






没有太晚的开始,不如就从今天行动。总有一天,那个一点一点可见的未来,会在你心里,也在你的脚下慢慢清透。生活,从不亏待每一个努力向上的人。
----------------分割线----------------
配对堆是一种满足堆性质的多叉树。下图是一个典型的配对小根堆。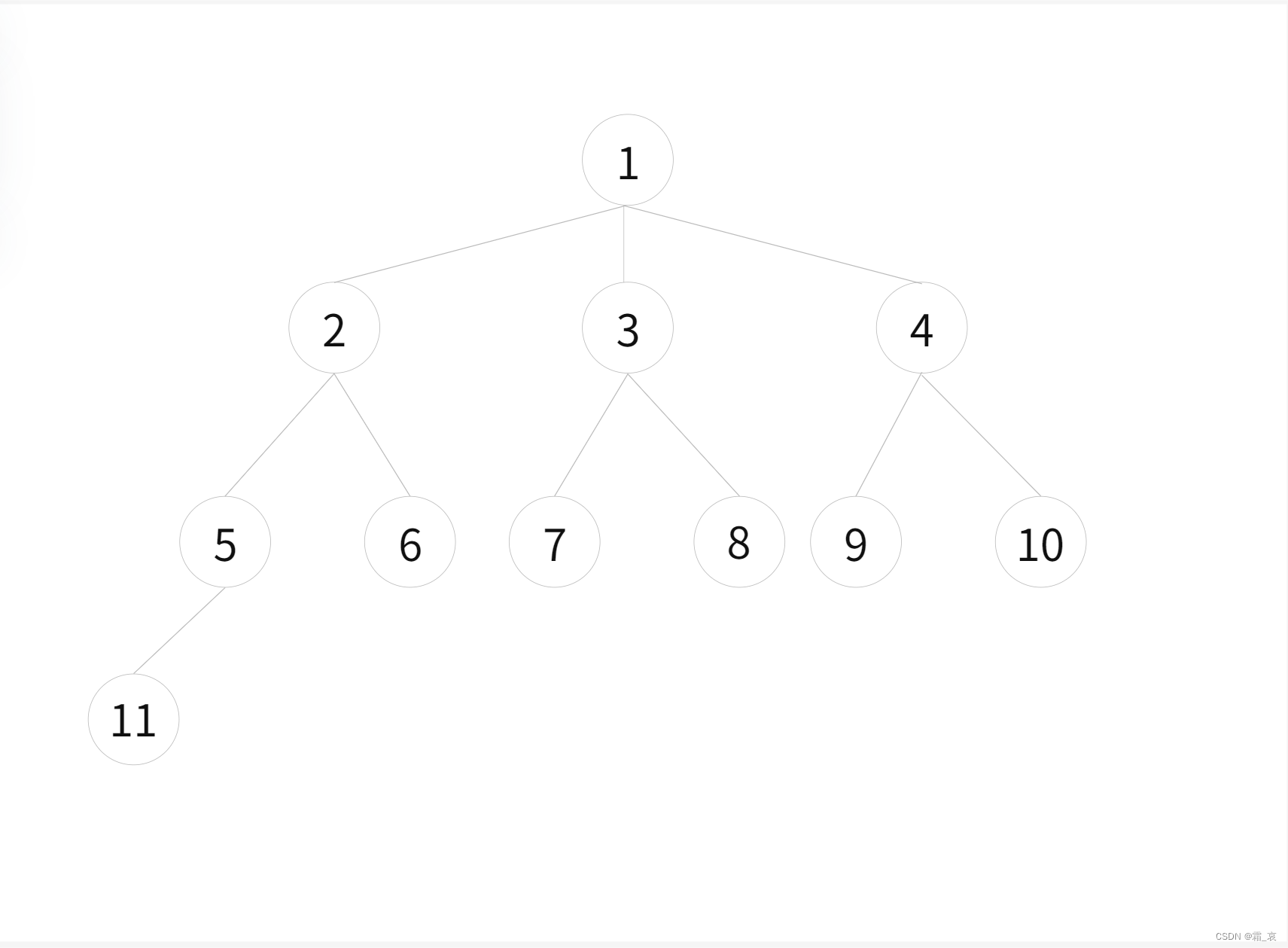
特殊地,对于配对堆,我们一般使用儿子——兄弟表示法表示一个堆。(不熟这个方法的可以去查一下,这里不多赘述)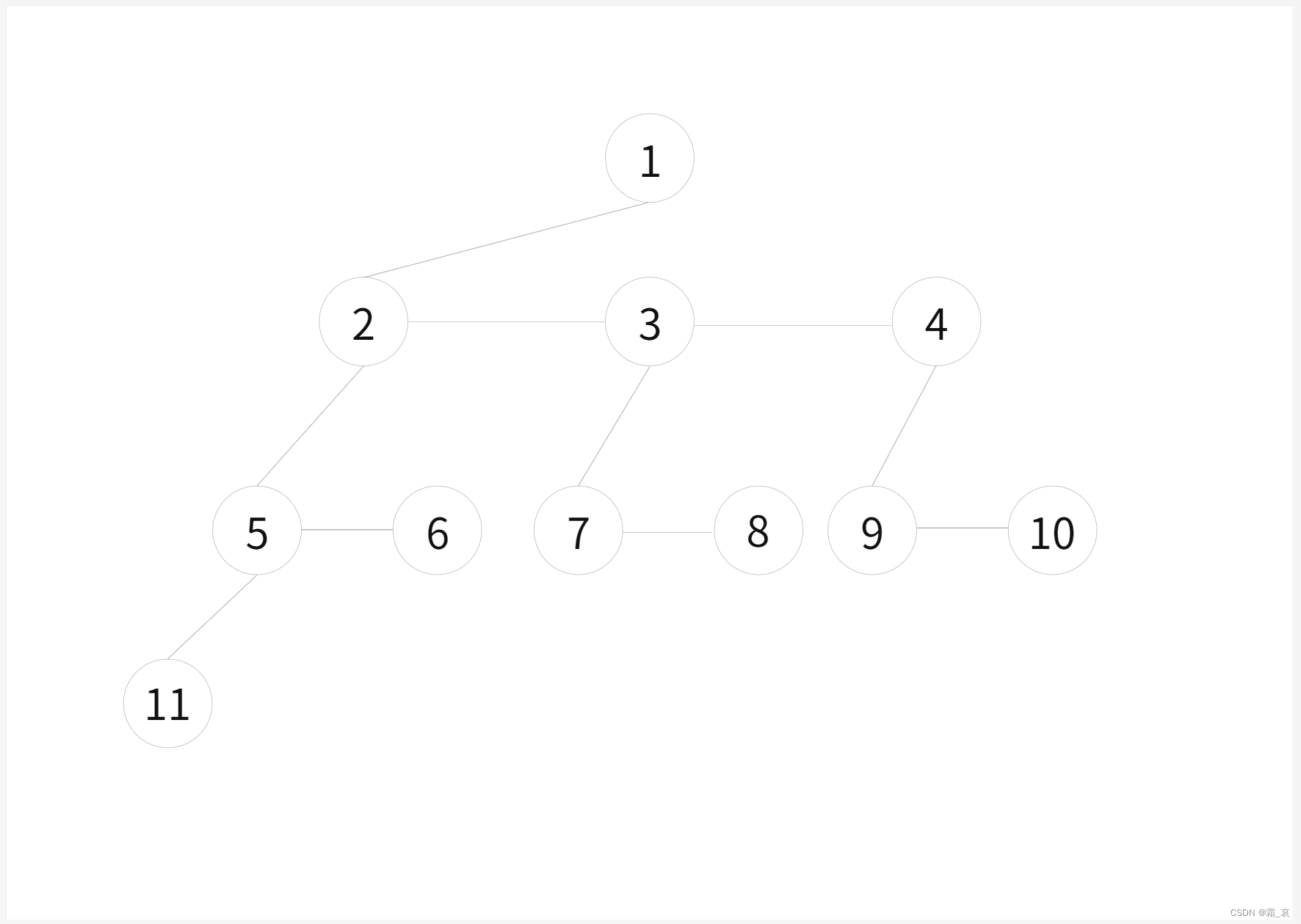
关于配对堆的算法有查询,合并,插入,删除,减小某个元素的值等。
查询
原理
依然是查询最大值/最小值,返回堆顶元素。
代码
int find(node* x) {
return x->v;
}
合并
原理
与并查集思想类似,将小的结点设为根结点,另一个结点直接作为其儿子的兄弟插到树上就可以。但要注意,新插入的树是插到儿子链表的最左边的。
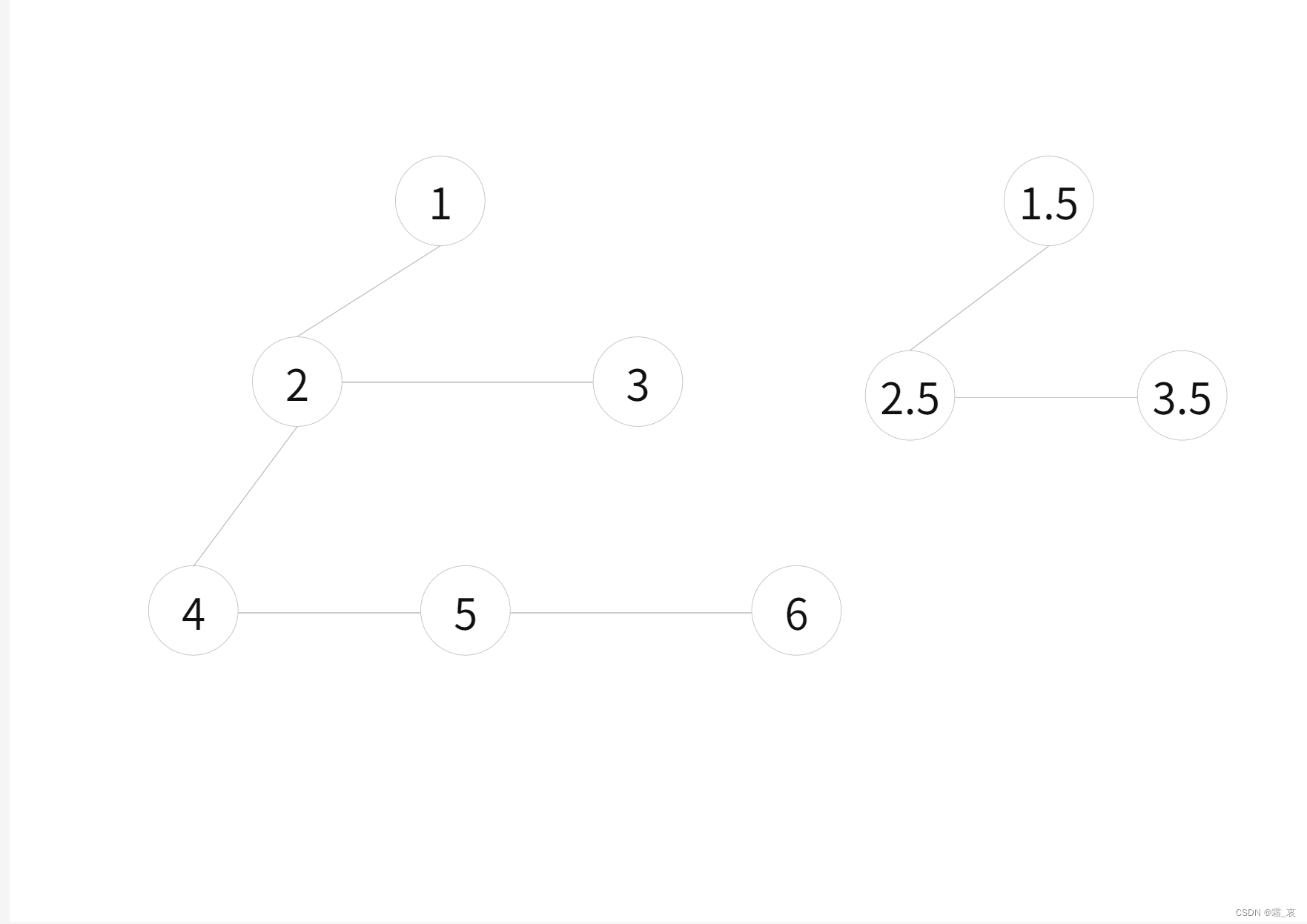
图示
- 原来的两个配对堆
- 将右边的根节点1.5插到左树的最左边(黄色的点是之前右树的点)
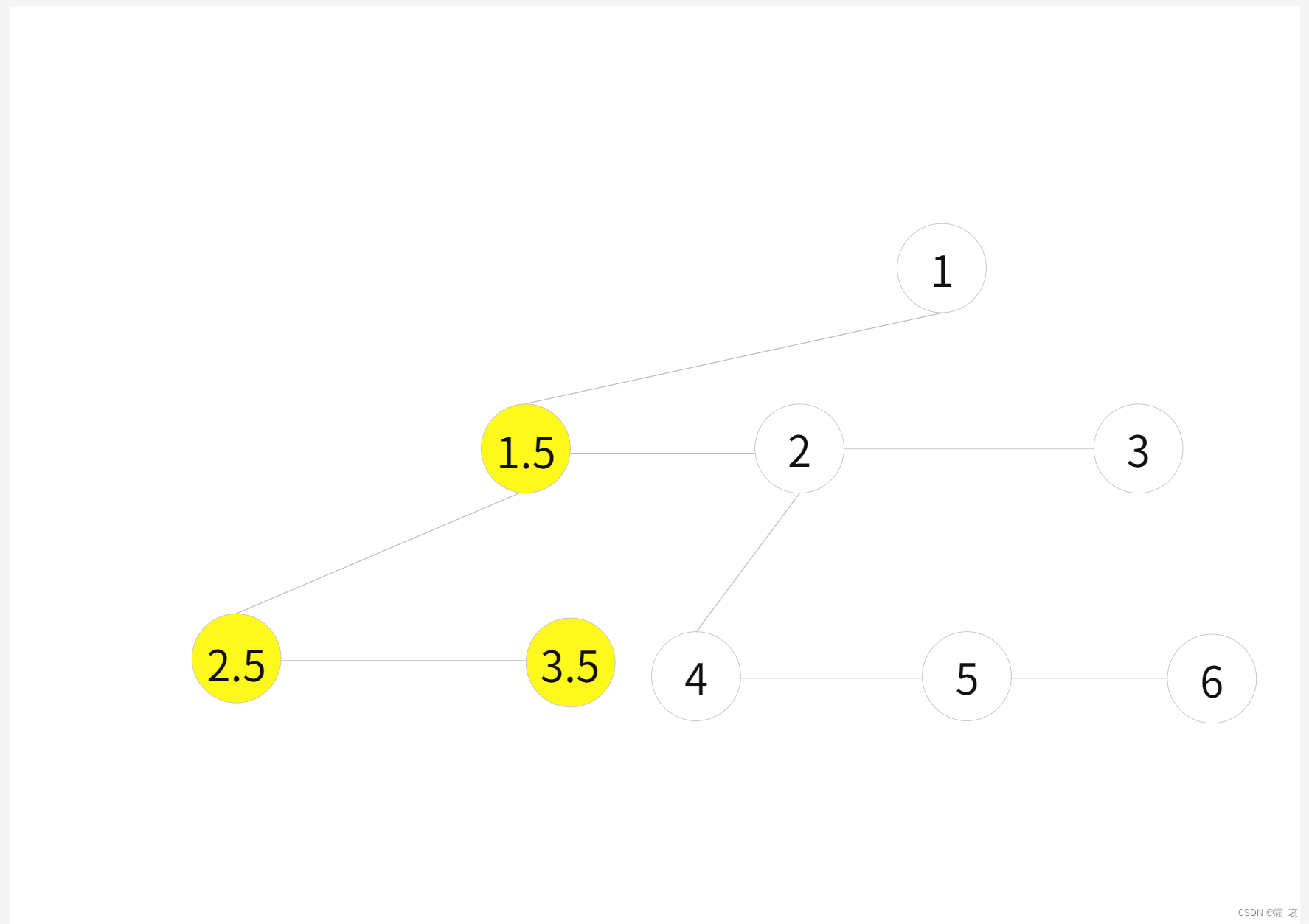
代码
node* merge(node* x, node* y)
{
if (x == NULL)return y;
if (y == NULL)return x;
if (x->v > y->v)swap(x, y);
y->sibling = x->child;
x->child = y;//这个过程会从右向左插入树
return x;
}
插入
原理
插入的本质就是将一个只有一个结点的配对堆与另一个配对堆合并。
代码
node* insert(node* x, node* y)
{
if (x->v > y->v)swap(x, y);
y->sibling = x->child;
x->child = y;//这个过程会从右向左插入树
return x;
}
删除
删除指删除堆中的最小值/最大值,即删除根结点。删除是配对堆的算法中最重要和巧妙的一个,它保证了配对堆的低时间复杂度。
原理
由于堆是个多叉树,所以删除后会变成好几棵树。但如果把这些树一个一个合并,那么时间复杂度会退化到线性。
因此,采用先将子树两两合并,然后再逐一合并的方式。
图示
- 原树
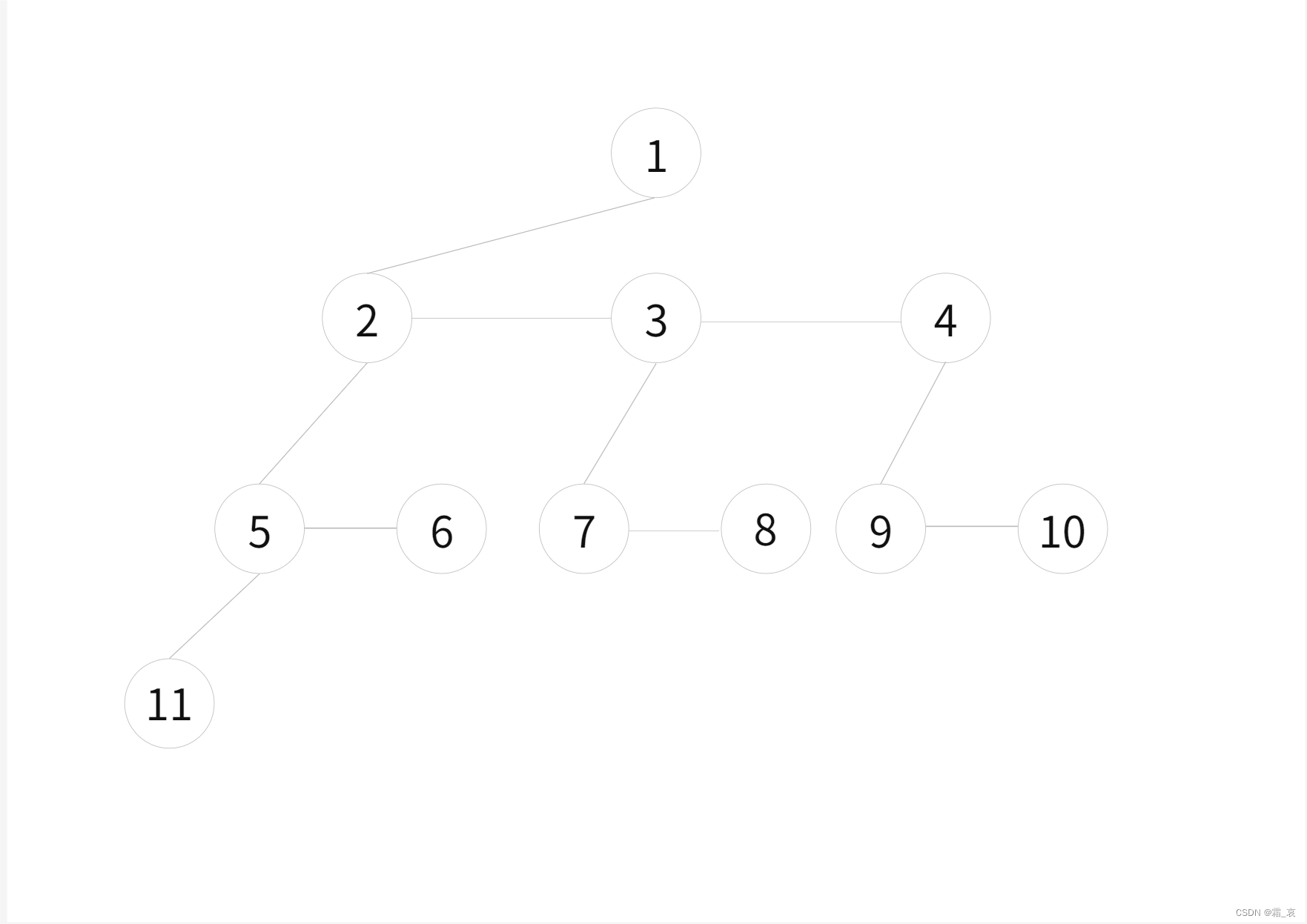
- 将根节点删除
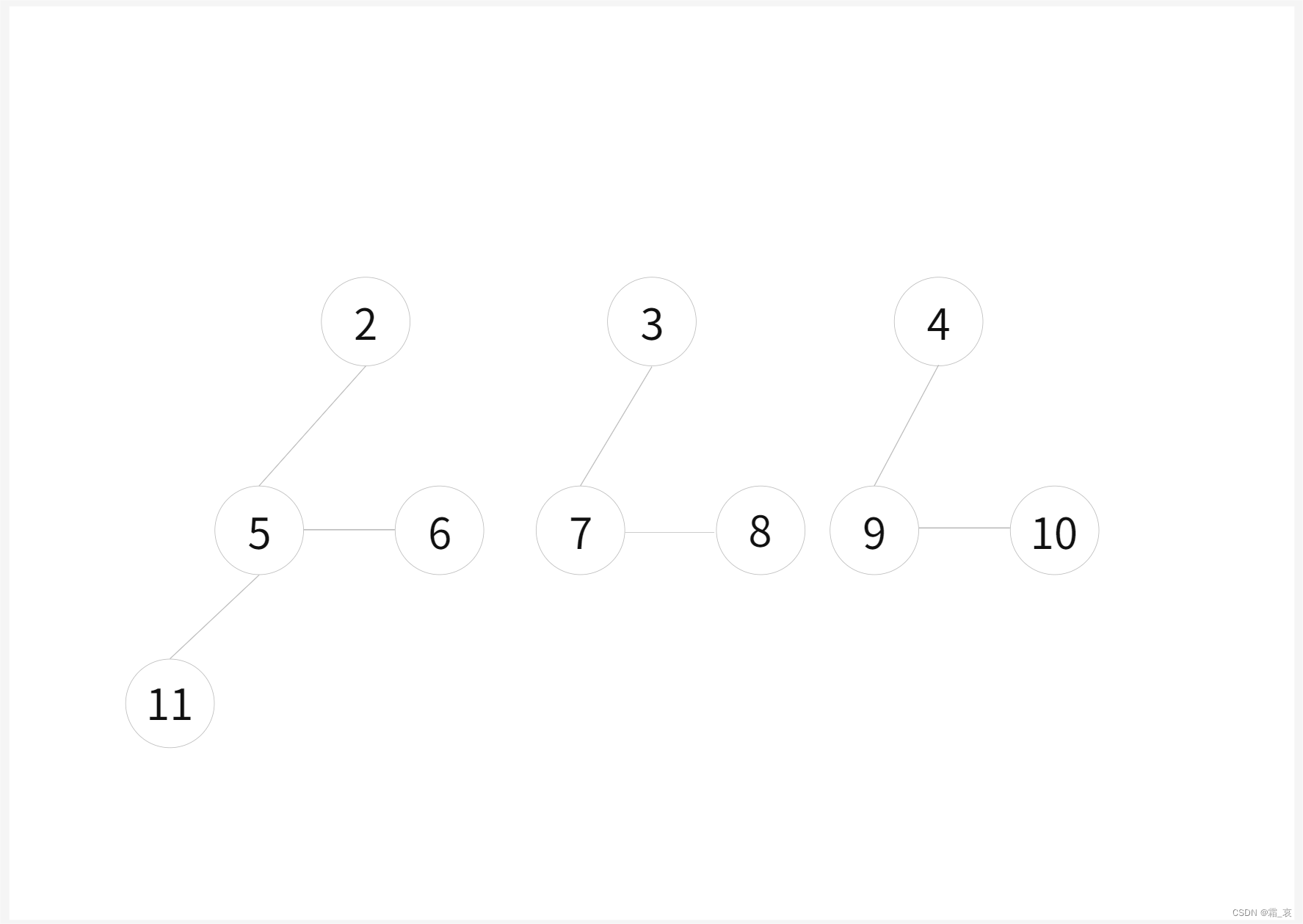
- 合并左边的两棵树(如果有右边还有树的话依然要两两合并)
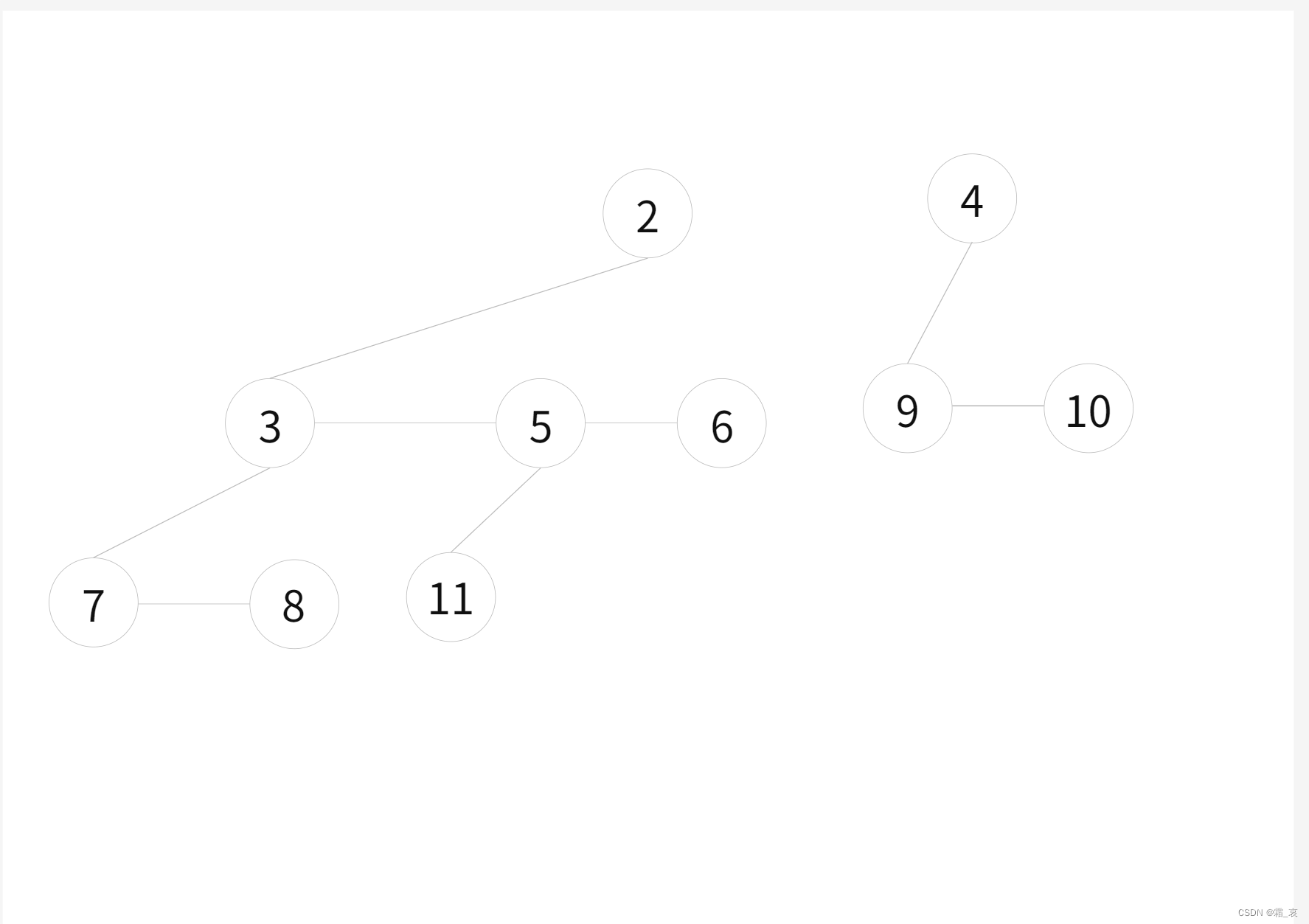
- 将合并完的树进行合并,这里只需将3图中的两棵树合并即可
代码
node* merges(node* x)
{
if (x == NULL && x->sibling == NULL)return;
node* y = x->sibling;
node* z = y->sibling;
x->sibling = y->sibling = NULL;
return merge(merges(z), merge(x, y));//这是这个函数的核心
}
node* delete_min(node* x)
{
node* y = x->child;
delete(x);
merges(y);
}
代码分析
不难看出,整个操作的核心是merges函数,merges函数的核心是最后一条语句。
我们举个例子来分析这段代码。(这里图示没有经过整理,重点看过程)
- 这是一个删除了根节点的多棵树(每一棵树用一个结点表示),其中merges函数的前几句逐步将各个结点拆散,我们这里就直接全部拆开,不再多讲

- 第一层递归的最后一条语句,将前两棵树合并,然后进入merges函数的第二层递归

- merges函数的第二层递归传入第三棵树,影响3,4,5三棵树,结果将3,4两棵树合并,并进入以5为参数的merges第三层递归…以此类推,最后只剩7一棵树无法合并时直接return

- 返回到第三层递归,执行最外层的merge函数,将最后两棵树合并
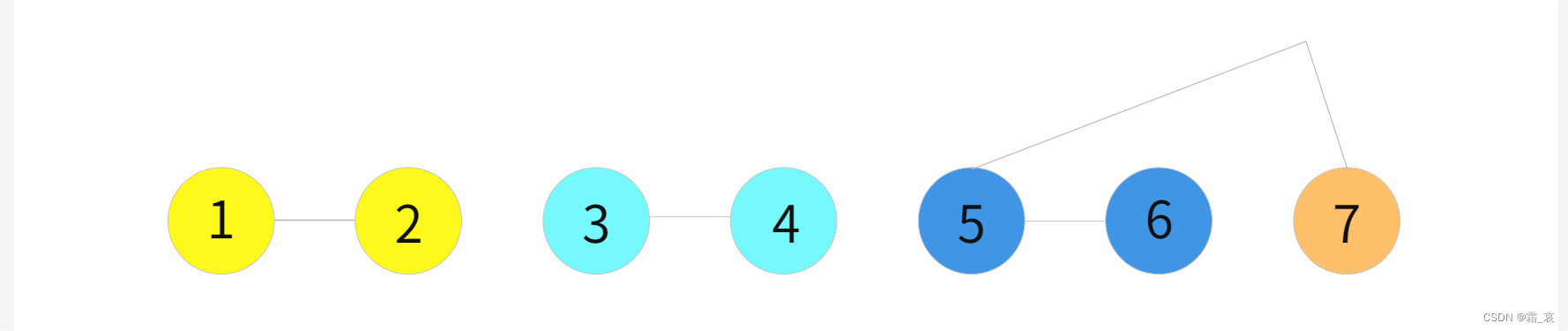
- 然后返回第二层递归,再将最后两棵树合并…以此类推,直到所有树都合并完成为止
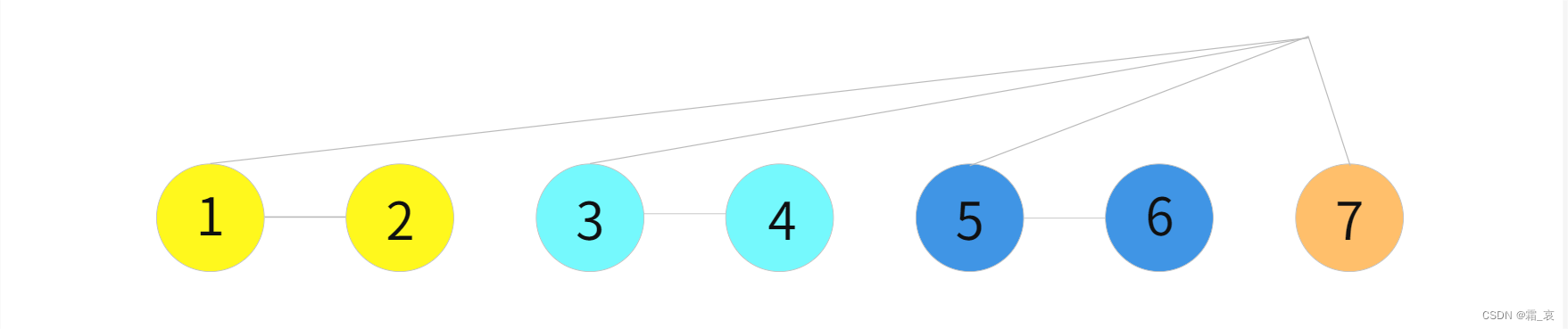
在第二个函数中,我们可以看到一开始传入的参数是未删除树的根节点的第一个儿子,即上图的1树,这也说明了这个函数的正确性。
减小某个元素的值
原理
对于小根堆来说,减小一个元素的值不会影响以它为根节点的树的堆性质,但会影响它和它的父亲的性质
。因此要新增一个指向它父亲的指针(这里的父亲指的是指向它的结点,即它的兄弟结点或父结点)
注意:新增父指针后前面的所有算法都需要维护父指针。
这样,我们可以把以减小的元素为根节点的子树从整个树中剖出,然后再重新合并来完成。
代码
node* decrease_node(node* root, node* x, int v)
{
x->v = v;
if (x == root)return x;
//运用链表的思想,将以x为根节点的树从整个树中剖出去
if (x->father->child == x)x->father->child = x->sibling;
else {
if (x->father->sibling == x)x->father->sibling = x->sibling;
}
if (x->sibling != NULL)x->sibling->father = x->father;//要记得维护x右兄弟的父指针
x->father = NULL;
x->sibling = NULL;
//将两个树重新合并
return merge(root, x);
}
总结
配对堆是一种低时间复杂度的数据结构,其最重要的算法是删除操作。
配对堆的算法到这里就差不多结束啦,祝各位天天开心,前程似锦(据说点赞的人心想事成哦)

















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











