






 本文讨论了缓存穿透问题,介绍了两种解决方案:一是缓存空数据,优点是简单但可能导致内存消耗和一致性问题;二是使用布隆过滤器,优点是内存占用少但存在误判,通过调整误判率进行控制。
本文讨论了缓存穿透问题,介绍了两种解决方案:一是缓存空数据,优点是简单但可能导致内存消耗和一致性问题;二是使用布隆过滤器,优点是内存占用少但存在误判,通过调整误判率进行控制。
缓存穿透
查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
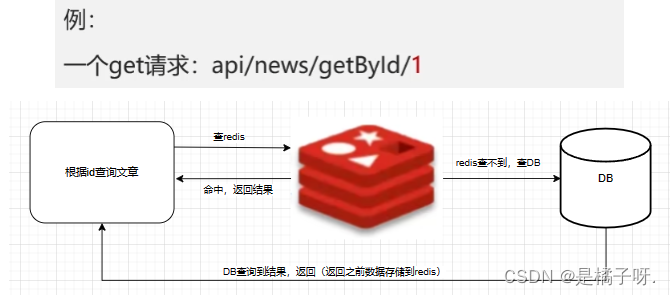
解决方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存
优点:简单
缺点:消耗内存,可能会发生不一致的问题(这种不一致,一般发生在高并发的场景当中,数据库已经更新了,还没来得及刷缓存,这个时候会存在不一致的问题)
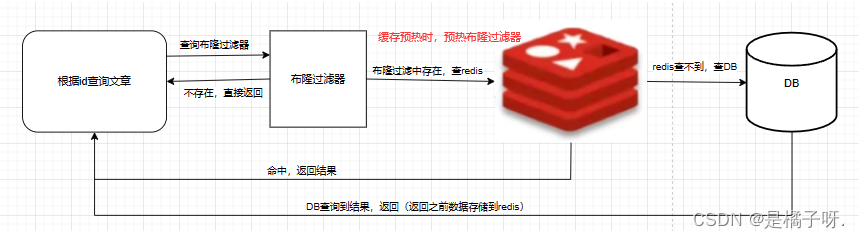
解决方案二:布隆过滤器(下图1为存在,0为不存在)
优点:内存占用较少,没有多余key
缺点:实现复杂,存在误判

其中布隆过滤器可能会出现误判,那么什么是误判呢?
首先,我们有id为1和id为2,id为1经过3次hash找到了三个位置1、3、7并将他们改为1,id为2经过3次hash找到了三个位置9、12、14并将他们改为1。这时来了个id为3但这个id为3的数据不存在,通过三次hash得到了值是3、9、12,这个时候原本的位置都是1则表示id为3存在,但真正的id为3是不存在的。这就是误判
那么误判如何解决呢?
在代码中增加一个误判率来控制误判的范围,使误判在一个可接受的范围内。一般误判率为5%(0.05)
误判率:数组越小误判率就越大。数组越大误判率就越小,但是同时带来了更多的内存消耗。















 3471
3471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









