










家人们好呀,我是 我不是小upper~
今天咱接着唠唠算法模型集合里的数据清洗方法,这部分内容对算法模型训练的重要性,怎么强调都不为过!
咱们都知道,数据就像是算法模型的 “燃料”,质量好坏直接影响模型的 “发挥”。数据清洗呢,就是那个给数据 “挑刺”“大扫除” 的关键步骤,把数据里的噪声、错误都清理掉,这样分析结果才能更靠谱、更精准。
经过精心清洗的数据,就像是给模型打了一针 “强心剂”,能让模型的性能蹭蹭提升,还能大大降低过拟合和欠拟合的风险。想象一下,模型在 “干净” 的数据环境里学习,自然能学到更有用的东西,表现肯定更出色。
而且啊,做好数据清洗,后续的分析和建模工作就会轻松很多,能帮咱们节省大把时间,工作效率直接起飞。所以说,数据清洗绝对是算法模型训练过程中不可或缺的一环!
在数据处理的过程中,方法多种多样。今天这篇文章,就为大家精心挑选出了十个极为重要且常用的数据清洗方法,涵盖了数据处理的多个关键方面。这些方法包括缺失值处理、异常值处理、重复数据移除,它们能帮助我们让数据更加准确和完整;还有数据一致性处理、数据归一化 / 标准化、数据离散化,能够优化数据的分布和特征;类别不平衡处理、文本数据清洗、数据类型转换,有助于提升数据的质量和可用性;最后还有特征工程,这对挖掘数据价值意义重大。下面,咱们就一起深入探讨这些方法。
1. 缺失值处理
在进行数据分析和模型训练时,我们常常会遇到数据集中存在空值或缺失数据的情况。缺失值处理,就是要通过合适的策略去填补或处理这些缺失的数据,从而降低它们对后续分析和模型训练造成的不良影响。常见的缺失值处理方法有删除缺失值、均值填补、中位数填补、众数填补以及插值法等。
核心公式
- 均值填补:
- 均值填补是用数据列的平均值来填补缺失值。公式为:
, 这里的
代表均值,n表示有效观测值的数量。比如,计算一组年龄数据的均值,把所有年龄相加再除以年龄数据的个数,得到的平均值就可以用来填补年龄列中的缺失值。
- 均值填补是用数据列的平均值来填补缺失值。公式为:
- 中位数填补:
- 中位数是将数据集中的数据按大小顺序排列后,位于中间位置的值(如果数据个数是奇数),或者中间两个数的平均值(如果数据个数是偶数)。中位数的优势在于可以避免极端值的影响。例如,在一组包含高收入极端值的薪资数据中,中位数能更好地代表一般水平,用它来填补薪资列的缺失值,能使数据更具代表性。
优缺点
- 优点:
- 采用这些填补方法,不需要删除含有缺失值的数据行或列,这样就能保持数据集的大小,减少数据丢失的情况,最大程度地保留原始数据的信息。
- 像均值、中位数、众数这些统计方法都比较简单易懂,在实际操作中很容易实现。
- 缺点:
- 如果缺失值不是随机出现的,而是存在某种规律(比如特定条件下的数据更容易缺失),那么使用这些简单的填补方法可能会引入偏差,导致数据的真实性受到影响。
- 填补缺失值可能会改变数据原本的分布,进而影响后续模型的性能,比如使模型的预测准确性下降。
适用场景
- 当数据集规模较小,并且缺失值的数量也较少时,这些填补方法比较适用。因为在这种情况下,填补缺失值对整体数据的影响相对较小,能在一定程度上保证数据的完整性和分析结果的可靠性。
- 当我们明确知道缺失值的缺失机制是随机的,也就是说数据缺失是偶然发生的,没有特定的原因或规律时,使用这些方法进行缺失值处理会比较合适。
核心案例代码
下面我们通过一段代码来看看缺失值处理的实际操作过程。首先,导入需要的 Python 库,像pandas用于数据处理,numpy用于数值计算,matplotlib.pyplot和seaborn用于数据可视化。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns然后,创建一个示例数据集,这里有 “Age”(年龄)和 “Salary”(薪资)两列数据,其中包含一些缺失值。
# 创建一个示例数据集
data = {
'Age': [25, np.nan, 30, 22, np.nan, 35],
'Salary': [50000, 60000, np.nan, 52000, 49000, np.nan]
}
df = pd.DataFrame(data)接下来,使用均值填补的方法处理缺失值。对 “Age” 列和 “Salary” 列,分别用它们各自的均值来填补缺失值。
# 缺失值处理:使用均值填补
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Salary'].fillna(df['Salary'].mean(), inplace=True)最后,为了分析填补缺失值后的效果,我们绘制直方图和箱线图。直方图可以展示填补后年龄的分布情况,帮助我们判断填补方法是否合理。正常情况下,数据应该呈现出比较自然的分布状态。箱线图则用于检查填补后的薪水数据分布以及是否存在异常值,它能提供关于薪水数据变异程度的信息。理想状态下,箱体应该相对集中,并且没有明显的离群点。
# 数据分析:绘制直方图和箱线图
plt.figure(figsize=(10, 6))
# 绘制直方图
plt.subplot(1, 2, 1)
sns.histplot(df['Age'], bins=5, color='blue', kde=True)
plt.title('Age Distribution After Imputation')
plt.xlabel('Age')
plt.ylabel('Frequency')
# 绘制箱线图
plt.subplot(1, 2, 2)
sns.boxplot(x=df['Salary'], color='orange')
plt.title('Salary Boxplot After Imputation')
plt.xlabel('Salary')
plt.tight_layout()
plt.show()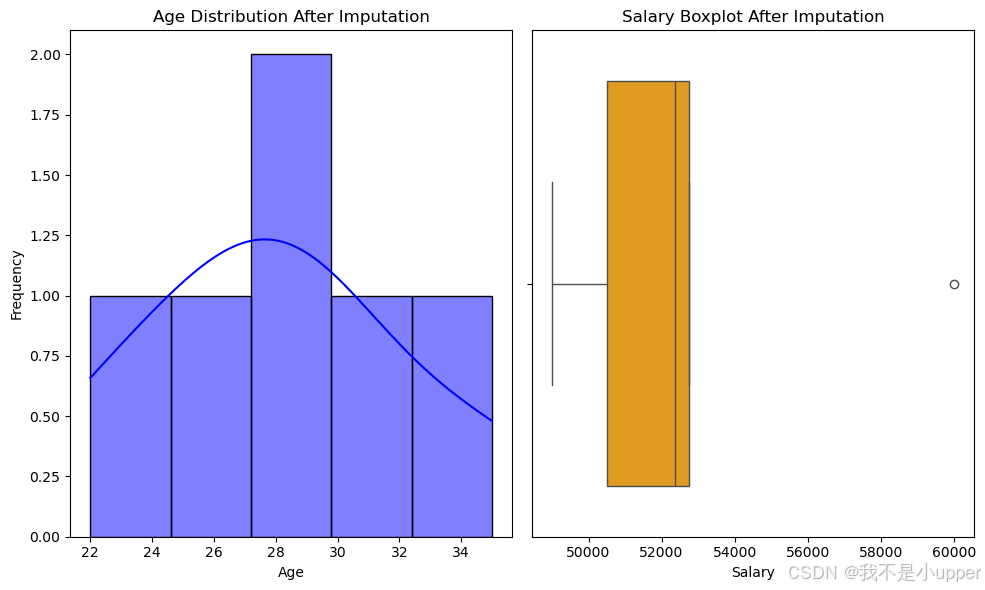
2. 异常值处理
在数据分析的过程中,我们常常会遇到一些特殊的数据点,它们和其他数据相比,显得格格不入,这些就是异常值。异常值处理,就是要把这些与大多数数据差异明显的观测值找出来,并进行相应的处理。异常值的出现可能是因为数据录入时不小心输错了,也可能是测量过程中出了差错,当然,有时候它也可能代表着真实存在的极端现象。常见的异常值处理办法有 z-score 法、IQR(四分位距)法,还有基于模型的方法,比如孤立森林法。
核心公式
- Z-score: Z-score 的计算公式是
,这里的
表示数据的均值,
代表标准差。在实际应用中,如果某个数据点计算出来的 Z 值大于 3 或者小于 -3 ,通常就认为这个数据点是异常值。举个例子,如果我们在分析一组学生的考试成绩,通过计算发现某个学生成绩对应的 Z 值远远超出了 3,那就说明这个成绩很可能是个异常值,也许是录入错误,或者这个学生的情况比较特殊。
- IQR(四分位距): IQR 的计算方法是
,其中
是数据的下四分位数(即把数据从小到大排序后,位于 25% 位置的数值),
是上四分位数(位于 75% 位置的数值) 。异常值的判断标准是:小于
或者大于
的数据点被认定为异常值。比如在分析房价数据时,就可以用这个方法找出那些价格过高或过低的异常样本。
优缺点
- 优点:
- 异常值处理能够有效地把那些可能干扰分析结果的噪声数据找出来并处理掉,让我们的数据更加 “干净”,从而提高后续分析和模型训练的准确性。
- Z-score 和 IQR 这两种方法理解起来很容易,操作也简单,而且在使用时不需要对数据的分布情况做额外的假设,适用范围比较广。
- 缺点:
- 当数据是多维的时候,只用单一维度去检测异常值,可能会忽略掉一些从整体来看属于异常的情况。比如在分析一个包含学生成绩、身高、体重等多维度数据时,仅看成绩维度的异常值,可能就会遗漏掉那些在成绩、身高、体重综合起来看才表现出异常的学生数据。
- 如果数据集中本身就存在大量的异常值,使用这些方法处理时,就有可能把正常的数据误判为异常值。
适用场景
- 当我们希望通过清理数据来提升模型的性能时,异常值处理就非常重要。因为异常值可能会让模型学习到错误的规律,影响模型的预测准确性,把异常值处理好了,模型性能往往会得到提升。
- 当数据集里存在很明显的极端值时,比如在分析收入数据时,出现了极少数超高收入的样本,这时候就需要用异常值处理方法来合理地处理这些极端值,让分析结果更具代表性。
核心案例代码
下面我们通过一段代码来看看异常值处理的实际操作。首先,导入pandas库来处理数据,matplotlib.pyplot和seaborn库用来绘制图表,方便我们直观地观察数据。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns接着,我们创建一个包含异常值的示例数据集,这里只有一列 “Value”,里面有一些正常的数据,也混入了像 100、300 这样明显的异常值。
# 生成一个包含异常值的示例数据集
data = {
'Value': [10, 12, 12, 13, 12, 11, 100, 12, 11, 10, 12, 13, 11, 9, 300]
}
df = pd.DataFrame(data)然后,我们用 IQR 方法来检测异常值。先计算出下四分位数、上四分位数
,进而得到四分位距IQR。
# 计算IQR
Q1 = df['Value'].quantile(0.25)
Q3 = df['Value'].quantile(0.75)
IQR = Q3 - Q1根据计算出的 IQR,确定异常值的上下界,然后在数据集中标记出哪些数据是异常值。
# 检测异常值
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df['Outlier'] = ((df['Value'] < lower_bound) | (df['Value'] > upper_bound))最后,我们通过绘制箱线图和散点图来分析数据。箱线图可以很直观地展示数据的分布情况,箱体外的点就是我们检测出来的异常值,通过它我们能快速找到那些极端的数据点。散点图则把异常值和正常值用不同颜色标识出来,这样我们就能更清楚地看到异常值在数据集中的分布位置。
# 数据分析:绘制箱线图和散点图
plt.figure(figsize=(12, 6))
# 绘制箱线图
plt.subplot(1, 2, 1)
sns.boxplot(x=df['Value'], color='lightgreen')
plt.title('Boxplot of Values')
plt.xlabel('Value')
# 绘制散点图
plt.subplot(1, 2, 2)
sns.scatterplot(x=df.index, y='Value', hue='Outlier', data=df, palette={True:'red', False: 'blue'})
plt.title('Scatter Plot of Values with Outliers')
plt.xlabel('Index')
plt.ylabel('Value')
plt.tight_layout()
plt.show()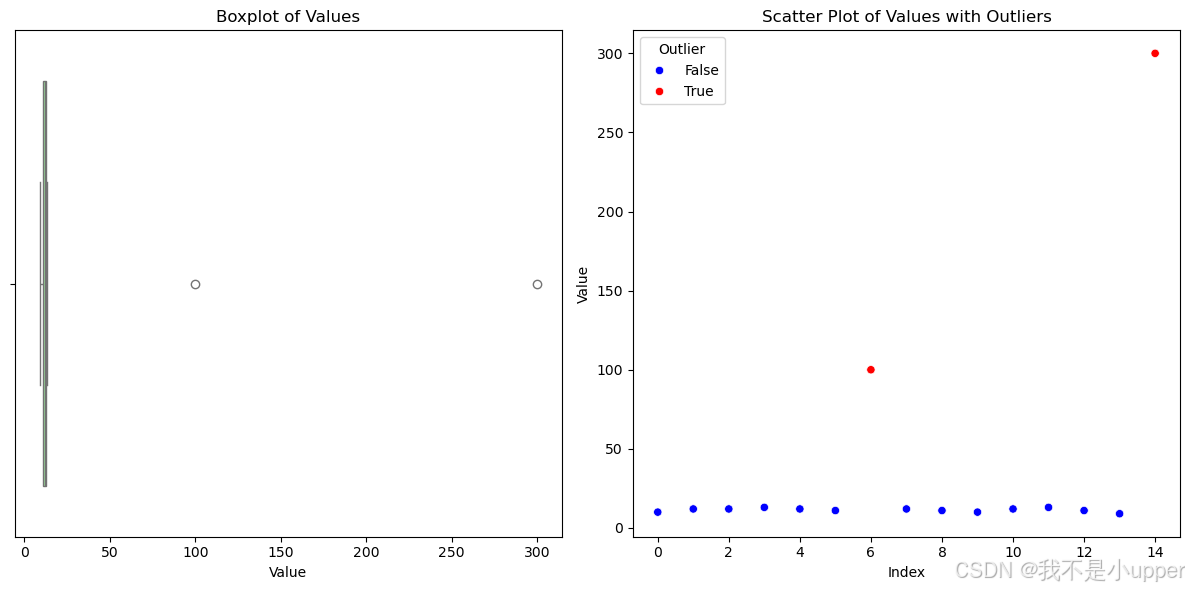
3. 重复数据移除
在处理数据的时候,我们常常会遇到这样的情况:数据集中存在一些一模一样的记录,这些就是重复数据。重复数据移除,简单来说,就是把这些重复的记录找出来并去掉,这样做是为了避免在分析数据时出现信息冗余的问题,保证数据集里每一条数据都是独一无二的。通常,我们会通过查找完全一样的行,或者部分特征相同的记录来找出这些重复数据。
优缺点
- 优点:
- 重复数据就像是数据里的 “累赘”,移除它们可以让数据集变得更加 “清爽”,提高数据的质量。打个比方,你有一份学生成绩表,如果有多个重复的学生记录,就会干扰对学生成绩的准确分析,去掉重复记录后,分析结果会更可靠。
- 重复数据会占用额外的内存空间,在进行计算时也会增加不必要的开销。把它们移除后,计算机在处理数据时就可以更 “轻松”,运行速度也会更快。
- 缺点:
- 虽然大多数时候重复数据没什么用,但在某些特殊场景下,它们可能有自己的价值。比如在记录交易信息的数据库里,每一笔交易记录都很重要,即使内容相同,也不能随意删除,因为它们代表着不同时间发生的交易行为。
- 移除重复数据时一定要小心谨慎。如果不小心误删了有用的数据,就可能会导致分析结果出现偏差,错过一些重要的信息。
适用场景
- 在数据收集的过程中,如果没有严格的去重机制,很容易产生重复记录。比如在问卷调查中,可能因为网络问题或用户误操作,导致同一份问卷被多次提交,这时候就需要进行重复数据移除。
- 在数据预处理阶段,为了提高数据质量,让后续的数据分析和模型训练更加准确,也需要对重复数据进行清理。
核心案例代码
下面我们用一段代码来演示重复数据移除的过程。首先,导入pandas库来处理数据,matplotlib.pyplot和seaborn库用来绘制图表,这样可以更直观地观察数据变化。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns接着,创建一个包含重复数据的示例数据集,这个数据集里有 “Name”(姓名)、“Age”(年龄)和 “Salary”(薪资)三列信息,其中 “Name” 和 “Salary” 列都存在重复数据。
# 创建一个包含重复数据的示例数据集
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'David', 'Bob'],
'Age': [25, 30, 35, 25, 40, 30],
'Salary': [50000, 60000, 70000, 50000, 80000, 60000]
}
df = pd.DataFrame(data)然后,使用drop_duplicates函数移除数据集中的重复数据,得到一个去重后的新数据集df_unique。
# 移除重复数据
df_unique = df.drop_duplicates()最后,通过绘制条形图和饼图来分析数据。条形图可以展示去重前每个名字出现的频率,这样我们就能很容易看出哪些名字存在重复记录。饼图则用来展示去重后每个唯一名字在数据集中所占的比例,通过这个比例,我们可以了解数据的分布情况,看看哪些名字出现的次数比较多,哪些比较少。
# 数据分析:绘制条形图和饼图
plt.figure(figsize=(12, 6))
# 绘制条形图
plt.subplot(1, 2, 1)
sns.countplot(x='Name', data=df, palette='viridis')
plt.title('Count of Names (Before Removing Duplicates)')
plt.xlabel('Name')
plt.ylabel('Count')
# 绘制饼图
plt.subplot(1, 2, 2)
df_unique['Name'].value_counts().plot.pie(autopct='%1.1f%%', startangle=90, colors=sns.color_palette("pastel"))
plt.title('Proportion of Unique Names (After Removing Duplicates)')
plt.ylabel('')
plt.tight_layout()
plt.show()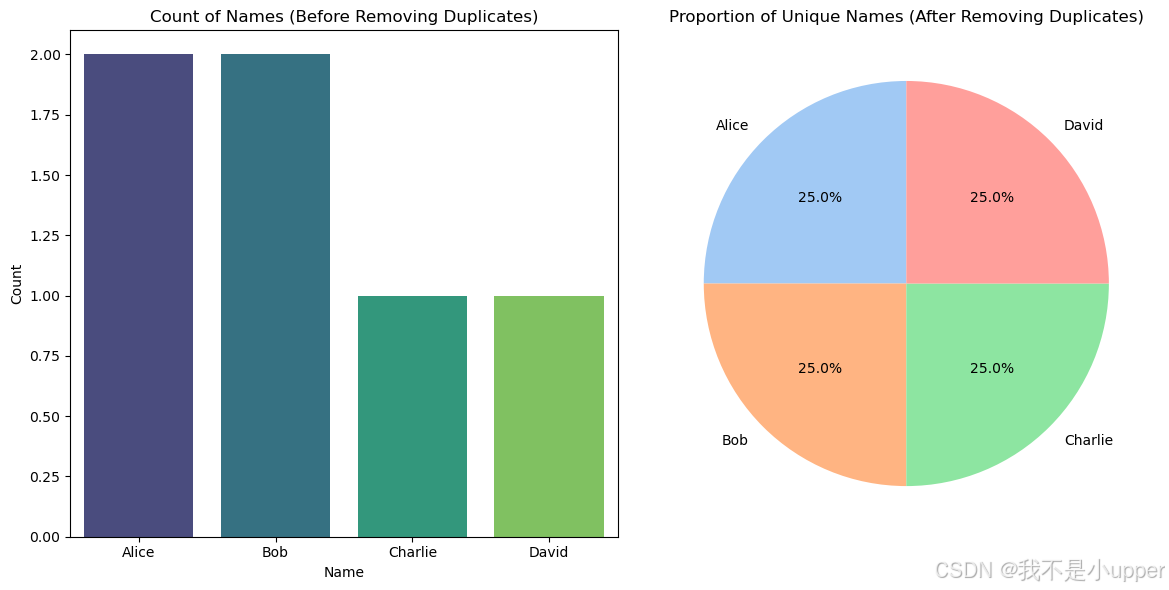
4. 数据一致性处理
在数据处理的过程中,数据一致性处理非常关键。简单来说,它就是要保证数据在不同记录之间保持一致,尤其是当数据来自多个不同的数据源时。这就好比你从不同地方收集了一堆学生成绩信息,有的用百分制记录,有的用等级制记录,还有的记录格式很混乱,这时候就需要进行数据一致性处理,把它们统一成一种格式,同时还要检查数据之间的逻辑关系对不对。一般我们会通过标准化字段格式,比如统一日期的写法、金额的表示方式;还要验证数据的范围,比如年龄不可能是负数,以及数据之间的逻辑关系,像入职时间肯定要早于离职时间等方法来处理数据。
优缺点
- 优点:
- 经过一致性处理的数据,可靠性和准确性都大大提高。就像刚刚说的学生成绩信息,统一格式、检查逻辑后,我们分析出来的结果肯定更靠谱,更能反映真实情况。
- 在后续的数据处理过程中,因为数据变得规范、一致了,出现错误的概率也就降低了。比如在计算学生的平均成绩时,就不会因为数据格式混乱而算错。
- 缺点:
- 要进行一致性检查,需要花费不少时间和计算资源。因为要一条一条数据去检查、去处理,数据量越大,花费的时间和资源就越多。
- 在标准化数据的过程中,可能会出现数据丢失的情况。比如有的数据格式实在太混乱,没办法转换,就只能舍弃了。
适用场景
- 当我们把多个数据源的数据合并到一起时,为了让这些数据能统一使用,就必须进行一致性处理。例如,公司合并了两个部门的客户信息表,两个表的格式、记录方式都不一样,这时候就需要让数据保持一致。
- 在进行数据分析之前,为了保证分析结果的准确性,也要先对数据进行一致性处理。只有数据准确、一致,分析出来的结果才是有价值的。
核心案例代码
下面我们通过一段代码来看看数据一致性处理的实际操作。首先,导入pandas库来处理数据,matplotlib.pyplot和seaborn库用来绘制图表,这样可以直观地看到处理前后的数据变化。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns接着,创建一个示例数据集,这个数据集里有 “ID”(编号)、“Date”(日期)和 “Salary”(薪资)三列信息。可以看到,“Date” 列的日期格式不一样,“Salary” 列的薪资表示方式也不统一,有带 “$” 符号的,还有字符串格式的。
# 创建一个示例数据集
data = {
'ID': [1, 2, 3, 4],
'Date': ['2024-01-01', '01/02/2024', '2024-03-01', 'March 4, 2024'],
'Salary': [50000, '60000$', '70000', 80000.0]
}
df = pd.DataFrame(data)然后,对数据进行一致性处理。先统一 “Date” 列的日期格式,再把 “Salary” 列的格式也统一,去掉 “$” 符号并转换为数值类型。
# 数据一致性处理:统一日期格式和薪资格式
df['Date'] = pd.to_datetime(df['Date'], errors='coerce').dt.strftime('%Y-%m-%d')
df['Salary'] = df['Salary'].replace({'\$': '', ' ': ''}, regex=True).astype(float)最后,通过绘制条形图和折线图来分析处理后的数据。条形图可以清晰地展示每个 “ID” 对应的薪资情况,这样我们就能直观地看到数据清洗后的结果。折线图则能展示薪资随着 “ID” 的变化趋势,让我们对薪资的变化有更清楚的认识。
# 数据分析:绘制条形图和折线图
plt.figure(figsize=(12, 6))
# 绘制条形图
plt.subplot(1, 2, 1)
sns.barplot(x=df['ID'], y=df['Salary'], palette='rocket')
plt.title('Salaries by ID (After Consistency Check)')
plt.xlabel('ID')
plt.ylabel('Salary')
# 绘制折线图
plt.subplot(1, 2, 2)
plt.plot(df['ID'], df['Salary'], marker='o', linestyle='-', color='purple')
plt.title('Salary Trend by ID (After Consistency Check)')
plt.xlabel('ID')
plt.ylabel('Salary')
plt.tight_layout()
plt.show()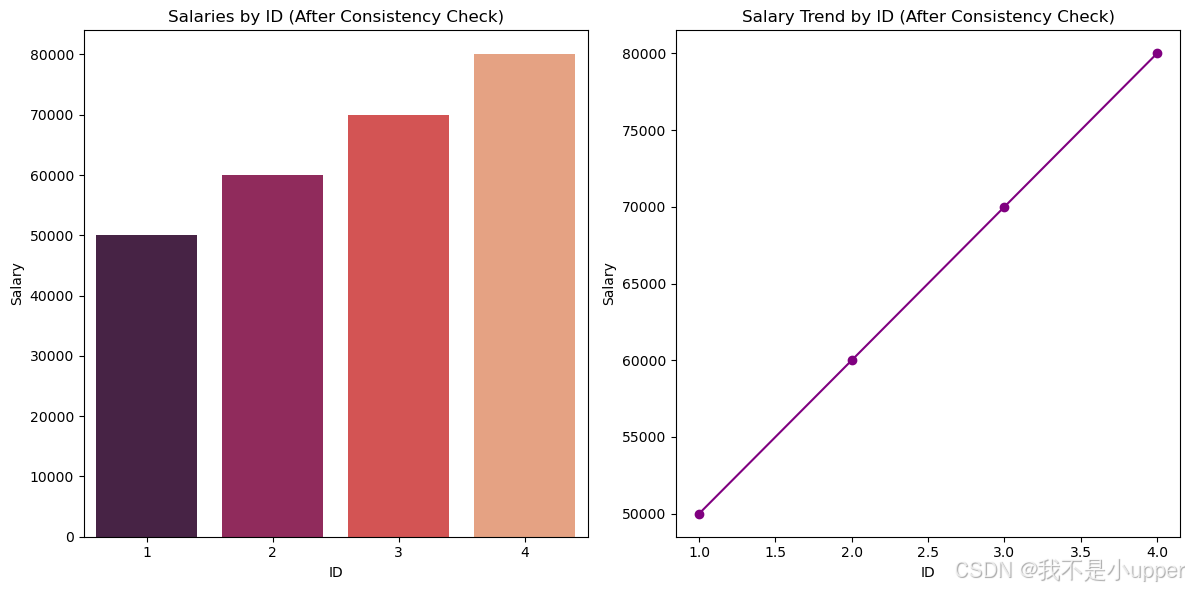
5. 数据归一化 / 标准化
在数据分析和机器学习里,数据归一化和标准化是非常重要的操作。我们在处理数据时,不同特征的数据范围和量纲可能差异很大。比如在分析人的身高和体重数据时,身高通常以厘米为单位,数值在一百多到两百左右;而体重以千克为单位,数值在几十到一百多。这种差异会影响到模型的训练效果。数据归一化和标准化就是想办法把这些数据进行处理,让它们更 “整齐”,便于模型学习。归一化是把数据缩放到特定的范围,像 [0, 1];标准化则是把数据调整为均值是 0、标准差为 1 的状态。
核心公式
- 归一化(Min - Max Scaling):公式为
。这里的x是原始数据值,
是该特征所有数据中的最小值,
是最大值。通过这个公式,就能把数据都转化到 [0, 1] 这个范围里。比如有一组成绩数据,最低分是 50 分,最高分是 90 分,那么 80 分经过这个公式计算后,就会被转化到 [0, 1] 范围内的一个对应值。
- 标准化(Z - score Scaling):公式是
,其中x同样是原始数据值,
优缺点
- 优点:
- 数据归一化和标准化能够消除不同特征量纲带来的影响。想象一下,如果模型在学习身高和体重数据时,因为两者量纲不同,可能会对体重数据 “另眼相看”,导致学习效果不好。经过处理后,模型就能更公平地对待每个特征,训练时收敛速度也会更快。
- 大多数机器学习算法,尤其是像 KNN、SVM 这种基于距离计算的算法,对经过归一化或标准化处理的数据适应得更好。因为这些算法在计算距离时,如果数据量纲不一致,距离的计算结果就不准确,处理后能让计算结果更合理。
- 缺点:
- 要是数据里存在异常值,在进行归一化处理时,这些极端的异常值可能会对最终结果产生比较大的影响。比如有一组身高数据,大部分人身高在 150 - 190 厘米之间,但有一个异常值是 250 厘米,在归一化时,这个 250 厘米的异常值可能会让整个数据的分布都受到较大干扰。
- 对数据进行归一化或标准化时,需要对每个特征单独进行处理。如果数据有很多特征,计算量就会比较大,成本也相应提高。
适用场景
- 当数据集中不同特征的值范围差异很大的时候,就非常适合进行数据归一化或标准化处理。比如分析房屋数据,房屋面积可能从几十平方米到几百平方米,而房价可能从几十万到几千万,这种情况下就需要处理一下,让模型更好地学习。
- 当使用像 KNN、SVM 这些需要计算距离的算法时,对数据进行归一化或标准化处理,可以让算法计算出的距离更准确,从而提高模型的性能。
核心案例代码
下面我们用一段代码来看看数据归一化的实际操作过程。首先,导入pandas库来处理数据,matplotlib.pyplot和seaborn库用来绘制图表,这样能更直观地观察数据处理后的变化。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns接着,创建一个示例数据集,这里有 “Height”(身高)和 “Weight”(体重)两列数据。
# 创建一个示例数据集
data = {
'Height': [150, 160, 170, 180, 190],
'Weight': [50, 60, 70, 80, 90]
}
df = pd.DataFrame(data)然后,对数据进行归一化处理。利用前面提到的归一化公式,把 “Height” 和 “Weight” 这两列数据都缩放到 [0, 1] 的范围。
# 数据归一化
df_normalized = (df - df.min()) / (df.max() - df.min())最后,通过绘制散点图和热力图来分析数据。散点图可以展示归一化后身高和体重之间的关系,让我们能直观地看到这两个特征之间有没有什么联系。热力图则可以展示归一化后各个特征之间的相关性,帮助我们发现数据中潜在的一些规律,比如看看身高和体重之间的相关性有多强,有没有其他隐藏的关系等。
# 数据分析:绘制散点图和热力图
plt.figure(figsize=(12, 6))
# 绘制散点图
plt.subplot(1, 2, 1)
sns.scatterplot(x=df_normalized['Height'], y=df_normalized['Weight'], color='cyan', s=100)
plt.title('Normalized Height vs Weight')
plt.xlabel('Normalized Height')
plt.ylabel('Normalized Weight')
# 绘制热力图
plt.subplot(1, 2, 2)
sns.heatmap(df_normalized.corr(), annot=True, cmap='coolwarm', center=0)
plt.title('Correlation Heatmap of Normalized Data')
plt.tight_layout()
plt.show()
6. 文本数据清洗
在对文本数据进行深入分析之前,通常需要先进行文本数据清洗。这就好比在做饭前要先把食材清洗干净一样,文本数据清洗就是对原始的文本数据进行一系列处理,去除其中的 “杂质”,统一格式,提取出真正有用的信息。常见的处理步骤有很多,比如把文本中的标点符号去掉,将所有字母都转换为小写形式,去除那些没有实际意义的停用词,以及进行词干提取(把单词还原成词根形式)等。
优缺点
- 优点:
- 经过清洗后,文本数据的质量会显著提高。就像把食材洗干净后做出来的饭菜会更好吃一样,清洗后的文本数据在后续分析中能发挥更大的作用,让分析结果更加准确。例如在文本分类任务中,清洗后的数据能帮助模型更精准地判断文本所属的类别。
- 在文本分类、情感分析以及主题建模等任务中,清洗后的文本数据能让模型表现得更好。因为模型不用再去处理那些杂乱无章的信息,可以更专注于文本的核心内容,从而提升性能。
- 缺点:
- 清洗过程必须格外小心谨慎。如果处理不当,很可能会把一些关键信息给误删掉。比如在去除停用词时,如果把某个特定领域中有意义的词误当成停用词去掉了,就会影响对文本的理解和分析。
- 停用词的选择也很有讲究。不同的领域可能有不同的停用词标准,选择不当就会对特定领域的分析效果产生负面影响。例如在医学领域的文本分析中,一些在普通文本中属于停用词的词汇,在医学文本里可能是有意义的专业术语,不能随意去除。
适用场景
- 当我们需要进行文本分类(比如判断一篇文章是体育类、科技类还是其他类别)、情感分析(分析一段文本表达的是积极、消极还是中性情感)或者主题建模(挖掘文本的主题)时,文本数据清洗是必不可少的步骤。只有经过清洗,模型才能更准确地完成这些任务。
- 面对大量原始文本数据时,为了提高处理效率和分析质量,也需要进行预处理,也就是文本数据清洗。比如处理新闻文章、社交媒体评论等大规模文本数据时,清洗可以让后续的分析更加高效、准确。
核心案例代码
下面我们通过一段代码来看看文本数据清洗的实际操作过程。首先,导入re库用于正则表达式操作,从sklearn.feature_extraction.text中导入CountVectorizer用于词频统计。
import re
from sklearn.feature_extraction.text import CountVectorizer接着,创建一个示例文本数据集,包含一些关于编程和数据分析的句子。
# 创建一个示例文本数据集
documents = [
"I love programming in Python! It's amazing.",
"Python is great for data science, but R is also good.",
"I hate debugging. It's frustrating!",
"Data analysis with Python and R is very popular."
]然后,定义一个清洗文本的函数clean_text。在这个函数里,先把文本转换为小写形式,这样可以统一单词的格式,避免因为大小写不同而被当成不同的单词;再使用正则表达式去除文本中的标点符号,让文本只剩下单词和空格。
# 文本数据清洗
def clean_text(text):
text = text.lower() # 转小写
text = re.sub(r'[^\w\s]', '', text) # 去除标点
return text利用这个函数对示例数据集中的每一个文本进行清洗,得到清洗后的文本数据集。
cleaned_documents = [clean_text(doc) for doc in documents]接下来,进行文本分析中的词频统计。使用CountVectorizer将清洗后的文本转换为词频矩阵,然后计算每个单词出现的总次数。
# 文本分析:词频统计
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(cleaned_documents)
word_counts = X.toarray().sum(axis=0)最后,通过绘制条形图和词云图来直观展示词频。条形图可以清晰地展示每个单词出现的频率,帮助我们识别哪些单词在文本中出现得比较频繁;词云图则以一种更直观的方式呈现词频,频率越高的单词在词云图中显示得越大,让我们能快速了解文本的主要特征。
# 数据分析:绘制条形图和词云图
plt.figure(figsize=(12, 6))
# 绘制条形图
plt.subplot(1, 2, 1)
sns.barplot(x=vectorizer.get_feature_names_out(), y=word_counts, palette='magma')
plt.title('Word Frequency')
plt.xlabel('Words')
plt.ylabel('Count')
plt.xticks(rotation=45)
# 绘制词云图
from wordcloud import WordCloud
wordcloud = WordCloud(width=400, height=200, background_color='white').generate_from_frequencies(dict(zip(vectorizer.get_feature_names_out(), word_counts)))
plt.subplot(1, 2, 2)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud')
plt.tight_layout()
plt.show()
7. 特征工程
在数据分析和模型构建的过程中,特征工程起着至关重要的作用。简单来说,它就是一系列对数据特征进行处理的操作,包括从原始数据中提取有用的特征、筛选出对模型最有价值的特征,以及通过各种方式转换现有特征,最终目的是提升模型的性能,让模型在预测、分类等任务中表现得更出色。特征工程主要包含特征选择、特征提取和特征构造这几个关键环节。
优缺点
- 优点:
- 经过精心设计的特征工程,能够显著提升模型的表现。这就好比给运动员配备了更合适的装备,他们就能在比赛中发挥得更好。同时,合理的特征工程还能让模型的可解释性变强,我们可以更清楚地知道模型是依据什么来做出决策的。
- 借助特定领域的专业知识进行特征工程,能够挖掘出那些对模型训练有重要意义的特征。比如在医学数据分析中,医生可以根据医学知识,从大量的生理指标数据里提取出与疾病诊断最相关的特征,帮助模型更准确地判断病情。
- 缺点:
- 特征工程是一个较为复杂的过程,往往需要耗费大量的时间。从对数据的深入分析,到尝试不同的特征处理方法,再到评估处理后的效果,每一个步骤都需要耐心和细心,这无疑增加了整个项目的时间成本。
- 要做好特征工程,领域知识必不可少。如果缺乏相关领域的知识,就很难确定哪些特征真正对任务有帮助,甚至可能选取一些没有价值,甚至会干扰模型训练的特征。例如在金融风险预测中,如果不了解金融市场的运行规律和相关知识,就难以挑选出合适的经济指标作为模型的特征。
适用场景
- 在进行数据分析和建模时,为了从复杂的数据中挖掘出有价值的信息,就需要通过特征工程提取那些真正有意义的特征。比如分析电商用户的购买行为数据,通过特征工程可以提取出用户的购买频率、消费金额分布、购买品类偏好等特征,为后续的用户分类和精准营销提供依据。
- 当我们发现模型的预测准确性不理想,想要进一步提升时,特征工程就是一个非常有效的手段。通过对现有特征的优化和新特征的构造,模型可以更好地学习数据中的规律,从而提高预测的准确性。
核心案例代码
下面我们通过一段代码来实际体验一下特征工程的操作过程。首先,导入需要的库,pandas用于数据处理,numpy用于数值计算,seaborn和matplotlib.pyplot用于数据可视化,fetch_california_housing用于获取加利福尼亚房价数据集,PolynomialFeatures用于构造多项式特征,LinearRegression用于建立线性回归模型。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression接着,加载加利福尼亚房价数据集。这个数据集包含了房屋的各种特征数据以及对应的房价信息。我们将数据中的特征部分存储在X中,目标房价存储在y中。
# 加载California Housing数据集
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target然后,进行特征工程操作。这里我们使用PolynomialFeatures来构造多项式特征,设置degree = 2表示构造二次多项式特征,include_bias = False表示不包含偏差项(即常数项)。通过这种方式,我们从原始特征中构造出了更复杂、可能包含更多信息的新特征。
# 特征工程:构造多项式特征
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)接下来,建立线性回归模型。将构造好的多项式特征数据X_poly作为输入,目标房价y作为输出,训练线性回归模型。
# 建立线性回归模型
model = LinearRegression()
model.fit(X_poly, y)最后,通过绘制图表来分析模型的效果。绘制实际值与预测值的散点图,同时添加一条从最小值到最大值的红色虚线作为参考线。理想情况下,散点应该尽可能地靠近这条对角线,这样说明模型的预测值与实际值比较接近。再绘制特征重要性图,展示每个特征在多项式回归模型中的重要程度,帮助我们了解哪些特征对房价预测的贡献更大。
# 数据分析:绘制实际 vs 预测图和特征重要性图
plt.figure(figsize=(12, 6))
# 绘制实际 vs 预测图
plt.subplot(1, 2, 1)
plt.scatter(y, model.predict(X_poly), alpha=0.5)
plt.plot([y.min(), y.max()], [y.min(), y.max()], color='red', linestyle='--')
plt.title('Actual vs Predicted Prices')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
# 绘制特征重要性图
importance = model.coef_
plt.subplot(1, 2, 2)
sns.barplot(x=importance, y=poly.get_feature_names_out(), palette='viridis')
plt.title('Feature Importance from Polynomial Regression')
plt.xlabel('Importance')
plt.tight_layout()
plt.show()
8. 数据类型转换
在数据分析与建模中,数据类型转换是一项极为关键的基础操作。简单来讲,数据类型转换就是把数据集中的数据从一种类型转变为另一种类型,目的是让数据能更好地契合后续的分析与建模流程。像把数值型数据转化为类别型数据,或者对日期型数据进行格式调整,都是常见的转换方式。
原理剖析
不同的数据类型在存储方式和适用场景上各有不同。比如数值型数据,像年龄、成绩这些数字,适合进行数学运算;而类别型数据,例如性别(男 / 女)、职业(教师 / 医生等),更侧重于分类。当我们需要对数据进行统计分析、建模预测时,如果数据类型不合适,就可能导致计算错误或者模型无法正常运行。所以,数据类型转换就是要根据具体的任务需求,对数据类型进行合理调整。比如在分析销售数据时,把日期从字符串格式转换为日期型,就能更方便地按照时间顺序进行统计;把表示产品类别的数字编码转化为文本类别,能让分析结果更直观易懂。
权衡利弊
- 优点
- 提升数据可用性:经过类型转换后,数据的形式更符合分析需求,就像给拼图找到了合适的位置,能让后续的分析过程更加顺畅。比如将字符串格式的数字转换为数值型后,就可以进行求和、求平均值等数学运算,挖掘数据背后的信息。
- 契合模型要求:不同的模型对输入数据的类型有特定要求。像一些机器学习模型,可能要求输入的特征是数值型数据。将数据类型转换为符合模型要求的类型,能确保模型正常训练和准确预测,提高模型的性能和可靠性。
- 缺点
- 数据风险:一旦转换错误,就可能出现数据丢失或者错误判断的情况。比如把数值型数据错误地转换为类别型数据,可能会丢失数据的数值信息,导致无法进行精确的数值分析;将日期格式转换错误,可能会使时间顺序混乱,影响时间序列分析的准确性。
- 判断难题:要进行正确的类型转换,就需要对数据集中每个字段的类型进行合理判断。然而,在复杂的数据集中,字段的含义和数据格式可能并不明确,这就增加了判断的难度,需要花费时间和精力去分析和验证。
适用场景
- 数据预处理环节:在对数据进行深入分析和建模之前,通常需要进行预处理。这时候,根据后续模型的要求,将数据格式转换为合适的类型是必不可少的步骤。例如在构建预测房价的模型时,需要把房屋面积、价格等数据从字符串转换为数值型,把房龄等数据根据实际情况进行类型调整,让数据更适合模型学习。
- 日期处理需求:在很多数据分析场景中,会涉及到对日期的处理。比如分析电商平台的销售趋势,就需要把日期数据转换为合适的格式,方便按照日、周、月等时间维度进行统计分析,找出销售数据随时间的变化规律。
核心案例代码实操
下面通过一段代码来看看数据类型转换的实际操作。
首先,导入进行数据处理和可视化所需的库,pandas用于处理数据,matplotlib.pyplot和seaborn用于绘制图表,让数据以直观的图形展示出来。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns接着,创建一个示例数据集,这个数据集包含两列信息,“Date” 列记录了日期,是字符串格式;“Value” 列记录了一些数值,同样也是字符串格式。
# 创建一个示例数据集
data = {
'Date': ['2024-01-01', '2024-01-02', '2024-01-03'],
'Value': ['100', '200.5', '300']
}
df = pd.DataFrame(data)然后,进行数据类型转换。使用pandas的to_datetime函数将 “Date” 列从字符串转换为日期型数据,这样就可以按照日期的规则进行排序和计算;使用astype函数将 “Value” 列从字符串转换为浮点型数据,方便进行数值运算。
# 数据类型转换
df['Date'] = pd.to_datetime(df['Date'])
df['Value'] = df['Value'].astype(float)最后,通过绘制折线图和条形图来分析转换后的数据。
- 折线图:绘制 “Value” 随 “Date” 的变化折线图,能清晰地展示数值随时间的变化趋势。通过观察折线的走向,可以了解数据在一段时间内是上升、下降还是波动,帮助我们把握时间序列数据的动态特征。
# 绘制折线图
plt.subplot(1, 2, 1)
plt.plot(df['Date'], df['Value'], marker='o', color='skyblue')
plt.title('Value Over Time')
plt.xlabel('Date')
plt.ylabel('Value')- 条形图:绘制每个 “Date” 对应的 “Value” 条形图,每个条形代表一个日期的数据,通过条形的高度可以直观地比较不同日期数值的大小,方便识别单个日期的值,快速发现数据中的最大值、最小值等特殊情况。
# 绘制条形图
plt.subplot(1, 2, 2)
sns.barplot(x=df['Date'], y=df['Value'], palette='viridis')
plt.title('Bar Plot of Values by Date')
plt.xlabel('Date')
plt.ylabel('Value')
plt.tight_layout()
plt.show()
9. 类别不平衡处理
在进行分类任务时,我们常常会遇到这样的情况:数据集中不同类别的样本数量差异巨大,某一类别的样本数量远远少于其他类别,这种现象被称为类别不平衡。类别不平衡处理就是专门用来解决这类问题的,它的目的是让分类模型在面对不均衡的数据时,也能有更好的表现。常见的处理方法有上采样、下采样以及 SMOTE(合成少数类过采样技术)等。
原理详解
- 上采样:就是增加少数类样本的数量。比如,在一个猫狗分类的数据集中,猫的图片有 1000 张,而狗的图片只有 100 张,为了让模型能更好地学习狗的特征,上采样会复制狗的图片,使狗的样本数量增多,和猫的样本数量更接近。
- 下采样:与上采样相反,它是减少多数类样本的数量。还是以刚才的猫狗数据集为例,下采样会从 1000 张猫的图片中随机挑选一部分删除,让猫和狗的样本数量比例更均衡。
- SMOTE(合成少数类过采样技术):它是一种更智能的上采样方法。SMOTE 不是简单地复制少数类样本,而是通过分析少数类样本的特征空间,在特征空间中生成新的、合理的少数类样本。比如,它会找到少数类样本在特征空间中的邻居,然后在邻居之间的连线上生成新的样本点,以此来扩充少数类样本的数量。
优缺点分析
- 优点
- 提升分类器性能:通过对类别不平衡问题的处理,可以让分类器更加关注少数类样本,从而提高对少数类的识别能力。例如在疾病诊断中,患病样本可能是少数类,处理类别不平衡后,模型能更准确地识别出患病样本,提高诊断的准确性。
- 灵活适应不同数据集:由于有多种处理方法可供选择,我们可以根据不同数据集的特点,灵活选择合适的方法来处理类别不平衡问题。比如对于一些数据量较小的数据集,可能更适合使用 SMOTE;而对于数据量较大的数据集,下采样可能是更好的选择。
- 缺点
- 上采样的过拟合风险:上采样在增加少数类样本数量时,可能会过度依赖已有的少数类样本,导致模型学习到的特征过于局限,从而在训练集上表现很好,但在测试集上却表现很差,出现过拟合现象。
- 下采样的信息损失问题:下采样删除多数类样本的过程中,不可避免地会丢失一些信息。这些丢失的信息可能包含重要的特征和规律,进而影响模型的整体性能。
- SMOTE 的假设局限性:SMOTE 基于一定的特征分布假设来合成新样本,但在实际情况中,这些假设可能并不总是成立。如果数据的真实特征分布不符合 SMOTE 的假设,那么合成的样本可能无法真实反映数据的实际情况,影响模型效果。
适用场景
- 分类任务中存在显著的类别不平衡时:当数据集中不同类别的样本数量差异很大时,就需要使用类别不平衡处理方法,以避免模型在训练过程中偏向多数类,忽略少数类的特征。
- 需要提高模型的精确度和召回率时:在一些对精确度和召回率要求较高的场景中,比如欺诈检测、异常行为识别等,处理类别不平衡问题可以帮助模型更准确地识别出少数类样本,提高模型的综合性能。
核心案例代码解读
下面我们通过一段代码来实际感受一下类别不平衡处理的过程。首先,导入需要用到的库。matplotlib.pyplot和seaborn用于数据可视化,make_classification用于生成一个类别不平衡的数据集,SMOTE则是我们要使用的处理类别不平衡的工具。
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from imblearn.over_sampling import SMOTE接着,使用make_classification函数生成一个类别不平衡的数据集。这里设置了类别数量为 2,两个类别的权重分别为 0.9 和 0.1,这意味着一个类别的样本数量占 90%,另一个类别只占 10%,从而模拟出类别不平衡的情况。同时,还设置了其他一些参数来生成具有一定特征的数据集。
# 创建一个类别不平衡的数据集
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.9, 0.1], n_informative=3,
n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)然后,使用 SMOTE 来处理这个类别不平衡的数据集。创建一个 SMOTE 对象,并指定随机种子为 42,以保证结果的可重复性。调用fit_resample方法,对输入的特征数据X和标签数据y进行处理,得到处理后的特征数据X_res和标签数据y_res。
# 处理类别不平衡:使用SMOTE
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)最后,通过绘制条形图和散点图来分析处理前后的数据。
- 条形图:绘制处理前的类别分布条形图,
sns.countplot函数会统计每个类别的样本数量,并以条形图的形式展示出来。这样我们可以很直观地看到在使用 SMOTE 处理之前,两个类别的样本数量差异,也就是类别不平衡的情况。
# 绘制条形图
plt.subplot(1, 2, 1)
sns.countplot(x=y, palette='pastel')
plt.title('Class Distribution Before SMOTE')
plt.xlabel('Class')
plt.ylabel('Count')- 散点图:绘制处理后的散点图,用
X_res的前两个特征作为横纵坐标,y_res作为颜色区分的依据。通过这个散点图,我们可以看到经过 SMOTE 处理后,少数类样本的分布情况,以及合成的样本是如何分布在特征空间中的,从而帮助我们理解 SMOTE 合成样本的效果。
# 绘制散点图
plt.subplot(1, 2, 2)
sns.scatterplot(x=X_res[:, 0], y=X_res[:, 1], hue=y_res, palette='deep')
plt.title('Scatter Plot After SMOTE')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.tight_layout()
plt.show()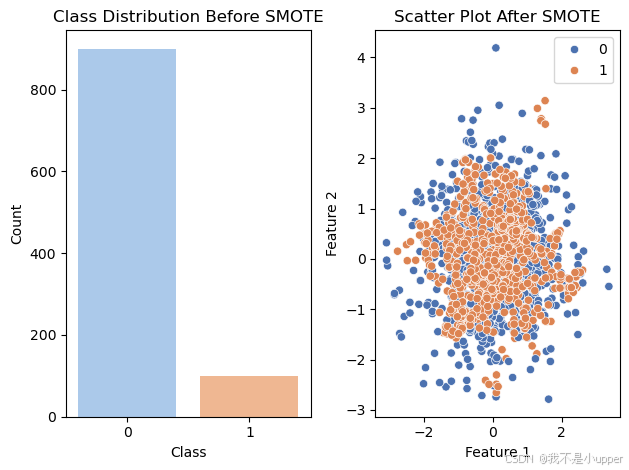
10. 数据离散化
在数据分析和建模过程中,数据离散化是一项重要的数据预处理操作。简单来说,数据离散化就是把连续变化的特征转化为一个个离散的类别,这在分类问题中能够显著提升模型的性能表现。常见的实现方法主要有分箱(Bin)和聚类这两种。
原理详解
- 分箱:分箱是将连续数据划分成若干个区间的过程,常见的分箱策略有等宽离散化和等频离散化。
- 等宽离散化:等宽离散化是按照固定的宽度将数据进行划分。公式为
, 其中
。这里的X代表要离散化的连续数据,n是我们设定的分箱数量,w是每个箱子的宽度,
表示第i个箱子的区间范围。例如,对于一组考试成绩数据,成绩范围是 0 到 100 分,如果我们想把它等宽离散化为 5 个箱子,那么每个箱子的宽度
,第一个箱子就是
,第二个箱子是
,以此类推。
- 等频离散化:等频离散化则是将数据分成n个频率相同的区间。这意味着每个区间内的数据点数量大致相等。比如有 100 个数据,要分成 5 个等频区间,那么每个区间内大约有 20 个数据点。这样划分可以确保每个区间在数据分布上具有相似的代表性。
- 等宽离散化:等宽离散化是按照固定的宽度将数据进行划分。公式为
- 聚类:聚类是基于数据的相似性,将数据点划分成不同的簇。在数据离散化中,每个簇就对应一个离散的类别。聚类算法会自动寻找数据中的自然分组结构,与分箱不同,它不是基于预先设定的规则(如等宽或等频),而是根据数据自身的特征来进行划分。
优缺点分析
- 优点
- 增强可解释性:连续数据往往比较复杂,难以直观理解。经过离散化后,数据变成了一个个离散的类别,例如将年龄这个连续特征离散化为 “少年”“青年”“中年”“老年” 等类别,这样的离散特征更加直观,很容易被理解和解释。
- 提升特定算法性能:对于一些算法,如决策树,离散化后的特征可以让模型的构建更加简单高效。决策树在处理离散特征时,能够更清晰地划分节点,找到数据中的分类规则,从而提高算法的准确性和效率。
- 缺点
- 信息损失:在离散化的过程中,连续数据的细节信息不可避免地会有所丢失。比如将学生成绩从具体分数离散化为等级,像 85 分和 89 分可能都被划分到同一个等级,这样就无法体现出这两个分数之间的差异,损失了成绩的精确信息。
- 参数选择影响大:分箱数和分箱方法的选择对模型性能有很大影响。如果分箱数选择不当,可能会导致数据过度离散或离散不足,都不利于模型学习数据的特征。选择合适的分箱策略和参数需要对数据有深入的理解和一定的经验。
适用场景
- 分类问题中的特征转换:当我们进行分类任务时,有些模型更适合处理离散的类别特征。例如在预测客户是否会购买某产品时,将客户的年龄、收入等连续特征离散化后,可以更好地被分类模型利用,提高预测的准确性。
- 数据分析中的分组处理:在进行数据分析时,为了更清晰地观察数据的分布和特征,常常需要对数据进行分组处理。数据离散化提供了一种有效的分组方式,帮助我们从不同的角度分析数据。
核心案例代码解读
下面通过一段代码来看看数据离散化的实际操作过程。 首先,创建一个示例数据集,这里以学生的考试成绩为例,数据集包含一个名为 “Score” 的列,记录了学生的成绩。
# 创建一个示例数据集
data = {
'Score': [58, 73, 80, 90, 55, 88, 66, 74, 99, 61]
}
df = pd.DataFrame(data)然后,对 “Score” 列的数据进行离散化处理,这里采用等宽分箱的方法。我们设定了 5 个箱子,分别对应不同的分数区间,同时为每个区间赋予一个等级标签,如 “F”“D”“C”“B”“A”。使用pd.cut函数将成绩数据划分到对应的箱子,并添加一个新的 “Grade” 列来存储等级信息。
# 数据离散化:等宽分箱
bins = [0, 60, 70, 80, 90, 100]
labels = ['F', 'D', 'C', 'B', 'A']
df['Grade'] = pd.cut(df['Score'], bins=bins, labels=labels, right=False)最后,通过绘制条形图和饼图来分析离散化后的数据。
- 条形图:使用
seaborn库的countplot函数绘制条形图,展示不同等级的分布情况。通过条形图,我们可以直观地看到每个等级的学生数量,从而观察离散化的效果,了解成绩在各个等级的分布情况。
# 绘制条形图
plt.subplot(1, 2, 1)
sns.countplot(x='Grade', data=df, palette='pastel')
plt.title('Grade Distribution After Discretization')
plt.xlabel('Grade')
plt.ylabel('Count')
- 饼图:利用
pandas的value_counts函数统计每个等级的数量占比,并绘制饼图。饼图能够清晰地展示各等级在总体中所占的比例,让我们一眼就能看出哪个等级的学生占比最高,哪个等级占比最低,了解各等级的相对权重。
# 绘制饼图
plt.subplot(1, 2, 2)
df['Grade'].value_counts().plot.pie(autopct='%1.1f%%', startangle=90, colors=sns.color_palette("pastel"))
plt.title('Proportion of Grades After Discretization')
plt.ylabel('')
plt.tight_layout()
plt.show()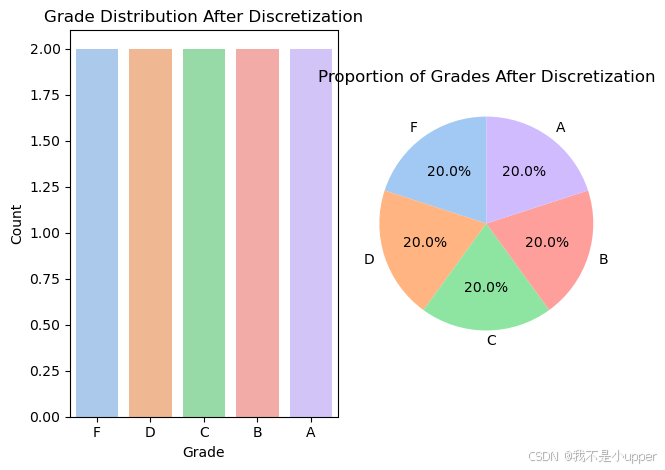


















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









