







 本文介绍了数据挖掘中遇到的缺失值问题及其处理方法,包括众数、中位数和平均数等集中趋势的计算,并展示了如何通过info()、缺失值矩阵图和条形图来检测缺失值。提供了删除、填充(零值、前后值、集中趋势值)等处理策略,并强调了在处理缺失值时应注意的数据量和影响。
本文介绍了数据挖掘中遇到的缺失值问题及其处理方法,包括众数、中位数和平均数等集中趋势的计算,并展示了如何通过info()、缺失值矩阵图和条形图来检测缺失值。提供了删除、填充(零值、前后值、集中趋势值)等处理策略,并强调了在处理缺失值时应注意的数据量和影响。
一、引言
在数据挖掘过程中我们会发现由于各种原因都会存在缺少信息,数据不完整。产生的原因多种多样,主要分为机械原因和人为原因。
二、集中趋势
(1)众数:出现次数最多的变量值(M0);不易受极端值的影响,一个数据集可能没有众数或者有几个众数,用于定序数据和数值型数据。
(2)中位数:排序后处于中间位置上的1值用Me表示;不易受极端值的影响;主要用于定序数据也可用于数值型数据但不能用于定类数据。
计算公式:
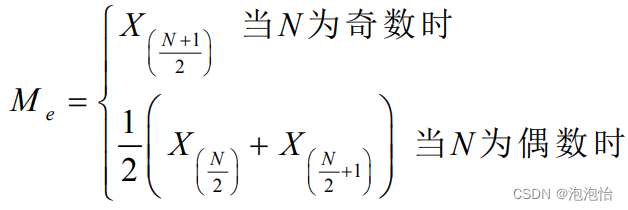
(3)平均数:一组数相加后除以数据的个数而得到的,也称均值;集中趋势最常用的测度值;易受极端值影响。
计算公式:
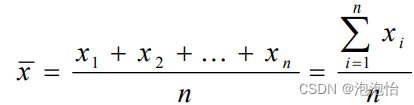
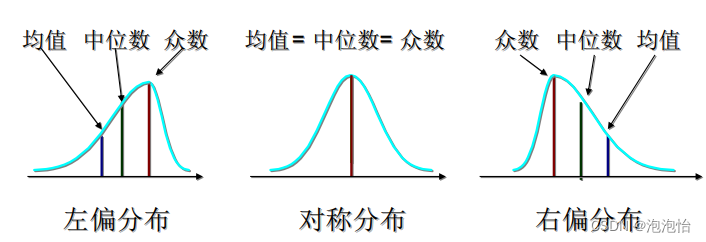
三、集中趋势的关系:
四、缺失值的显示方法
方法一:info()查看
print(data.info())结果;
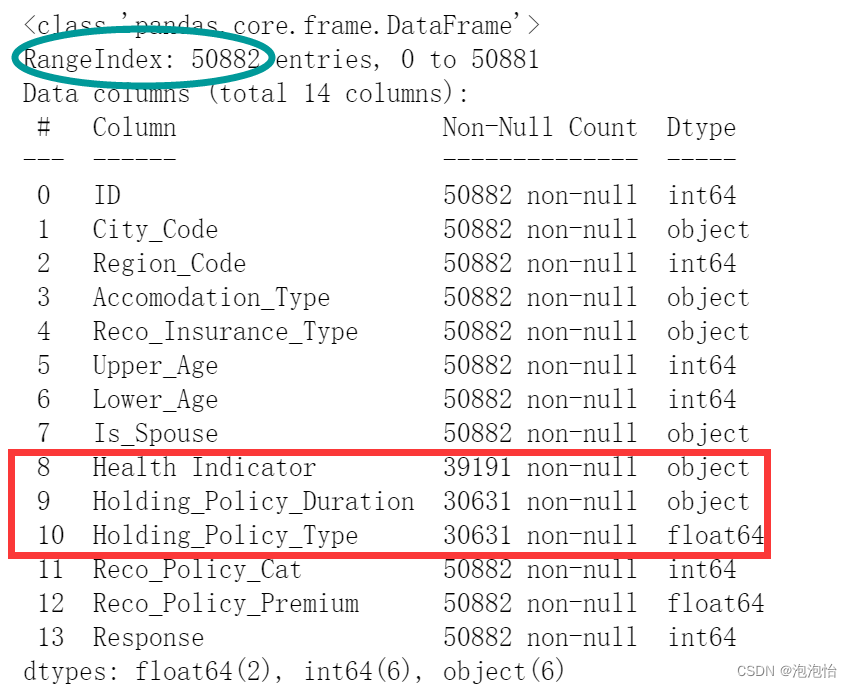
从图上我们就可以看到有缺失,总共50882条数据,8、9、10分别有39191、30631、30631条数据非空。
方法二:缺失值矩阵图:图中白色的地方就是存在缺失值的地方,从图中可以看出Cabin字段存在大量的数据缺失。
import matplotlib.pyplot as plt
import missingno as mnso
mnso.matrix(data)
plt.show()结果;

明显可以看出来:
'Health Indicator', 'Holding_Policy_Duration','Holding_Policy_Type'存在缺失值,我们可以再利用缺失值条形图可以直观看到每一列数据的个数和缺失值的个数。
方法三:缺失值条形图
mnso.bar(data)
plt.show()结果:
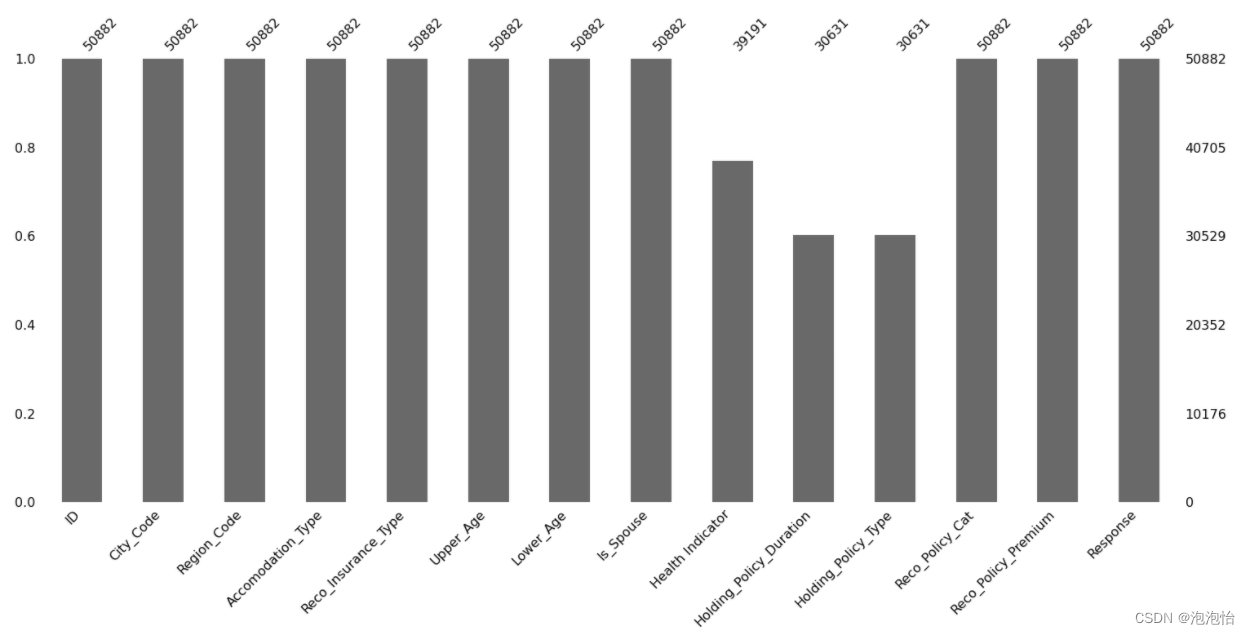
清晰可见。
五、缺失值处理办法
(一)、可以选择删除一行;若数据缺少特别多可以选择删除这一列特征。但是如果删除之后,数据剩余一半那还是不要选择删除。
data1=data.dropna(how='any') #默认为any,删除只要有缺失值所在的整行(二)、还可以用零进行填充:
data2=data.fillna(0) #用0替换所有缺失值(三)、前后进行填充
data3=data.fillna(method='pad') #用前一个数据代替缺失值
data4=data.fillna(method='bfill') #用后一个数据代替缺失值(四)、集中趋势进行填充(众数、中位数、平均数)
1.均值填充
data['Health Indicator']=data['Health Indicator'].fillna(round(data['Health Indicator'].mean()))
2.中位数填充
data['Holding_Policy_Duration']=data['Holding_Policy_Duration'].fillna(data['Holding_Policy_Duration'].median())
3.众数填充
data['Holding_Policy_Type']=data['Holding_Policy_Type'].fillna(data['Holding_Policy_Type'].mode()[0])(五)、验证
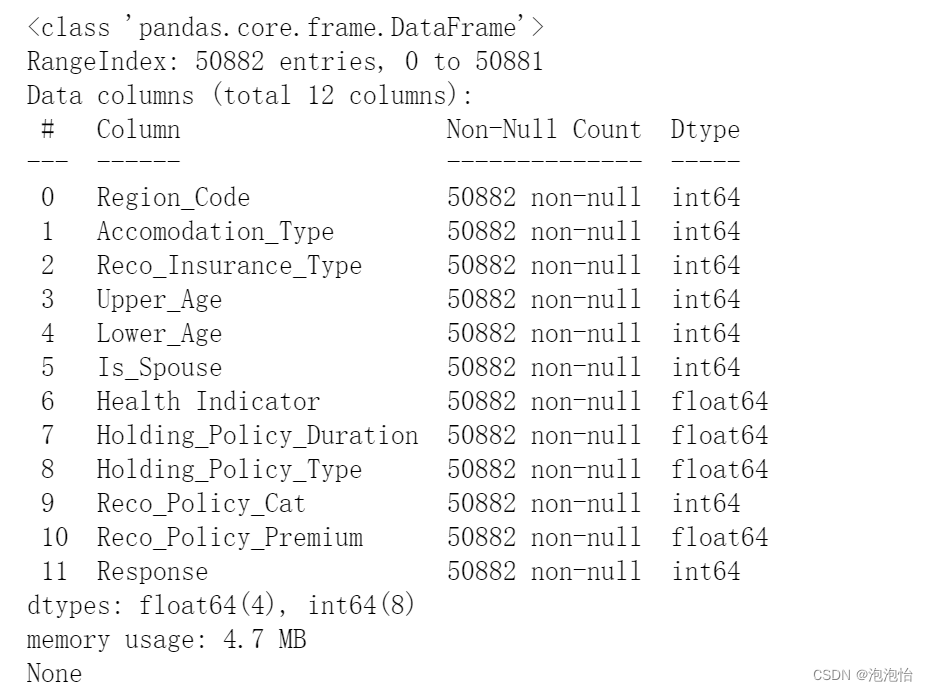
欧克啦
目录


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









