






目录
哈希表是什么结构?
哈希表(Hash Table),也称为散列表,是一种常见的数据结构。哈希表是一种通过哈希函数将键映射到数组中的一个位置,然后在该位置存储对应的值的数据结构(就是存储键值对)。哈希表的核心思想是利用哈希函数将键转换成数组的索引,从而实现快速的查找、插入和删除操作。
哈希表的核心组件包括:
- 哈希函数: 哈希表的核心,将键转换成数组的索引。好的哈希函数应该将键均匀地映射到数组的不同位置,以减少哈希冲突。将键转换为哈希值,哈希值用于确定键在表中的位置。这个哈希值通常是一个大整数,为了适应哈希表的大小,通常对这个哈希值取模(即哈希值 % 数组大小)以获得数组的索引。
- 数组: 哈希表的底层存储结构通常是一个数组,数组的每个元素称为一个“桶”,每个桶可以包含一个或多个键值对,不同的哈希表实现可能使用不同的方式来存储这些键值对。由于哈希函数的计算可能会导致不同的键映射到同一个桶(即发生哈希冲突),每个桶必须能够处理多个键值对。
- 冲突处理 或 碰撞处理: 哈希函数将键转换成数组的索引,当两个或多个键具有相同的哈希值,可能将不同的键映射到数组的同一个位置(同一个桶),所以可能会发生哈希冲突(碰撞)。解决冲突的常见的方法包括链地址法(拉链法)和开放地址法。(后面会介绍这两种方法)
map 底层扩容机制
map 的底层实现是一个哈希表(hash table),在 Go 运行时,当 map 中的元素数量达到一定阈(yu)值时,会触发扩容操作。这个阈值由 map 的负载因子(load factor)决定,负载因子是指 map 中已存储的元素数量与 map 的桶(buckets)数量之比。当负载因子超过一定阈值(通常为 6.5)时,map 会自动进行扩容。扩容通常需要创建一个更大的哈希表,并将现有元素重新映射到新表中。
Go 中 map 的底层实现中,桶内部会存储链表或者红黑树等数据结构来处理哈希冲突。扩容操作会使得桶的数量翻倍,并重新计算每个元素的哈希值,将其分配到新的桶中。扩容的过程是由 Go 运行时自动管理的,程序员不需要手动触发。由于扩容操作可能会导致内存重新分配和数据的重新散列,因此在编写代码时应该考虑到 map 的扩容操作可能会带来的性能开销。
map 和 bucket 数据结构
在go的map实现中,它的底层结构体是hmap,hmap 结构表示一个哈希表,包含了桶数组以及相关的元数据,hmap里维护着若干个bucket数组。
map 数据结构由 runtime/map.go:hmap 定义:
type hmap struct {
count int // 元素的个数,调用len(map)时返回的就是该字段值
flags uint8 // 状态标志(是否处于正在写入的状态)
B uint8 // 代表buckets桶的对数,桶的个数就是 2^B 个
noverflow uint16 // 溢出桶的数量
hash0 uint32 // 生成hash的随机数种子
buckets unsafe.Pointer // 2^B个桶对应的数组指针(如果桶的个数为0,它就为nil)
oldbuckets unsafe.Pointer // 发生扩容时,记录扩容前的buckets数组指针(老的buckets数组大小是新的buckets的1/2,非扩容状态下,它为nil)
nevacuate uintptr // 表示扩容进度,小于此地址的buckets代表已搬迁完成
extra *mapextra // 用于保存溢出桶的地址(这个字段是为了优化GC扫描而设计的)
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
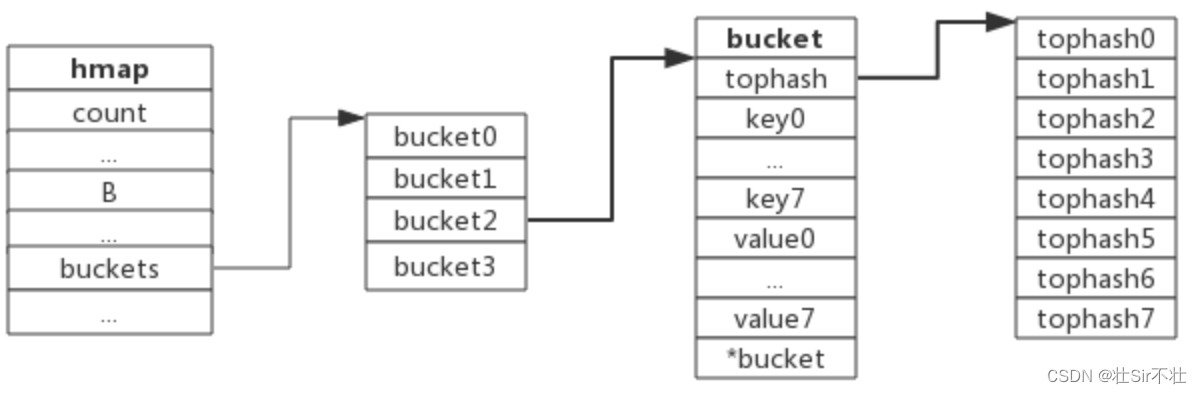
}bmap 结构表示一个存储桶(bucket),每个桶包含8个键值对。如果8个满了,又来了一个键值对到了这个桶中,会使用overflow连接下一个桶,即桶溢出。
一个桶内最多装8个key,这些key之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果的低B位是相同的,又会根据 key 计算出来的 hash 值的高8位来决定key到底落入桶内的哪个位置。
bucket(桶) 数据结构由 runtime/map.go:bmap 定义:
// bucket数据结构:
type bmap struct {
tophash [bucketCnt]uint8
// 长度为8的数组,用来快速定位key是否在这个bmap中
// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表key在这个桶中
}
// 在编译期间bmap结构体会拓展为新的结构体
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}每个bucket可以存储8个键值对:
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/...value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
注意:上述中data和overflow并不是在结构体中显示定义的,而是直接通过指针运算进行访问的。
下图展示bucket存放8个key-value对:
哈希冲突
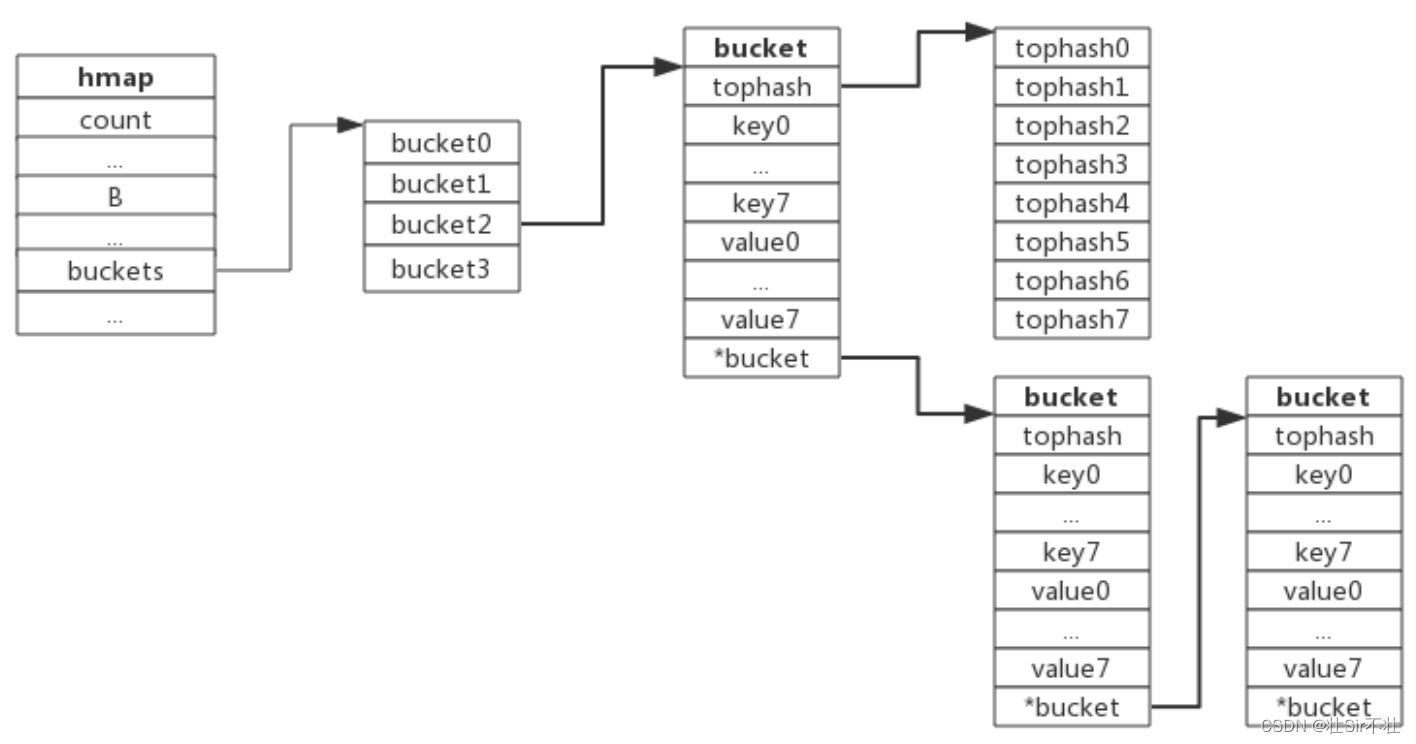
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键冲突。 由于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个键值对,用类似链表的方式将bucket连接起来。
下图展示产生冲突后的map:
链地址法(拉链法)和开放地址法:
链地址法(拉链法):
当哈希冲突发生时,创建新单元,并将新单元添加到冲突单元所在链表的尾部。
go采用拉链法来解决哈希冲突的问题,即在同一个桶内部通过链接(链表)存储所有冲突的键值对。不过拉链法在当哈希冲突出现的次数相当频繁时,会将常数级的时间复杂度上升甚至到线性级。
开放地址法:
通过尝试在哈希表中的其他位置找到空槽来解决冲突:当哈希冲突发生时,从发生冲突的那个单元起,按照一定的次序,从哈希表中寻找一个空闲的单元,然后把发生冲突的元素存入到该单元。开放寻址法有多种方式:线性探测法、平方探测法、随机探测法和双重哈希法。
- 线性探测:
- 当发生冲突时,线性探测会顺序地检查下一个位置,直到找到一个空槽或达到哈希表的末尾。
- 具体地,线性探测的探测序列为:(h(k) + i mod m),其中 h(k) 是键的哈希值,m 是哈希表的大小,i 是探测序列的步长(通常为 1)。
- 线性探测可能会导致连续的聚集现象,这可能会影响到性能。
- 二次探测:
- 二次探测通过使用二次函数来计算探测序列,而不是线性递增。
- 具体地,二次探测的探测序列为:((h(k) + c_1 * i + c_2 * i^2) mod m),其中 c_1 和 c_2 是用于控制二次探测步长的常数。
- 二次探测可能会减少连续的聚集现象,但可能会产生二次聚集现象。
- 双重散列:
- 双重散列使用两个不同的哈希函数来计算探测序列,这两个哈希函数应该是独立的。
- 具体地,双重散列的探测序列为:((h_1(k) + i * h_2(k)) mod m),其中 h_1(k) 和 h_2(k) 是两个不同的哈希函数。
- 双重散列通常能够有效地减少聚集现象,并且可以提供较好的性能。
比较:
对于链地址法,基于数组+链表进行存储,链表节点可以在需要时再创建,不必像开放寻址法那样事先申请好足够内存,因此链地址法对于内存的利用率会比开方寻址法高。链地址法对装载因子的容忍度会更高,并且适合存储大对象、大数据量的哈希表。而且相较于开放寻址法,它更加灵活,支持更多的优化策略,比如可采用红黑树代替链表。但是链地址法需要额外的空间来存储指针。
对于开放寻址法,它只有数组一种数据结构就可完成存储,继承了数组的优点,对CPU缓存友好,易于序列化操作。但是它对内存的利用率不如链地址法,且发生冲突时代价更高。当数据量明确、装载因子小,适合采用开放寻址法。
总结:
在发生哈希冲突时,Python中dict采用的开放寻址法,Java的HashMap采用的是链地址法,而Go map也采用链地址法解决冲突,具体就是插入key到map中时,当key定位的桶填满8个元素后,将会创建一个溢出桶,并且将溢出桶插入当前桶所在链表尾部。
在哈希表的使用过程中,当需要插入、查找或删除一个键值对时,首先通过哈希函数计算出键对应的数组索引,然后根据碰撞处理的方法处理可能的冲突,最终完成相应的操作。哈希表的平均时间复杂度为 O(1),在良好设计的情况下,它能够实现高效的数据存储和检索。
负载因子
负载因子用于衡量一个哈希表冲突情况,公式为:负载因子 = 键数量/bucket数量。例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1。
哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织(当Hash表中负载因子过大,需要不断申请bucket,并对所有的键值重新组织,使其均匀分布到这些bucket中,这个过程被称为rehash),注意:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存1个键值对,而Go的bucket可能存8个键值对,所以Go可以容忍更高的负载因子。
渐进式扩容
1.扩容的前提条件
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。 触发扩容的条件有两个:
- 超过负载:
map元素个数 > 6.5 * 桶个数时(负载因子 > 6.5),即平均每个bucket存储的键值对达到6.5个。
- 溢出桶太多:
当桶总数 < 2^15时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。
当桶总数 >= 2^15时,直接与2^15比较,当溢出桶总数>=2^15时,即认为溢出桶太多了。
对于条件2,其实算是对条件1的补充。因为在负载因子比较小的情况下,有可能map的查找和插入效率也很低,而第1点识别不出来这种情况。表面现象就是负载因子比较小,即 map里元素总数少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶)。比如不断的增删,这样会造成overflow的bucket数量增多,但负载因子又不高,达不到第1点的临界值,就不能触发扩容来缓解这种情况。这样会造成桶的使用率不高,值存储得比较稀疏,查找插入效率会变得非常低,因此有了第2扩容条件。
2.增量扩容
当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。 考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
下图展示了包含一个bucket满载的map(为了描述方便,图中bucket省略了value区域):

当前map存储了7个键值对,只有1个bucket。此地负载因子为7。再次插入数据时将会触发扩容操作,扩容之后再将新插入键写入新的bucket。
当第8个键值对插入时,将会触发扩容,扩容后示意图如下:
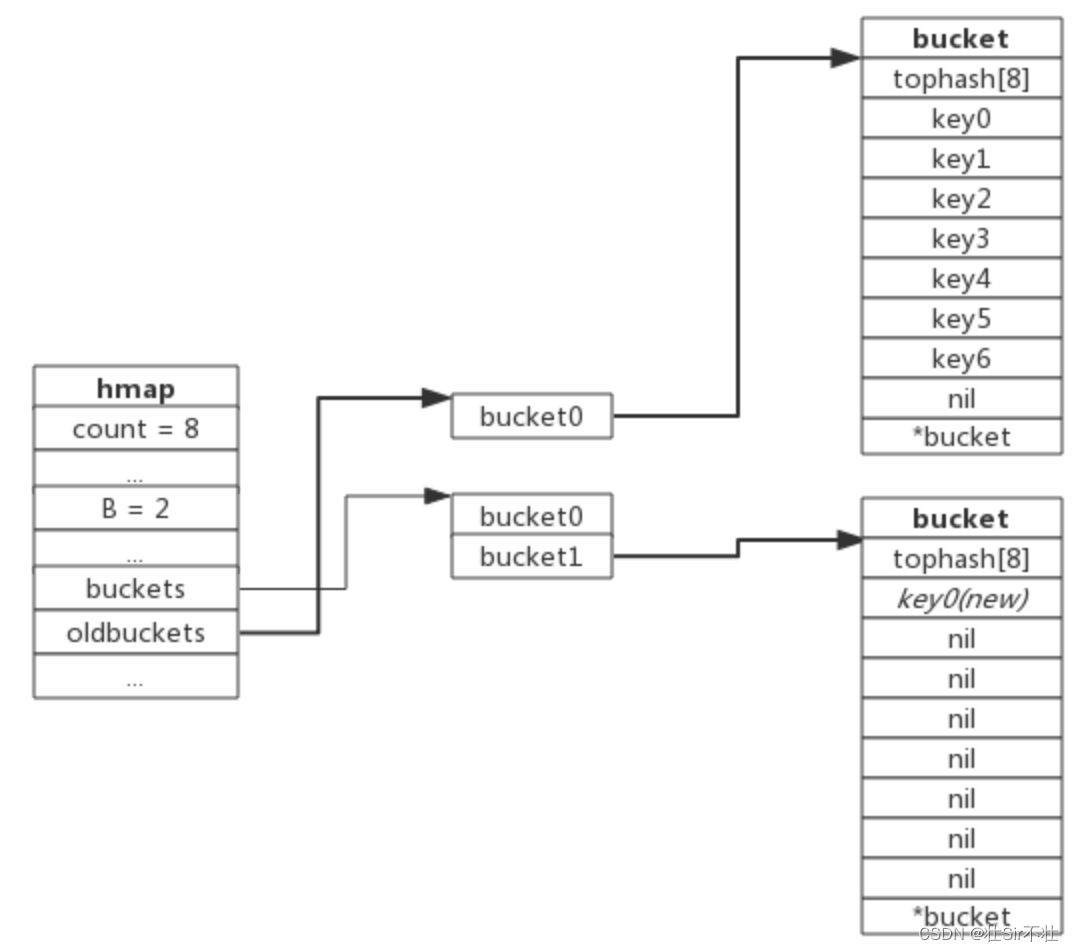
hmap数据结构中oldbuckets成员指身原bucket,而buckets指向了新申请的bucket。新的键值对被插入新的bucket中。 后续对map的访问操作会触发迁移,将oldbuckets中的键值对逐步的搬迁过来。当oldbuckets中的键值对全部搬迁完毕后,删除oldbuckets。
搬迁完成后的示意图如下:
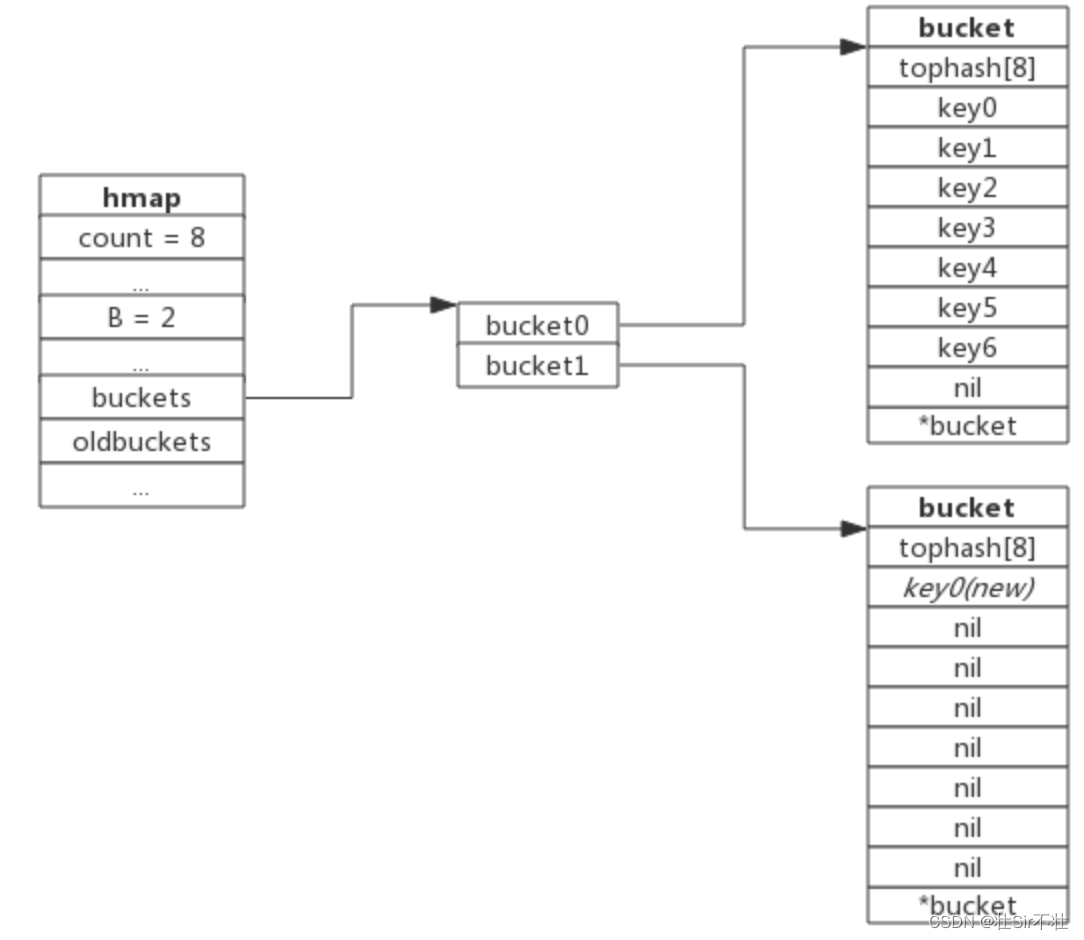
数据搬迁过程中原bucket中的键值对将存在于新bucket的前面,新插入的键值对将存在于新bucket的后面。
3.等量扩容
等量扩容,实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
在极端场景下,比如不断地增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况,如下图所示: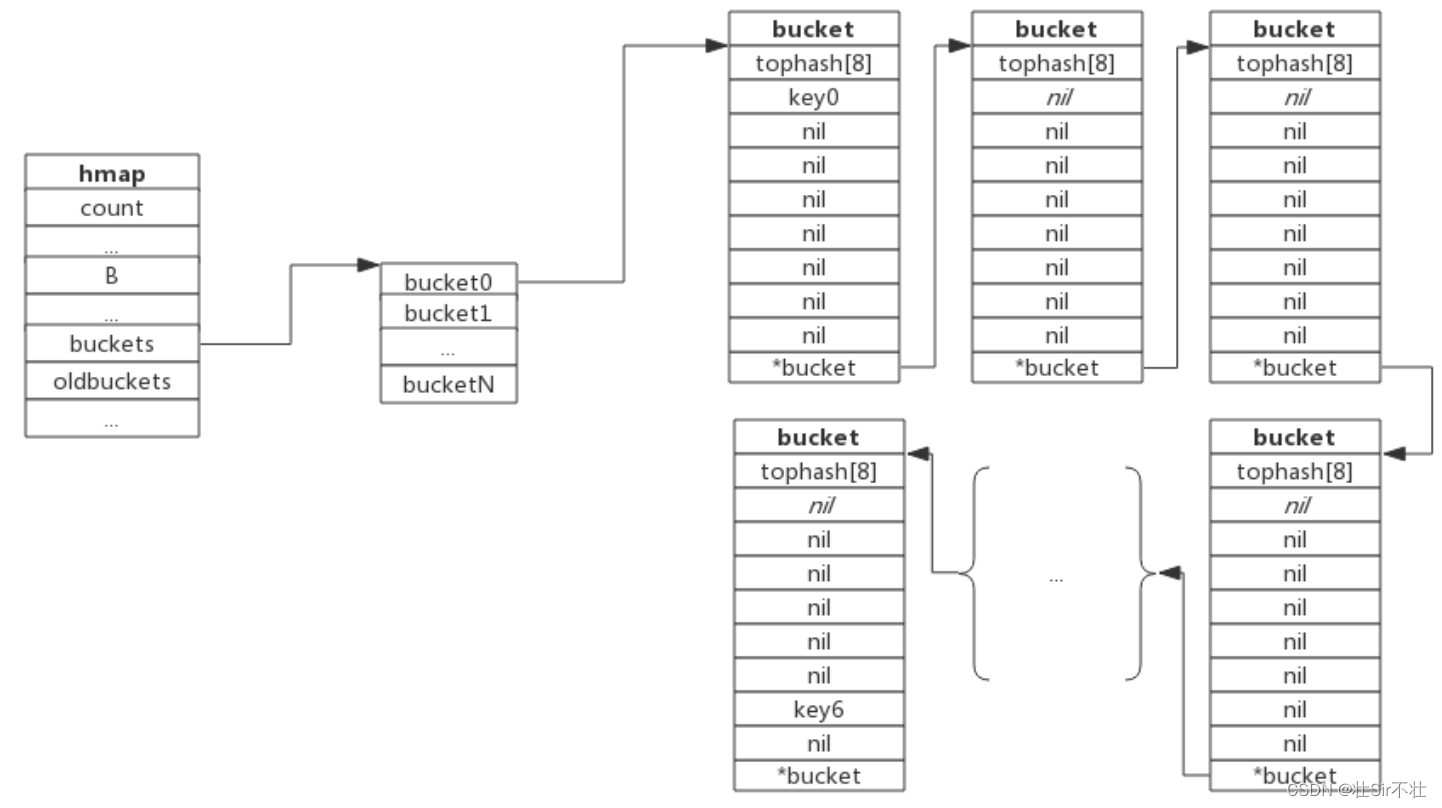
上图可见,overflow的bucket中大部分是空的,访问效率会很差。此时进行一次等量扩容,即buckets数量不变,经过重新组织后overflow的bucket数量会减少,即节省了空间又会提高访问效率。















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









