







0、Python是什么?

- Python是一种解释型语言。但是跟C和C的衍生语言不同,Python代码在运行之前不需要编译。其他解释型语言还包括PHP和Ruby。
- Python是动态类型语言,指的是在声明变量时,不需要说明变量的类型。可以直接编写类似
x=111和x="Hello World"这样的代码,程序不会报错。 - Python是一门强类型语言,是指不容忍隐式的类型转换,比如字符串类型的数字和整型的数字进行比较不会成立。
- Python非常适合面向对象的编程(OOP),因为它支持通过组合(composition)与继承(inheritance)的方式定义类(class)。
- 在Python语言中,函数是第一类对象(first-class objects)。这指的是它们可以被指定给变量,函数既能返回函数类型,也可以接受函数作为输入。类(class)也是第一类对象。
- Python代码编写快,而运行速度比编译语言通常要慢。但是Python允许加入基于C语言编写的扩展,也常被用作“胶水语言”。因此我们能够优化代码,消除瓶颈。比如说
numpy就是一个很好地例子,它的运行速度非常快。 - Python用途非常广泛——爬虫、Web 程序开发、桌面程序开发、自动化、科学计算、科学建模、大数据应用、图像处理、人工智能等等。
- Python包含八种数据类型:字符串、元组、字典、列表、集合、布尔类型、整型、浮点型。拥有三大特性:封装、继承、多态。最显著特点是采用缩进/4个空格(不能混用)表示语句块的开始和结束。
- Python的标识符命名规则有:可以由字母下划线数字组成,不能以数字开头,不能与关键字重名,不能含有特殊字符和空格,使用大驼峰、小驼峰式命名。Python区分大小写
_单下划线开头:声明为私有变量,通过from M import * 方式将不导入所有以下划线开头的对象,包括包、模块、成员。 单下划线结尾_:为了避免与python关键字的命名冲突。 __双下划线开头:模块内的成员,表示私有成员,外部无法直接调用 __双下划线开头双下划线结尾__:指那些包含在用户无法控制的名字空间中的“魔术”对象或属性,如类成员的name 、doc、init、import、file、等。
表达式:算术运算符 + - * / // % ; 比较运算符 > < >= <= != ; 逻辑运算符 and or not ;判断是否为同一对象:is、is not ; 判断是否属于另一个对象: in 、not in。 函数支持递归、默认参数值、可变参数、闭包,实参与形参之间的结合是传递对象的引用。另外还支持字典、集合、列表的推导式。 Python3中的print函数代替Python2的print语句 Python3中的Str类型代表Unicode字符串,Python2中的Str类型代表bytes字节序列 Python3中的 / 返回浮点数,Python2中根据结果而定,能被整除返回整数,否则返回浮点数 Python3中的捕获语法 except exc as var 代替Python2中的 except exc, var

1、Python新式类&旧式类的区别

Python2中默认都是旧式类,除非显式继承object才是新式类; Python3中默认都是新式类,无需显式继承object。
新式类对象可以直接通过__class__属性获取自身类型:实例对象a1.__class__ 、type(实例对象a1)结果为:<class '__main__.A1'>; 旧式类为 __main__.A、<type 'instance'>
多继承时,经典类搜索父类的顺序: 先深入继承树左侧,再返回开始找右侧,菱形搜索,深度优先搜索(MRO算法); 新式类搜索父类的顺序: 先水平搜索,然后再向上移动,广度优先搜索(C3算法)。
新式类增加了__slots__内置属性, 可以把实例属性的种类锁定到__slots__规定的范围之中。
新式类增加了__getattribute__方法

2、如何在一个函数内部修改全局变量

a = 10 def info(): print(a) def foo(): global a a = 22 print(a) print(a) info() foo() # 经过foo函数的修改,a的值已变为22 print(a) info()

3、列出5个python标准库
标准库:sys、os、re、urllib、logging、datetime、random、threading、multiprocessing、base64 第三方库:requests、Scrapy、gevent、pygame、pymysql、pymongo、redis-py、Django、Flask、Werkzeug、celery、IPython、pillow
4、字典如何删除键和合并两个字典

di = {"name": "power"}
ci = {"age": 18}
# 删除键
del di["name"]
# 合并字典
di.update(ci)
5、python实现列表去重的方法

li = [2, 2, 1, 0, 0, 1, 2]
# 方法一:使用set方法
sl = list(set(li))
# 方法二:额外使用一个列表
li2 = list()
for i in li:
if i not in li2:
li2.append(i)
# 方法三:使用列表的sort方法
l1 = ['b','c','d','c','a','a'] l2 = list(set(l1)) l2.sort(key=l1.index) print(l2) l1 = ['b','c','d','c','a','a'] l2 = sorted(set(l1),key=l1.index) print(l2)
6、一句话解释什么样的语言能够用装饰器?

装饰器本质上是一个Python函数,他可以让其他函数在不需要做任何代码改动的前提下额外增加功能,装饰器接收一个函数作为参数,返回值也是一个函数。 谁可以用:函数可以作为参数传递的语言,就可以使用装饰器。 作用:在不改变源代码的情况下添加新的功能。
使用场景:插入日志、性能测试(计算函数运行时间)、事务处理(让函数实现事务的一致性)、缓存、权限校验等场景 问题:函数A接收整数参数n,返回一个函数B,函数B是将函数A的参数与n相乘后的结果返回 def info(func): def foo(n): res = func(n) return res * n return foo @info def func(n): return n func(2) [Out]: 4

7、python内建数据类型有哪些

# 不可变类型
int 整形
str 字符串
float 浮点型
tuple 元组
bool 布尔型
# 可变类型
list 列表
dict 字典
8、简述面向对象中__new__和__init__区别

1、__new__必须接收一个名为 cls 的参数,代表的是当前类对象。
2、__new__必须有返回值,返回的是由当前类对象创建的实例对象,而__init__什么都不返回。
3、__init__必须接收一个名为 self 的参数,代表的是由__new__方法所创建的实例对象。
4、只有在__new__方法返回一个 cls 的实例时,后面的__init__才能被调用。
5、当创建一个新实例对象是,自动调用__new__方法, 当初始化一个实例时调用__init__方法。
ps: __metaclass__ 是创建类时起作用.所以我们可以分别使用__metaclass__,__new__和__init__来分别在类创建,实例创建和实例初始化的时候做一些小手脚.

9、进程&线程&协程?

1、进程多与线程进行比较
- 线程是CPU真正调度的单位,也是进程内的一个执行单元,进程是系统资源分配的基本单位;
- 一个进程内至少有一个线程,同一个进程内的线程共享进程的资源,而进程有自己独立的地址空间,每个进程各自有独立的资源互不干扰。
- 每个独立的线程必须有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在进程当中。
- 不仅进程之间可以并发执行,同一个进程的多个线程之间也可以并发执行。
- 多线程的意义在与一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
2、协程与线程进行比较
- 一个线程内可以有多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程可以选择同步或异步。
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态。

10、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
li = [1, 2, 3, 4, 5]
def info(x):
return x**2
li2 = [i for i in map(info, li) if i > 10]
11、python中生成随机整数、随机小数、0--1之间小数方法

import random import numpy as np # 随机整数 print(random.randint(0, 99999)) # 随机小数 print(np.random.randn()) # 随机 0-1 小数 print(random.random())

12、避免转义给字符串加哪个字母表示原始字符串?

import re a = 'power.top*one' res = re.match(r'.*', a) print(res) # 注:r 只针对于Python代码生效,与re正则并无关系

13、<div class="nam">中国</div>,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的

import re a = '<div class="nam">中国</div>' res = re.match(r'<div class=".*">(.*)</div>', a) res.group(1) res = re.findall(r'<div class=".*">(.*)</div>', a) print(res[0])
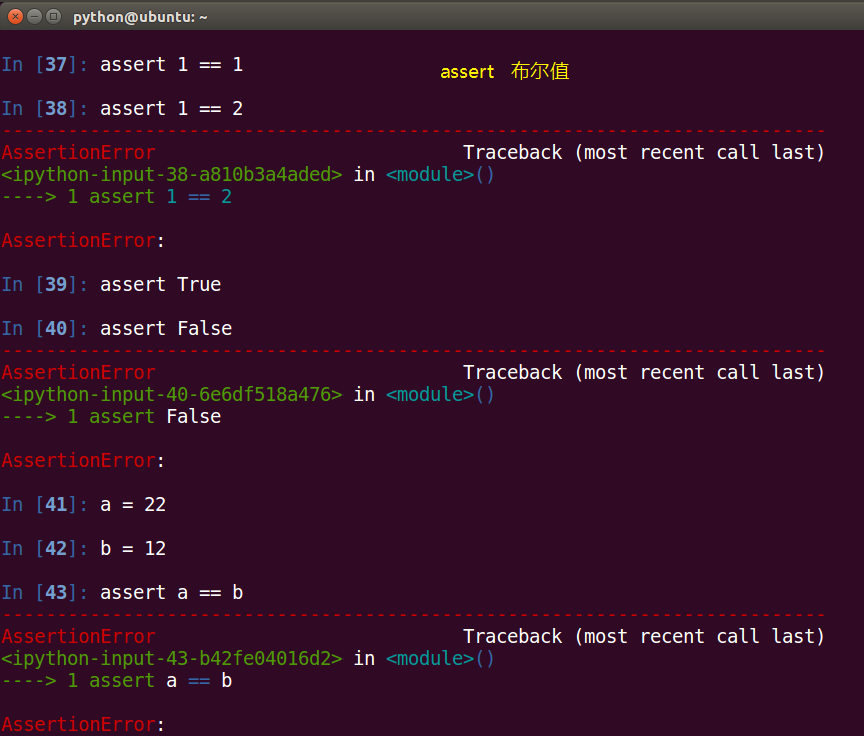
14、python中断言方法举例
15、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
16、10个Linux常用命令
cd、ls、cp、mv、mkdir、touch、cat、grep、echo、pwd、more、tar、tree
17、python2和python3区别?

1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python3的range 返回可迭代对象,python2的range返回列表,xrange返回迭代器
for ... in 和 list() 都是迭代器
3、python2中使用ascii编码,python中使用utf-8编码 4、python2中unicode表示字符串序列,str表示字节序 python3中str表示字符串序列,byte表示字节序列 5、python2中为正常显示中文,引入coding声明,python3中不需要 6、python2中是raw_input()函数,python3中是input()函数
18、列出python中可变数据类型和不可变数据类型,并简述原理
可变类型: 列表、字典 不可变类型:字符串、整型、浮点型、元组
19、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"

s = "ajldjlajfdljfddd"
# set方法
li = list(set(s))
li.sort() # 注:sort 没有返回值
# 循环遍历
li2 = []
for i in s:
if i not in li2:
li2.append(i)
li2.sort()
20、用lambda函数实现两个数相乘
nu = lambda x, y: x*y nu(2, 3) lambda 函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数。 1、lambda函数比较轻便,即用即扔,很适合的场景是,需要完成一项功能,但此功能只在此一处使用,连名字都很随意的情况下。 2、匿名函数,一般用来给 filter、map 这样的函数式编程服务。 3、作为回调函数,传递给某些应用,比如消息处理。

21、字典根据键从小到大排序
dict(sorted(di.items(), key=lambda x: x))
22、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"

from collections import Counter
s = "kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
Counter(s)
# 输出结果
Counter({'l': 9, 'h': 6, ';': 6, 'f': 5, 'a': 4, 'd': 3, 'j': 3, 's': 2, 'b': 1, 'g': 1, 'k': 1})
23、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳

import re
a = "not 404 found 张三 99 深圳"
# 第一种方式
res = re.sub('[^\u4e00-\u9fa5]', '', a).split()
print(res)
# 第二种方式
value = re.findall(r'[^a-zA-Z\d\s]+', a)
print(''.join(value))

24、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]

# filter(function, iterable) function -- 判断函数。 iterable -- 可迭代对象。
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def info(x):
if x % 2 == 1:
return x
print(list(filter(info, a)))

25、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
li = [i for i in a if i % 2 == 1]
26、正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用
27、a=(1,)b=(1),c=("1") 分别是什么类型的数据?
元组 : a=(1,)
整型 :b=(1)
字符串 : c=("1")
28、两个列表合并为一个列表

#[1,2,5,6,7,8,9] li1 = [1,5,7,9] li2 = [2,2,6,8] # 第一种方法 li3 = list(set(li1 + li2)) print(li3.sort()) # 第二种方法 li1.extent(li2) li5 = list(set(li1)) li5.sort() print(li5)
# 第三种方法 li6 = li1 + li2 print(li6)

29、用python删除文件和用linux命令删除文件方法
python: os.remove(文件名) linux: rm 文件名
30、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”

from datetime import datetime
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
print(datetime.strftime(datetime.now(), "%Y-%m-%d %H:%M:%S"))
# Out[12]: '2019-03-30 18:57:55'
logging模块的日志等级:
DEBUG 最详细的日志信息,典型应用场景是:问题诊断
INFO 信息细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作
WARNING 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的
ERROR 由于一个更严重的问题导致某些功能不能正常运行时记录的信息
CRITICAL 当发生验证错误,导致应用程序不能继续运行时记录的信息
logging.debug('debug message')
logging.info('info message')
logging.warn('warn message')
logging.error('error message')
logging.critical('critical message') 
31、写一段自定义异常代码
li = [1, 2, 3, 0]
for i in li:
try:
if i == 0:
raise Exception("遍历得到0")
except Exception as e:
print(e)
32、正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配 (.*?)是非贪婪匹配,会把满足正则的尽可能少匹配
33、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
li = [[1, 2], [3, 4], [5, 6]] lis = [j for i in li for j in i]
34、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果

x="abc" z=["d","e","f"] y="def" x.join(y) # Out[202]:'dabceabcf' x.join(z) # Out[202]: 'dabceabcf'
35、举例说明异常模块中 try except else finally 的相关意义

li = [1, 2, 3, 0]
for i in li:
try:
if i == 0:
raise Exception("遍历得到0")
except Exception as e:
print(e)
else:
print(i)
finally:
print("顺利跑完")
# Out[28]:
1
顺利跑完
2
顺利跑完
3
顺利跑完
遍历得到0
顺利跑完
try: 放置可能出现异常的代码
except: 当出现异常时,执行此处代码
else: 当程序没有没有出现异常时,执行此处代码
finally: 不管程序是否出现异常,此处代码都会执行

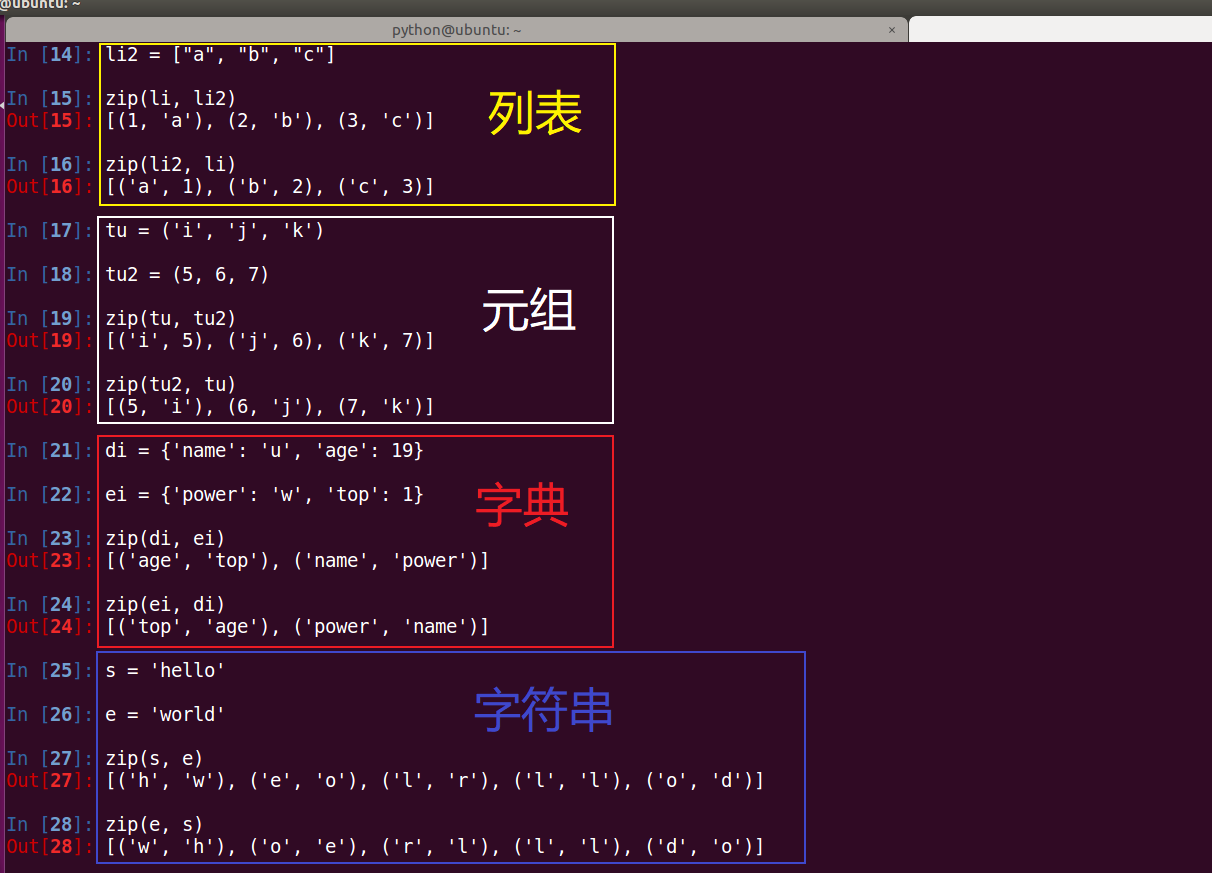
36、举例说明zip()函数用法
37、a="张明 98分",用re.sub,将98替换为100
res = re.sub(r'\d+', '100', a) print(res)
38、写5条常用sql语句
# 增
insert into student (name, age) values ("power", 22);
# 删
delete from student where name="power";
# 改
update student set age=12 where name="power";
# 查
select name from student where id=2;
39、简述ORM

O 模型类对象 R 关系 M 映射 : 模型类对象和数据库的表的映射关系 ORM拥有转换语法的能力,没有执行SQL 语句的能力,执行SQL语句需要安装数据库驱动(python3解释器需安装PyMySQL, python2解释器需安装mysql)django只能识别mysqldb驱动,需要给pymysql起别名骗过django ORM作用: 1. 将面向对象的操作数据库的语法转换为相对应SQL语句 2. 解决数据库之间的语法差异性(根据数据库的配置不同,生成不同的SQL语句)

40、a="hello"和b="你好"编码成bytes类型
a="hello" print(b'a') b="你好" print(b.encode())
41、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存。 2、循环代码的优化,避免重复执行循环代码。 3、核心模块用Cython PyPy等,提高效率。 4、对于不同场景使用多进程、多线程、协程,充分利用CPU资源。 5、多个if elif条件判断,将最有可能先发生的条件放到前面写,可减少程序判断的次数。

42、遇到bug如何处理

0、查看报错信息(错误日志信息),分析bug出现原因。 1、在接口的开头打断点,单步执行往下走,逐渐缩小造成bug的代码范围。 2、【可选】在程序中通过 print() 打印,能执行到print() 说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log 2、若自己无法解决,利用搜索引擎将报错信息进行搜索。 3、查看官方文档,或者一些技术博客。 4、查看框架的源码。 5、对于bug进行管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录。

43、正则匹配,匹配日期2018-03-20

a= 'aa20kk18-power03-30oo' res = re.findall(r'[-\d]+', a) data = ''.join(res) print(data) Out[82]: '2018-03-30'

44、list=[2,3,5,4,9,6],从小到大排序,不许
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









