






大家都知道WPS中,Word文档在输入过程中会自动统计字符。
受博主@一头小山猪 所撰写的经典算法专栏启发,决定利用所有查找算法中最基本的顺序查找,检索一段汉字中同一关键字出现的位置,以及总出现次数。
正文开始
一、问题分析
与一般的英文字符串不同,单个中文汉字占据了两个字节大小。此外中国人的语言习惯是不使用空格作为分隔符,而是使用中文标点符号分割。因此,这虽然为统计带来了麻烦,但极大地方便了输入操作。
并且,中文输入有语法逻辑,不需要进行排序。
二、解决思路
1.中文字符段落长度一般较短,而字符串数组本身不容易实现动态数组的操作,故通过数组大小设置最多不能输入超过1000字。(2000字节)(char a[2000];)
2.中文的关键字会以字符串形式存储,加上结尾的'\0',总计3个字节(char b[3];)
3.中文字符的查找需要遍历整个输入数组a的实际长度,而比对则需要将每两个字节与关键字字符串数组逐一比对,故使用for循环+if嵌套的结构:只有第一个字节相同,才会比对第二个字节,若两个字节都相同,则说明是同一个汉字。
4.每个字符占两个字节,肉眼看来,其位置就是(数组下标+1)/2(加一的原因是数组从a[0]开始)
5.需要一个计数器(num),统计总出现次数,请注意,这个计数器与数组遍历的计数器不可以重合。
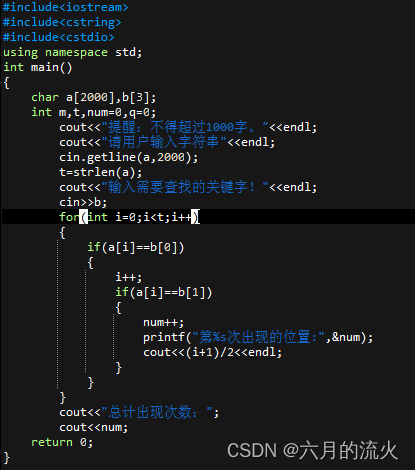
三、代码实现
C++源代码如下:
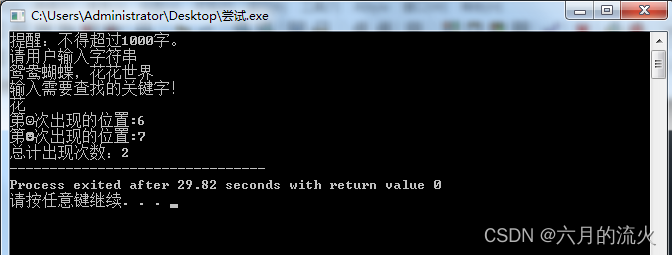
运行结果:
四、算法时间复杂度与缺点
1.该算法需要遍历所有“有效字节”,故时间复杂度为o(n);
2.该算法的缺点也很明显,最大输入字数有限;无法用文件直接导入;无法处理双语混合字符串。
欢迎指正与完善!
the end;















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









