







GpuMmu 模型
在 GpuMmu 模型中,GPU 有自己的内存管理单元 (MMU),用于将每进程 GPU 虚拟地址转换为物理地址。
每个进程都有单独的 CPU 和 GPU 虚拟地址空间,这些空间使用不同的页表。 视频内存管理器(VidMm)管理所有进程的 GPU 虚拟地址空间。 VidMm 还负责分配、扩展、更新、确保驻留和释放页表。 GPU MMU 使用的页表的硬件格式对于 VidMm 来说是未知的,并通过设备驱动程序接口 (DDI) 进行抽象封装。 抽象支持多级级别转换,包括固定大小的页表和可调整大小的根页表。
尽管 VidMm 负责管理 GPU 虚拟地址空间及其基础页表,但 VidMm 不会自动将 GPU 虚拟地址分配给分配。 这一责任落在用户模式驱动程序 (UMD) 身上。
VidMm 为 UMD 提供两个主要服务:
-
内存分配和解除分配。 UMD 可以通过现有 Allocate 回调分配视频内存,并通过现有Deallocate回调释放该内存。 Allocate 返回一个指向 VidMm 分配的句柄给 UMD。 GPU 引擎可以在此句柄上运行。 此类分配专门指物理视频内存,GPU 引擎可以通过分配列表访问和处理这些内存。
-
GPU 虚拟地址空间管理。 对于在虚拟模式下运行的引擎,必须先将 GPU 虚拟地址显式分配给内存分配,然后才能进行虚拟化访问。 为此,VidMm 提供 UMD 服务来保留或释放 GPU 虚拟地址,并将特定分配范围映射到进程的 GPU 虚拟地址空间。 这些服务很灵活,允许 UMD 精细控制进程 GPU 虚拟地址空间。 UMD 可以决定为某个分配指定特定的 GPU 虚拟地址,或者让 VidMm 自动选取可用地址,并可能指定一些最小和最大 GPU 虚拟地址的约束条件。 单项分配可以有多个与之关联的 GPU 虚拟地址映射,并且向 UMD 提供服务以实现图块资源协议。
同样,在链接的显示适配器配置中,UMD 可以将 GPU 虚拟地址显式映射到特定的分配实例。 对于每个映射,UMD 可以选择是映射到自身还是映射到特定的对等 GPU。 在此模型中,分配中分配的 CPU 和 GPU 虚拟地址是独立的。 UMD 可以决定在两个地址空间中保持它们相同,或使它们保持独立。
GPU 虚拟地址通过 DDI 接口以固定 4 KB 页面粒度进行逻辑化管理。 GPU 虚拟地址可以引用驻留在内存段或系统内存中的内存分配。 系统内存以 4 KB 物理粒度进行管理,而内存段在驱动程序选择时以 4 KB 或 64 KB 进行管理。 所有 VidMm 分配都对齐,并调整大小为驱动程序选择的页面大小的整数倍。
对无效范围的 GPU 虚拟地址的访问将导致访问冲突,并终止导致访问错误的上下文和/或设备。 为了从这种故障中恢复,VidMm 会启动引擎重置;如果不成功,则会升级为适配器范围的超时检测恢复 (TDR)。
下图演示了 GpuMmu 模型: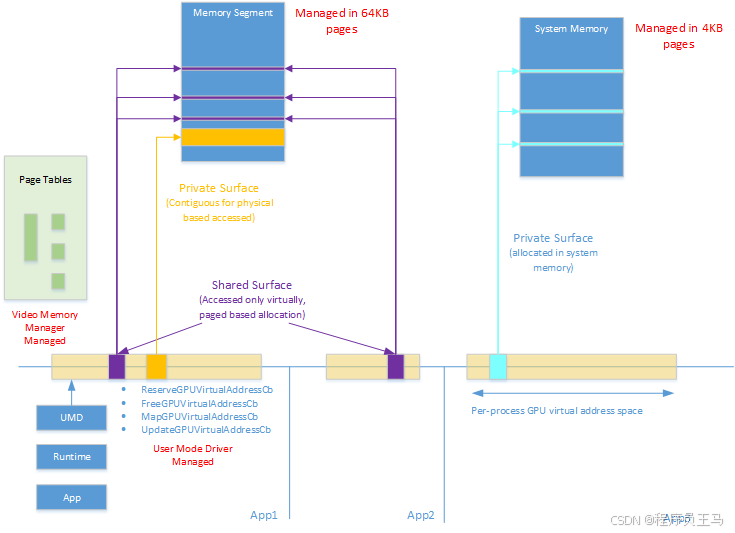
GPU 段
内存段
内存段表示专用于 GPU 的内存。 这可能是离散 GPU 上的 VRAM 或集成 GPU 上的固件/驱动程序保留内存。 可以枚举多个内存段。
WDDM v2 中的新增功能是,内存段作为大小为 4KB 或 64KB 的物理页池进行管理。 使用填充/传输放弃/填充/虚拟传输/虚拟分页操作将 Surface 数据复制到内存段和从内存段复制出来。
CPU 可以通过两种方式之一访问内存段的内容。 首先,内存段可能在 CPU 的物理地址空间中可见,在这种情况下,视频内存管理器只需将 CPU 虚拟地址直接映射到段内的分配。 在 WDDM v2 中引入的视频内存管理器还支持通过与该段关联的可编程 CPU 主机光圈访问内存段的内容。
光圈段
光圈段是一个全局页表,用于从 GPU 引擎的角度使不连续的系统内存页显示为连续。
在 WDDM v2 中,必须报告单个光圈段。
系统内存段
系统内存段是表示系统内存引用的隐式段, (即) 来宾物理地址。 内核模式驱动程序不直接枚举系统内存段。 它由视频内存管理器隐式枚举,并且始终被分配 SegmentId==0。 若要在系统内存段中放置分配,内核模式驱动程序需要使用光圈段 ID。
物理内存参考
在 DDI 中,物理内存引用始终采用段 ID 段偏移对的形式。
按物理地址访问分配
不支持 GPU 虚拟寻址的 GPU 引擎需要通过其物理地址访问分配。 这会影响分配如何从段获取分配的资源。 物理引用意味着分配必须在内存段中连续分配,或者占用光圈段中的连续范围。
若要避免不必要的、昂贵的连续分配,内核模式驱动程序必须在分配创建期间设置新的 DXGK_ALLOCATIONINFOFLAGS2::AccessedPhysically 标志,显式标识需要由呈现引擎以物理方式访问的分配。
当驻留在系统内存中时,此类分配将映射到光圈段。 如果驻留在内存段中,则分配将是连续的。 以这种方式创建的分配可以通过在物理寻址模式下运行的引擎上的分配列表进行引用。
未设置此标志的分配将分配为内存段中的一组页或系统内存中的一组页,其中任一页均可通过 GPU 虚拟地址进行访问。 无法通过分配列表引用以这种方式创建的分配。 引用该分配的任何命令缓冲区提交都将被拒绝。
据悉,主图面可由显示控制器以物理方式访问,并且将在内存段中连续分配,或在显示时映射到光圈段。 当呈现引擎以物理方式访问分配时,内核模式驱动程序应仅设置 AccessPhysically 标志。 主要图面上的隐式物理访问与显式标志的区别在于分配将映射到光圈。 设置 AccessedPhysically 标志后,每当其驻留时,分配将映射到光圈中。 未设置此标志的主要图面只有在显示时才会映射到光圈中。 这有助于消除光圈段的压力,因为通常只有少数主图面正在主动显示,而可能存在大量主图面并呈现到 (即,所有 FlipEx 交换链都是在 dFlip iFlip/ 方案中创建为主图面,并且可能在) 中显示。
| ccessedPhysically==0 | AccessedPhysically==1 | Primary && AccessedPhysically==0 | ||
| 内存段 |
| 系列 允许 GPU 物理访问 | 系列 呈现引擎仅允许 GPU 虚拟访问。 | |
| 光圈段 |
| 驻留时映射 允许 GPU 物理访问 | 显示时映射 呈现引擎仅允许 GPU 虚拟访问。 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









