







文章目录
什么是RAG
RAG的全称是检索增强生成(Retrieval Augmented Generation)。是一种LLM(Large Language Model)的应用方案。
LLM的局限性
我们使用LLM应用实际业务场景的时候不难发现一些LLM的局限性:
1、知识有局限性,模型的知识完全源于它的训练数据,也就是网络公开的数据,但无法获取一些私有,实时性的数据。说通俗点就是我们可能希望它是根据我的excel表格里的数据来统计结论,而不是根据它自己获得的数据来告诉我结论。
2、数据安全性,我们不能随意的把我们一些私密的数据发送给LLM来训练,保证自身数据私密和安全很重要。
3、数据量问题,即便要让它通过我的数据给出结论,但是可能我的数据量过大,我一个普通用户可能无法把这么多数据都传给LLM来训练。
RAG架构
以下是RAG操作的架构图:
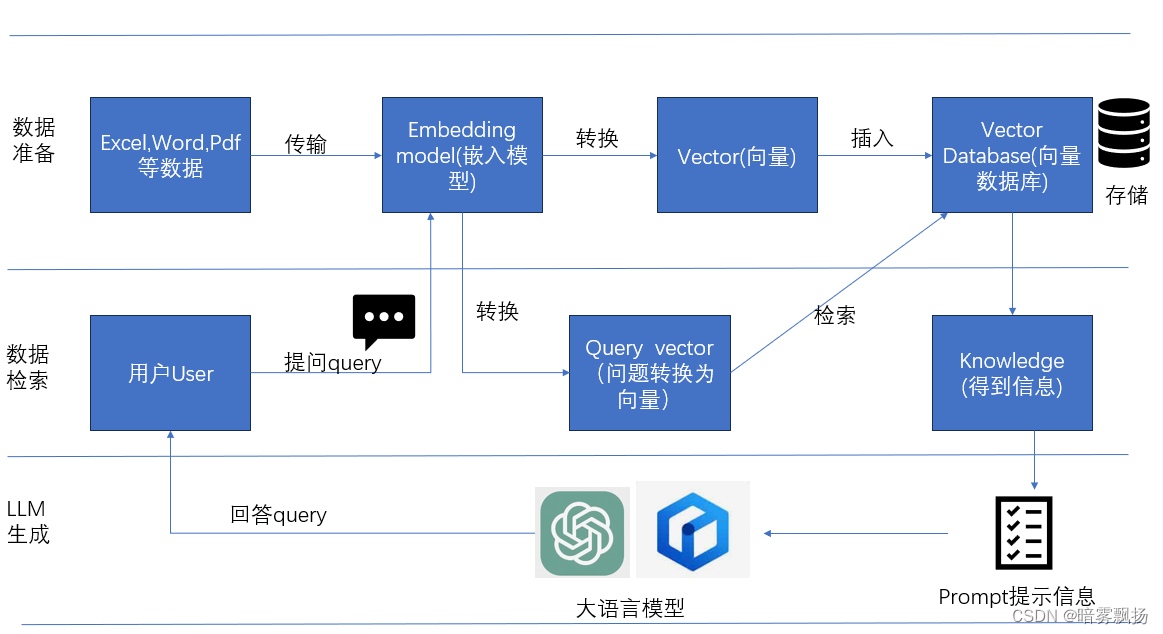
实现目标(应用场景)
我现在手中有一个包含了用户个人简历信息的Word(包括了用户的基本信息、学历、竞赛项目工作经历、掌握技能、期望岗位、期望薪资),还有一个8000多条数据的企业招聘岗位信息Excel(包括企业名字,岗位,薪资,学历要求,技能要求,以及企业地址,网站联系方式等信息)
现在要求根据用户个人简历Word来从这8000多条企业招聘岗位信息中找出该用户最适配的3条岗位信息。
向量数据库
这里选择用postgresql数据库,安装pgvector插件来作为存储向量的向量数据库。(上一期有如何配置)
创建存储表(存储vector数据)
然后我们还需要创建一个表,用于存储这些向量数据。
代码如下:
DROP TABLE IF EXISTS "public"."vector_data";
CREATE TABLE "public"."vector_data" (
"id" int8 NOT NULL DEFAULT nextval('vector_data_id_seq'::regclass),
"content" text COLLATE "pg_catalog"."default",
"embedding" "public"."vector",
"created_at" timestamptz(6) DEFAULT now(),
"updated_at" timestamptz(6) DEFAULT now(),
"is_del" bool DEFAULT false
)
;
这是flask-SQLAlchemy对应的模型类:
(我这里是flask搭建的项目连接了两个数据库,所以用到__bind_key__)
#定义第二个数据库连接db_psql的模型
class VectorData(db.Model):
__bind_key__ = 'db_psql' #模型类中设置 __bind_key__ 属性,将其绑定到第二个数据库连接
__tablename__ = 'vector_data'
id = db.Column(db.BigInteger, primary_key=True)
content = db.Column(db.Text)
embedding = db.Column(db.ARRAY(db.Float))
created_at = db.Column(db.DateTime(timezone=True), default=db.func.now())
updated_at = db.Column(db.DateTime(timezone=True), default=db.func.now())
is_del = db.Column(db.Boolean, default=False)
查询函数
在数据库中直接自定义一个函数用于后续RAG对话查询,代码如下:
CREATE OR REPLACE FUNCTION "public"."match_vector_data"("query_embedding" "public"."vector", "match_threshold" float8, "match_count" int4)
RETURNS TABLE("id" int8, "content" text, "similarity" float8) AS $BODY$
select
vector_data.id,
vector_data.content,
1 - (vector_data.embedding <=> query_embedding) as similarity
from vector_data
where vector_data.embedding <=> query_embedding < 1 - match_threshold
order by vector_data.embedding <=> query_embedding
limit match_count;
$BODY$
LANGUAGE sql STABLE
COST 100
ROWS 1000
三个参数的意思分别是:1、输入问题转换为的向量2、匹配度(0-1越高越精确)3、查找相似对象个数
基于langchain的RAG实现代码
我的检索vector的代码都基于langchain实现,具体请查看官网文档:https://python.langchain.com/docs/get_started/introduction
存储vector数据
首先要将excel里的8000多条数据全部转换为向量插入数据库中
(此功能基于langchain和flask-SQLAlchemy实现)
def insert_vector_db():
try:
# 加载文档对象
loader = CSVLoader(
file_path="src/static_files/data_all.csv", #一点点插入csv数据
encoding='utf-8' # 指定编码方式为 utf-8
)
docs = loader.load()
print("加载文件成功")
# 创建向量数据库
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000, #读取字符量
chunk_overlap=200, #上下文包括量
)
#创建OpenAIEmbeddings实例
embedding = OpenAIEmbeddings(openai_api_key="your key..."
, openai_api_base="your base...")
splits = text_splitter.split_documents(docs) # 切割
for idx,split in enumerate(splits):
content = split.page_content #page_content相当于读取的内容
vector = embedding.embed_query(content) #转换为向量
# 添加了输出idx,查看加载了多少数据
print(f"Vector{idx}:{vector}")
# print(f"Vector{idx}")
#将数据插入向量数据库
vector_data = VectorData(content=content, embedding=vector)
db.session.add(vector_data)
# 提交事务
db.session.commit()
# 关闭连接
db.session.close()
print("插入数据库成功")
response = {
'status': 'success',
'message': '岗位信息插入数据库成功',
}
return jsonify(response), 200
except Exception as e:
print(f"插入数据库失败:{str(e)}")
# 事务回滚
db.session.rollback()
response = {
'status': 'fail',
'message': '岗位信息插入数据库失败',
}
return jsonify(response), 500
如果插入数据过多,时间过长可能导致远程数据库关闭连接,报500,我直接分成1000条一次,插多次了
根据简历提问(检索vector数据库)
思路:正常来讲我们会提出一个问题query,将其转换为向量去检索数据库里最合适的那几条数据。但是这里需要LLM读取个人简历,简历的数据量也可能很大,所以我们直接把简历甩给LLM总结,得到str(resume),然后用这个总结的resume+query作为问题向LLM提问。
我们需要重载retriever检索器函数(不明白的可以去langchain文档上搜索):
#重载检索器函数
class CustomRetriever(BaseRetriever):
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
documents = [] # 初始化 documents 为空列表,以确保总是有返回值
embeddings = OpenAIEmbeddings(openai_api_key="your key..."
, openai_api_base="your base...")
vector = embeddings.embed_query(query) #模型和query转换为向量vector
print("query是什么:",query)
try:
# 获取数据库引擎
engine = db.get_engine(app=current_app, bind='db_psql')
# 使用文本查询构造你的函数调用
query = text("""
SELECT * FROM match_vector_data(:query_embedding, :match_threshold, :match_count)
""")
# 准备参数
params = {
'query_embedding': str(vector),
'match_threshold': 0.8,
'match_count': 3
}
# 执行查询
with engine.connect() as connection:
results = connection.execute(query, params).fetchall()
# 处理结果
for row in results:
print("结果:",row) # 或者其他你需要的操作
if results:
# 将查询结果转换为 Document 对象列表
documents = [Document(page_content=result.content) for result in results]
except Exception as e:
print(f"重载函数错误:{str(e)}")
db.session.rollback()
#返回检索列表文档
return documents
请注意我这里的写法是flask-SQLAlchemy连接的第二个数据库的写法,如果你只连接了一个请按照自己的来
然后就是RAG应用根据个人简历提问功能
# 设置large language model的配置
llm = ChatOpenAI(openai_api_key="..."
, openai_api_base="...", model_name="gpt-3.5-turbo-16k")
#RAG应用,根据个人简历推荐岗位
@bp_vector_chat.route('/admin/vector_chat',methods=['GET','POST'])
@check_admin_privilege #装饰器检查管理员权限
def vector_chat():
try:
#!!!!!将个人简历总结
# 加载向gpt提问的文档
loader = Docx2txtLoader(
file_path="src/static_files/个人简历.docx",
# encoding='utf-8' # 指定编码方式为 utf-8
)
docs = loader.load()
print("加载个人简历成功")
# 构建索引和向量vector(本地向量储存FAISS)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
splits = text_splitter.split_documents(docs) # 切割
vector = FAISS.from_documents(documents=splits, embedding=embeddings)
# 设置提示模板prompt
prompt = ChatPromptTemplate.from_template("""你是一个个人简历总结助手
<context>
{context}
</context>
Question: {input}""")
# 设置一个索引链document_chain,配置llm和模板prompt
document_chain = create_stuff_documents_chain(llm, prompt)
# 使用检索器retriever动态选择最相关的文档并将其传递
retriever = vector.as_retriever()
# 设置检索链,接收一个问题然后检索文档(将文档和问题一起传给llm)并让llm生成一个答案
retrieval_chain = create_retrieval_chain(retriever, document_chain)
print("准备总结个人简历")
# 调用这个检索链,会返回一个字典(来自llm的响应在键中answer)
response = retrieval_chain.invoke(
{"input": "请你帮我总结一下我的个人简历,包括基本信息,教育背景,工作经验,竞赛获奖,专业技能和期望职位,薪资"}
)
resume = str(response["answer"])
# print("个人简历总结:",resume)
print("个人简历总结successfully~")
#!!!!!个人简历总结完成
# 设置一个链,接收一个问题和检索到的文档并生成一个答案
prompt = ChatPromptTemplate.from_template("""你是一个岗位应聘助手
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# 构建检索器
retriever = CustomRetriever()
# 使用检索器动态选择最相关的文档并将其传递
retrieval_chain = create_retrieval_chain(retriever, document_chain)
print("\n准备输入简历总结提问RAG")
# 调用这个链,返回一个字典(来自 LLM 的响应在键中answer)
response = retrieval_chain.invoke(
{"input": "这是我的个人简历:" + resume}
)
print("回答:",response["answer"])
# 运行成功
print("运行成功-success")
response = {
'status': 'success',
'message': 'RAG输出成功',
}
return jsonify(response), 200
except Exception as e:
print(f"RAG输出失败:{str(e)}")
# 事务回滚
db.session.rollback()
response = {
'status': 'fail',
'message': 'RAG输出失败',
}
return jsonify(response), 500
可以将不确定的值输出看,比如query是输入的问题,即retrieval_chain.invoke的input的内容。
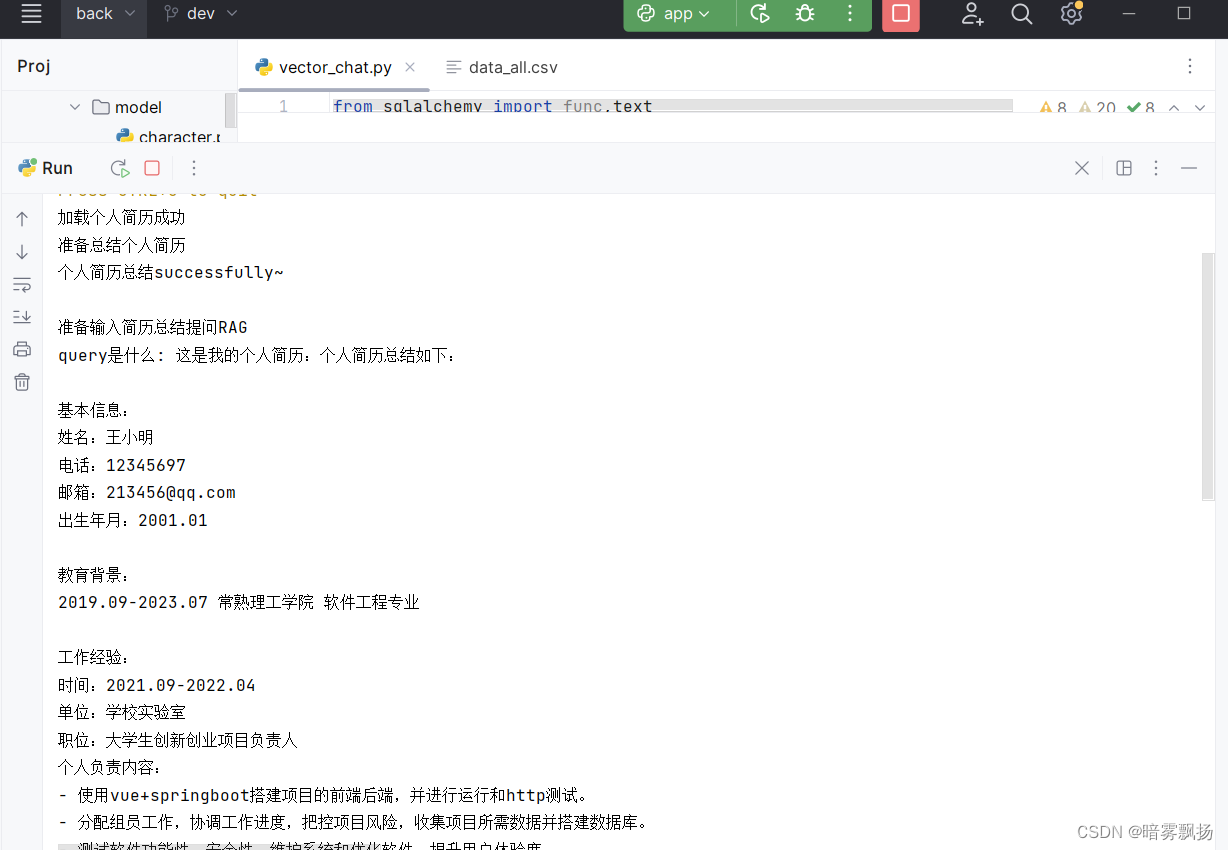
运行成功了。
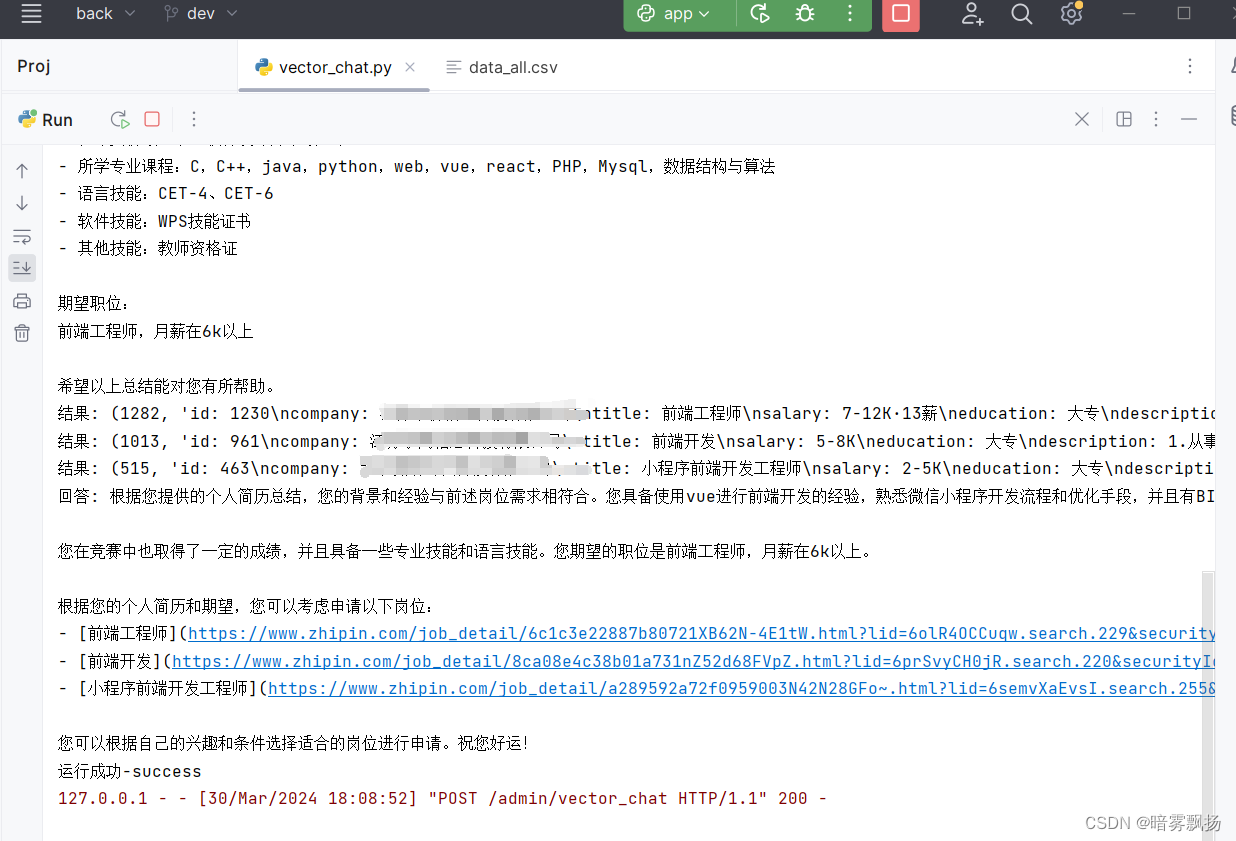

















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









