







文章目录
在Vue和flask之间使用JWT认证
问题的提出
之前在做项目的时候,为了图方便,使用的前后端保存登录凭证方法是后端使用session,前端使用sessionstorage,但是老师提出了使用JWT(Json Web Token)比较好,因为session storage有太多的弊端。
以下是我对自己学习知识的一些总结:
1)传统session的问题
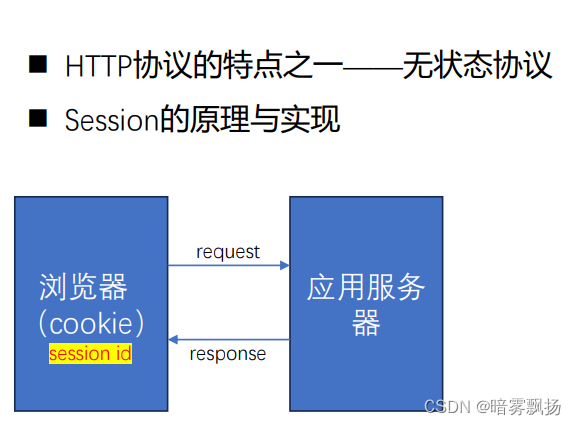
1、认证方式(HTTP是无状态协议),对于事物处理没有记忆能力。
2、在用户经过登录认证后,应用需要在服务器端做一次记录,以便下次用户请求的鉴别,这样将数据都保存在服务器中会使服务器开销变大。
3、对于分布式应用会出现无法保证每一次客户端请求都传回保存了该用户信息到内存的那台服务器上
2)使用JWT的好处
可以通过URL,POST参数在HTTP Header中发送,数据量小,传输快
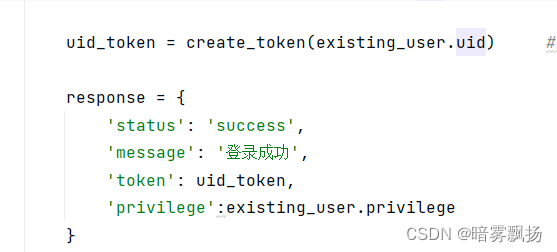
使用JWT可以直接将uid加密放入token中,然后放在response里传输给前端:
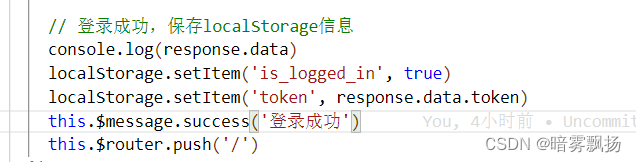
前端接收到response以后将token拿出来保存在localStorage中:
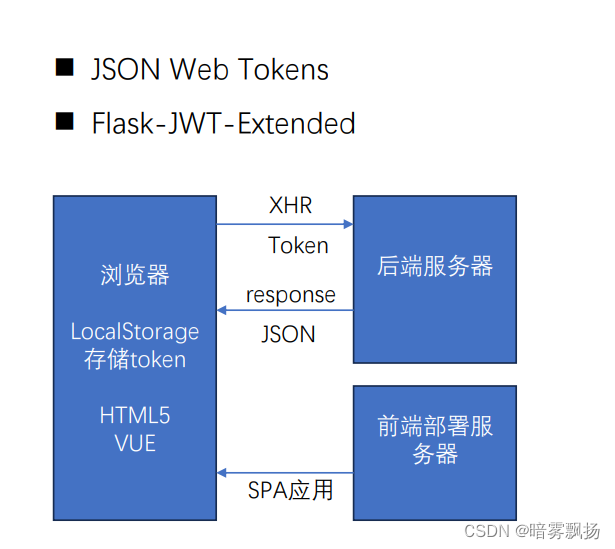
这样就可以保证,当前端(客户端)再次发送事务操作(request)给后端的时候,后端可以去验证token里面的密钥,签发凭证,生效时间等等(可以保证这是我们后端服务器发送出去的token,而不是别人伪造的request用来攻击你的服务器的,保证了安全性)
1、数据库的修改
1)flask-SQLAIchemy的ORM模型
首先我需要修改我的数据库:
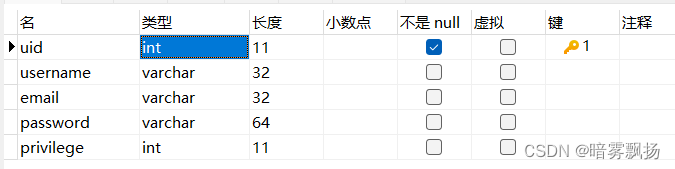
(当然对应的后端flask-SQLAIchemy使用的ORM模型也要修改)
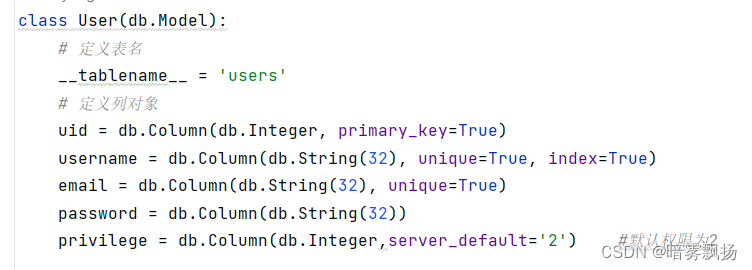
(请注意设置默认值的方法)
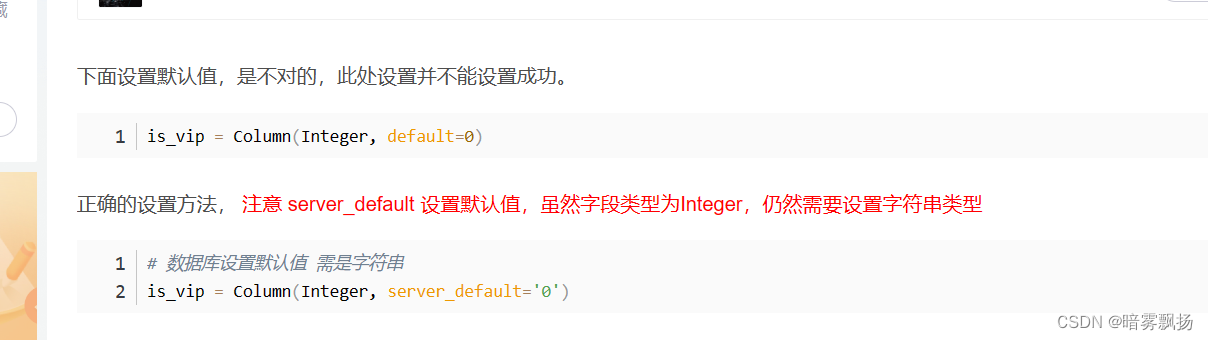
2)对password的哈希加密

我这里使用的SHA-256加密法
(注意!!!SHA256输出256位,用Hex表示是64个字符,数据库设置的参数长度不能比它短)
import hashlib
#password哈希加密
password_hash = hashlib.sha256(password.encode('utf-8')).hexdigest()
3)加盐
由于SHA-256加密法每次加密一个字符串,生成的随机字符串是同一个,所以可能被彩虹表破解密码,这个时候可以使用加盐操作有效防止彩虹表。
(注意!!!“加盐”操作是在加密之前;因为如果加密之后再“加盐”的话人家多收集几个密码就能看出来你加的“盐”了)
#密码加盐(有效防止彩虹表)
password = password+"cy"
#password哈希加密
password_hash = hashlib.sha256(password.encode('utf-8')).hexdigest()
2、后端pyJWT
1)JWT的构成(头部、载荷与签名)
一个JWT实际上就是令牌token,就是一个String字符串,由3部分组成,中间用点隔开。
令牌组成:
1、标头(Header)
2、有效载荷(Payload)
3、签名(Signature)
token格式:head.payload.singurater 如:xxxxx.yyyy.zzzz
Header
代表了加密算法和token类型(“JWT”), 若不显示指定, 默认为:
{
"alg": "HS256",
"typ": "JWT"
}
Payload
用来存放实际需要传递的数据。JWT 规定了7个官方字段,供选用。除了以上字段之外,你完全可以添加自己想要的任何字段,但是!!!由于jwt的标准,信息是不加密的,所以一些敏感信息最好不要添加到json里面
iss (issuer):签发人
exp (expiration time):过期时间
sub (subject):主题
aud (audience):受众
nbf (Not Before):生效时间
iat (Issued At):签发时间
jti (JWT ID):编号
例如:
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022,
"exp": 451154141
}
Signature
为了得到签名部分,你必须有编码过的header、编码过的payload、一个秘钥(这个秘钥只有服务端知道),签名算法是header中指定的那个,然对它们签名即可。
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)
算出签名以后,把 Header、Payload、Signature 三个部分拼成一个字符串,每个部分之间用"点"(.)分隔,就可以返回给用户。需要提醒一下:base64是一种编码方式,并非加密方式。
2)JWT的实际使用
我这里只是举个例子,可以结合JWT知识自定义加密和解密的方法构造
token加密
创建一个create_token方法用于加密(当然名字可自定义)
def create_token(uid: str):
dic = {
'exp': int(time.time()) + int(__time__) , # 结束时间
'iss':'anwupiaoyang', #签名
'data': {
'uid': uid # 内容,一般存放该用户id
},
}
#数据,密钥,编码模式
token = jwt.encode(dic, '__secret__', algorithm='HS256') # 加密生成字符串
return token
token解密
创建一个parse_token方法用于解密
def parse_token(token: str):
token_bytes = bytes(token,'utf-8') # 将字符串类型的 token 转换为字节类型
dic = jwt.decode(token_bytes, '__secret__', issuer='anwupiaoyang' , algorithms=['HS256']) # 解密,校验签名
return dic
token前后端传输流程图
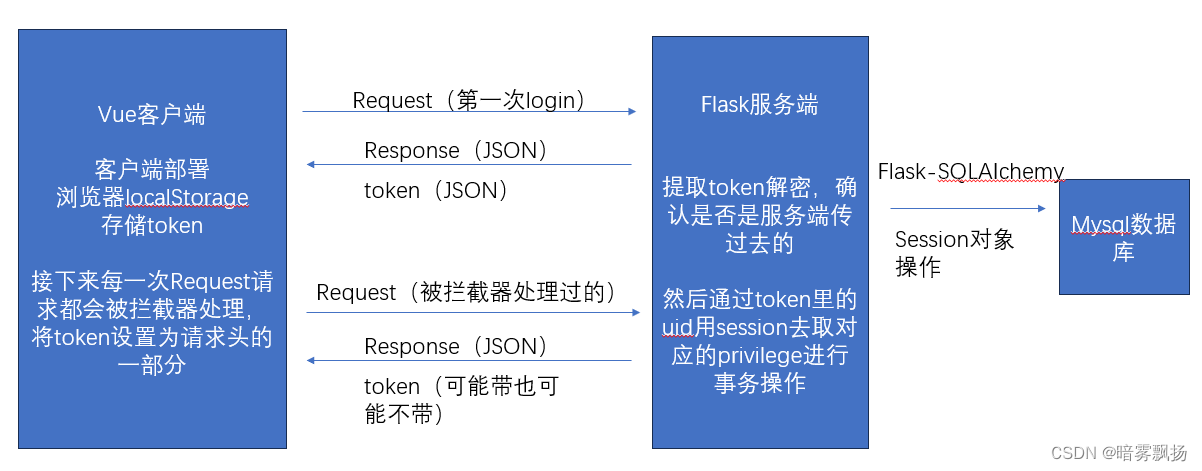
当然!这里某位大佬告诉我,我们不能将privilege(权限)这种敏感字段放在token里,被人拦截获取后容易被攻击;但是我们也不要用uid去session查找对应privilege,这样会加大服务器负担;应该将privilege放在cookie中传输
3、前端的拦截器
拦截器详解:
我们将加密过的token放在response里传到前端以后,前端需要做一个请求拦截器,以便之后前端(客户端)向后端(服务端)发送的每一个request请求自动包含JWT token作为请求头的一部分,让后端进行身份验证。
axios基础设置

请求拦截器
// 请求拦截器,在发送请求前设置Authorization请求头
instance.interceptors.request.use(config => {
const token = localStorage.getItem('token'); //获取存储在localStorage中的toke
const isLoggedIn = localStorage.getItem('is_logged_in'); //获取是否登录的状态值
if (token&&isLoggedIn) {
//将token设置为请求头的Authorization字段的值
//以后每个请求中自动包含JWT token作为请求头的一部分,并发送到后端进行身份验证
config.headers['Authorization'] = `Bearer ${token}`;
}
return config;
}, error => {
return Promise.reject(error);
});
4、Request请求头里的token取出问题
问题:
我在将前端传送回后端的request中的headers提取出token的时候遇到了很多报错。(后来才发现,原来是请求头中取出token的方式不正确)我们要先正确的取出token才能解密。
Bytes问题:
首先报错就是bytes和string的问题:
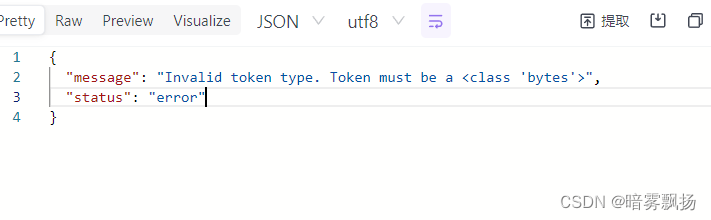
于是我去解码方法里改:

改完依然不对又尝试修改logout方法:
方法一:
@bp_logout.route('/logout', methods=['GET', 'POST'])
def logout():
try:
# 方法一:报错400
data = request.get_json()
token = str(data.headers.get('Authorization'))
token_parsed = parse_token(token) # 解密
uid = token_parsed['data']['uid'] # 通过解密得到其中的uid
# 清除用户的session
response = {
'status': 'success',
'message': '用户已登出'
}
session.clear()
return jsonify(response), 200
except Exception as e:
#处理异常,返回错误信息
response = {
'status':'error',
'message':str(e)
}
return jsonify(response),500
报错:
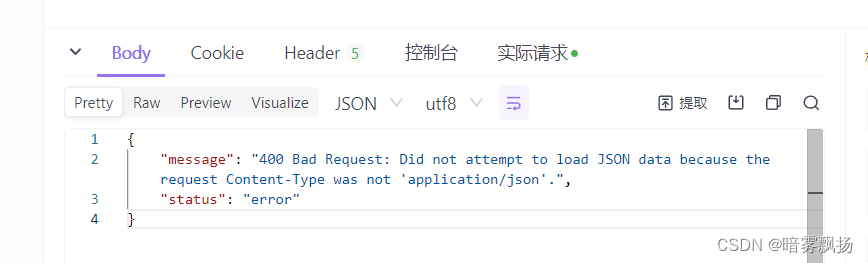
方法二:
@bp_logout.route('/logout', methods=['GET', 'POST'])
def logout():
try:
#方法二:报错(encoding without a string argument)
token = request.headers.get('Authorization')
token_parsed = parse_token(token) # 解密
uid = token_parsed['data']['uid'] # 通过解密得到其中的uid
# 清除用户的session
response = {
'status': 'success',
'message': '用户已登出'
}
session.clear()
return jsonify(response), 200
except Exception as e:
#处理异常,返回错误信息
response = {
'status':'error',
'message':str(e)
}
return jsonify(response),500
报错:
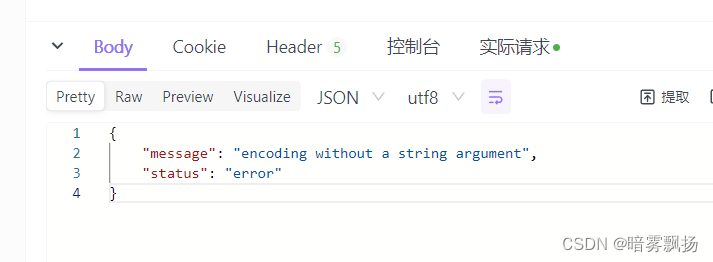
方法三:
最后终于找到正确方法:
需要先把请求头中的’Bearer '这一串字符丢掉(这是请求头默认的),也就是从请求头headers的第七位后面开始取,才能取到正确的token,取出正确的token后再去解密。
@bp_logout.route('/logout', methods=['GET', 'POST'])
def logout():
try:
#方法三:从请求头中获取 Authorization,并提取出实际的 JWT
auth_header = request.headers.get('Authorization')
if auth_header and auth_header.startswith('Bearer '):
token = auth_header[7:] # 提取出实际的 JWT
else:
raise Exception('Invalid Authorization header.')
token_parsed = parse_token(token) # 解密
uid = token_parsed['data']['uid'] # 通过解密得到其中的uid
# 清除用户的session
response = {
'status': 'success',
'message': '用户已登出'
}
session.clear()
return jsonify(response), 200
except Exception as e:
#处理异常,返回错误信息
response = {
'status':'error',
'message':str(e)
}
return jsonify(response),500
成功以后就可以把储存在token里的信息(如:uid)拿出来进行身份验证和实务操作了~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









