







 这篇博客探讨了排序算法的实验报告,包括冒泡排序、选择排序、插入排序、合并排序和快速排序的原理、时间复杂度分析以及实际运行效率。实验表明,快速排序和合并排序在大规模数据上表现最优,而冒泡排序、选择排序和插入排序适用于小规模数据。对于一亿数据的排序,使用了计数排序,实现了线性时间复杂度。
这篇博客探讨了排序算法的实验报告,包括冒泡排序、选择排序、插入排序、合并排序和快速排序的原理、时间复杂度分析以及实际运行效率。实验表明,快速排序和合并排序在大规模数据上表现最优,而冒泡排序、选择排序和插入排序适用于小规模数据。对于一亿数据的排序,使用了计数排序,实现了线性时间复杂度。
第一次写博客,排版可能存在一定问题,还请见谅。
分享这篇实验报告的目的是想这可以帮助有需要的同学,毕竟我在进行该课程中也参考了许多前人的代码(前人code,后人copy)
该课程是存在查重系统的,可以借鉴,但不要照搬别人的实验报告和代码
实验目的
1. 掌握选择排序、冒泡排序、合并排序、快速排序、插入排序算法原理
2. 掌握不同排序算法时间效率的经验分析方法,验证理论分析与经验分析的一致性
3.完成一亿数据排序
实验原理
通过对大量样本的测试结果,统计不同排序算法的时间效率与输入规模的关系, 通过经验分析方法,展示不同排序算法的时间复杂度,并与理论分析的基本运算次数做比较, 验证理论分析结论的正确性。
实验过程及内容:
冒泡排序:
算法原理:
比较相邻的元素,如果前一元素大于后一元素,则两元素交换,最终将最大的元素送至队尾
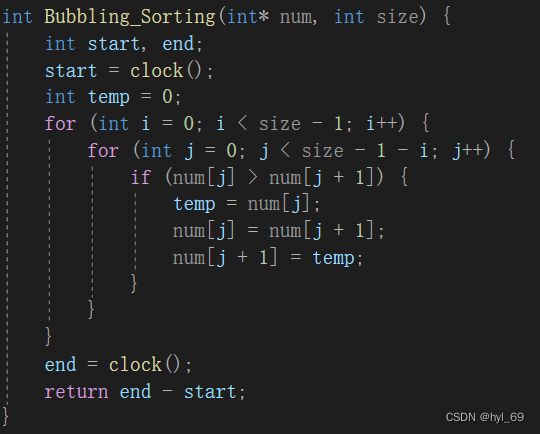
伪代码:
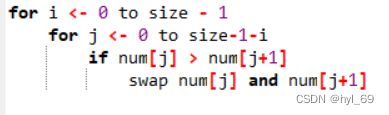
时间复杂度:
比较次数:[n*(n-1)] / 2
最好情况:O(n^2)
最坏情况:O(n^2)
平均时间复杂度:O(n^2)
选择排序
算法原理:
每趟遍历都会选择最大的元素,放置到队末,经过多次遍历最终形成有序序列
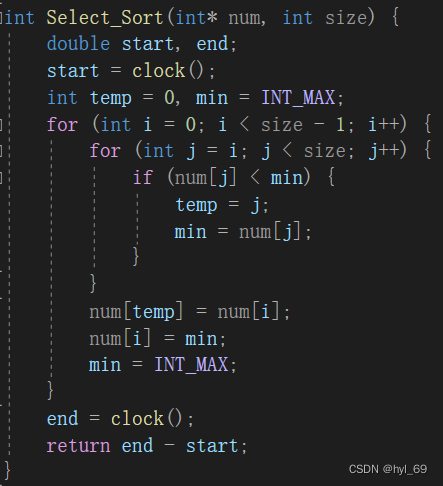
伪代码:

时间复杂度:
比较次数:[n*(n-1)] / 2
最好情况:O(n^2)
最坏情况:O(n^2)
平均时间复杂度:O(n^2)
插入排序
算法原理:
将序列分为有序序列和无序序列两部分,有序序列最初只有一个元素,每趟将一个无序序列中待排序的对象,插入到前面已经排好序的有序序列的适当位置上, 直到对象全部插入为止。
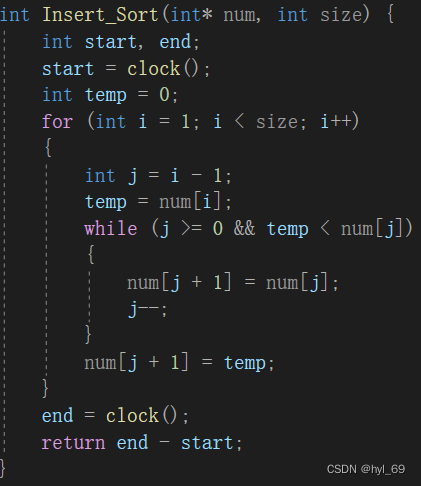
伪代码:

时间复杂度:
比较次数:不确定
最好情况:O(n)
最坏情况:O(n^2)
平均时间复杂度:O(n^2)
合并排序
算法原理:
合并排序代码分为两部分,第一部分为划分,使用二分的方法将无序序列划分为子序列,直到每个子序列都只有一个元素。然后开始第二部分合并,将两个有序子序列合并成一个有序子序列,直到只存在一个子序列为止
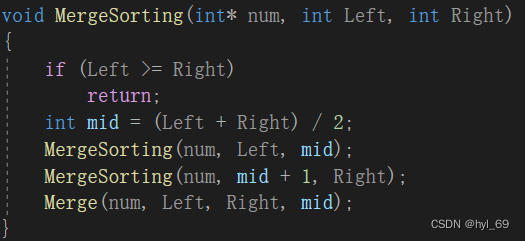
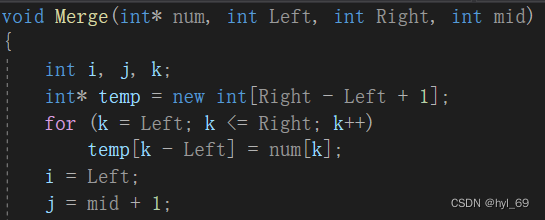
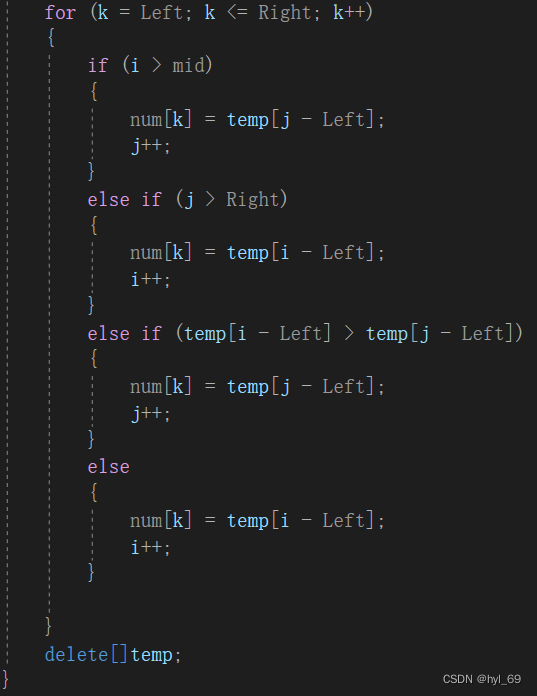
伪代码:

时间复杂度:
所有情况的递归式
T(n)=2T(n/2)+n
T(1)=1
T(n)=2²T(n/2²)+2n
......
T(n)=2^kT(1)+kn
2 =n
k=log₂n
算法复杂度为O(nlogn)
快速排序
算法原理:
选择序列第一个元素为基准,序列中比基准大的元素移至右侧,比基准小的元素移至左侧,以基准为界划分成两个子序列,然后子序列再进行快速排序,直到每个子序列只有一个元素为止

伪代码:

时间复杂度:
如果每执行一次快速排序,两个子序列长度相同,则为最理想的情况,时间复杂度为O(nlog2n) 如果每执行一次快速排序,其中一个子序列长度只为1,则为最糟糕的情况,时间复杂度为O(n^2)
最坏情况:(每次只划分一个数字)
T(n)=T(n-1)+n-1
T(1)=1
T(n)=n(n-1)/2
最好情况:(每次刚好均分)
T(n)=2T(n/2)+n-1
T(1)=1
T(n)= O(nlog2n)
最坏情况下时间复杂度为O(n^2)
算法时间理论效率分析的曲线和实测的效率曲线
//文章显示存在一定问题,有些表格数据不全,会以图片形式展现,请见谅
| 10000 | 20000 | 30000 | 40000 | 50000 | 60000 | 70000 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









