







概念
什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库。
数据库是长期储存在计算机内、有组织的、可共享的数据集合。数据库中的数据指的是以一定的数据模型组织、描述和储存在一起、具有尽可能小的冗余度、较高的数据独立性和易扩展性的特点并可在一定范围内为多个用户共享。
常用的数据库有 MySQL、ORACLE、SQL Server 等。
什么是数据仓库?
数据仓库是决策支持系统(dss)和联机分析应用数据源的结构化数据环境。数据仓库研究和解决从数据库中获取信息的问题。
数据仓库的特征在于面向主题、集成性、稳定性和时变性,用于支持管理决策。
数据仓库存在的意义在于对企业的所有数据进行汇总,为企业各个部门提供统一的, 规范的数据出口。
面向主题:数据仓库中的数据是按照一定的主题域进行组织的,每一个主题对应一个宏观的分析领域。数据仓库排除对于决策无用的数据,提供特定主题的简明视图。
集成的:企业内不同业务部门数据的完整集成。
对于企业内所有数据的集成要注意一致性(假设财务系统中对于性别使用 F/M,而 OA 系统对性别使用 A/B,这就是数据不一致,如果想搭建企业级的数据仓库,需要数据具有一致性)。
稳定的:数仓里不存在数据的更新和删除操作。
变化的:数仓里会完整的记录某个对象在一段时期内的变化情况。
-
数据仓库与数据库对比
| 维度 | 数据仓库 | 数据库 |
|---|---|---|
| 应用场景 | OLAP | OLTP |
| 数据来源 | 多数据源 | 单数据源 |
| 数据标准化 | 非标准化Schema | 高度标准化的静态Schema |
| 数据读取优势 | 针对读操作进行优化 | 针对写操作进行优化 |
数据湖:一个集中存储各类结构化和非结构化数据的大型数据仓库,它可以存储来自多个数据源、多种数据类型的原始数据,数据无需经过结构化处理,就可以进行存取、处理、分析和传输。数据湖能帮助企业快速完成异构数据源的联邦分析、挖掘和探索数据价值。
数据湖 = 数据存储架构 + 数据处理工具
数据存储架构:要有足够的扩展性和可靠性,可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
数据处理工具,则分为两大类:
1)聚焦如何把数据“搬到”湖里。包括定义数据源、制定数据同步策略、移动数据、编制数据目录等。
2)关注如何对湖中的数据进行分析、挖掘、利用。数据湖需要具备完善的数据管理能力、多样化的数据分析能力、全面的数据生命周期管理能力、安全的数据获取和数据发布能力。如果没有这些数据治理工具,元数据缺失,湖里的数据质量就没法保障,最终会由数据湖变质为数据沼泽。
数据仓库和数据湖的不同类比于仓库和湖泊:仓库存储着来自特定来源的货物;而湖泊的水来自河流、溪流和其他来源,并且是原始数据。
| 维度 | 数据湖 | 数据仓库 |
|---|---|---|
| 应用场景 | 可以探索性分析所有类型的数据,包括机器学习、数据发现、特征分析、预测等 | 通过历史的结构化数据进行数据分析 |
| 使用成本 | 起步成本低,后期成本较高 | 起步成本高,后期成本较低 |
| 数据质量 | 包含大量原始数据,使用前需要清洗和标准化处理 | 质量高,可作为事实依据 |
| 适用对象 | 数据科学家、数据开发人员为主 | 业务分析师为主 |
数据仓库分层
-
分层原因
1)把复杂问题简单化
2)减少重复开发
3)隔离原始数据 -
数据仓库基础分层主要是分为四层
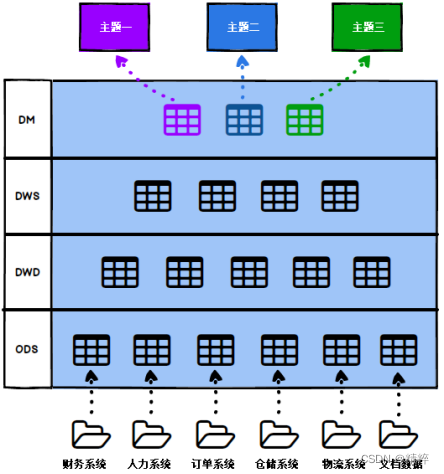
如上图所示,一个公司可能有多个业务系统,而数据仓库就是将所有的业务系统按照某种组织架构整合起来,形成一个仓储平台,也就是数仓。
1.四层分层
第一层:ODS——原始数据层:存放原始数据
ODS层即操作数据存储,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层;一般来说ODS层的数据和源系统的数据是同构的,主要目的是简化后续数据加工处理的工作。从数据粒度上来说ODS层的 数据粒度是 最细 的。ODS层的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存3-6个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存;数据在装入本层前需要做以下工作:去噪、去重、提脏、业务提取、单位统一、砍字段、业务判别。
第二层:DWD——数据明细层:对ODS层数据进行清洗、维度退化、脱敏等。
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证,在ODS的基础上对数据进行加工处理,提供更干净的数据。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,当一个维度没有数据仓库需要的任何数据时,就可以退化维度,将维度退化至事实表中,减少事实表和维表的关联。例如:订单id,这种量级很大的维度,没必要用一张维度表来进行存储,而我们一般在进行数据分析时订单id又非常重要,所以我们将订单id冗余在事实表中,这种维度就是退化维度。
第三层:DWS——数据汇总层: 对DWD层数据进行一个轻度的汇总。
DWS层为公共汇总层,会进行轻度汇总,粒度比明细数据稍粗,会针对度量值进行汇总,目的是避免重复计算。该层数据表会相对比较少,大多都是宽表(一张表会涵盖比较多的业务内容,表中的字段较多)。按照主题划分,如订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
第四层:DM——数据集市层:为各种统计报表提供数据。
存放的是轻度聚合的数据,也可以称为数据应用层,基于DWD、DWS上的基础数据,整合汇总成分析某一个主题域的报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。从数据粒度来说,这层的数据是汇总级的数据,也包括部分明细数据。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年的即可。从数据的广度来说,仍然覆盖了所有业务数据。
2,三层分层
第一层:ODS——原始数据层:存放原始数据
第二层:DW——数据仓库层:数据清洗,初步汇总
本层将从 ODS 层中获得的数据按照主题建立各种数据模型,每一个主题对应一个宏观的分析领域,数据仓库层排除对决策无用的数据,提供特定主题的简明视图。在DW层会保存BI系统中所有的历史数据,例如保存10年的数据。
第三层:DM——数据集市层:为各种统计报表提供数据。
3,五层分层
第一层:ODS——原始数据层:存放原始数据
第二层:DWD——数据明细层:对ODS层数据进行清洗、维度退化、脱敏等。
第三层:DWS——数据汇总层: 对DWD层数据进行一个轻度的汇总。
第四层:ADS——数据应用层:为各种统计报表提供数据
该层是基于DW层的数据,整合汇总成主题域的服务数据,用于提供后续的业务查询等。
第五层:DIM——维表层:基于维度建模理念思想,建立整个企业的一致性维度。
维表层主要包含两部分数据:1)高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。2)低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
OLTP 与 OLAP区别
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。
OLTP 与 OLAP 的异同如表所示:
| OLTP | OLAP | |
|---|---|---|
| 用户 | 操作人员,低层管理人员 | 决策人员,高级管理人员 |
| 功能 | 日常操作处理 | 分析决策 |
| DB设计 | 面向应用 | 面向主题 |
| 数据 | 当前的,最新的,细节的,二维的,分立的 | 历史的,聚集的,多维的,集成的,统一的 |
| 存取 | 读写数十条记录 | 读上百万条记录 |
| 工作单位 | 简单的事务 | 复杂的查询 |
| 用户数 | 上千个 | 上百万个 |
| DB大小 | 100MB-GB | 100GB-TB |
| 时间要求 | 具有实时性 | 对时间的要求不严格 |
| 并发要求 | 高并发 | 低并发 |
| 技术实现方案 | 事务;索引;存储计算耦合 | 大量SCAN;列式存储;存算可以分离 |
| 数据模型/规约 | 关系模型,3NF范式 | 维度模型,关系模型,对范式要求低 |
| 主要应用 | 数据库 | 数据仓库 |
| 技术典范 | MySQL,Oracle | SQL-On-Hadoop |
六范式与反范式
六范式
一范式(1NF):域应该是原子性的,即数据库表的每一列都是不可分割的原子数据项。
域:域就是列的取值范围,比如性别的域就是(男,女)
不符合一范式的表格设计如下:
| ID |
商品 |
商家 |
用户ID |
产地 |
| 001 |
5 台电脑 | XXX旗舰店 |
00001 |
河北省石家庄市裕华区 |
很明显上表所示的表格设计是不符合第一范式的,商品列中的数据不是原子数据项,是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如下表所示:
| ID |
商品 |
数量 |
商家ID |
用户ID |
省 |
市 |
区 |
| 001 |
电脑 |
5 |
00254 |
00001 |
河北 |
石家庄 |
裕华区 |
实际上, 1NF 是所有关系型数据库的最基本要求, 你在关系型数据库管理系统
(RDBMS),例如 SQL Server,Oracle,MySQL 中创建数据表的时候,如果数据表的设计
不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在 RDBMS 中已经存在的数据表,一定是符合 1NF 的。
二范式
二范式(2NF):在 1NF 的基础上,实体的属性完全函数依赖于主关键字(混合主键), 不能存在部分函数依赖于主关键字(混合主键)。
如果存在某些属性只依赖混合主键中的部分属性,那么不符合二范式。
数据表中的所有列,必须依赖于唯一的一个主键。
| 学生 ID |
姓名 |
所属系 |
系主任 |
所修课程 |
分数 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
000001 |
95 |
| 20170901176 |
王小强 |
计算机系 |
马小腾 |
000002 |
99 |
上述表格中是混合主键(学生 ID + 所修课程),但是所属系和系主任这两个属性只依赖于混合主键中的学生 ID 这一个属性,因此,不符合第二范式。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









