







一.认识寄存器
集成在CPU上.效率高,造价高,所以比较小.一般只是暂时存放.

二.常用寄存器
1.eax ebx ecx edx
2.edi eci
3.ebp esp
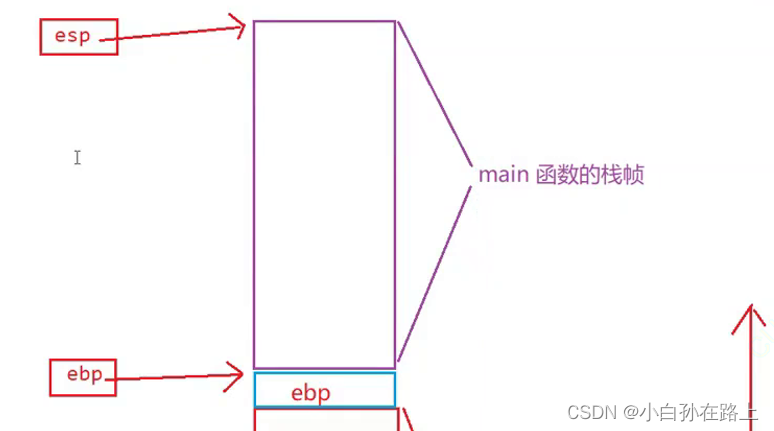
三.函数栈帧
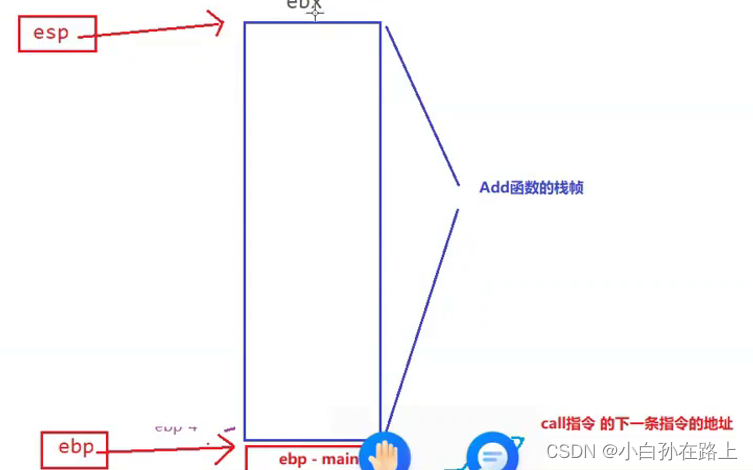
ebp 和esp这两个寄存器中存放的是地址,这两个地址是为了 维护函数栈帧的
每一个函数调用,都要在栈区开辟一块空间
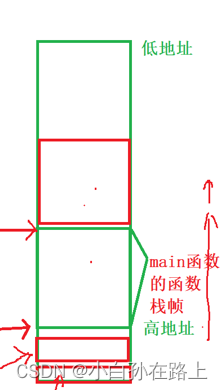
栈顶指针-----esp
栈底指 针---ebp
在vs13中,main 函数也是被其他函数调用
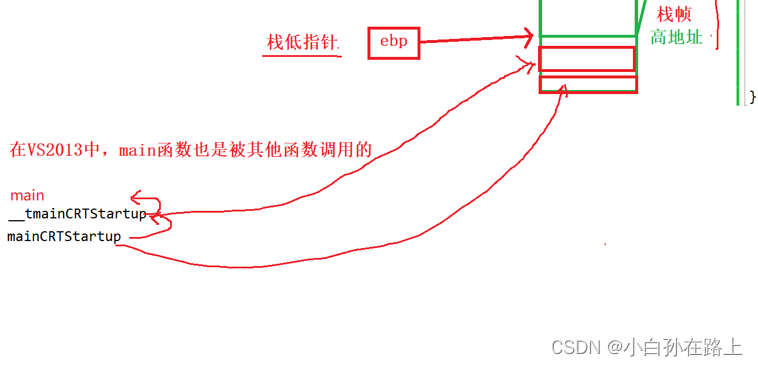
这是vs2022下.调用main函数的函数
三.函数栈帧的创建与销毁过程
STEP1 main函数栈帧的创建

1.压栈
![]()
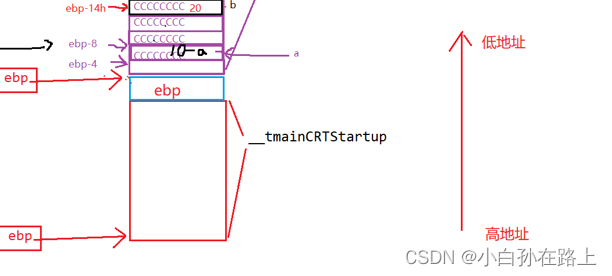
注意:从下往上是由高到低执行的
将ebp的地址放到调用main函数的地址上
2.move
![]()
将esp和ebp的地址指向ebp上

3.sub-减
![]()
0E4H是一个16进制数
就是将esp的地址减去0e4h指向ebp往上0e4h的空间
这一块空间就是为main函数预开辟好的空间.
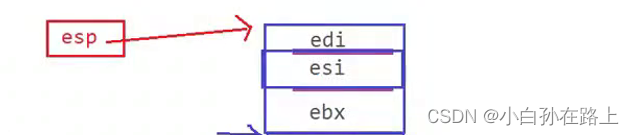
4.三次push-ebx.esi.edi

1.ebx
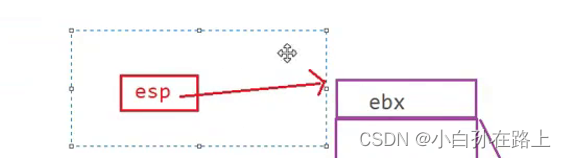
每次开辟空间,esp都会指向最上面的
2.esi-edi
![]()
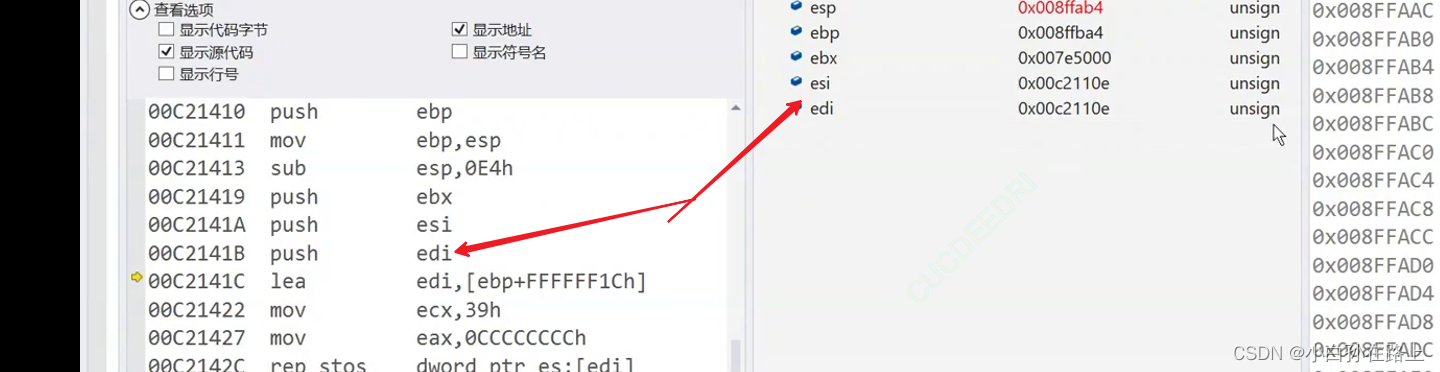
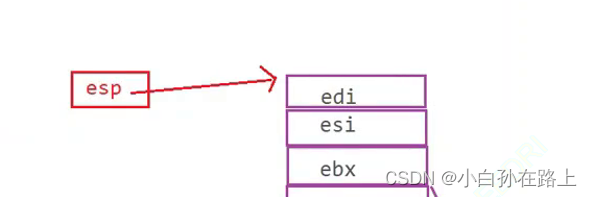
注意,esi,edi地址一样
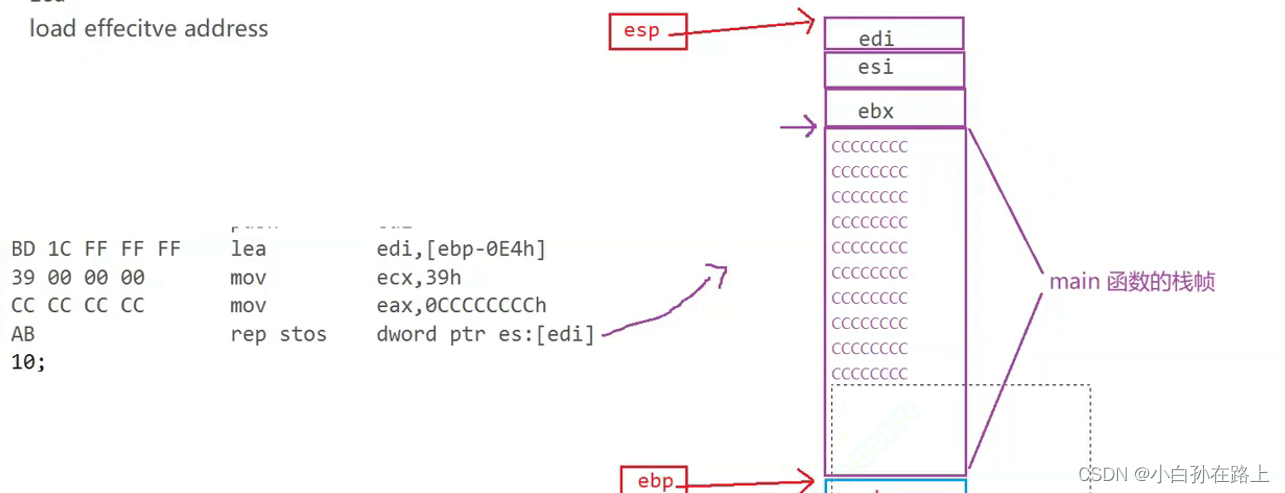
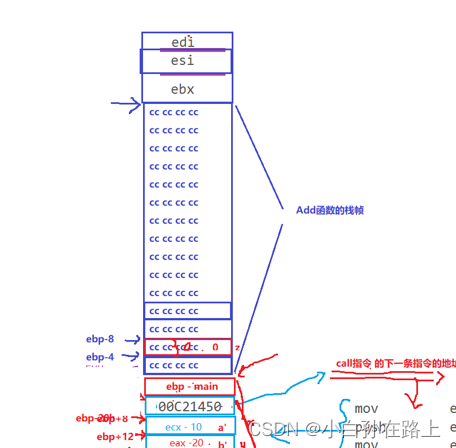
5.lea
lea- load effecitve address-加载有效地址的意思

把后面那个地址加载到edi中那个地址其实就是04eh
6.move

ecx指的是次数
eax右边的指的是数值--c
后面跟的h表示16进制
把右边的值放到左边的寄存器中
7 rep stos
![]()
word表示两个字节..dword就是表示四个字节

意思从edi位置向下的空间四个字节的空间,全部放进0cccccch的数值

到ebp结束(ebp是栈底)
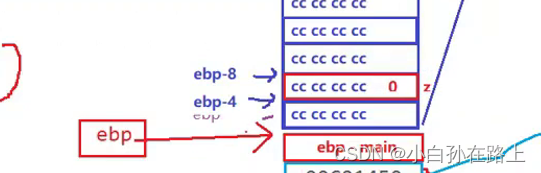
STEP 2 函数主体的实现

一个内存空间四个字节
1.int a = 10;
意思把0AH的值放进[ebp-8]

其实这里就可以解释了为什么局部变量不初始化就会出现烫烫烫..就是因为是随机值.比如cccccc
2.int b = 20;
意思把14H的值放进[ebp-14h] 换算成十进制就是20 也就是ebp-8向上2个内存单位(12个字节-)

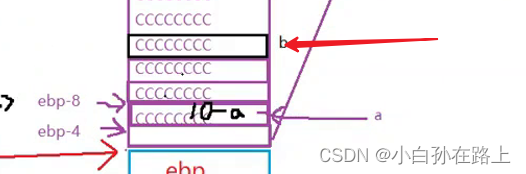
3.int c =0;

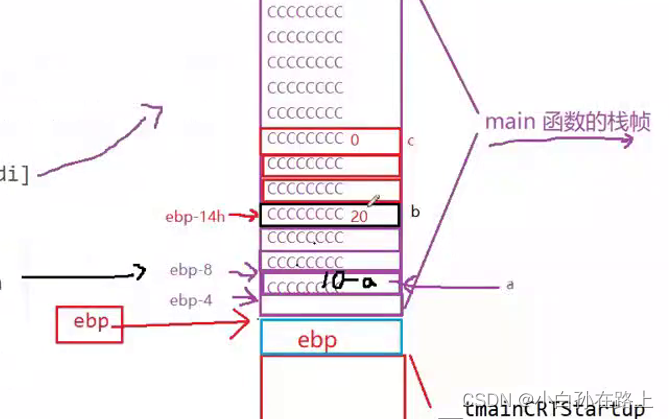
STEP.3函数的传参与局部变量的建立

1.把[ebp-14h]放到eax里
也就是把20(b)的值放到eax里
同时栈顶寄存器esp到上面
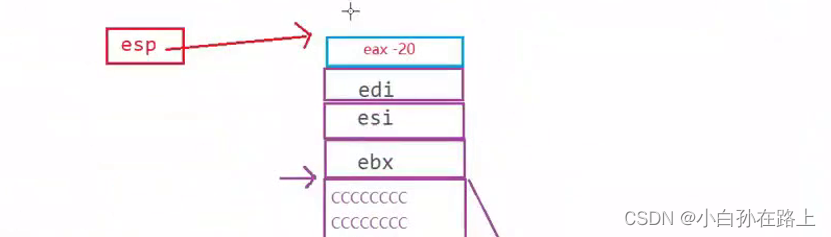
2.eax压栈

3.把[ebp-8]的值放入ecx里
也就是(10)a的值
4.压栈
同时esp向上移动

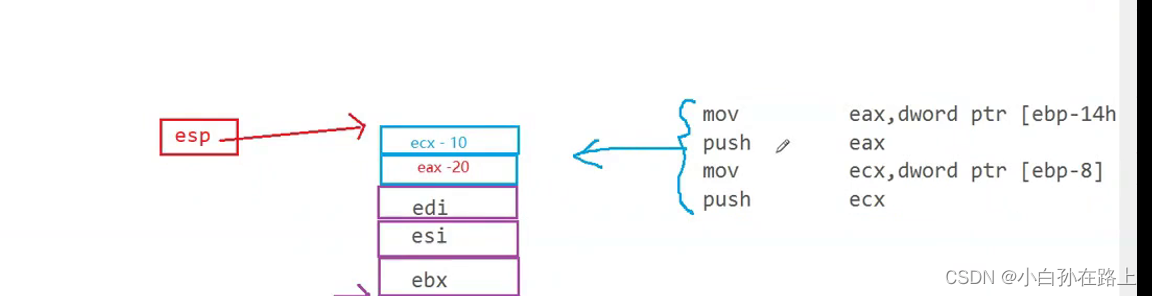
以上四个动作是在传参
5.call
调用

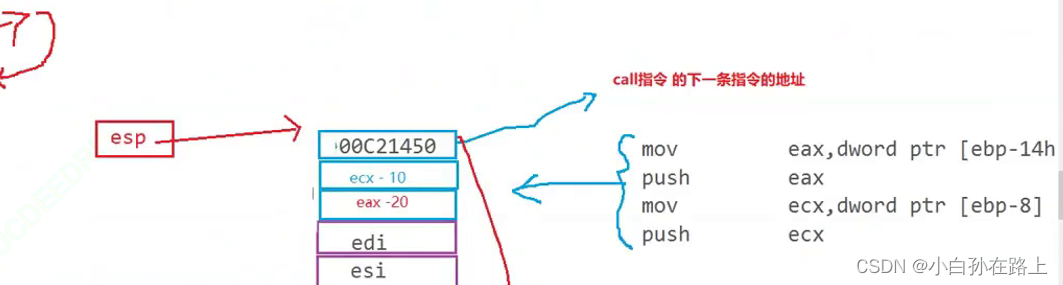
回来的时候需要通过这个地址找回来
STEP.4 分函数的实现
1.push
将main函数的栈底寄存器ebp放在上面

2.move
将栈顶寄存器esp移到栈底寄存器ebp上
![]()
3.sub
将esp寄存器往上加0cch的地址 这一步是为分函数创建新的空间
![]()
4.三次push

与之前雷同
5.lea-mov-mov-rep stos
将[ebp+FFFFFF34H]的值放入edi中初始化并把它以下的空间全部初始化
![]()
STEP 5 分函数的主体
1.初始化z

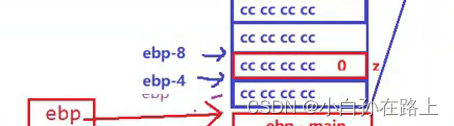
2.传参

把之前创立好的临时参数使用相加放入a的地址[ebp-8];
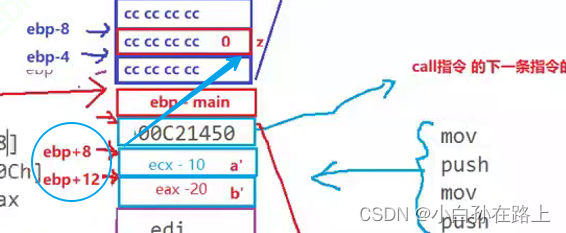
3.返回值

这里可以解决一个疑问.就是z被返回的时候会随着函数调用的结束销毁,但是返回值是放在寄存器eax/
STEP 6 分函数的销毁
1.pop

栈顶的三个寄存器分别pop出去,同时esp往下加一位
2.move
分函数的空间回收,只要把ebp的值赋值给espesp就指回去了
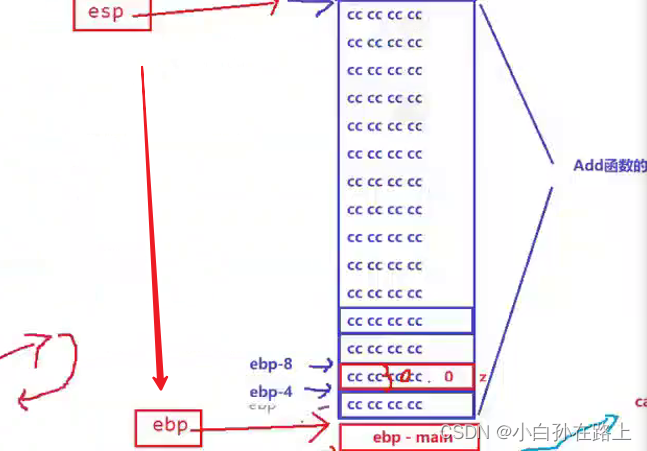
![]()
3.ebp寄存器的弹出

回到原来main函数栈底
![]()
![]()
4.ret
同时esp正好就指向了上次调用函数的下一个地址
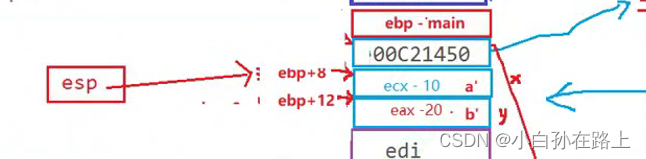
![]()
STEP 7主函数继续实现
1.销毁形参

![]()
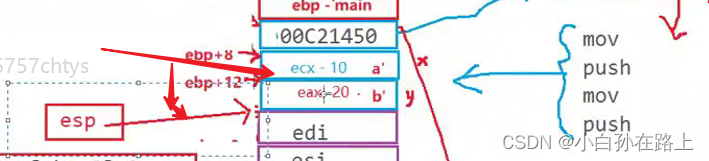
2.传递返回值
![]()
之前函数的返回值放到了eax里
这里就是将eax的值传递到[ebp-20h]里 也就是c的地址
四.思考

五.举例

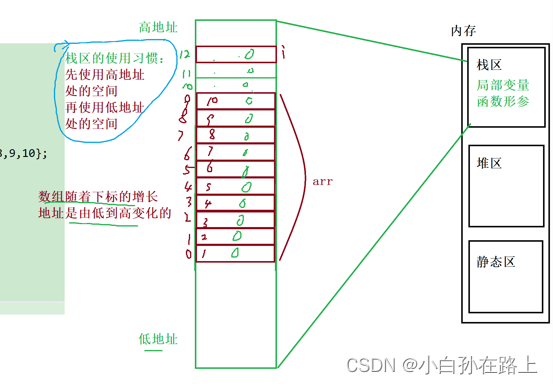
数组下标为10 的地址隔两个内存单元就到了i的地址,如果越界访问数组下标为12的,会导致12与i同时占用一个地址空间
就导致了死循环

六.良好的编程习惯
1.学会使用msdn.观察返回值,参数

2.学会使用const
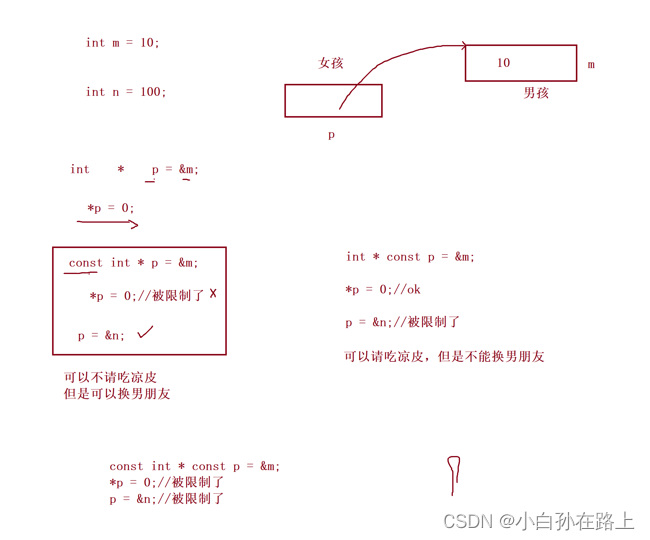
const 可以修饰指针//
//const 放在*的左边(const int* p;)//
//const修饰的是*p,表示p指向的对象不能通过p来改变,但是p变量中的地址是可以改变的//
//const 放在*的右边(int* const p;)//
//const 修饰的是p,表示p的内容不能被改变,但是p指向的的对象是可以通过p来改变的
const修饰指针变量的时候:
- const如果放在*的左边,修饰的是指针指向的内容,保证指针指向的内容不能通过指针来改
变。但是指针变量本身的内容可变。
2. const如果放在*的右边,修饰的是指针变量本身,保证了指针变量的内容不能修改,但是指
针指向的内容,可以通过指针改变。
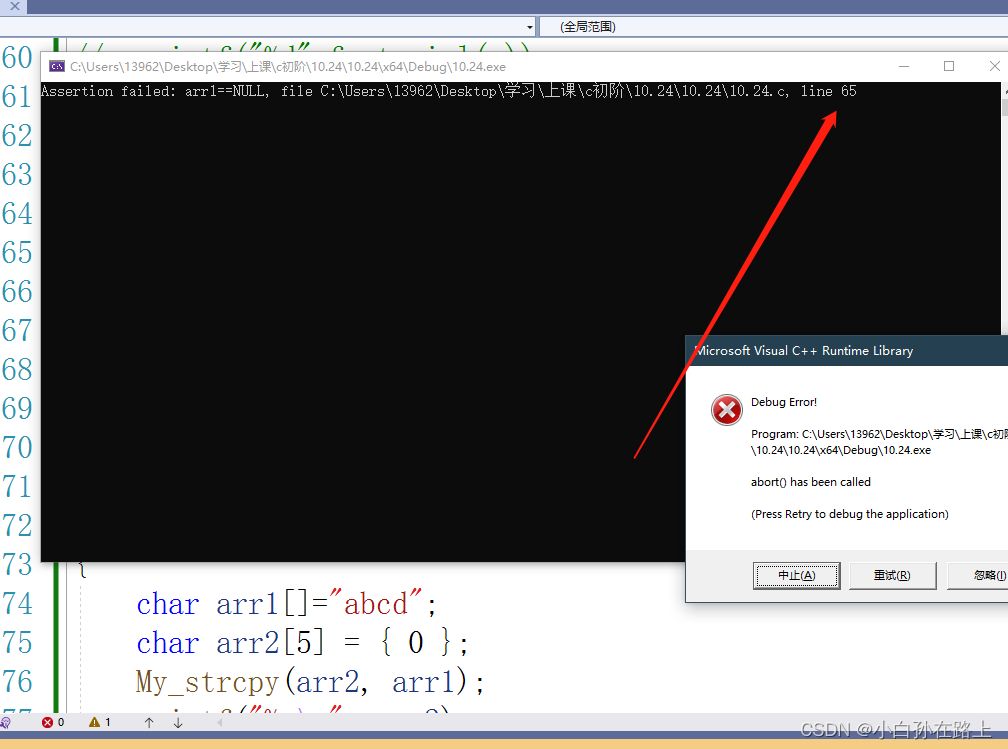
3.assert

如果表达式结果为假.会终止程序并且会展示哪一行出现什么错误
char* My_strcpy(char* arr2, const char* arr1)
{
assert(arr1&&arr2);
while(*arr2++ = *arr1++)
{
;
}
return arr2;
}
int main()//模拟实现strcpy函数,就是把一个字符串的内容放到另一个字符串上 并且包括\0
{
char arr1[]="abcd";
char arr2[5] = { 0 };
My_strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}
size_t 是一些C/C++标准在stddef.h中定义的,size_t 类型表示C中任何对象所能达到的最大长度,它是无符号整数。

七.类型
类型的意义:
- 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
- 如何看待内存空间的视角。
- 对于整形来说:数据存放内存中其实存放的是补码。
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统
一处理;同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。


八.大小端
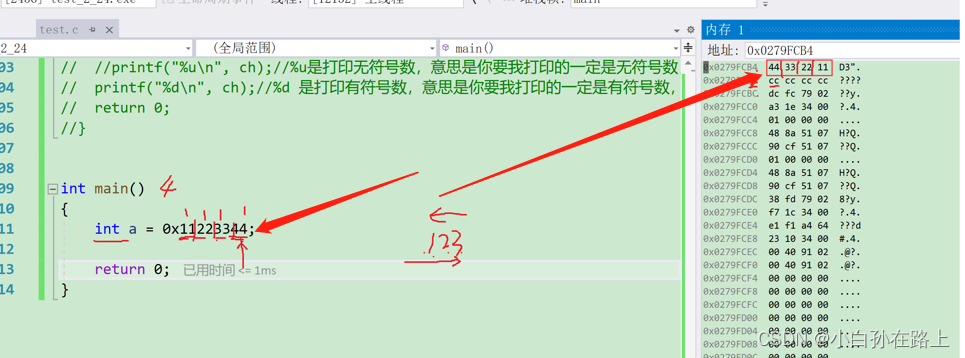
1.大端字节序存储
把一个数据低位字节处的数据存放在高低处,把高位字节处的数据存放在低地址处

2.小端字节序存储
把一个数据低位处的字节的数据放在低地址处\

3.为什么有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元
都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short
型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32
位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因
此就导致了大端存储模式和小端存储模式。
4.题目

int check()
{
int i = 1;//00000000000000000000000000000000001
//0x 00 00 00 01
char* p = (char*)&i;
if (p)
{
return 0;
}
return 1;
}
int main()//判断大小端
{
if (check())
{
printf("大端");
}
else
{
printf("小端");
}
return 0;
}














 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









