







 本文详细介绍了Python中的文件操作,包括文件的打开与关闭、读写方法(如read(),write()等),以及处理CSV和JSON文件的技巧。还通过实例演示了如何进行文本文件的读写实验,以及使用with语句和seek方法。
本文详细介绍了Python中的文件操作,包括文件的打开与关闭、读写方法(如read(),write()等),以及处理CSV和JSON文件的技巧。还通过实例演示了如何进行文本文件的读写实验,以及使用with语句和seek方法。
文章目录
一、文件概述
- 文件是数据的集合和抽象,类似,函数是程序的集合和抽象
- 文件是一个存储在辅助存储器上的数据序列,可以包含任何数据内容。
- 展示形态:文本文件和二进制文件。
二、文件操作
Python中我们依然使用
open/write/read...函数来实现文件的打开。
但需要注意的是,如Python中的open性质类似于C语言中的fopen,都为基于系统open接口的包装,是内置函数。如果希望在Python中调用系统的文件操作接口需要引入os库,具体不在此处介绍。
对于常规文件操作,通常仍推荐使用Python内置函数
下图为Liunx内核下open系统接口,更多具体介绍与操作可见【Linux/OS学习】基础文件控制/IO——内存文件
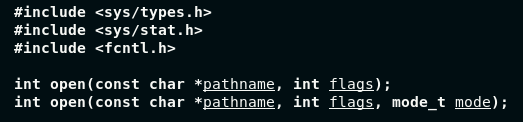
此文主要介绍Python文件相关的内置函数
1.文件的打开与关闭
open() 函数用于打开一个文件,创建一个 file 对象
- open函数格式:
open(name[, mode[, buffering]]) - 参数说明:
-
name : 一个包含了你要访问的文件名称的字符串值。
-
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读。
-
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
-
- 实际上我们还可以再open函数中使用“第四个参数”,
encoding="xxx"来规定文件打开时的编码规则(如utf-8、GBK)
常用的使用方法是只使用前两个参数:name即操作文件的绝对路径/若只有文件名则是在程序文件工作目录下。
以下为基本mode功能:
| mode | 功能 |
|---|---|
| t | 文本模式 (默认) |
| b | 二进制模式 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头(默认) |
| + | 打开一个文件进行更新(可读可写) |
| U | 通用换行模式(不推荐) |
不同的mode之间也可以互相组合使用(相互冲突的不可)
with语句:
with 语句是一种上下文管理器,当它的代码块执行完毕时,会自动关闭文件(recommended)。可以避免一些忘记关闭文件导致的错误。使用示例如下:
file_path = 'example.txt'
with open(file_path, 'a+') as file_stream:
# 执行文件操作,例如读取文件内容
file_content = file_stream.read()
file_stream.read()# 文件在这里已经被自动关闭,会报错
- close函数:没有使用with语句时,切记在open文件后,不再使用时手动关闭
2. 文件的读写
2.1 读取
通常来说,我们使用r、r+mode来读取文件。
对于一般文件我们可以直接使用file类的函数read()、readlines()来读取
如:
fp = 'example.txt'
# 读取文件
with open(fp, 'r+') as fd:
data = fd.read()
print(data)
with open(fp, 'r+') as fd:
lines = fd.readlines()
for line in lines
print(line)
readlines是 Python 中用于读取文件的方法之一,它用于逐行读取文件内容,并将每一行作为字符串存储在一个列表中- 还有
readline方法,其每次调用只返回文件中的一行作为字符串。如果再次调用,将返回下一行。当文件读取完毕后,返回空字符串 ‘’。通常只在需要逐行处理大型文件时使用。 - 或者Python本身可直接将文件作为行序列逐行处理
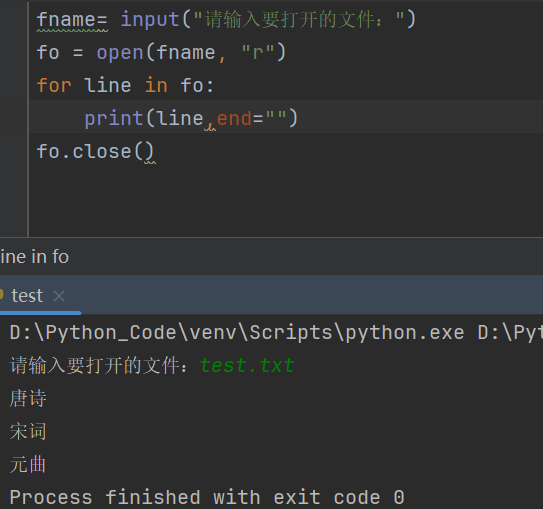
fname= input("请输入要打开的文件:")
fo = open(fname, "r")
for line in fo:
print(line,end="")
fo.close()
2.2 写入
Python提供3个与文件内容写入有关的方法,如表所示:
| 方法 | 含义 |
|---|---|
| .write(s) | 向文件写入一个字符串或字节流 |
| .writelines(lines) | 将一个元素为字符串的列表写入文件 |
| .seek(offset[,where]) | 改变当前文件操作指针的位置。offset表示基于where向后偏移几个字节,where的值——0:文件开头(默认);1:当前位置;2:文件结尾 |
值得一提的是,当我们在使用w或相关组合的mode进行文件打开与写入后,直接调用read之类的函数无法打印文件内容——这是由于此时文件操作指针往往指向文件末尾,之后已经没有字符可以打印。所以我们需要使用seek(0)将文件操作指针重新指向文件开头,此时再调用read之类的函数即可成功打印
tips:CSV与JSON文件
对于以上两种文件,对其进行读写操作需要分别引入csv与json库,具体使用函数详见库
一些文件操作小实验
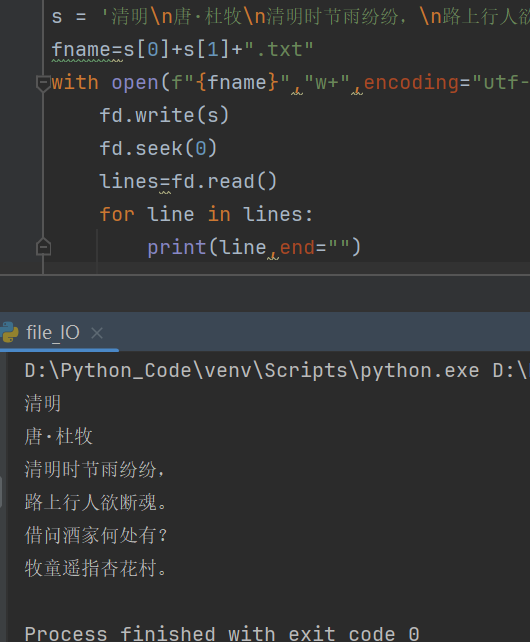
《清明》文本写入与读取
s = '清明\n唐·杜牧\n清明时节雨纷纷,\n路上行人欲断魂。\n借问酒家何处有?\n牧童遥指杏花村。\n'
fname=s[0]+s[1]+".txt"
with open(f"{fname}","w+",encoding="utf-8") as fd:
fd.write(s)
fd.seek(0)
lines=fd.read()
for line in lines:
print(line,end="")
测试结果:
《红楼梦》人物出现统计(部分文本)
关于中文文本处理,可以引入第三方库jieba,来更好的进行处理操作
import jieba
excludes = {'什么', '一个', '我们', '你们', '如今', '说道', '知道', '起来', '这里','奶奶',
'姑娘', '出来', '众人', '那里', '自己', '他们', '一面', '只见', '怎么','老太太',
'两个', '没有', '不是', '不知', '这个', '听见', '这样', '进来', '咱们','太太',
'告诉', '就是', '东西', '回来', '只是', '大家', '只得', '丫头','姐姐','不用',
'过来', '心里', '如此', '今日', '这些', '不敢', '出去', '所以', '不过', '的话',
'不好', '一时', '不能', '银子', '几个', '答应', '二人', '还有', '只管', '这么',
'说话', '一回', '那边', '这话', '外头', '打发', '自然', '今儿', '罢了', '屋里',
'那些', '听说', '如何', '问道', '看见','二爷','小丫头','人家','妹妹','老爷','她们','哪里'}
txt = open("E:\Downloads\红楼梦.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "宝玉" or word == "宝二爷" :
rword = "贾宝玉"
elif word == "凤姐" or word == "凤辣子" or word == "凤姐儿" or word == "琏二奶奶" or word == "凤丫头" or word == "凤哥儿" :
rword = "王熙凤"
elif word == "老祖宗" or word == "老太君":
rword = "贾母"
elif word == "颦颦" or word == "林姑娘" or word == "黛玉" or word == "林妹妹" or word == "潇湘妃子" or word == "林丫头":
rword = "林黛玉"
elif word == "宝姑娘" or word == "宝丫头" or word == "蘅芜君" or word == "宝姐姐" or word == "宝钗":
rword = "薛宝钗"
elif word == "湘云":
rword = "史湘云"
elif word == "存周":
rword = "贾政"
elif word == "花珍珠" or word == "花大姑娘":
rword = "袭人"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(20):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
测试结果:
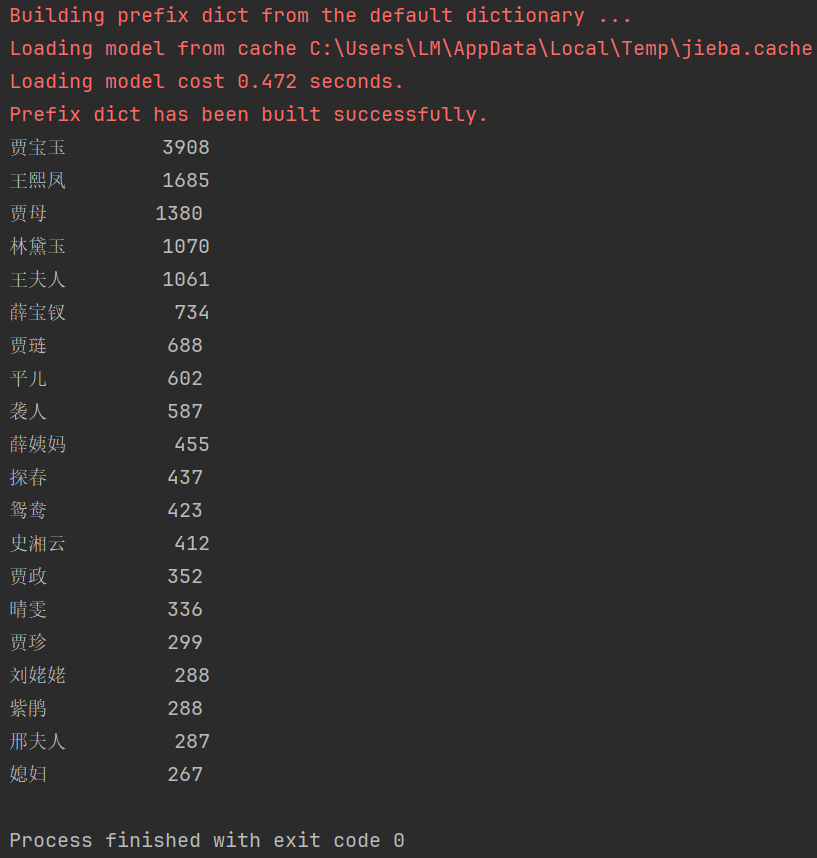















 3415
3415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









