







显示微型端口驱动程序可以为其定义的每个内存空间或光圈空间段指定 CPU 虚拟地址是否可以直接映射到段中的分配,方法是在段DXGK_SEGMENTDESCRIPTOR结构的Flags 成员中设置 CpuVisible 位字段标志。
若要将 CPU 虚拟地址映射到段,段应通过 PCI 光圈进行线性访问。 换句话说,段内任何分配的偏移量应与 PCI 光圈中的偏移量相同。 因此,视频内存管理器可以根据分配在给定段内的偏移量计算任何分配的总线相对物理地址。
下图演示了如何将虚拟地址映射到线性内存空间段。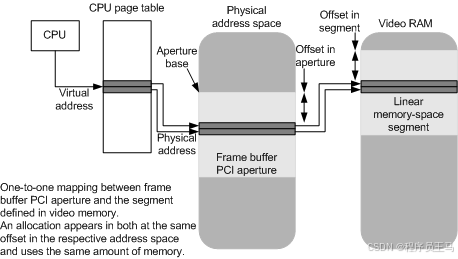
1. 核心机制
(1) CpuVisible 标志的作用
启用 CPU 映射:在 DXGK_SEGMENTDESCRIPTOR 中设置 DXGK_SEGMENT_FLAGS_CPU_VISIBLE,表示该段允许 CPU 直接访问。
地址一致性要求:
- 线性地址对齐:段内的分配偏移必须与 PCI 光圈(Aperture)的偏移严格一致。
- 总线地址计算:VidMm 通过 段基址 + 分配偏移 直接生成 CPU 可访问的物理地址。
(2) 适用段类型
| 段类型 | CPU 直接映射支持 | 典型用途 |
|---|---|---|
| 线性内存空间段(显存) | ✅ 是 | CPU 频繁读写的资源(如动态缓冲区) |
| 线性光圈空间段(系统内存) | ✅ 是 | 共享纹理、跨设备数据 |
| AGP 光圈段 | ✅ 是(传统硬件) | 旧设备兼容 |
2. 驱动配置与地址映射
(1) 段描述符配置
DXGK_SEGMENTDESCRIPTOR Segment = {
.Flags = DXGK_SEGMENT_FLAGS_CPU_VISIBLE, // 启用 CPU 映射
.BaseAddress = 0x80000000, // GPU 物理地址起始
.Size = 0x20000000, // 512MB
.SegmentId = 1,
};(2) CPU 地址计算规则
总线相对物理地址:CPU物理地址 = PCI光圈基址 + (分配偏移 - 段基址)
示例:
- 段基址(GPU):0x80000000
- PCI 光圈基址:0xA0000000
- 分配偏移:0x80001000
- CPU 物理地址:0xA0001000
(3) 可视化映射流程
GPU 显存地址空间:
0x80000000 ┌───────────────────────┐ ← 段基址(GPU 物理地址)
│ Allocation @0x80001000 │
├───────────────────────┤
│ │
0xA0000000 └───────────────────────┘ ← PCI 光圈基址(CPU 物理地址)
│ Mapped CPU Page │ ← CPU 访问 0xA0001000
└───────────────────────┘3. 硬件依赖与限制
(1) PCI 光圈(PCI Aperture)要求
- 线性地址对齐:GPU 显存的物理布局必须与 PCI 光圈地址 逐页对齐(如 4KB 粒度)。
- 固定映射范围:PCI 光圈大小需 ≥ 显存段大小(否则无法完整映射)。
(2) 缓存一致性(Cache Coherency)
可选标志:DXGK_SEGMENT_FLAGS_CACHE_COHERENT
- 若启用,CPU/GPU 缓存自动同步(避免手动刷新)。
- 若无,驱动需调用 Flush/Invalidate 接口(如 D3D12_RESOURCE_BARRIER)。
(3) 性能影响
- 优势:零拷贝(Zero-Copy)数据传输,减少 CPU-GPU 间内存复制。
- 风险:频繁 CPU 写可能引发 GPU 缓存失效,降低性能。
4. 驱动开发注意事项
(1) 地址验证
偏移对齐检查:分配偏移必须满足硬件对齐要求(如 64KB)。
段边界检查:确保 BaseAddress + Size 不超出 PCI 光圈范围。
(2) 错误处理
映射失败:若 PCI 光圈空间不足,返回 STATUS_GRAPHICS_INSUFFICIENT_DMA_BUFFER。
非法访问:CPU 访问未映射地址触发蓝屏(BSOD),需在驱动中拦截。
(3) 多线程安全
并发访问:
- 若多线程读写同一资源,需同步机制(如原子操作)。
- 避免 CPU/GPU 同时修改数据(需显式同步点)。
5. 典型应用场景
(1) 动态顶点/索引缓冲区
需求:CPU 每帧更新数据,GPU 直接读取。
配置:
{
.Flags = DXGK_SEGMENT_FLAGS_CPU_VISIBLE |
DXGK_SEGMENT_FLAGS_CACHE_COHERENT,
.BaseAddress = 0x90000000,
.Size = 0x08000000, // 128MB
}(2) 零拷贝纹理上传
流程:
- CPU 直接写入 CpuVisible 显存。
- GPU 从同一地址读取,无需 CopyResource。
(3) 调试与分析
CPU 侧内存分析:直接通过虚拟地址检查显存内容(如 RenderDoc 抓帧)。
6. 与 Non-CpuVisible 段的对比
| 特性 | CpuVisible 段 | Non-CpuVisible 段 |
|---|---|---|
| CPU 访问 | 直接读写 | 必须通过映射/复制 |
| 地址转换 | 线性映射(PCI 光圈) | 需 VidMm 中转 |
| 性能 | 低延迟(零拷贝) | 较高开销 |
| 适用场景 | 动态数据、共享资源 | 静态纹理、渲染目标 |
7. 总结
CpuVisible 段的核心价值:通过 PCI 光圈实现 CPU 直接访问显存,避免数据复制,提升性能。
关键约束:
- 地址必须线性对齐 PCI 光圈。
- 驱动需处理缓存一致性和多线程安全。
现代 GPU 趋势:随着 PCIe 带宽提升和 Resizable BAR 技术普及,CpuVisible 段的适用性进一步增强。
正确配置 CpuVisible 段可显著优化 CPU-GPU 数据交互,是高性能图形开发的关键技术之一



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









