







前言
拓扑排序(Topological Sorting)是一种解决有向无环图(DAG)的线性序列问题方法。它将DAG中的所有节点排序,使得对于任意一条有向边(u,v),起点u所在的位置在终点v在排序后的节点序列中的位置之前。
拓扑排序可以用来判断一个有向图是否存在环,若存在,则无法进行拓扑排序,即图中无法排序。拓扑排序的应用很广,比如任务调度,将一些任务按照它们之间的依赖关系排列,使得先完成的任务不依赖还未完成的任务等等。
拓扑排序也是求关键路径的算法的基础。
一些基本概念
- 无环的有向图称作有向无环图(Directed Acycline Graph),简称DAG图。
- 用顶点表示活动,用弧表示活动间的优先关系的有向图称为以顶点表示活动的网(Activity On Vertex Network),简称AOV-网。
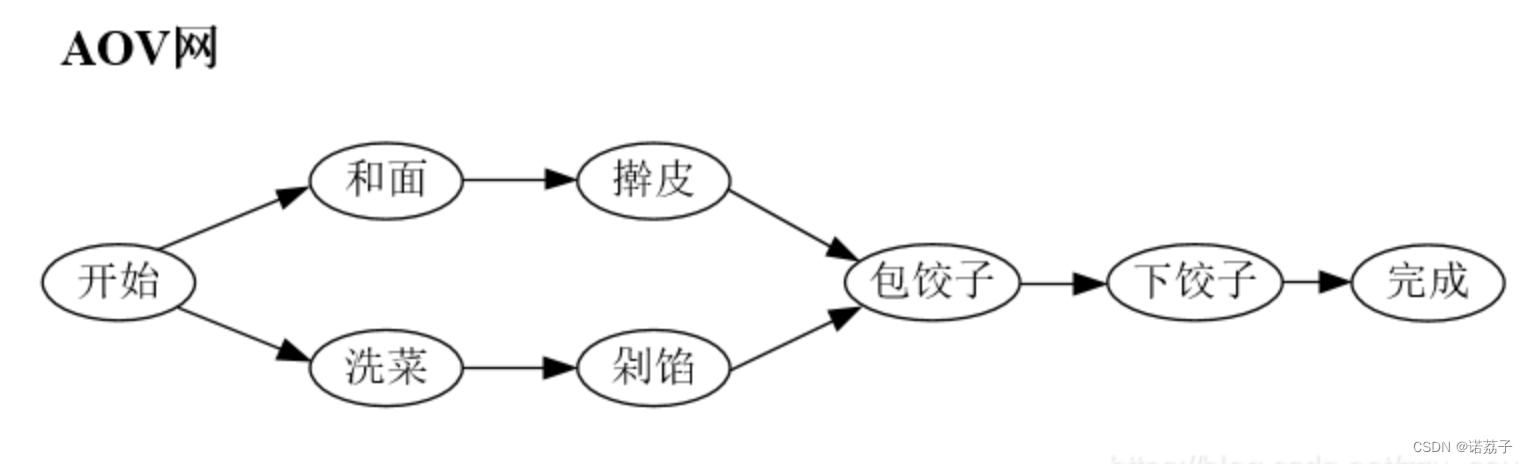
在AOV-网中,不应该出现有向环 ,因为存在环意味着某项活动开始的条件为自己已完成,这是矛盾的。
拓扑排序过程

视频------------------------------------------------------------->
拓扑排序
拓扑排序的实现
拓扑排序具体实现可以使用两种算法:Kahn算法和深度优先搜索(DFS)算法。其中Kahn算法比较好理解和实现,而DFS算法更适合某些特殊情况下的场景,比如需要找到一个正确的拓扑序列或某个特定的顺序等。
以下为以邻接表为储存结构的有向图进行拓扑排序。
Kahn算法
Khan算法又称为“拓扑排序算法”,其主要思想是通过不断地去除入度为0的节点,并更新与之相邻接点的入度值,从而逐步构建出拓扑排序序列。这样进行下去,直到最后所有的节点都被处理完毕或不存在入度为0的节点时,就可以得到一个拓扑序列。
基本流程:
1.求各顶点的入度并存入数组indegree中。
2.使入度为0的顶点入栈。
3.当栈非空时重复以下操作:
- 顶点v出栈并输出,记录输出顶点数count加1。
- 顶点v的邻接点入度减1,若邻接点入度变为0,则邻接点入栈。
4.若count小于总顶点数,则网中存在环,拓扑排序失败,否则成功。
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define MVNUM 100
typedef struct ArcNode {
int adjvex;
struct ArcNode* next;
}ArcNode;
typedef struct VNode {
char data;
ArcNode* firstarc;
}VNode, AdjList[MVNUM];
typedef struct {
AdjList vertices;
int vexnum, arcnum;
}ALGraph;
//定位
int LocateVex(ALGraph* G, char v) {
int i;
for (i = 0; i < G->vexnum; i++) {
if (G->vertices[i].data == v) {
return i;
}
}
return -1;
}
//有向图邻接表的建立
ALGraph* CreateGraph() {
int i, j, k, v1, v2;
ALGraph* G = malloc(sizeof(ALGraph));
printf("输入顶点数和边数:\n");
scanf("%d%d", &G->vexnum, &G->arcnum);
getchar();
printf("输入顶点信息:\n");
for (i = 0; i < G->vexnum; i++) {
scanf("%c", &G->vertices[i].data);
G->vertices[i].firstarc = NULL;
}
getchar();
for (k = 0; k < G->arcnum; k++) {
printf("输入一条弧依附的起点和终点:\n");
scanf("%c%c", &v1, &v2);
getchar();
i = LocateVex(G, v1), j = LocateVex(G, v2);
ArcNode* p = malloc(sizeof(ArcNode));
p->adjvex = j;
p->next = G->vertices[i].firstarc;
G->vertices[i].firstarc = p;
}
return G;
}
//输出邻接表
void print(ALGraph* G) {
int i;
ArcNode* p = NULL;
for (i = 0; i < G->vexnum; i++) {
printf("%c", G->vertices[i].data);
p = G->vertices[i].firstarc;
while (p) {
printf("-->%c", G->vertices[p->adjvex].data);
p = p->next;
}
printf("\n");
}
}
//Kahn算法实现拓扑排序
bool TopoSort(ALGraph* G) {
int indegree[MVNUM] = { 0 };//记录顶点入度
int i, j, v;
int count = 0;//记录输出的顶点数
int stack[MVNUM];//定义一个简单的数组栈
int top = 0;//栈顶指针
ArcNode* p = NULL;
//统计各顶点入度
for (i = 0; i < G->vexnum; i++) {
p = G->vertices[i].firstarc;
while (p != NULL) {
indegree[p->adjvex]++;
p = p->next;
}
}
//将所有入度为0的顶点入队
for (i = 0; i < G->vexnum; i++) {
if (indegree[i] == 0) {
stack[top++] = i;
}
}
//栈非空时循环
while (top > 0) {
v = stack[--top];//出栈一个顶点
printf("%c ", G->vertices[v].data);
count++;//已输出的顶点数加1
//遍历该顶点为起点的所有边
p = G->vertices[v].firstarc;
while (p != NULL) {
indegree[p->adjvex]--;//入度减1
//若入度为0,入队
if (indegree[p->adjvex] == 0) {
stack[top++] = p->adjvex;
}
p = p->next;//指向下一条边
}
}
//输出顶点数小于总顶点数,说明有环
if (count < G->vexnum) {
printf("该图有环,拓扑排序失败。\n");
return false;
}
return true;
}
int main() {
ALGraph* G = CreateGraph();
printf("邻接表:\n");
print(G);
printf("拓扑排序序列:\n");
TopoSort(G);
return 0;
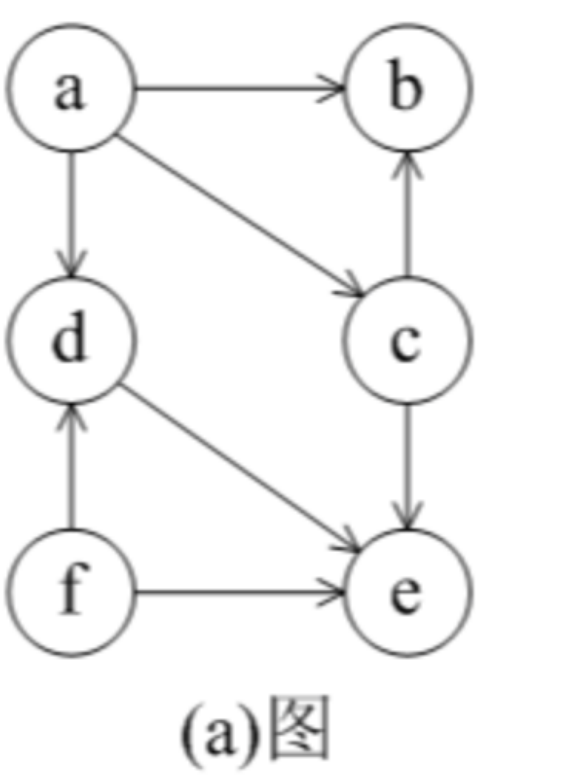
}运行代码求下图中的拓扑排序序列:
运行结果如下:

拓扑排序序列并不一定是唯一的,当我们把栈换为队列时,输出序列可能会不同。
深度优先搜索(DFS)算法
基本流程:
- 首先定义一个visited数组和一个sorted数组,visited数组用于记录每个顶点是否已经访问过,sorted数组用于存储已经排序好的顶点序列。
- 对于任意一个未被访问过的顶点v,调用dfs(v)函数进行深度优先搜索。
- 在dfs(v)函数中,首先将当前顶点v标记为已访问过,并遍历v的所有出边指向的邻接顶点w。
- 如果邻接顶点w没有被访问过,则递归调用dfs(w)函数,继续深度优先搜索。
- 当所有相邻顶点都被访问过后,将当前顶点v添加到已排序好的序列中。
- 重复步骤2-5,直到所有的顶点都被访问过。
- 最后输出已经排序好的顶点序列即可完成拓扑排序。
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define MVNUM 100
typedef struct ArcNode {
int adjvex;
struct ArcNode* next;
}ArcNode;
typedef struct VNode {
char data;
ArcNode* firstarc;
}VNode, AdjList[MVNUM];
typedef struct {
AdjList vertices;
int vexnum, arcnum;
}ALGraph;
//定位
int LocateVex(ALGraph* G, char v) {
int i;
for (i = 0; i < G->vexnum; i++) {
if (G->vertices[i].data == v) {
return i;
}
}
return -1;
}
//有向图邻接表的建立
ALGraph* CreateGraph() {
int i, j, k, v1, v2;
ALGraph* G = malloc(sizeof(ALGraph));
printf("输入顶点数和边数:\n");
scanf("%d%d", &G->vexnum, &G->arcnum);
getchar();
printf("输入顶点信息:\n");
for (i = 0; i < G->vexnum; i++) {
scanf("%c", &G->vertices[i].data);
G->vertices[i].firstarc = NULL;
}
getchar();
for (k = 0; k < G->arcnum; k++) {
printf("输入一条弧依附的起点和终点:\n");
scanf("%c%c", &v1, &v2);
getchar();
i = LocateVex(G, v1), j = LocateVex(G, v2);
ArcNode* p = malloc(sizeof(ArcNode));
p->adjvex = j;
p->next = G->vertices[i].firstarc;
G->vertices[i].firstarc = p;
}
return G;
}
//输出邻接表
void print(ALGraph* G) {
int i;
ArcNode* p = NULL;
for (i = 0; i < G->vexnum; i++) {
printf("%c", G->vertices[i].data);
p = G->vertices[i].firstarc;
while (p) {
printf("-->%c", G->vertices[p->adjvex].data);
p = p->next;
}
printf("\n");
}
}
//DFS算法实现拓扑排序
int visited[MVNUM] = { 0 };//记录顶点是否被访问
int sorted[MVNUM];//储存已排好序的额顶点序列
int index = 0;//已排好序的顶点序列的下标
void DFS(ALGraph* G, int i) {
visited[i] = 1;//标记顶点为已访问
//遍历所有vi的邻接点
ArcNode* p = G->vertices[i].firstarc;
while (p != NULL) {
//若邻接点为被访问,递归访问邻接点
if (!visited[p->adjvex]) {
DFS(G, p->adjvex, visited);
}
p = p->next;
}
sorted[index++] = i;//将已访问顶点加入排好的序列
}
void TopoSort(ALGraph* G) {
int i;
//对每个未被访问的顶点进行DFS
for (i = 0; i < G->vexnum; i++) {
if (!visited[i]) {
DFS(G, i);
}
}
//输出拓扑排序序列,注意sorted的序列是反的,要倒着输出
for (i = index - 1; i >= 0; i--) {
printf("%c ", G->vertices[sorted[i]].data);
}
}
int main() {
ALGraph* G = CreateGraph();
printf("邻接表:\n");
print(G);
printf("拓扑排序序列:\n");
TopoSort(G, visited);
return 0;
}运行代码求下图的拓扑排序序列:
运行结果如下:

总结
Kahn算法和DFS算法都可以实现拓扑排序,二者均对顶点进行入度计数,但他们的实现方式不同,各有特点。Kahn算法使用栈或队列进行操作,实现过程简单且极易理解;而DFS算法则更加优美,同时也使用了栈的思想。然而,当面对大规模数据时,Kahn算法通常会更快一些。总之,两种算法都是在时间复杂度 (n为顶点数,e为边数)的情况下解决任务调度问题、编译依赖等问题的简单有效方法。

















 2675
2675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











