







前言:希尔排序就是对插入排序的一种优化方法吧!
目录
我第一次听到希尔排序这个名字的时候,哇塞,好高大上的样子。这就有点像高中数学,或者高数学的洛必达法则嘛(据说洛必达法则是洛必达花钱买来的嘛,我想表达啥意思,你自己拿捏哈。)希尔排序并没有想我想象的那么NB(哈哈,只是相对来说哈,这些排序算法是我发明不出来的),他就是对插入排序的优化。
希尔排序的思想
把待排序列分为多个组,然后再对每一组进行插入排序,从而让整个序列有一定的顺序,让后多次调整分组方式,使得序列进一步有序起来,最终达到排序的效果。
咱就得好好谈一谈这个希尔排序的分组问题,所谓分组,就是如何选取每组排序元素之间的间隔,只要按照一定的算法,使得最后一次排序时每组数据之间的间隔为零就行了。可能这样不好理解,咱看个示意图
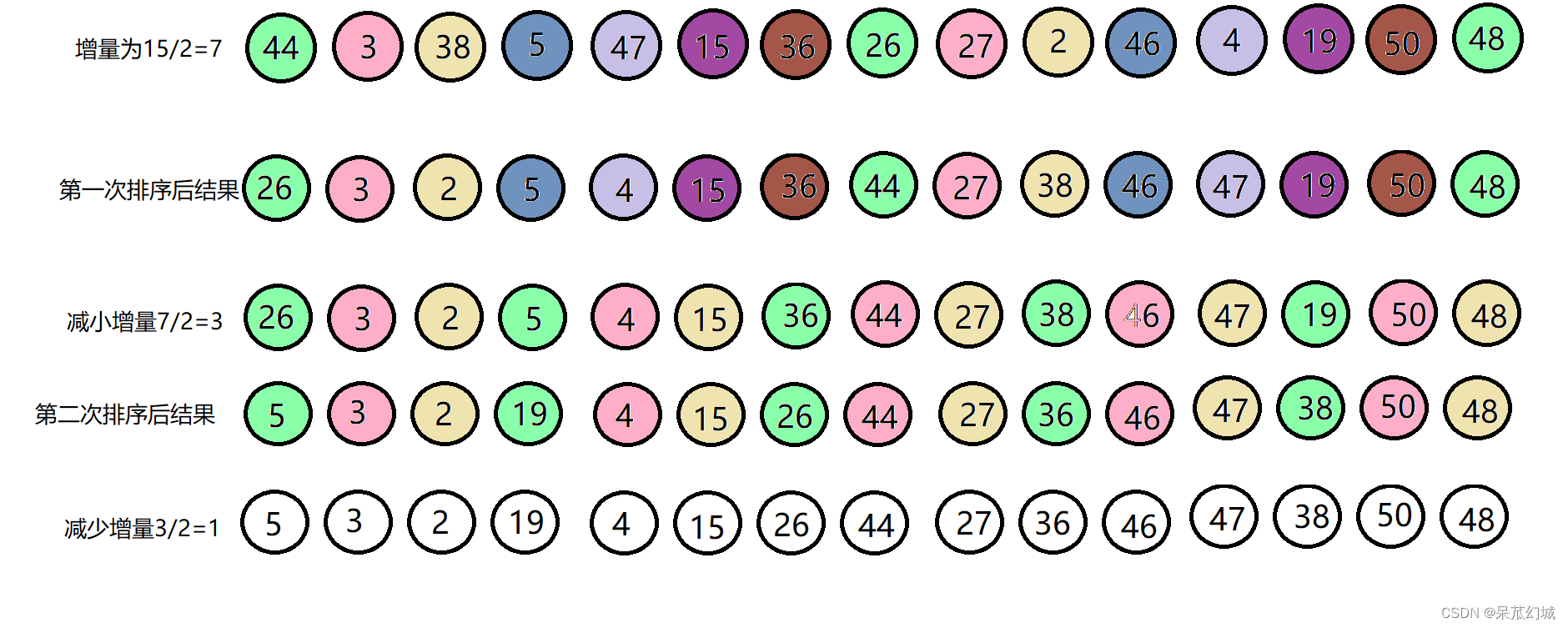
通过每组数据的排序和增量的减少达到排序的目的。如上图第一次增量为7(至于为什么是元素个数除以2得到增量,这个只是其中的一种算法,你只要保证最后的增量为1即可),我们就以7为步长,即中间隔6个元素,选取数组元素分为一组,然后对每一组进行插入排序(颜色相同的即为每一组)。排序完成后减少步长(增量)进行第二次排序,直到步长(增量)为1后进行最后一次排序,最终达到排序效果。这就是希尔排序的精髓所在吧。因为希尔排序是通过缩小增量达到排序的效果,所以希尔排序也叫做缩小增量排序。
代码分析
1. 希尔排序就是在插入排序之上套了几层循环,所以你肯定得先会插入排序。
i 就代表步长啦(没做到见名知义,抱歉啦),外层循环控制整体的排序次数,即增量减为1需要经历几次排序。内层循环控制每组的插入排序,步长(增量)为7,就有7组数据嘛。
//参数一:数组首元素地址,参数2:数组长度
void shell_sort(int* arr, int length)
{
int i = 0;
int j = 0;
int flag = 0;
//排序次数
for (i = length / 2; i > 0; i = i / 2)
{
//每组进行插入排序
for (j = 0; j < i; j++)
{
insert_sort(arr, length, j, i);
}
}
}2. 每组的插入排序:与原来的插入排序不同咱需要四个参数:参数1:数组首元素地址,参数2:数组长度,参数3:每组数据开始的下标,参数4:步长。因为每个元素中间隔了步长-1个元素
所以循环的增量就是步长,要交换元素的下标也要加上步长,如果插入排序不懂,可以看看我前面写的内容。
//参数1:数组首元素地址,参数2:数组长度,参数3:每组数据开始的下标,参数4:步长
void insert_sort(int* arr, int length, int begin, int step)
{
int i, j, k, m, l;
int flag = 0;
//比较的次数
for (i = begin + step; i < length; i += step)
{
flag = arr[i];
//每个元素的排序
for (j = i - step; j >= 0; j-=step)
{
//不比前面的元素大停止循环
if (arr[j] <= flag)
break;
//移位
arr[j + step] = arr[j];
}
//插入
arr[j + step] = flag;
}
}完整代码
#include<stdio.h>
int main()
{
int arr[15] = { 3,44,38,5,47,15,36,26,27,2,46,4,19,50,48 };
int i = 0;
int j = 0;
int media;
for (j = 1; j < 15; j++)
{
media = arr[j];
for (i = j - 1; i >= 0; i--)
{
if (arr[i] <= media)
break;
arr[i + 1] = arr[i];
}
arr[i + 1] = media;
}
//打印数据
int m = 0;
for (m = 0; m < 15; m++)
{
printf("%d ", arr[m]);
}
return 0;
}
//参数1:数组首元素地址,参数2:数组长度,参数3:每组数据开始的下标,参数4:步长
void insert_sort(int* arr, int length, int begin, int step)
{
int i, j, k, m, l;
int flag = 0;
//比较的次数
for (i = begin + step; i < length; i += step)
{
flag = arr[i];
//每个元素的排序
for (j = i - step; j >= 0; j-=step)
{
//不比前面的元素大停止循环
if (arr[j] <= flag)
break;
//移位
arr[j + step] = arr[j];
}
//插入
arr[j + step] = flag;
}
}
//参数一:数组首元素地址,参数2:数组长度
void shell_sort(int* arr, int length)
{
int i = 0;
int j = 0;
int flag = 0;
//排序次数
for (i = length / 2; i > 0; i = i / 2)
{
//每组进行插入排序
for (j = 0; j < i; j++)
{
insert_sort(arr, length, j, i);
}
}
}
int main()
{
int arr[15] = { 3,44,38,5,47,15,36,26,27,2,46,4,19,50,48 };
int length = sizeof(arr) / sizeof(arr[0]);
shell_sort(arr, length);
//打印数组元素
int m = 0;
for (m = 0; m < length; m++)
{
printf("%d ", arr[m]);
}
return 0;
}好啦,希尔排序就到这里,拜拜!
















 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











