






题(2)请用requests库的get()函数访问如下一个网站20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度:
代码如下:
import requests
for i in range(2):
responese = requests.get('https://cn.bing.com/?mkt=zh-cn')
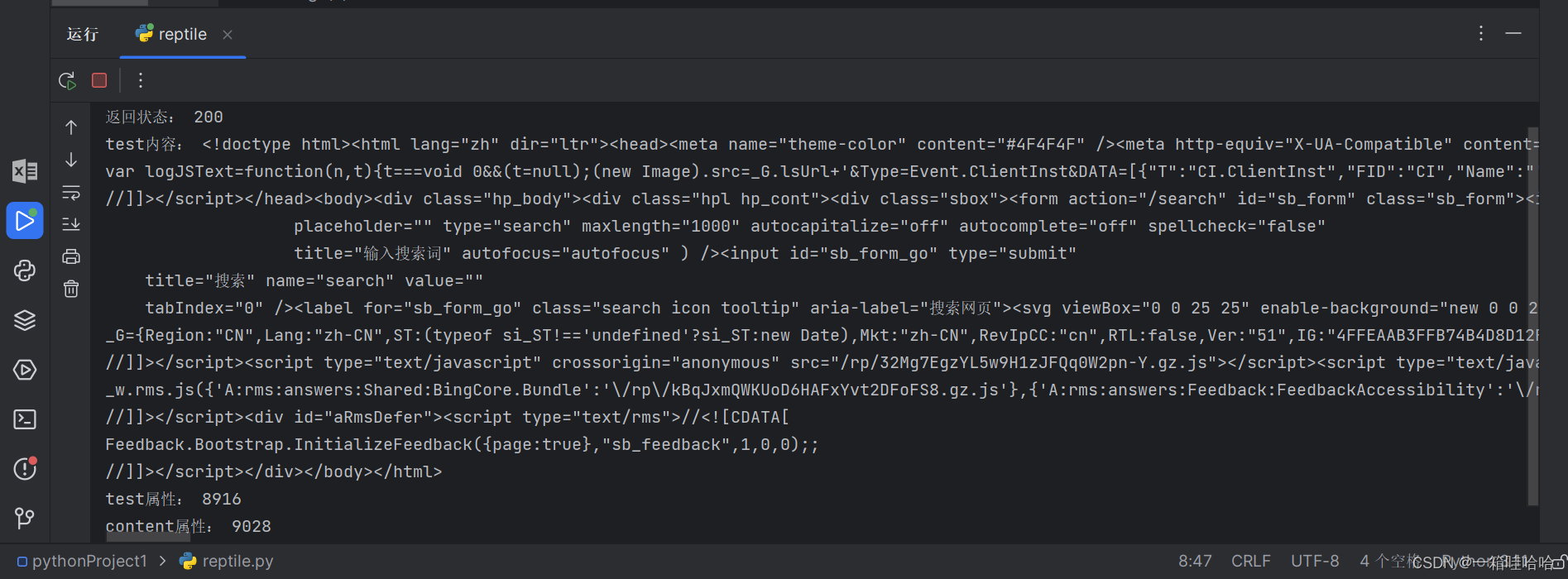
print('返回状态:',responese.status_code)
print('test内容:',responese.text)
print('test属性:',len(responese.text))
print('content属性:',len(responese.content))运行结果:
题(3)a. 打印head标签内容和你的学号后两位 b,获取body标签的内容 c. 获取id 为first的标签对象 d. 获取并打印html页面中的中文字符:
代码如下:
import requests
from bs4 import BeautifulSoup
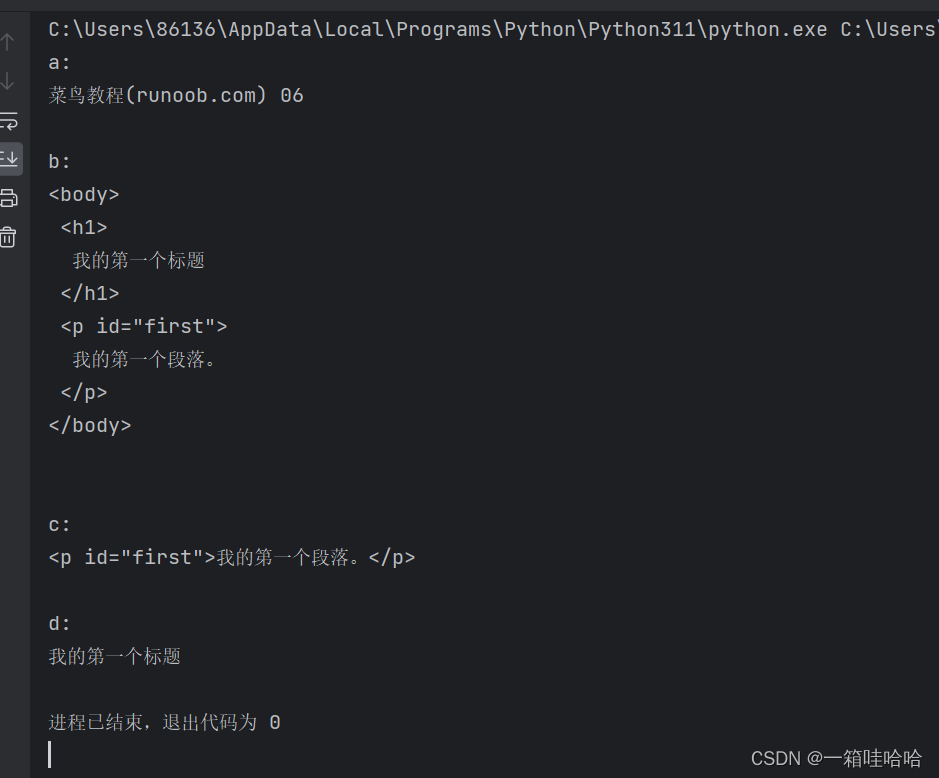
print('a:')
print("菜鸟教程(runoob.com) 06\n")
with open('C:/Users/86136/Desktop/programming/PythonPractices/reptile2.html', 'r', encoding='utf-8') as file:
content = file.read()
soup = BeautifulSoup(content,'lxml') #soup是beautifulsoup解析器返回的解析对象
bodycontent = soup.body.prettify()
print('b:')
print(bodycontent,"\n")
fisrtelement = soup.find(id='first')
print('c:')
print(fisrtelement,'\n')
soup2 = BeautifulSoup(content, "html.parser")
print('d:')
for text in soup2.stripped_strings:
if all('\u4e00' <= char <= '\u9fff' for char in text):
print(text)运行结果:
题(4):爬中国大学排名网站内容,
https://www.shanghairanking.cn/rankings/bcur/201811
要求:(一)爬取大学排名(学号尾号1,2,爬取年费2020,学号尾号3,4,爬取年费2016,学号尾号5,6,爬取年费2017,学号尾号7,8,爬取年费2018,学号尾号9,0,爬取年费2019,)
(二)把爬取得数据,存为csv文件
代码如下:
import requests
from bs4 import BeautifulSoup
import csv
# 请求网页内容
url = "https://www.shanghairanking.cn/rankings/bcur/201611"
response = requests.get(url)
response.encoding = 'utf-8'
html_content = response.text
# 解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')
table = soup.find('table', {'class': 'rk-table'})
rows = table.find_all('tr')[1:] # 跳过表头
# 提取大学名称和序号
data = []
for row in rows:
cols = row.find_all('td')
university_name = cols[1].find('a', class_='name-cn').text.strip()
university_rank = cols[0].text.strip()
data.append([university_name, university_rank])
# 保存为csv文件
with open('university_ranking_2016.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['大学名称', '排序']) # 写入表头
writer.writerows(data) # 写入数据
运行结果:
















 2313
2313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









