






I. What is RAG
rag
Large language models (LLMs) have more powerful capabilities compared to traditional language models; however, in certain cases, they may still fail to provide accurate answers. To address a series of challenges faced by large language models in generating text and to improve the model’s performance and output quality, researchers have proposed a new model architecture: Retrieval-Augmented Generation (RAG). This architecture cleverly integrates relevant information retrieved from a vast knowledge base and uses it as a foundation to guide large language models in generating more precise answers, thereby significantly enhancing the accuracy and depth of responses.
Currently, the main issues faced by LLMs include:
-
Information Bias/Hallucination: LLMs sometimes generate information that does not align with objective facts, leading to inaccurate information received by users. RAG assists the model generation process by retrieving data sources, ensuring the precision and credibility of the output content, and reducing information bias.
-
Knowledge Update Lag: LLMs are trained on static datasets, which may result in the model’s knowledge being outdated and unable to reflect the latest information dynamics in a timely manner. RAG maintains the timeliness of content by retrieving the latest data in real-time, ensuring continuous updates and accuracy of information.
-
Content Non-Traceability: The content generated by LLMs often lacks clear information sources, affecting the credibility of the content. RAG establishes links between generated content and retrieved original materials, enhancing the traceability of the content, thereby increasing user trust in the generated content.
-
Lack of Domain Expertise: LLMs may not perform optimally when handling specialized knowledge in specific fields, which can affect the quality of their responses in relevant areas. RAG improves the quality and depth of answers in specialized fields by retrieving relevant documents from specific domains, providing the model with rich contextual information.
-
Reasoning Ability Limitations: When faced with complex questions, LLMs may lack the necessary reasoning capabilities, which affects their understanding and answering of questions. RAG enhances the model’s reasoning and understanding abilities by combining retrieved information with the model’s generation capabilities, providing additional background knowledge and data support.
-
Application Scenario Adaptability Limitations: LLMs need to maintain efficiency and accuracy across diverse application scenarios, but a single model may struggle to adapt comprehensively to all scenarios. RAG enables LLMs to flexibly adapt to various application scenarios, such as question-answering systems and recommendation systems, by retrieving corresponding application scenario data.
-
Weak Long Text Processing Ability: LLMs are limited by a finite context window when understanding and generating long content, and they must process content sequentially; the longer the input, the slower the speed. RAG strengthens the model’s understanding and generation of long contexts by retrieving and integrating long text information, effectively breaking through input length limitations, while reducing invocation costs and improving overall processing efficiency.
II. Some Prerequisite Knowledge of RAG.
2.1 Embedding Model
Embedding is the process of converting unstructured data into continuous vector representations. Because all computations in computers are based on numbers as data carriers, we need to convert text language into a vector representation. Through this embedding technology, we can uniformly convert each vocabulary or sentence into a vector representation, which also contains the semantic information of that vocabulary or sentence.
For example:
The traditional way to convert to vectors is to use Word2Vec. It is a vector conversion technology proposed by Google in 2023 and is one of the most classic algorithms in word vector technology. Its principle is to learn the semantic and grammatical relationships between words by training on a corpus, mapping words to dense vectors in a high-dimensional space. This algorithm is also commonly used in early machine learning tasks completed in NLP.
A simple Word2Vec model development source code is as follows:
- Install the Gensim library (if not already installed):
pip install gensim
- Prepare text data. Below is a simple text list example:
sentences = [ ['我', '喜欢', '吃', '苹果'], ['我', '不喜欢', '吃', '香蕉'], ['他', '喜欢', '跑步'], ['她', '喜欢', '游泳'] ]
- Use the Word2Vec function in the Gensim library to train the model:
from gensim.models import Word2Vec # train Word2Vec model model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4) # save model model.save("word2vec.model") # load model model = Word2Vec.load("word2vec.model") # Gets a vector representation of terms print(model.wv['苹果']) # Find the word that is most similar to a word print(model.wv.most_similar('喜欢'))Below are some parameter explanations from the above code:
- vector_size: The dimension of the word vector.
- window: The size of the context window for considering surrounding words.
- min_count: Ignore words that appear less than this value.
- workers: The number of processes used for training.
There are two common ways to call external embedding models:
- Vector models based on Transformers, such as BGE, etc.
- API-based interface models, such as iFlytek’s Spark large model, etc.
The method for implementing embedding based on BGE is as follows:
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
The method based on the iFlytek API is as follows:
import os
import requests
from datetime import datetime
from wsgiref.handlers import format_date_time
from time import mktime
import hashlib
import base64
import hmac
from urllib.parse import urlencode
import json
import numpy as np
from loguru import logger
class Config():
def __init__(self, appid: str = None, apikey: str = None, apisecret: str = None):
'''
讯飞API统一的环境配置
:param uid: uid
:param appid: appid
:param apikey: api key
:param apisecret: api secret
调用方式:
# 加载系统环境变量xf_uid、xf_app_id、xf_app_key、xf_app_secret
config = Config()
# 自定义key写入
config = Config('14****93', 'eb28b****b82', 'MWM1MzBkOD****Mzk0')
'''
if appid is None:
self.XF_APPID = os.environ["SPARKAI_APP_ID"]
else:
self.XF_APPID = appid
if apikey is None:
self.XF_APIKEY = os.environ["SPARKAI_API_KEY"]
else:
self.XF_APIKEY = apikey
if apisecret is None:
self.XF_APISECRET = os.environ["SPARKAI_API_SECRET"]
else:
self.XF_APISECRET = apisecret
class EmbeddingModel(object):
def __init__(self, config: Config, model_url: str = 'https://emb-cn-huabei-1.xf-yun.com/'):
'''
图片理解(https://www.xfyun.cn/doc/spark/ImageUnderstanding.html)
:param config: 项目配置文件
:param model_url: 模型地址
'''
# 讯飞的api配置
self.appid = config.XF_APPID
self.apikey = config.XF_APIKEY
self.apisecret = config.XF_APISECRET
# url地址
self.model_url = model_url
self.host, self.path, self.schema = self.__parse_url(model_url)
def get_embedding(self, text: str, style: str = 'query') -> np.array:
# 准备请求体
req_body = {
"header": {"app_id": self.appid, "status": 3},
"parameter": {"emb": {"domain": style, "feature": {"encoding": "utf8"}}},
"payload": {"messages": {"text": base64.b64encode(json.dumps({"messages": [{"content": text, "role": "user"}]}).encode('utf-8')).decode()}}
}
# 生成url
url = self.__create_url("POST")
# 调用接口
resp_data = requests.post(url, json=req_body, headers={'content-type': "application/json"}).json()
# 提取输出
code = resp_data['header']['code']
if code != 0:
raise Exception(f'请求错误: {code}, {resp_data}')
else:
sid = resp_data['header']['sid']
text_base = resp_data["payload"]["feature"]["text"]
# 使用base64.b64decode()函数将text_base解码为字节串text_data
text_data = base64.b64decode(text_base)
# 创建一个np.float32类型的数据类型对象dt,表示32位浮点数。
dt = np.dtype(np.float32)
# 使用newbyteorder()方法将dt的字节序设置为小端("<")
dt = dt.newbyteorder("<")
# 使用np.frombuffer()函数将text_data转换为浮点数数组text,数据类型为dt。
text = np.frombuffer(text_data, dtype=dt)
# # 打印向量维度
return text
def __create_url(self, method="GET"):
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# date = "Thu, 12 Dec 2019 01:57:27 GMT"
signature_origin = "host: {}\ndate: {}\n{} {} HTTP/1.1".format(self.host, date, method, self.path)
signature_sha = hmac.new(self.apisecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.apikey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
values = {
"host": self.host,
"date": date,
"authorization": authorization
}
return self.model_url + "?" + urlencode(values)
def __parse_url(self, requset_url):
stidx = requset_url.index("://")
host = requset_url[stidx + 3:]
schema = requset_url[:stidx + 3]
edidx = host.index("/")
if edidx <= 0:
raise Exception("错误的请求地址:" + requset_url)
path = host[edidx:]
host = host[:edidx]
return host, path, schema
if __name__ == '__main__':
config = Config()
em = EmebddingModel(config)
vector = em.get_embedding("我们是datawhale")
logger.info(vector)
2.2 Similarity Calculation
The reason RAG can achieve document retrieval enhancement is primarily based on the similarity calculation of word vectors; then, it extracts the documents most similar to the user’s question to assist the model in answering. Therefore, similarity is also the key to RAG technology.
Traditional similarity calculations include: Pearson correlation coefficient, Euclidean distance, Manhattan distance, and cosine similarity. Below, we will explain the principle of similarity calculation using cosine similarity as a case study.
Cosine similarity is a commonly used method to measure the similarity between two non-zero vectors. This method evaluates their similarity by measuring the cosine of the angle between the two vectors. The closer the two vectors are, the smaller the value; the farther apart the two vectors are, the larger the value.
Calculation Formula
Given two vectors P and Q, their cosine similarity is represented as follows, thus obtaining the formula for cosine similarity.
c o s ( θ ) = ( P ⋅ Q ) ∣ ∣ P ∣ ∣ ∗ ∣ ∣ Q ∣ ∣ cos(\theta)=\frac{(P·Q)}{||P||*||Q||} cos(θ)=∣∣P∣∣∗∣∣Q∣∣(P⋅Q)
Here, (P·Q) represents the dot product of P and Q, while ||P|| and ||Q|| represent the Euclidean norms of P and Q (i.e., the lengths of the vectors).
The formula for the dot product (P·Q) is:
P ⋅ Q = ∑ ( p i ∗ q i ) P·Q=\sum(p_i*q_i) P⋅Q=∑(pi∗qi)
Calculation Formula for the Euclidean Norm of Vector ||P||:
∣ ∣ P ∣ ∣ = ∑ p i 2 ||P||=\sqrt{\sum{p_i^2}} ∣∣P∣∣=∑pi2
TODO: Code for filling in cosine similarity.
Ⅲ、Workflow of RAG
RAG is a complete system, and its workflow can be simply divided into four stages: data processing, retrieval, enhancement, and generation.
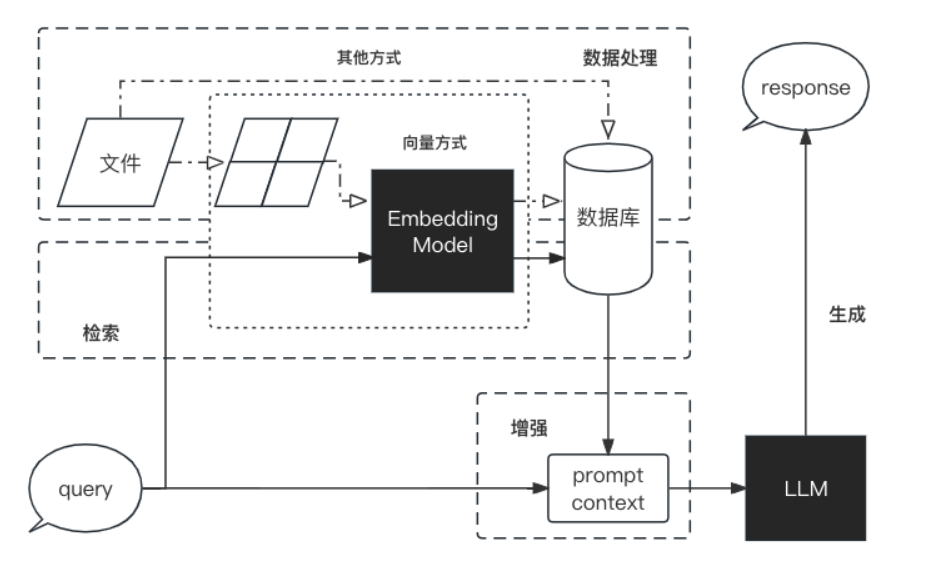
- Data processing stage
- Clean and process the original data.
- Transform the processed data into a format that the retrieval model can use.
- Store the processed data in the corresponding database.
- Search phase
- Input the user’s question into the retrieval system and retrieve the relevant information from the database.
- Enhancement phase
- The retrieved information is processed and enhanced so that the generated model can be better understood and used.
- Generation phase
- Input the enhanced information into the generative model, and the generative model generates answers according to the information.
Ⅳ、RAG vs Finetune
In improving the performance of large language models, RAG and finetuning are two mainstream methods.
Finetuning: Improve the model’s performance on specific tasks by further training the large language model on a specific dataset.
Comparison of RAG and Fine-tuning([1] [2])
| Characteristics | RAG | Fine-tuning |
|---|---|---|
| Knowledge renewal | Directly updates the retrieval knowledge base without the need for retraining. The cost of information updates is low, suitable for dynamically changing data. | Typically requires retraining to maintain the update of knowledge and data. The update cost is high, suitable for static data. |
| External Knowledge | Excels at utilizing external resources, particularly suitable for handling documents or other structured/unstructured databases. | Incorporates external knowledge into the LLM. |
| Data Processing | Has extremely low requirements for data processing and operations. | Relies on building high-quality datasets; limited datasets may not significantly improve performance. |
| Model Customization | Focuses on information retrieval and integrating external knowledge, but may not fully customize model behavior or writing style. | Can adjust LLM behavior, writing style, or specific domain knowledge according to specific styles or terminology. |
| Interpretability | Can trace back to specific data sources, with good interpretability and traceability. | Black box, with relatively low interpretability. |
| Computational Resources | Requires additional resources to support retrieval mechanisms and database maintenance. | Relies on high-quality training datasets and fine-tuning objectives, with high demands on computational resources. |
| Inference Latency | Increases the time cost of retrieval steps | the time cost of purely LLM-generated responses decreases. |
| Hallucination | Generates answers through retrieved real information, reducing the probability of hallucinations. | The model learning specific domain data helps reduce hallucinations, but hallucinations may still occur when facing unseen inputs. |
| Ethical Privacy | Retrieving and using external data may raise ethical and privacy issues. | Sensitive information in training data needs to be handled properly to prevent leaks. |
Ⅴ、Success Cases of RAG
RAG has achieved success in multiple fields, including question-answering systems, dialogue systems, document summarization, document generation, etc.
- Datawhale Knowledge Base Assistant is based on the content of Datawhale courses, built on the ChatWithDatawhale—Datawhale content learning assistant created by Sanbu, and has adjusted the architecture to the LangChain architecture, which is easy for beginners to learn. It also refers to the content of Chapter Two to encapsulate different source large model APIs into LLM applications, which can help users have smooth conversations with DataWhale’s existing repository and learning content, thereby helping users quickly find the content they want to learn and the content they can contribute.
- Tianji is a free-to-use, non-commercial artificial intelligence system produced by SocialAI (Lai Shier AI). You can use it for tasks involving traditional social etiquette, such as how to toast, how to speak well, how to handle social situations, etc., to enhance your emotional intelligence and core competitive abilities. We firmly believe that only social etiquette is the core technology of future AI, and only AI that can handle social situations has the opportunity to move towards AGI. Let us join hands to witness the arrival of general artificial intelligence.— “The secret cannot be leaked.”
【Reference】 :















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









