






题目要求:红楼梦相关的分词,出现次数最高的20个。
代码如下:
import jieba
from collections import Counter
import os
with open('hongloumeng.txt', 'r', encoding='utf-8') as file:
text = file.read()
# 使用jieba进行分词
words = jieba.lcut(text) # 使用lcut直接返回一个列表
# 统计词频
word_counts = Counter(words)
# 找出出现次数最高的20个词
top_twenty_words = word_counts.most_common(20)
# 打印结果
print("分词排序")
for word, freq in top_twenty_words:
print(f'分词: {word}, 次数: {freq}')运行结果:
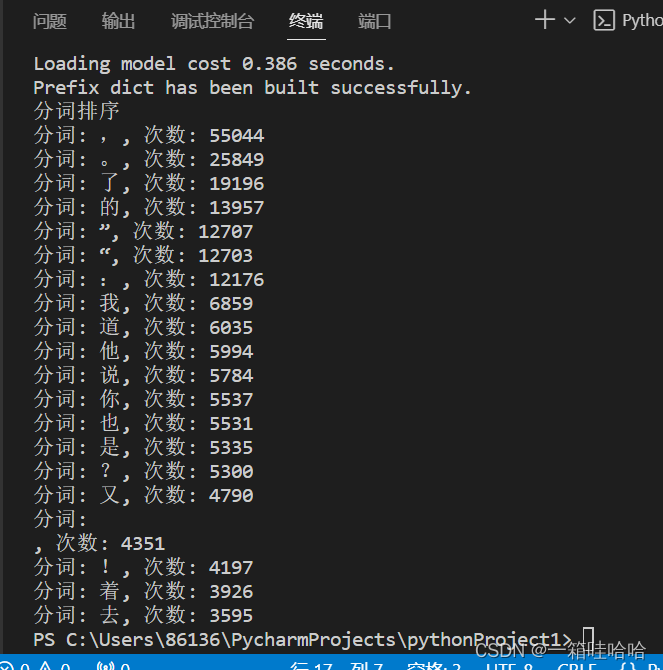















 2533
2533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









