






大数据概论
大数据的概念
大数据的特点以及集群分布方式
Apache ZooKeeper
ZooKeeper的功能与作用
ZooKeeper的原理架构
ZooKeeper的shell指令
ZooKeeper的典型应用
一、大数据导论
1.1 数据与数据分析
什么是数据??
数据就是生产生活中客观事务的记录或总结
这些记录或总结可以反映出事物的某种状态或数值
什么是数据分析?
让数据开口说话
通过一些经验或者专业技巧让数据反映出客观规律或真实状态
数据分析的作用?(在商业中)
让数据分析的结果给企业的运营和决策提供依据
数据分析不是企业的决策者,只能辅助决策,不能左右结果
1.2 数据分析的作用
原因分析:历史数据分析,分析当前情况产生的原因
现状分析:分析当下的数据,对于现有数据进行分析
预测分析:根据历史数据推论数据未来的走势或者未来的值(深度学习,机器学习等....)
数据分析的三种分析形式和大数据的三种分析方式正好一一对应
离线分析
分析现有的数据,历史数据,面向过去进行分析
在开发中按照一定的时间间隔进行分析 T+1(每天分析一次) T+7(每周分析一次)
实时分析
分析实时产生的数据,当下数据,面向当下进行分析
例如我们天猫双十一的数据可视化大屏就用到了实时分析
一般实时分析和离线分析相比计算间隔更小,以秒或毫秒为单位进行计算累加
机器学习
基于历史数据和当下数据预测未来的时间走向或结果
偏重于算法和概率统计
2 大数据时代
大数据时代,我们面临的挑战是海量数据的存储和计算
2.1大数据5v特征
数据量大
数据来源多样化
价值密度低
数据增长块
数据准确性和可信赖度低
2.2 分布式和集群
分布式:
分布式服务: 将服务端拆分为多个应用部署在不同的服务器上,共同对外提供服务
分布式存储: 将数据文件拆分为多个块,存储在不同的服务器上,通过分布式存储服务进行统一的增删改查
分布式计算: 将计算程序发送到每一个服务器上,根据使用服务器的硬件资源进行计算,最终将结果进行合并
集群:
主从架构: 有主角色和从角色, 一般主角色负责发号施令,从角色负责干活
主备架构: 有一个主角色和一个备用角色,如果主角色宕机,备用机可以上位,防止服务整体崩溃.
二、Apache ZooKeeper
2.1 ZooKeeper的概念
ZooKeeper是一个分布式协调服务,主要解决服务间的一致性问题(重要)
集群环境下,服务间配合的最大问题就是能否统一执行或者稳定通讯
ZooKeeper就是通过一致性特点,保证每一台服务接到的指令相同,或者给服务执行排序
ZooKeeper的本质是分布式小文件存储系统
ZooKeeper是一个标准的主从架构集群 (一主多从)
ZooKeeper最重要的特性就是全局数据一致性(保证当前集群中,所有服务存储的数据时完全一致的)
2.2 ZooKeeper集群角色
主角色 leader
事务型请求(写操作)的唯一调度者和处理者
可以理解为董事长
从角色 follower
进行非事务型操作,如果接收到事务型操作,将会把指令发送给leader
参与ZooKeeper集群内部的选举(选举leader)
可以理解为无管理全的公司股东
观察者角色 observer
observer角色不是必要的,可以没有,当集群规模不大时,一般没有观察者角色
进行非事务型操作,如果接收到事务型操作,将会把指令发送给leader
不参与ZooKeeper集群内部的选举(选举leader)
可以理解为无话语权的打工人
事务型操作: 可以理解为写入操作(增删改)
非事务型操作: 可以理解为读取操作(查)
思考: 为什么要设置观察者角色呢?
不是每一台服务器都适合做leader,做leader的服务器配置要求相对较高
当我们投票时所有的follower服务是无法进行非事务型操作(读取操作)的,此时observer依然可以读取数据
集群角色间的关系图
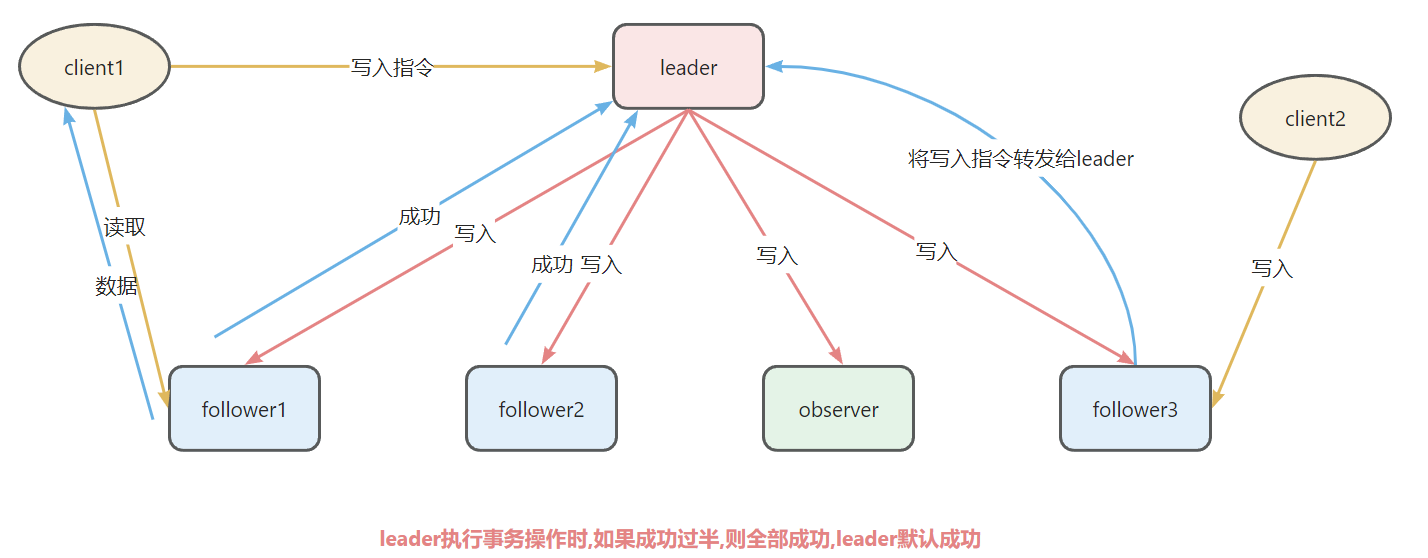
zk集群过半原则拓展:
当服务启动时,启动的服务数量超过集群总数的一般以上,服务才能启动成功
当服务宕机数量达到集群总数的一般以上时,集群服务宕机,服务不可用
2.3 ZooKeeper的Shell指令以及相关机制
启动客户端的指令
zkCli.sh -server ip # ip可以为node1,node2,node3,也可以不写,如果不写就证明访问的是本地服务zk四种节点模式
在ZooKeeper中可以创建永久节点和临时节点
创建节点时默认为永久节点,如果要创建临时节点需要加-e
每个节点可以是序列化节点,也可以是非序列化节点
创建节点时默认为非序列化节点,如果要创建序列化节点需要加-s
永久非序列化节点

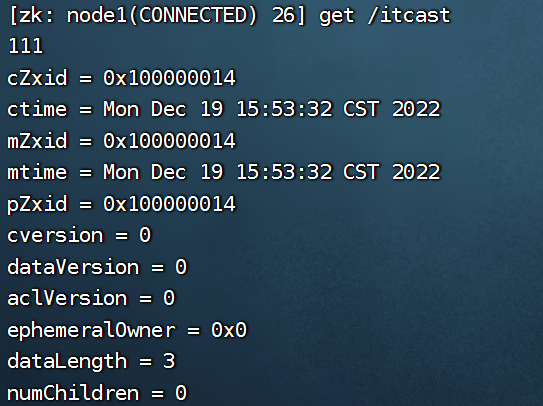
临时非序列化节点(-e)
临时节点在使用时会绑定一个会话编号(也就是我们的客户端),当这个会话(客户端)关闭时,该节点将会被销毁
临时节点的作用:
当我们的服务断开连接时,可以将其保存的数据删除
我们可以根据节点的数量判断任务数,服务数等...
永久序列化节点(-s)
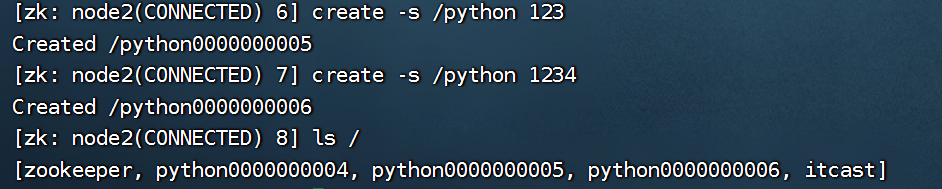
创建一个节点时,会给几点一个序号,该需要单调递增, 防止节点名称重复
序列化节点,可以多次重复创建同名节点
序列化节点可以通过需要查看节点创建的顺序
序列化节点一定程度上保证了ZooKeeper上数据的顺序性
临时序列化节点(-e -s)

2.4 ZooKeeper的监听机制
监听需要几步才能实现
举例: 想监听一个人, 在他的住所放置监听设备,如果说了一些话会同步给我
第一步: 设置监听
第二步: 执行监听
第三步: 触发监听事件,发送通知给设置监听的一方 callback(回调)
ZooKeeper中监听的是什么呢?
ZooKeeper中监听的是节点的变化情况
ZooKeeper是使用客户端监听服务端 -- 一般的服务中都是服务端监听客户端
zk不是角色间的互相监听,而是客户端监听服务端,因为zk内部是全局数据一致的,所以不需要设置监听
服务端监听的节点发生了变化需要告知设置监听的客户端
监听的是什么事
就是服务端znode节点的变化 包括但不限于节点增加,节点删除,节点修改等....
可以设置监听的指令
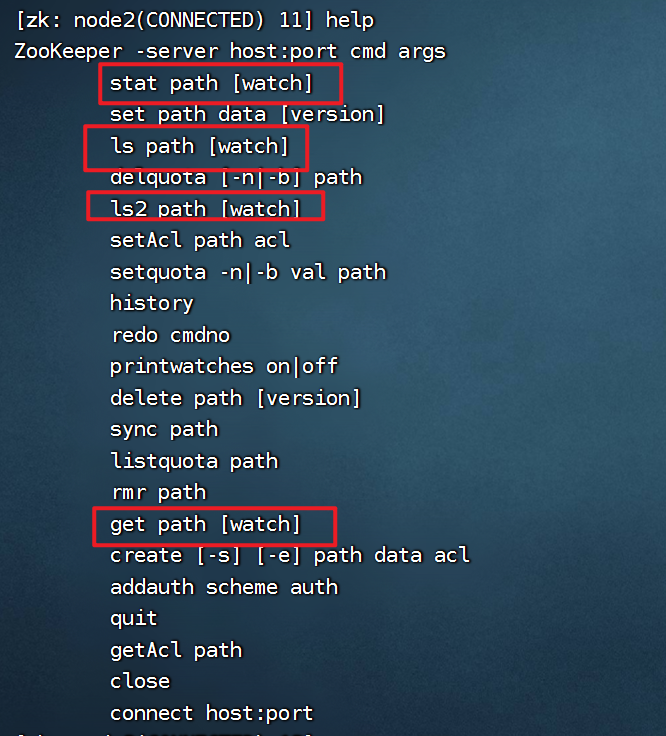
使用终端指令设置监听
# ls path [watch]
# get path [watch]
# 1. 设置监听 (node1的会话中)
ls /itcast watch
# 2. 触发监听 (node2的会话中)
create /itcast/python 1233
# 3. 回调通知客户端(node1的会话)
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/itcastzk的监听特性:
先注册后触发: 用户主动注册服务端监听
注册后监听只能使用一次: 监听一旦被触发将失效,需要重新注册后才能再次使用
异步通知:设置监听后可以进行其他操作,不需要等待通知
使用event事件来进行封装: java的一个事件类可以说明发生了什么在哪里发生的等
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/itcast
state: 异步连接 type: 子节点发生变化 path:发生变化的节点为/itcast
2.5 zk功能主要来源于其监听特性和节点的特殊性
特殊1: znode节点具有临时特性
特殊2: znode节点具有序列化特性
特殊3: zk有监听机制可以满足客户监听服务端的变化需求
特殊4: 在非序列化节点下路径是唯一的,不能重名
2.6 zk典型应用
数据发布与订阅机制
举例: 统一全局的配置文件
我们要求集群中所有服务的profile文件中的配置信息是完全相同的,但是我们逐一修改每一台服务中的配置文件非常麻烦
如果我们采用发布订阅机制,则会变得很简单
在其中一个节点中存放配置文件,或者在修改配置文件后,修改其相对应的节点
其他所有的客户端都监听这个节点,由于全局数据一致性,如果这个节点发生了改变,所有的服务都会收到通知
此时他们就会同时去zk中获取新的配置信息
分布式锁
我们利用每一个节点路径只能创建一次的特性
我们可以使用两个服务同时注册这个节点,谁注册成功了,谁就使用这个数据
如果没有注册成功的则设置监听,如果注册成功的服务使用数据结束,则删除节点
注册监听的节点收到通知后继续创建节点使用数据
分布式锁保证了同一时间只有一个服务再使用该数据,防止数据出现错误,或者说防止出现资源竞争的现象.
集群选举机制
此处分为两种一个是zk集群内部选举,另一种是帮助其他服务进行选举
集群内部选举(重点)
举例: 例如有zk1-zk5一共5台服务,分别部署了ZooKeeper服务,myid的值从1-5

选举流程:
zk1先启动,先进行投票,将票投给自己
zk1: 1票
zk2再启动,将票投给自己
zk1: 1票 zk2: 1票
改票环节,查询谁的myid更大,zk2更大,所以zk1改票投给了zk2
zk1:0票 zk2: 2票
zk3启动, 将票投给自己
zk1: 0票 zk2: 2票 zk3: 1票
改票环节,查询谁的myid更大, zk3的更大,所以zk1,zk2将票投给了zk3
zk1: 0票 zk2: 0票 zk3: 3票
node3获取3票,此时已经票数过半,所以直接当选为leader, 其余主机自动变为follower
node4启动,直接变为follower
node5启动,直接变为follower
注意: node4和node5 是没有来得及选举就已经有人当选了,不是没有选举权,而observer是真的没有选举权
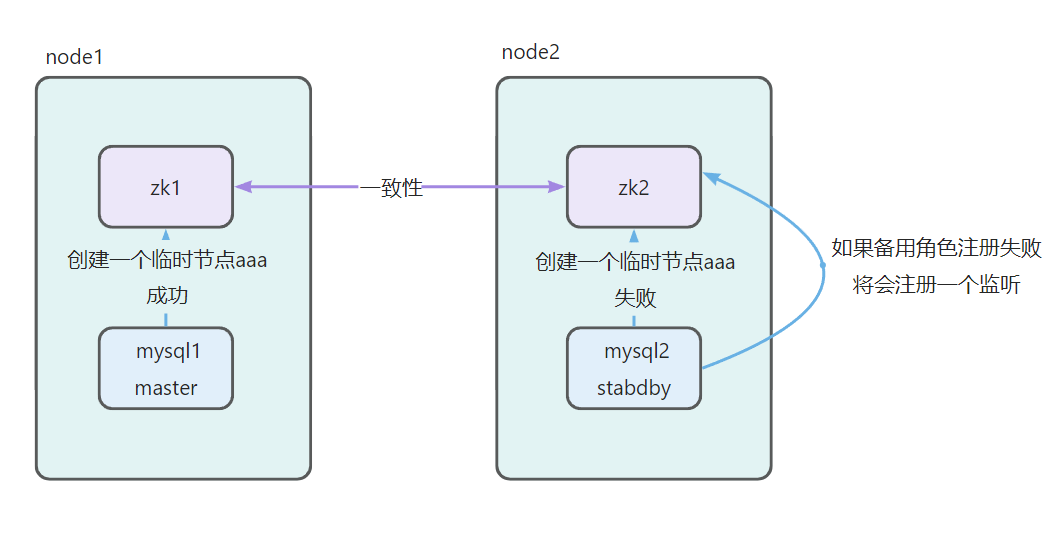
抢占选举机制: 多个服务同时注册一个节点,谁注册成功,谁就是主机,其余都为从机
排序选举机制: 多个服务同时注册一个序列化节点,谁的序号更小则为主机,其余都为从机















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









