






目录
什么是结构体?
在学习结构体之前我们需要了解什么是结构体?我们为什么要引用结构体这个概念呢?
拿一个学生来说,一个学生的身上有很多的属性例如:年龄,姓名,身高,性别,分数等等,而学生又不止一个,有很多的学生,这时候我们想要记录每个学生的数据,首先我们想到的是我们可以定义多个变量来表示不同的学生,但是这样的话我们不仅要定义学生变量还要定义多个学生的属性,这样的话如果有1000个学生的话光是定义变量就会消耗不少时间。
这时我们想到我们可以定义一个学生的模板,然后把学生的各个属性全部放在这个模板中这样的话每定义一个学生只需要引用一下这个模板就行了,大大的减少了我们的工作量。
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
结构体的声明
上面我们解释了什么是结构体我们为什么要用结构体,下面就来介绍一下我们该怎么使用结构体,首先就是结构体的声明
struct tag
{
member-list;
}variable-list;tag是我们的结构体名称,也就是我们所谓的模板名称,mem-list是结构体里面的成员,variable-list是我们通过结构体声明出来的变量,这是一种声明方式,后面我们还会介绍别的方式。
下面我们先来声明一个学生的结构体
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}; //分号不能丢匿名结构体
我们在声明结构体的时候可以不完全的声明
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20], * p;我们可以看到我们没有写结构体的名称,这就是匿名结构体。
接着我们看一下下面的一段代码
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20], * p1, y, * p2;
int main()
{
p1 = &y;
p2 = &x;
return 0;
}我么运行代码将会看到下面的警告,在我们p2 = &x这行
warning C4133: “=”: 从“*”到“*”的类型不兼容
我们可以看出这两个结构体类型是不一样的,所以在我们赋值的时候才会报警告。
结构体自引用
上面说到我们结构体的成员,那么我们结构体的成员能不能再是一个结构体呢。
答案是肯定的,但是我们该怎么写呢?
struct Node
{
int data;
struct Node next;
};这样写对不对呢?我们来检测一下

很明显这样是不行的,因为这样我们没法计算我们结构体的大小,它的一个成员是一个结构体,那么那个结构体的大小又是多少呢?里面的成员还有一个结构体?如此无限套娃算不出来结构体的大小。
于是我们就想到了下面这种写法。
struct Node
{
int data;
struct Node* next;
};如此一来我们结构体的成员就变成了一个指针而不是一个结构体了,而且一个指针的大小又是确定的,这样就不用担心算不出来结构体的大小了。
结构体重命名
typedef struct Node
{
int data;
struct Node* next;
}node;typedef关键字是将我们的结构体重命名的,typedef后面跟着我们想要重命名的结构体名称,然后再在最后写出更改后的新名字,这样我们定义结构体对象的时候就不用struct Node x,而是可以改成node x,就可以了。这样写起来确实会让人觉得简洁了一些,但是这样也降低的代码的可阅读性,我们不容易知道这个node是个什么东西,所以在这里我们是不推荐大家使用typedef关键字的。
结构体变量的定义和初始化
前面我们已经分析好了结构体里面的成员变量了,下面就是学习该怎么定义结构体变量和如何初始化结构体了。
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//初始化:定义变量的同时赋初值。
struct Point p3 = { x, y };
struct Stu //类型声明
{
char name[15];//名字
int age; //年龄
};
struct Stu s = { "zhangsan", 20 };//初始化
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = { 10, {4,5}, NULL }; //结构体嵌套初始化
struct Node n2 = { 20, {5, 6}, NULL };
方法主要有两种一种是在声明结构体的时候就对其定义并且初始化,还有一种就是我们单独对其进行定义和初始化。
结构体内存对其问题
结构体大小的计算
前面我们提到了结构体大小的问题,那么我们该如何计算结构体的大小呢?
这时就要知道我们结构体内存对其的原理了。
struct S1
{
char c1;
int i;
char c2;
};
//练习2
struct S2
{
char c1;
char c2;
int i;
};
//练习3
struct S3
{
double d;
char c;
int i;
};
//练习4-结构体嵌套问题
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{
//p1 = &y;
//p2 = &x;
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
printf("%d\n", sizeof(struct S3));
printf("%d\n", sizeof(struct S4));
return 0;
}
上面的结构分别是多少呢?
想要知道结果是多少我们就得知道结构体的对其规则。
1. 第一个成员在与结构体变量偏移量为0的地址处。
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
VS中默认的值为8
3. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
现在我们已经了解了对齐规则,接下来就开始计算了。
struct S1
{
char c1;
int i;
char c2;
};我们先看第一个,第一个成员在与结构体变量偏移量为0的地方,然后就是int类型,int占4个字节小于我们的默认对齐数,对齐数就是4,然后对齐在距离偏移量为0的四个字节的地方,又因为其本身占四个字节,所以char从第八个字节出开始对齐因为char占一个字节小于默认对齐数所以就占用了第九个字节,然后我们看到第3点结构体的总大小为最大对齐数的整数倍也就是4的整数倍所以结构体的大小就是12。
struct S3
{
double d;
char c;
int i;
};
//练习4-结构体嵌套问题
struct S4
{
char c1;
struct S3 s3;
double d;
};
同理我们可以算出S3的总大小为16,那么我们S4的结构体大小该如何计算呢?
char 的对齐数是1,然后就是结构体的对齐数了根据第四点我们知道结构体的对齐数就是嵌套结构体的最大对齐数也就是8,所以就是8+16了又因为double的对齐数是8,同时占8个字节,也就是8+16+8=32了又因为32是最大对齐数8的整数倍所以该结构体的大小就是32。
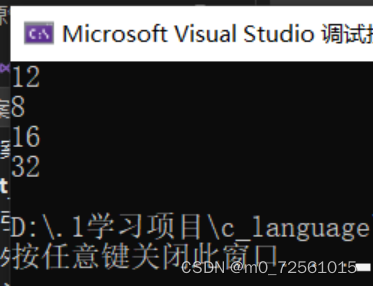
运行结果如图。
修改默认对齐数
之前我们见过了 #pragma 这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
#include <stdio.h>
#pragma pack(8)//设置默认对齐数为8
struct S1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
#pragma pack(1)//设置默认对齐数为1
struct S2
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
int main()
{
//输出的结果是什么?
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}
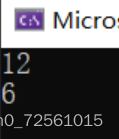
我们可以看到同样的结构体成员,我们改变了默认对齐数结构体的大小自然跟着变化了。
struct S
{
int data[1000];
int num;
};
struct S s = { {1,2,3,4}, 1000 };
//结构体传参
void print1(struct S s)
{
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
printf("%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}
上面是两种结构体的传参方式我们可以看到一种是将我们的整个结构体都给传过去了,另外一种就是传我们的地址,然后通过我们的地址找到我们的结构体,很明显当然是我们的第二种传参方式比较好,因为当我们的结构体比较大的时候我们传整个结构体将会开辟很多的内存,这样就造成了空间的浪费,所以我们采用传地址。















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









