audio():
if 'file' not in request.files:
return jsonify({"error": "未上传文件"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "空文件名"}), 400
if not allowed_file(file.filename):
return jsonify({"error": "不支持的文件格式"}), 400
try:
# 保存上传文件
upload_dir = os.path.join(os.getcwd(), 'static', 'uploads')
os.makedirs(upload_dir, exist_ok=True)
filepath = os.path.join(upload_dir, secure_filename(file.filename))
file.save(filepath)
# 执行语音识别
text = sense_voice_service.transcribe(filepath)
return jsonify({"text": text})
except Exception as e:
return jsonify({"error": str(e)}), 500
再部署完成后,使用apifox测试运行结果如下图所示。
可以看出该模型很好的支持了多语言识别,识别内容准确,响应速度非常快,且可以识别情绪,返回结果不仅包含转换后的文本,还包含了情感标记和语言标记。
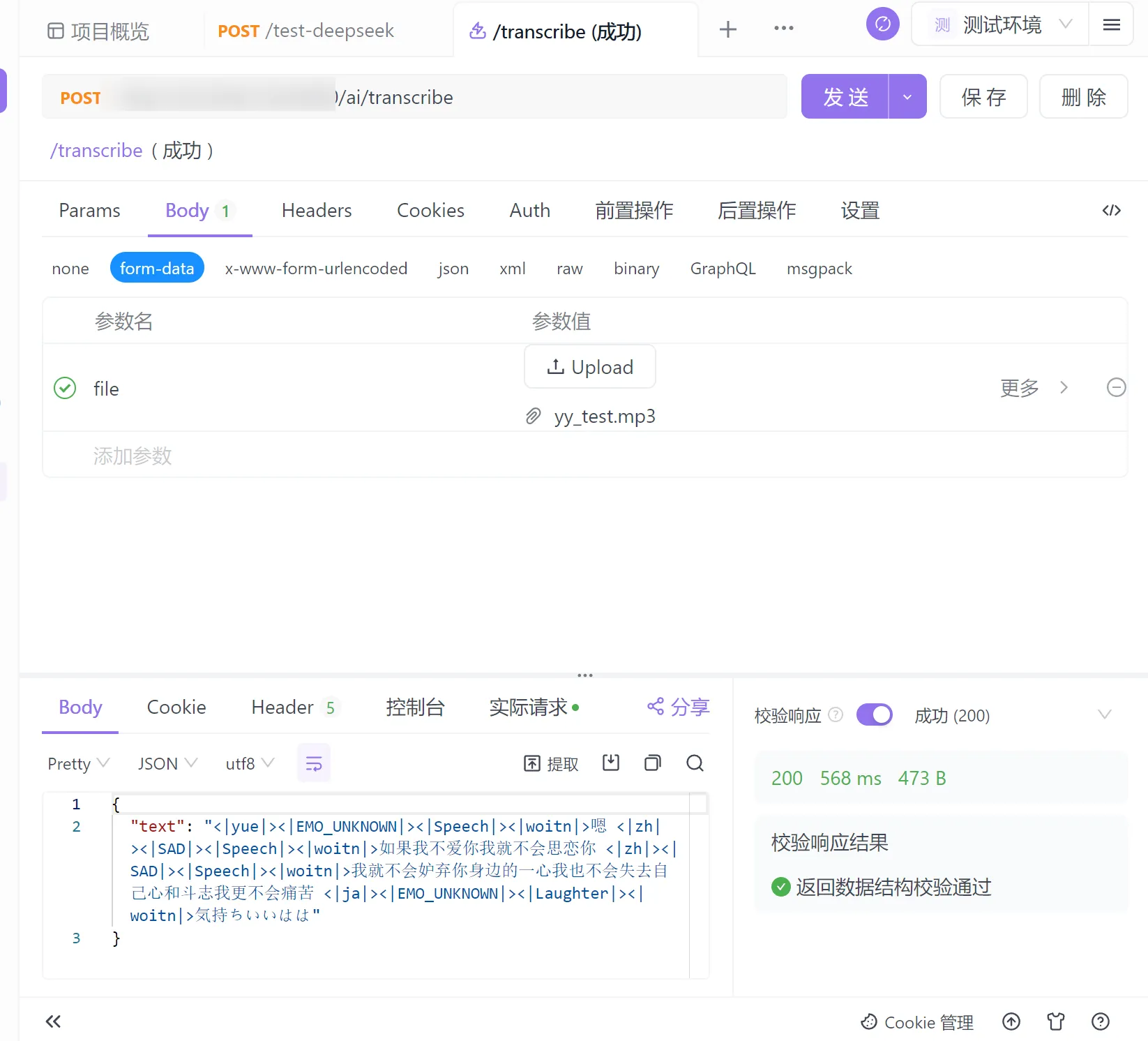
虽然SenseVoice已经能够识别情绪,但返回的字符串格式需要进一步处理:
- 文本提取:从返回的复杂字符串中提取纯文本内容
- 情绪标记解析:解析EMO_UNKNOW等情绪标记
- 语言识别:利用LID功能识别用户使用的语言
这些处理将为我们的情绪小助手AI提供更结构化的输入数据。
总结
SenseVoice模型为我们的MoodVine项目提供了强大的语音转文本功能,其额外的情感识别和语言识别能力更是锦上添花。虽然安装和配置过程遇到了一些挑战,但最终实现的API服务表现稳定,响应迅速,完全满足了项目需求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









