







 本文介绍了对应分析(Correspondence Analysis)这一统计方法,用于分析多个分类变量间的关系,尤其在分类变量较多时,作为卡方检验和逻辑回归的替代。通过SPSS软件演示了一个关于冰咖啡品牌与感知图像的对应分析案例,展示了如何进行数据预处理、卡方检验和对应分析操作,以及如何解读分析结果,帮助理解不同品牌与形象特征的关联。
本文介绍了对应分析(Correspondence Analysis)这一统计方法,用于分析多个分类变量间的关系,尤其在分类变量较多时,作为卡方检验和逻辑回归的替代。通过SPSS软件演示了一个关于冰咖啡品牌与感知图像的对应分析案例,展示了如何进行数据预处理、卡方检验和对应分析操作,以及如何解读分析结果,帮助理解不同品牌与形象特征的关联。
在开展统计分析的过程中,分类变量(定序和定类变量)是我们研究的一个重点。通常我们分析分类变量间关系时,最常用的分析方法是卡方检验,其次是逻辑回归和对数线性模型等。
如果类别变量的分类较少,我们可以通过卡方检验判断行变量和列变量间是否相互独立,同时还可以通过查看列联表或进行进行事后两两比较,判断各变量的不同组别间具体存在怎样的差异
但如果涉及的分类变量较多时,卡方检验能给的信息就很有限了,它并不能告诉我们两个变量之间具体存在怎样的联系。而逻辑回归方法和对数线性模型等方法的操作和解释相对比较复杂,学起来比较让人头疼。所以今天我想向大家介绍对应分析方法。
对应分析方法又称相应分析,它善于展示两个/多个分类变量各类间的关系,能够将交叉列联表的数据信息转化为二维散点图,直观、简单的描述庞杂的列联表数据中所蕴含的对应关系。
它是于1970年由法国统计学家J.P.Beozecri提出来的,起初在法国和日本最为流行,后来引入到美国,是在R型和Q型因子分析基础上发展起来的一种多元统计方法。
简单对应分析是分析某一研究事件两个分类变量间的关系,其基本思想以点的形式在较低纬的空间中表示列联表的行和列中各元素的比例结构,可以在二维空间更加直观的通过空间距离反映两个分类变量间的关系。属于分类变量的典型相关分析。
Fisher在1940采集了5387名苏格兰人的眼睛和头发颜色数据,并利用对应分析方法分析了眼睛颜色和头发之间是否存在显著关系,这是利用对应分析方法开展的经典案例。有关这个案例的分享很多,感兴趣的读者可以到网上搜索查看。
案例数据集介绍
接下来我将用SPSS中的自带数据集coffee.sav向大家介绍对应分析方法。
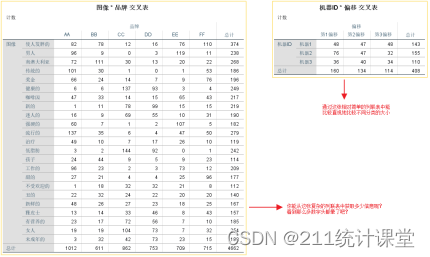
研究者收集了4662份有关6个冰咖啡品牌与23张感知图像的数据,其中6个品牌分别表示为AA、BB、CC、DD、EE和FF,23张感知图像表示的是不同的形象特征。研究者希望知道这6个冰咖啡品牌和23种感知图像之间是否存在何种联系,即不同的冰咖啡品牌是否更倾向于某种品牌形象。
打开数据集:
选择文件 -> “欢迎”对话框(SPSS25及以上版本),在欢迎对话框中选择样本文件, 选择coffee.sav,选择打开。SPSS会自动打开这份数据文件。
.
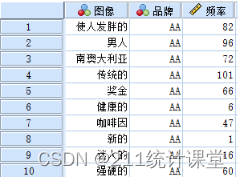
该数据集的部分数据截图如下所示:
数据分析1:个案加权
当涉及到分类变量的频数分析时,一般都需要对数据进行加权处理。(扩展阅读:加权到底是怎么回事儿?)
在本案例中,频率变量记录了不同品牌与不同图像属性相关的频数,因此我们需要对频率变量进行加权。
加权操作步骤:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7196
7196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









