







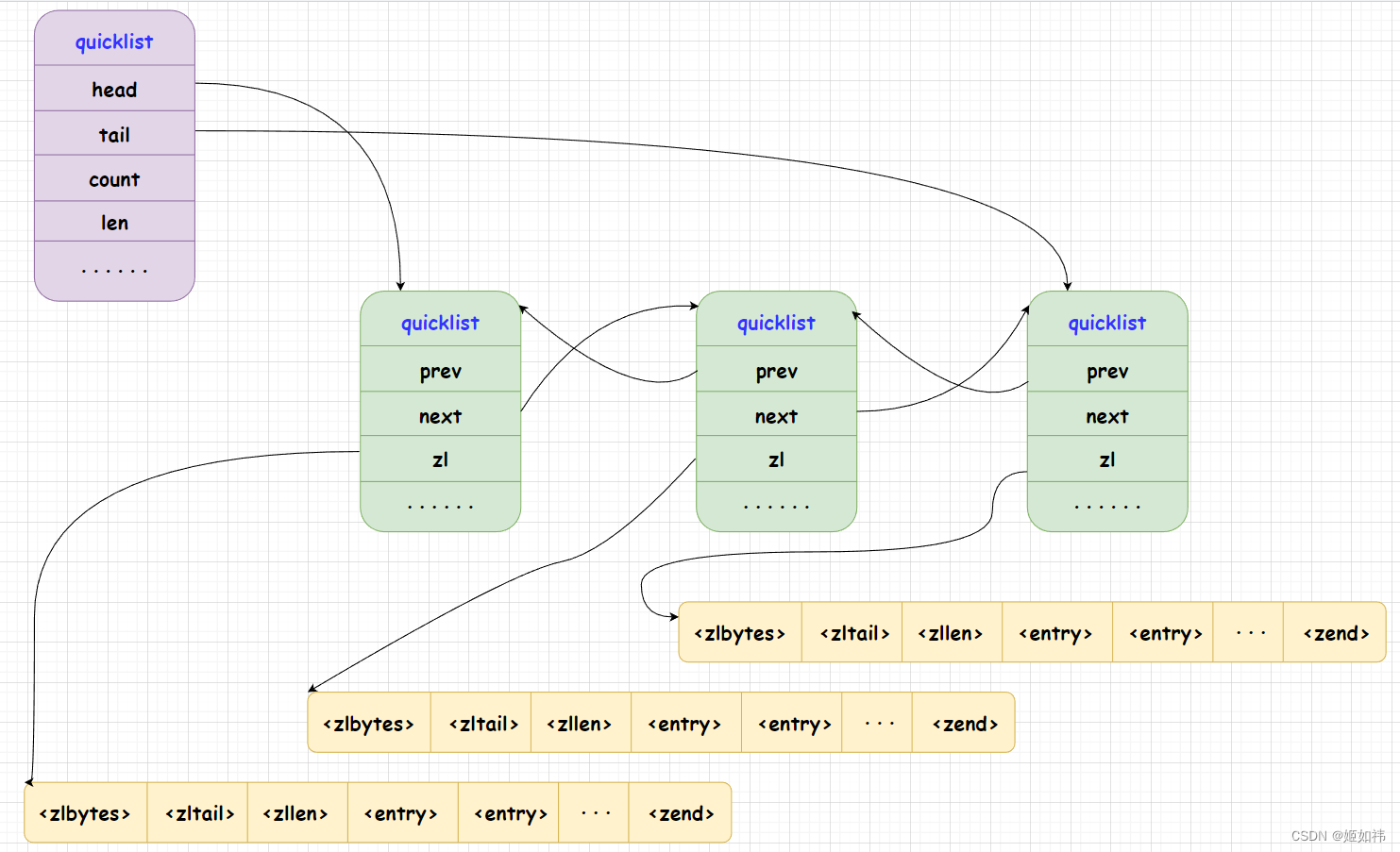
quicklist
Redis 源码版本:Redis-6.0.9,本篇文章的代码均在
quicklist.h / quicklist.c文件中。
quicklist 的设计思想很简单,将一个长的 ziplist 拆分为多个短 ziplist,避免插入或删除元素时导致大量的内存拷贝。
ziplist 存储数据的形式更类似于数组,而 quicklist 是真正意义上的链表结构,它由 quicklistNode 节点链接而成,在 quicklistNode 中使用 ziplist 存储数据。
定义
typedef struct quicklistNode {
struct quicklistNode *prev; // 前驱节点
struct quicklistNode *next; // 后继节点
unsigned char *zl; // ziplist, 负责存储数据
unsigned int sz; // ziplist 占用的字节数
unsigned int count : 16; // ziplist 的元素数量
unsigned int encoding : 2; // 编码方式,RAW == 1 表示没有压缩,LZF == 2 表示已压缩
unsigned int container : 2; // 目前固定为 2 代表使用 ziplist 存储数据
unsigned int recompress : 1; // 1 代表暂时解压 (用于读取数据等),后续需要时再将其压缩
unsigned int attempted_compress : 1; // 表示是否尝试过压缩该节点的数据,1 表示该节点的数据大小太小,无法进行压缩。
unsigned int extra : 10; // 预留属性,暂未使用
} quicklistNode;
当链表很长时,中间节点数据访问频率较低。这时,Redis 会将中间节点数据进行压缩,进一步节省内存空间。Redis 采用的是无损压缩算法 —— LZF 算法。
压缩后节点定义如下:
typedef struct quicklistLZF {
unsigned int sz; // 压缩最后的 ziplist 大小
char compressed[]; // 存放压缩后的 ziplist 字节数组
} quicklistLZF;
quicklist 的定义如下:
typedef struct quicklist {
quicklistNode *head; // 指向头结点
quicklistNode *tail; // 指向尾节点
unsigned long count; // 所有节点的 ziplist 的元素数量总和
unsigned long len; // 节点的数量
int fill : QL_FILL_BITS; // 16 bit,用于判断节点 ziplist 是否已满
unsigned int compress : QL_COMP_BITS; // 16bit,存放压缩节点的配置
unsigned int bookmark_count: QL_BM_BITS; // 表示 quicklist 的书签数量,用于快速定位到某个位置。
quicklistBookmark bookmarks[]; // 表示 quicklist 的书签数组,用于存储书签信息
} quicklist;
quicklist 的结构如下图所示:双向非循环的链表。
quicklistPushHead
-
函数功能:向一个
quicklist的头结点ziplist的头插一个新元素。 -
参数:
quicklist *quicklist:待插入的quicklist的首地址。void *value:新插入元素的值。size_t sz:新插入元素的大小。
-
返回值:是否开辟新的
quicklistNode。1:开辟了新的quicklistNode。0:没有开辟新的quicklistNode。
#define likely(x) (x)
#define unlikely(x) (x)
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head; // quicklist 的头结点
// 如果 quicklist->head 可以插入新节点
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD); // 插入新元素到 quicklist->head。ziplistPush 在讲解 ziplist 的时候讲过
quicklistNodeUpdateSz(quicklist->head); // 更新 quicklistNode 的 sz 字段
} else { // 如果 quicklist->head 不可以插入新节点
quicklistNode *node = quicklistCreateNode(); // 新开辟一个 quicklist 的节点
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD); // 创建一个空的 ziplist 然后将数据插入到这个 ziplist 中,同时初始化新的 quicklistNode 的 zl 字段
quicklistNodeUpdateSz(node); // 更新 quicklistNode 的 sz 字段
_quicklistInsertNodeBefore(quicklist, quicklist->head, node); // 向 quicklist 的头结点插入一个 ziplist 节点
}
quicklist->count++; // quicklist 中 总 ziplist 节点数加 1
quicklist->head->count++; // quicklist 头结点中 ziplist 节点数量加 1
return (orig_head != quicklist->head); // 是否开辟新的 quicklistNode,根据记录值与现有值比较即可
}
_quicklistNodeAllowInsert
-
函数功能:判断一个
quicklistNode节点中是否可以插入新的ziplist节点。 -
参数:
const quicklistNode *node:带插入元素的quicklistNode。const int fill:qucicklistNode的最大填充因子。const size_t sz:新插入元素的大小。
-
返回值:是否可以插入新的节点。
1:可以插入新的节点。0:不可以插入新的节点。
#define REDIS_STATIC static
#define likely(x) (x)
#define unlikely(x) (x)
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node)) // 如果插入的节点为 NULL
return 0; // 返回 0 表示不允许插入
int ziplist_overhead;
/* size of previous offset */
// [1](见注解1)
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
// [2](见注解2)
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead; // 粗略计算到的 quicklistNode 指向的 ziplist 的总大小
// [3](见注解3)
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
else if (!sizeMeetsSafetyLimit(new_sz))
return 0; // 检查结果为:不安全,则无法插入新的节点
else if ((int)node->count < fill) // 如果当前 quicklistNode 存储的 ziplist 的节点小于 fill
return 1; // 可以插入新的节点
else
return 0;
}
-
ziplist_overhead是用来粗略计算ziplist节点的额外开销的,即ziplist节点除了entry-data之外prevlen和encoding字段的开销。如果新插入元素的大小小于 254 那么prevlen的开销为 1 字节,否则为 5 字节。为什么计算prevlen字段的开销是用新插入元素的大小来计算呢?这种计算只是为了近似地估算节点插入新元素后的总大小。这个计算并没有直接关联到前一个元素的实际偏移量。 -
计算
encoding字段的开销。正好分别对应字符串编码的三种情况:00pp pppp:长度小于等于 63,encoding占用 1 字节。01pp pppp:长度小于等于 16383 ( 2 14 − 1 \space 2^{14} - 1 \space 214−1 ),encoding占用 2 字节。10000 0000:长度大于 16383 ( 2 14 − 1 \space 2^{14} - 1 \space 214−1 ),encoding占用 5 字节。
-
我们来看看这个
fill到底是什么?list-max-ziplist-size:配置server.list_max_ziplist_size属性,该值会赋值给quicklist.fill。这个配置项允许取正值和负值表示不同的逻辑:- 取正值:表示
quicklist节点的ziplist最多可以存放多少个元素。例如,配置为 5,表示每个quicklist节点的ziplist做多包含 5 个元素。 - 取负值:表示
quicklist节点的ziplist最多占用的字节数。这时,它只能取 -1 到 -5 这 5 个值 (默认为 -2),每个值的含义如下:-5:每个quicklist节点上的ziplist大小不能超过64KB。-4:每个quicklist节点上的ziplist大小不能超过32KB。-3:每个quicklist节点上的ziplist大小不能超过16KB。-2:每个quicklist节点上的ziplist大小不能超过8KB。-1:每个quicklist节点上的ziplist大小不能超过4KB。
让我们回到这个判断是否能够插入节点的逻辑上来:
-
对于第一个
if分支,当fill为正数的时候,该条件一定不成立,进入下一个if分支;当fill为负数的时候,fill的值直接限制了quicklistNode的ziplist的大小,if条件中的函数能够判断插入一个ziplist节点之后 (new_sz) 是否超过了fill对ziplist大小的限制,如果没有超过,说明当前quicklistNode的ziplist能插入新节点。相反,则不能插入新节点,进入下一个if分支。 -
对于第二个
if分支,当fill为正数的时候,即使在配置文件中设置的正数非常大,一个quicklistNode的ziplist大小也会受到#define SIZE_SAFETY_LIMIT 8192这个宏的限制;当fill为负数的时候,能走到第二个if分支,说明插入新节点之后已经超过了配置文件中fill对ziplist的大小限制,再对ziplist的大小做8192的限制,其实并没有什么意义。 -
对于第三个
if分支,当fill为负数的时候,该条件一定不成立,进入下一个if分支;当fill为正数的时候,走到这个分支,说明插入新节点之后的ziplist大小并没有超过8192的限制,如果当前quicklistNode中ziplist的节点数量小于fill说明其还能进行插入。反之,则不能进行插入,进入下一个if分支。 -
对于第四个
if分支,走到这里说明当前的quicklistNode一定不能插入新的节点啦!
下面就是
redis的配置文件截图: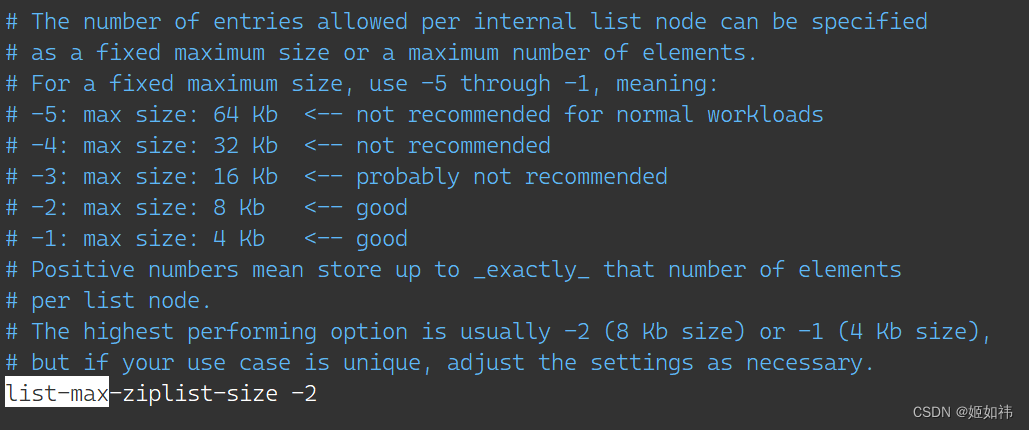
- 取正值:表示
_quicklistNodeSizeMeetsOptimizationRequirement
- 函数功能:判断
ziplist的大小是否满足优化条件。 - 参数:
const size_t sz:ziplist的大小,单位是字节。const int fill:quicklistNode的填充因子。
- 返回值:是否满足优化条件。
1:满足优化条件。0:不满足优化条件。
#define REDIS_STATIC static
static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};
REDIS_STATIC int
_quicklistNodeSizeMeetsOptimizationRequirement(const size_t sz,
const int fill) {
if (fill >= 0) // Redis 的 quicklist 实现中,通常情况下 fill 应该是一个负数,而不是一个非负数
return 0;
size_t offset = (-fill) - 1; // 根据 fill 计算偏移量,偏移量用于确定优化级别数组 optimization_level 中的索引
// 检查索引是否合法
if (offset < (sizeof(optimization_level) / sizeof(*optimization_level))) {
if (sz <= optimization_level[offset]) { // 只有 sz 小于等于该索引下的值,才能优化
return 1;
} else {
return 0; // sz 不满足要求
}
} else {
return 0; // 索引不合法
}
}
sizeMeetsSafetyLimit
宏功能:对 ziplist 的大小进行安全检查。
#define SIZE_SAFETY_LIMIT 8192
#define sizeMeetsSafetyLimit(sz) ((sz) <= SIZE_SAFETY_LIMIT)
quicklistNodeUpdateSz
宏功能:更新一个 quicklistNode 的 sz 字段。
#define quicklistNodeUpdateSz(node) \
do { \
(node)->sz = ziplistBlobLen((node)->zl); \
} while (0)
ziplistBlobLen
- 函数功能:计算一个
ziplist占用的字节数。 - 参数:
unsigned char *zl:ziplist的首地址。
- 返回值:
ziplist占用的字节数。
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) // ziplist 的首 4 字节存储的就是 ziplist 占用的字节数嘛
size_t ziplistBlobLen(unsigned char *zl) {
return intrev32ifbe(ZIPLIST_BYTES(zl)); // intrev32ifbe 仅仅是一个字节序的转换
}
quicklistCreateNode
- 函数功能:在堆上开辟一个
quicklistNode并初始化相关结构体成员。 - 参数:无。
- 返回值:返回新节点的首地址。
#define QUICKLIST_NODE_ENCODING_RAW 1
#define QUICKLIST_NODE_CONTAINER_ZIPLIST 2
REDIS_STATIC quicklistNode *quicklistCreateNode(void) {
quicklistNode *node;
node = zmalloc(sizeof(*node)); // 开辟空间
node->zl = NULL;
node->count = 0;
node->sz = 0;
node->next = node->prev = NULL;
node->encoding = QUICKLIST_NODE_ENCODING_RAW;
node->container = QUICKLIST_NODE_CONTAINER_ZIPLIST;
node->recompress = 0;
return node;
}
_quicklistInsertNodeBefore
- 函数功能:向
quicklist中old_node的前面插一个quicklistNode。 - 参数:
quicklist *quicklist:quicklist结构体的首地址。quicklistNode *old_node:插入基准的quicklistNode地址。quicklistNode *new_node:待插入的quicklistNode地址。
- 返回值:无。
REDIS_STATIC void _quicklistInsertNodeBefore(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node) {
__quicklistInsertNode(quicklist, old_node, new_node, 0);
}
__quicklistInsertNode
- 函数功能:向
quicklist中插入一个quicklistNode。根据after参数决定是插入到old_node结点的前面,还是old_node结点的后面。 - 参数:
quicklist *quicklist:quicklist结构体的首地址。quicklistNode *old_node:插入基准的quicklistNode地址。quicklistNode *new_node:待插入的quicklistNode地址。int after:new_node是否插入到old_node的后面。1:插入到old_node结点的后面。0:插入到old_node结点的前面。
- 返回值:无。
REDIS_STATIC void __quicklistInsertNode(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node, int after) {
if (after) { // 插入到 old_node 结点的后面
new_node->prev = old_node; // 连接前驱节点
if (old_node) {
new_node->next = old_node->next; // 连接后继节点
if (old_node->next)
old_node->next->prev = new_node;
old_node->next = new_node;
}
if (quicklist->tail == old_node)
quicklist->tail = new_node; // 更新 quicklist 结构体的 tail 字段
} else { // 插入到 old_node 结点的前面
new_node->next = old_node;
if (old_node) {
new_node->prev = old_node->prev;
if (old_node->prev)
old_node->prev->next = new_node;
old_node->prev = new_node;
}
if (quicklist->head == old_node)
quicklist->head = new_node;
}
/* If this insert creates the only element so far, initialize head/tail. */
if (quicklist->len == 0) { // 在 if else 的两条分支中,均可能出现需要同时更新 quicklist 的 head 和 tail 的情况,redis 作者将这种情况单独提取出来了,即只有当 quicklist 中没有节点的时候才会出现上述情况
quicklist->head = quicklist->tail = new_node;
}
if (old_node),
quicklistCompress(quicklist, old_node);
quicklist->len++; // quicklist 中的节点数加 1
}
_quicklistInsert
- 函数功能:在
quicklist的指定位置插入元素。 - 参数:
quicklist *quicklist:quicklist结构体的首地址。quicklistEntry *entry:quicklistEntry结构体,quicklistEntry.node指定元素插入的quicklistNode节点,quicklistEntry.offset指定插入ziplist的索引位置 (offset的取值范围是 [ 0 , q u i c k l i s t N o d e . c o u n t ] [0, quicklistNode.count] [0,quicklistNode.count])。void *value:待插入元素的值。const size_t sz:待插入元素的大小。int after:是否在quicklistEntry.offset之后插入ziplist的节点。1:在quicklistEntry.offset之后插入ziplist的节点。。0:在quicklistEntry.offset之前插入ziplist的节点。
- 返回值:无。
typedef struct quicklistEntry
{
const quicklist *quicklist; // 所属的 quicklist
quicklistNode *node; // 所属的 quicklistNode
unsigned char *zi; // ziplist 节点的首地址
unsigned char *value; // 如果 ziplist 节点的数据是字符串,则将数据存储在这个字段中
long long longval; // 如果 ziplist 节点的数据是整数,则将数据存储在这个字段中
unsigned int sz; // 如果 ziplist 节点的数据是字符串,则存储该字符串的大小
int offset; // 存储该 ziplist 节点在整个 ziplist 中的偏移量,可正可负
} quicklistEntry;
// [1](见注解1)
#ifndef REDIS_TEST_VERBOSE
#define D(...)
#else
#define D(...) \
do { \
printf("%s:%s:%d:\t", __FILE__, __FUNCTION__, __LINE__); \
printf(__VA_ARGS__); \
printf("\n"); \
} while (0);
#endif
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after) {
int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;
int fill = quicklist->fill;
quicklistNode *node = entry->node; // 指定元素插入的 quicklistNode 节点
quicklistNode *new_node = NULL;
if (!node) { // 如果指定元素插入的 quicklistNode 节点为 NULL
/* we have no reference node, so let's create only node in the list */
D("No node given!");
new_node = quicklistCreateNode(); // 开辟一个新的 quicklistNode
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD); // 向新开辟的 quicklistNode 的 ziplist 中头插入新元素
__quicklistInsertNode(quicklist, NULL, new_node, after); // 将新开辟的 quicklistNode 插入到 quicklist 中
new_node->count++; // quicklistNode 中 ziplist 节点的数量加 1
quicklist->count++; // quicklist 中总的 ziplist 节点的数量加 1
return;
}
/* Populate accounting flags for easier boolean checks later */
if (!_quicklistNodeAllowInsert(node, fill, sz)) { // 如果指定的 quicklistNode 无法插入新的 ziplist 节点
D("Current node is full with count %d with requested fill %lu",
node->count, fill);
full = 1;
}
// 疑问?为什么这里的判断是 entry->offset == node->count 而不是 entry->offset == node->count - 1,个人认为是尾插的 offset 经过了特殊的处理吧,这个还需要等到后面才能知晓了
if (after && (entry->offset == node->count)) { // 向指定 quicklistNode 节点的 ziplist 尾插
D("At Tail of current ziplist");
at_tail = 1;
if (!_quicklistNodeAllowInsert(node->next, fill, sz)) { // 如果指定的 quicklistNode 的下一个节点无法进行插入
D("Next node is full too.");
full_next = 1;
}
}
if (!after && (entry->offset == 0)) { // 向指定 quicklistNode 节点的 ziplist 头插
D("At Head");
at_head = 1;
if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) { // 如果指定的 quicklistNode 的上一个节点无法进行插入
D("Prev node is full too.");
full_prev = 1;
}
}
// [2](注解2)
/* Now determine where and how to insert the new element */
if (!full && after) { // 指定插入的 quicklistNode 未满,且在 quicklistEntry.offset 的后面插入
D("Not full, inserting after current position.");
quicklistDecompressNodeForUse(node); // 如果节点已经压缩的话解压节点
unsigned char *next = ziplistNext(node->zl, entry->zi); // 获取 offset 节点的下一个节点
// [3](见注解3)
if (next == NULL) {
node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL); // ziplist 的尾插
} else {
node->zl = ziplistInsert(node->zl, next, value, sz); // 非尾插
}
node->count++; // 指定的 quicjlistNode 的 ziplist 节点数量加 1
quicklistNodeUpdateSz(node); // 更新 quicklistNode 的 sz(ziplist占用的字节数) 字段
quicklistRecompressOnly(quicklist, node); // 尝试压缩节点
} else if (!full && !after) { // 指定插入的 quicklistNode 未满,且在 quicklistEntry.offset 的前面插入
D("Not full, inserting before current position.");
quicklistDecompressNodeForUse(node); // 如果节点已经压缩的话解压节点
node->zl = ziplistInsert(node->zl, entry->zi, value, sz); // 插入新节点
node->count++; // 指定的 quicjlistNode 的 ziplist 节点数量加 1
quicklistNodeUpdateSz(node); // 更新 quicklistNode 的 sz(ziplist占用的字节数) 字段
quicklistRecompressOnly(quicklist, node);
} else if (full && at_tail && node->next && !full_next && after) { // 指定插入的 quicklistNode 已满 && 在 ziplist 的尾部插入 && 下一个节点不为 NULL && 下一个节点未满 && 在 quicklistEntry.offset 的 插入
/* If we are: at tail, next has free space, and inserting after:
* - insert entry at head of next node. */
D("Full and tail, but next isn't full; inserting next node head");
new_node = node->next; // 找到指定节点的下一个节点
quicklistDecompressNodeForUse(new_node); // 如果节点已经压缩的话解压节点
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD); // 下一个节点的 ziplist 的头插 [2](见注解2)
new_node->count++; // 更新下一个节点的 ziplist 的节点数量
quicklistNodeUpdateSz(new_node); // 更新下一个节点的 ziplist 的 sz(ziplist 占用的字节数) 字段
quicklistRecompressOnly(quicklist, new_node);
} else if (full && at_head && node->prev && !full_prev && !after) {
/* If we are: at head, previous has free space, and inserting before:
* - insert entry at tail of previous node. */
D("Full and head, but prev isn't full, inserting prev node tail");
new_node = node->prev; // 找到指定节点的上一个节点
quicklistDecompressNodeForUse(new_node); // 如果节点已经压缩的话解压节点
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL); // 上一个节点的 ziplist 的尾插 [2](见注解2)
new_node->count++; // 更新上一个节点的 ziplist 的节点数量
quicklistNodeUpdateSz(new_node); // 更新上一个节点的 ziplist 的 sz(ziplist 占用的字节数) 字段
quicklistRecompressOnly(quicklist, new_node);
} else if (full && ((at_tail && node->next && full_next && after) ||
(at_head && node->prev && full_prev && !after))) {
/* If we are: full, and our prev/next is full, then:
* - create new node and attach to quicklist */
D("\tprovisioning new node...");
new_node = quicklistCreateNode(); // 创建一个新的 quicklistNode 节点
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD); // 新节点 ziplist 的头插
new_node->count++; // 新节点的 ziplist 的节点数量加 1
quicklistNodeUpdateSz(new_node); // 更新新节点的 sz 字段
__quicklistInsertNode(quicklist, node, new_node, after); // 根据 after 插入新节点到 quicklist 中,确保与 offset 节点的位置关系正确
} else if (full) {
/* else, node is full we need to split it. */
/* covers both after and !after cases */
D("\tsplitting node...");
quicklistDecompressNodeForUse(node); // 如果节点已经压缩的话解压节点
new_node = _quicklistSplitNode(node, entry->offset, after); // after 为 1,new_node 是 将 offset 之后的 ziplist 节点组成一个 quicklistNode 的首地址;after 为 0,new_node 的 ziplist 是原节点 ziplist 的第一个节点到 offset 节点的前一个节点
new_node->zl = ziplistPush(new_node->zl, value, sz,
after ? ZIPLIST_HEAD : ZIPLIST_TAIL); // after 为 1 是头插,after 为 0 是尾插
new_node->count++; // new_node 必然是新插入元素的那个节点
quicklistNodeUpdateSz(new_node); // 更新这个节点 sz 字段
__quicklistInsertNode(quicklist, node, new_node, after); // 根据 after 选择 new_node 的插入位置,确保新插入元素与 offset 节点的相对位置的正确
_quicklistMergeNodes(quicklist, node);
}
quicklist->count++; // 整个 quicklist 的 quicklistNode 数量加 1
}
-
这是一个用来打印调试信息的宏,一般会在
debug阶段使用,通过条件编译来决定该宏的打印哈!其中D(...)中的三个点是 C 语言中的一个预处理器特性,表示可变参数宏(variadic macro)。这是C99标准中引入的特性,允许宏接受可变数量的参数。通常我们用__VA_ARGS__来接收这个可变参数。 -
下面就是
_quicklistInsert函数中if else分支中的 6 中情况,序号的顺序与代码的分支顺序匹配。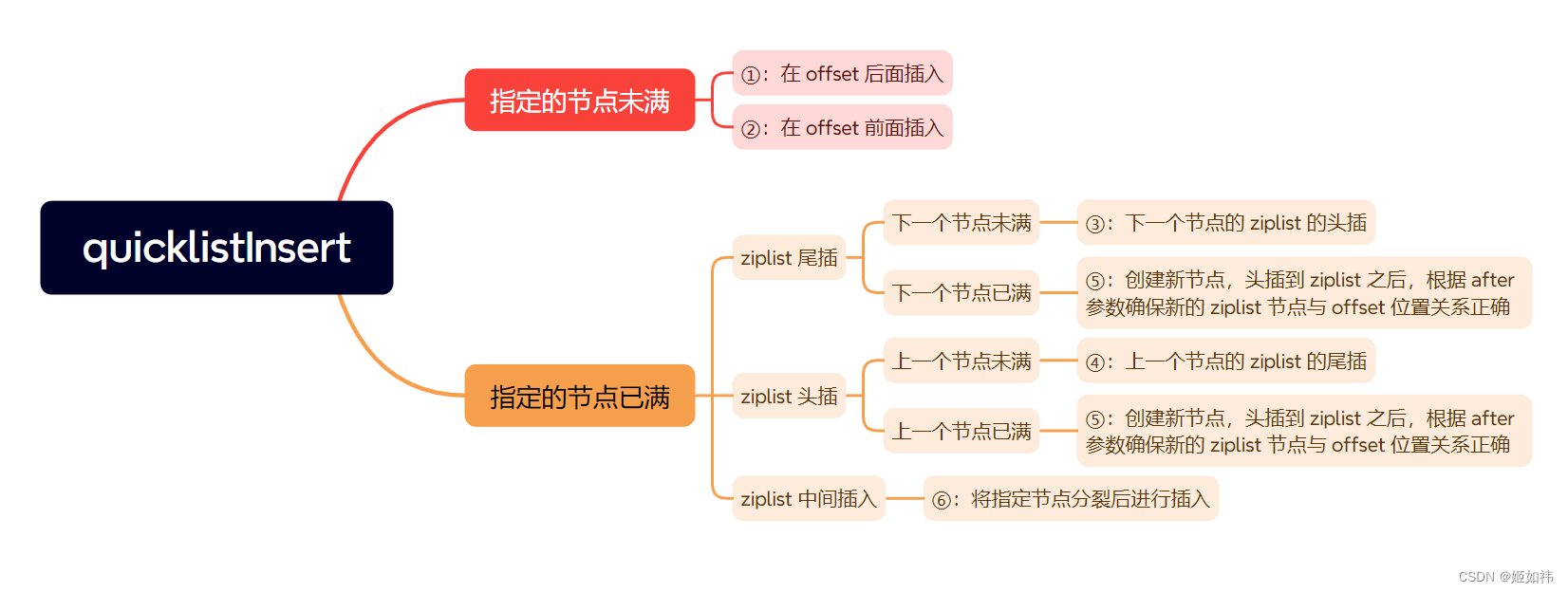
-
在 《Redis 核心原理与实践》中说,在此代码环境下
ziplistPush在尾插的时候效率比ziplistInsert的效率高。我个人认为没有什么大的差异哈!因为ziplistPush与ziplistInsert函数最终都是调用的__ziplistInsert函数嘛。但是呢,ziplistPush函数能够对__ziplistInsert函数的第二个参数提前处理出来,因此效率上的差异应该就是在第二个参数的处理上!通常情况下,我们调用ziplistInsert函数要提前找到这个后驱节点,效率上自然比不上ziplistPush。但是在这个代码环境上,我们已经通过quicklistEntry这个结构体能够直接获取到这个后驱节点。无论对于ziplistPush的调用,还是对于ziplistInsert的调用,_quicklistInsert都是要传入quicklistEntry这个结构体的,因此,个人认为效率上是没有太大差别的。
quicklistDecompressNodeForUse
quicklistRecompressOnly
- 宏功能:
#define quicklistRecompressOnly(_ql, _node) \
do { \
if ((_node)->recompress) \
quicklistCompressNode((_node)); \
} while (0)
quicklistCompressNode
- 宏功能:
#define quicklistCompressNode(_node) \
do { \
if ((_node) && (_node)->encoding == QUICKLIST_NODE_ENCODING_RAW) { \
__quicklistCompressNode((_node)); \
} \
} while (0)
__quicklistCompressNode
- 函数功能:
- 参数:
- 返回值:
typedef struct quicklistLZF {
unsigned int sz; // 压缩最后的 ziplist 大小
char compressed[]; // 存放压缩后的 ziplist 字节数组
} quicklistLZF;
#define MIN_COMPRESS_BYTES 48
REDIS_STATIC int __quicklistCompressNode(quicklistNode *node) {
// ziplist 大于等于 48 字节才尝试压缩
if (node->sz < MIN_COMPRESS_BYTES)
return 0;
quicklistLZF *lzf = zmalloc(sizeof(*lzf) + node->sz);
/* Cancel if compression fails or doesn't compress small enough */
if (((lzf->sz = lzf_compress(node->zl, node->sz, lzf->compressed,
node->sz)) == 0) ||
lzf->sz + MIN_COMPRESS_IMPROVE >= node->sz) {
/* lzf_compress aborts/rejects compression if value not compressable. */
zfree(lzf);
return 0;
}
lzf = zrealloc(lzf, sizeof(*lzf) + lzf->sz);
zfree(node->zl);
node->zl = (unsigned char *)lzf;
node->encoding = QUICKLIST_NODE_ENCODING_LZF;
node->recompress = 0;
return 1;
}
_quicklistSplitNode
- 函数功能:根据条件分裂指定的
quicklistNode。 - 参数:
quicklistNode *node:指定要进行分裂的quicklistNode节点。int offset:指定节点中的ziplist节点的索引,是节点分裂的边界线。int after:具体决定offset节点的划分。
- 返回值:分裂出来的
quicklistNode节点的首地址,设分裂出来的节点为new_node。after == 1时new_node的ziplist中的节点为offset之后的所有节点,不包括offset节点。after == 0时new_node的ziplist中的节点为第一个节点到offset节点的前一个节点。
REDIS_STATIC quicklistNode *_quicklistSplitNode(quicklistNode *node, int offset,
int after) {
size_t zl_sz = node->sz; // quicklistNode 的 ziplist 占用的字节数
quicklistNode *new_node = quicklistCreateNode(); // 开辟一个新的 quicklistNode
new_node->zl = zmalloc(zl_sz); // 开辟一个新的 ziplist
/* Copy original ziplist so we can split it */
memcpy(new_node->zl, node->zl, zl_sz); // 将原来的 ziplist 给新的 ziplist 拷贝一份
/* -1 here means "continue deleting until the list ends" */
// 当 after 为 1 时, orig_start = offset + 1 orig_extent = -1
// new_start = 0 new_extent = offset + 1
// 画图可知 orig_start 到 orig_extent 为 offset 之后的所有节点,不包括 offset 这个节点
// new_start 到 new_extent 为第一个节点到 offset 节点,包括 offset 节点
// 当 after 为 0 时, orig_start = 0 orig_extent = offset
// new_start = offset new_extent = -1
// 画图可知 orig_start 到 orig_extent 为第一个节点到 offset 节点的前一个节点
// new_start 到 new_extent 为 offset 之后的所有节点,包括 offset 节点
int orig_start = after ? offset + 1 : 0;
int orig_extent = after ? -1 : offset;
int new_start = after ? 0 : offset;
int new_extent = after ? offset + 1 : -1;
D("After %d (%d); ranges: [%d, %d], [%d, %d]", after, offset, orig_start,
orig_extent, new_start, new_extent);
// ziplistDeleteRange 的第三个参数是删除节点的个数,参数的类型是 unsigned int 传入 -1 会使得形参变得非常大,从而达到删除指定索引之后的所有节点
node->zl = ziplistDeleteRange(node->zl, orig_start, orig_extent)
node->count = ziplistLen(node->zl);
quicklistNodeUpdateSz(node); // 更新 sz 字段
new_node->zl = ziplistDeleteRange(new_node->zl, new_start, new_extent);
new_node->count = ziplistLen(new_node->zl);
quicklistNodeUpdateSz(new_node); // 更新 sz 字段
D("After split lengths: orig (%d), new (%d)", node->count, new_node->count);
return new_node;
// after == 1 时 new_node 的 ziplist 中的节点为 offset 之后的所有节点,不包括 offset 节点
// after == 0 时 new_node 的 ziplist 中的节点为 第一个节点到 offset 节点的前一个节点
}
ziplistDeleteRange
- 函数功能:删除
ziplist的节点。 - 参数:
unsigned char *zl:ziplist的首地址。unsigned char *p:需要删除节点的首地址。unsigned int num:从p开始向后删除num个节点 (包括p节点)。
- 返回值:返回删除节点之后
ziplist的首地址。
unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num) {
unsigned char *p = ziplistIndex(zl,index);
return (p == NULL) ? zl : __ziplistDelete(zl,p,num);
}
ziplistIndex
- 函数功能:获取一个
ziplist索引为index的节点的首地址。 - 参数:
unsigned char *zl:ziplist的首地址。int index:想要获取的索引。支持负索引。
- 返回值:根据索引获取到的
ziplist节点的首地址。无效的索引返回 NULL,目标索引对应的节点是 ZIP_END 返回 NULL。
// ziplist 中是有一个字段保存了 ziplist 其实位置到最后一个节点的偏移量的嘛
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 首地址加上偏移量就是尾节点的首地址啦,intrev32ifbe 用来转换字节序
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \
ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \
if ((prevlensize) == 1) { \
(prevlen) = (ptr)[0]; \
} else if ((prevlensize) == 5) { \
assert(sizeof((prevlen)) == 4); \
memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \
memrev32ifbe(&prevlen); \
} \
} while(0)
// ziplist 头部的数据是固定的嘛
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 首地址加上头部数据的大小就是 ziplist 首节点的地址嘛
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 传入一个 ziplist 的节点,返回该节点占用的字节数
unsigned int zipRawEntryLength(unsigned char *p) {
unsigned int prevlensize, encoding, lensize, len;
ZIP_DECODE_PREVLENSIZE(p, prevlensize); // 获取 prevlen 字段的字节数,保存到 prevlensize 变量中
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len); // 获取 encoding 字段的字节数,并将结果保存到 lensize 字段中;获取 ziplist 存储数据的字节数,并将结果保存到 len 中。
return prevlensize + lensize + len;
}
unsigned char *ziplistIndex(unsigned char *zl, int index) {
unsigned char *p;
unsigned int prevlensize, prevlen = 0;
if (index < 0) { // 如果索引值小于 0,计算该索引是倒数第几个节点
index = (-index)-1;
p = ZIPLIST_ENTRY_TAIL(zl); // 获取 ziplist 的尾节点
if (p[0] != ZIP_END) { // 尾节点不是 ZIP_END 说明 ziplist
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); // 获取 prevlen 字段的字节数,并将结果保存到 prevlensize 变量中,获取前驱节点占用的字节数,并将结果保存到 prevlen 变量中。
while (prevlen > 0 && index--) { // 找到索引值对应的节点,prevlen > 0 这个条件能对索引进行检查,确保不越界
p -= prevlen p 开始向后删除 num 个节点 (
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); // 更新 prevlen
}
}
} else { // 索引值大于 0
p = ZIPLIST_ENTRY_HEAD(zl); // 获取 ziplist 头结点的首地址
while (p[0] != ZIP_END && index--) {
p += zipRawEntryLength(p); // 跳过一个节点
}
}
return (p[0] == ZIP_END || index > 0) ? NULL : p; // 无效的索引返回 NULL,目标索引对应的节点是 ZIP_END 返回 NULL
}
__ziplistDelete
- 函数功能:删除
ziplist的节点。 - 参数:
unsigned char *zl:ziplist的首地址。unsigned char *p:需要删除节点的首地址。unsigned int num:从p开始向后删除num个节点 (包括p节点)。
- 返回值:返回删除节点之后
ziplist的首地址。
typedef struct zlentry
{
unsigned int prevrawlensize; // prevlen 字段占用的字节数
unsigned int prevrawlen; // 前驱节点的字节数
unsigned int lensize; // encoding 字段占用的字节数
unsigned int len; // 存储数据占用的字节数
unsigned int headersize; // prevlen 占用的字节数 + encoding 字段占用的字节数
unsigned char encoding; // 编码方式
unsigned char *p; // 节点的首地址
} zlentry;
unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
zipEntry(p, &first); // 传入 ziplist 节点的首地址,获取节点相关的数据,用来初始化 zlentry 这个结构体。
for (i = 0; p[0] != ZIP_END && i < num; i++) {
p += zipRawEntryLength(p); // 跳过一个节点
deleted++; // 已经删除的节点数量
}
totlen = p-first.p; // 总共需要删除的字节数
if (totlen > 0) { // 有需要删除的节点
if (p[0] != ZIP_END) {
/* Storing `prevrawlen` in this entry may increase or decrease the
* number of bytes required compare to the current `prevrawlen`.
* There always is room to store this, because it was previously
* stored by an entry that is now being deleted. */
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen); // 最后需要删除的那个节点的下一个节点的 prevlen 字段能否存储第一个需要删除的节点的前一个节点占用的字节数。
p -= nextdiff; // [1](见注解1)
zipStorePrevEntryLength(p,first.prevrawlen); // 修改 p 节点的 prevlen 字段为 first.prevrawlen
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen); // 更新 ziplist 的 ztail 字段
zipEntry(p, &tail); // 传入 ziplist 节点的首地址,获取节点相关的数据,用来初始化 zlentry 这个结构体。
if (p[tail.headersize+tail.len] != ZIP_END) { // 如果 p 指向的节点不是最后一个节点
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff); // ztail 字段的更新还需要加上 nextdiff。不明白画一个图就明白了 [2](见注解2)
}
// 移动指针 p 之后的所有数据,不包括那个 zlend 哈,这是因为在下面的 ziplistResize 对 zlend 进行了处理的哈
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
} else { // 说明节点 p 之后的所有节点都需要删除(包括节点 p)
// 这样的话,我们就不需要移动数据啦,直接修改 zltail 字段就行啦
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
}
offset = first.p-zl; // 第一个需要删除节点相对于 ziplist 首地址的偏移量
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff); // 重新开辟空间,我们已经移动了数据,realloc 会保留所有有效的数据,并且我们放弃了原来空间的继续使用。即 ziplist 末尾多余的空间我们归还给操作系统了,realloc 缩容,没有效率上的损耗吧,O(1) 的
ZIPLIST_INCR_LENGTH(zl,-deleted); // 修改 zllen 字段
p = zl+offset; // 让 p 重新指向最后一个需要删除节点的下一个节点
if (nextdiff != 0) // nextdiff 不等于 0 进行级联更新
zl = __ziplistCascadeUpdate(zl,p);
}
return zl; // 返回新的 ziplist 的首地址
}
-
如下图是
nextdiff的取值与p指针的修正。
-
下图是
p指针指向的节点是ziplist尾节点的情况:

不是尾节点的情况整个 ziplist 在中间少了多少字节,尾节点的偏移就要与之对应,当然要加上 nextdiff。
_quicklistMergeNodes
- 函数功能:尝试合并多组
quicklistNode节点。 - 参数:
quicklist *quicklist:quicklist首地址。quicklistNode *center:中心节点。
- 返回值:无。
REDIS_STATIC void _quicklistMergeNodes(quicklist *quicklist,
quicklistNode *center) {
int fill = quicklist->fill;
quicklistNode *prev, *prev_prev, *next, *next_next, *target;
prev = prev_prev = next = next_next = target = NULL;
// 初始化 prev prev_prev 变量
if (center->prev) {
prev = center->prev;
if (center->prev->prev)
prev_prev = center->prev->prev;
}
// 初始化 next next_next 变量
if (center->next) {
next = center->next;
if (center->next->next)
next_next = center->next->next;
}
// 尝试合并 prev_prev 和 prev 这两个节点
if (_quicklistNodeAllowMerge(prev, prev_prev, fill)) {
_quicklistZiplistMerge(quicklist, prev_prev, prev);
prev_prev = prev = NULL; /* they could have moved, invalidate them. */
}
// 尝试合并 next_next 和 next 这两个节点
if (_quicklistNodeAllowMerge(next, next_next, fill)) {
_quicklistZiplistMerge(quicklist, next, next_next);
next = next_next = NULL; /* they could have moved, invalidate them. */
}
// 尝试合并 center 和 center->prev 这两个节点
if (_quicklistNodeAllowMerge(center, center->prev, fill)) {
target = _quicklistZiplistMerge(quicklist, center->prev, center);
center = NULL; /* center could have been deleted, invalidate it. */
} else {
/* else, we didn't merge here, but target needs to be valid below. */
target = center;
}
// 尝试合并 node 和 node->next
// 如果上一次合并成功,那么原来的 center 会失效,有效的是 target,但是如果合并失败就需要用原来的 center 所以上一次的合并需要有 else 分支。
if (_quicklistNodeAllowMerge(target, target->next, fill)) {
_quicklistZiplistMerge(quicklist, target, target->next);
}
}
_quicklistNodeAllowMerge
- 函数功能:判断两个节点能否进行合并。
- 参数:
const quicklistNode *a:需要合并的第一个节点。const quicklistNode *b:需要合并的第二个节点。const int fill:quicklistNode的最大填充因子。
- 返回值:这两个节点能否进行合并。
1:这两个节点能否进行合并。0:这两个节点不能否进行合并。
REDIS_STATIC int _quicklistNodeAllowMerge(const quicklistNode *a,
const quicklistNode *b,
const int fill) {
if (!a || !b)
return 0; // 如果有一个 quicklistNode 节点为 NULL 不可能进行合并
//减 11 是因为两个 ziplist 有重复的 zlbytes(4字节) zltail(4字节) zllen(2字节) zlend(1字节) 字段
unsigned int merge_sz = a->sz + b->sz - 11;
// 这里的逻辑和 _quicklistNodeAllowInsert 函数是一样的,不做分析了
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(merge_sz, fill)))
return 1;
else if (!sizeMeetsSafetyLimit(merge_sz))
return 0;
else if ((int)(a->count + b->count) <= fill)
return 1;
else
return 0;
}
_quicklistZiplistMerge
-
函数功能:合并两个
quicklistNode的ziplist。 -
参数:
quicklist *quicklist:quicklist的首地址。quicklistNode *a:需要合并的第一个quicklistNode。quicklistNode *b:需要合并的第二个quicklistNode。
-
返回值:节点合并成功,返回新节点的首地址;节点合并失败,返回 NULL。
/* Decompress only compressed nodes. */
#define quicklistDecompressNode(_node) \
do { \
if ((_node) && (_node)->encoding == QUICKLIST_NODE_ENCODING_LZF) { \
__quicklistDecompressNode((_node)); \
} \
} while (0)
REDIS_STATIC quicklistNode *_quicklistZiplistMerge(quicklist *quicklist,
quicklistNode *a,
quicklistNode *b) {
D("Requested merge (a,b) (%u, %u)", a->count, b->count);
quicklistDecompressNode(a); // 解压节点
quicklistDecompressNode(b); // 解压节点
if ((ziplistMerge(&a->zl, &b->zl))) { // 如果合并成功
quicklistNode *keep = NULL, *nokeep = NULL;
// 判断是哪个 quicklistNode 的 ziplist 被释放了
if (!a->zl) {
nokeep = a; // 第一个 quicklistNode 的 ziplist 被释放啦
keep = b;
} else if (!b->zl) {
nokeep = b; // 第二个 quicklistNode 的 ziplist 被释放啦
keep = a;
}
// 更新新节点的 count(ziplist 的节点数量) 字段
keep->count = ziplistLen(keep->zl);
// 更新 新节点的 sz (ziplist 的总大小) 字段
quicklistNodeUpdateSz(keep);
// 回收资源
nokeep->count = 0;
// 释放节点
__quicklistDelNode(quicklist, nokeep);
// 压缩节点
quicklistCompress(quicklist, keep);
// 返回合并之后的 quicklistNode 的首地址
return keep;
} else {
// 合并失败,返回 NULL
return NULL;
}
}
ziplistMerge
- 函数功能:合并两个
ziplist。 - 参数:
unsigned char **first:第一个ziplist。unsigned char **second:第二个ziplist。
- 返回值:合并之后的
ziplist的首地址。
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second) {
// 如果 ziplist 的任何一级指针为 NULL 都无法进行合并
if (first == NULL || *first == NULL || second == NULL || *second == NULL)
return NULL;
// 两个相同的 ziplit 不能进行合并
if (*first == *second)
return NULL;
// 第一个 ziplist 的大小,节点数量
size_t first_bytes = intrev32ifbe(ZIPLIST_BYTES(*first));
size_t first_len = intrev16ifbe(ZIPLIST_LENGTH(*first));
// 第二个 ziplist 的大小,节点数量
size_t second_bytes = intrev32ifbe(ZIPLIST_BYTES(*second));
size_t second_len = intrev16ifbe(ZIPLIST_LENGTH(*second));
int append;
unsigned char *source, *target;
size_t target_bytes, source_bytes;
/* Pick the largest ziplist so we can resize easily in-place.
* We must also track if we are now appending or prepending to
* the target ziplist. */
// 确定 target ziplist 和 source ziplist
// 选择节点数量较多的 ziplist 作为 target
if (first_len >= second_len) {
/* retain first, append second to first. */
target = *first;
target_bytes = first_bytes;
source = *second;
source_bytes = second_bytes;
append = 1;
} else {
/* else, retain second, prepend first to second. */
target = *second;
target_bytes = second_bytes;
source = *first;
source_bytes = first_bytes;
append = 0;
}
// 计算两个 ziplist 的所有节点和一个 zlbytes zltail zllen zlend 的大小 (单位字节)
size_t zlbytes = first_bytes + second_bytes -
ZIPLIST_HEADER_SIZE - ZIPLIST_END_SIZE;
// 计算两个 ziplist 的节点数量
size_t zllength = first_len + second_len;
// 因为 zllen 本身的类型限制,获取一个 ziplist 的节点数量也是有限制的,当超过 UINT16_MAX - 1 个节点时,只能通过遍历整个 ziplist 来获取节点数量
zllength = zllength < UINT16_MAX ? zllength : UINT16_MAX;
// 保存尾节点相对于 ziplist 起始地址的偏移量
size_t first_offset = intrev32ifbe(ZIPLIST_TAIL_OFFSET(*first));
size_t second_offset = intrev32ifbe(ZIPLIST_TAIL_OFFSET(*second));
// 给 target 的 ziplist 开辟足够的空间
target = zrealloc(target, zlbytes
if (append) { // 参数 1 的 ziplist 节点个数大于参数 2 ziplist 的节点个数
// 拷贝数据,目的地址:跳过整个 target ziplist,但是需要减去 target 的 zlend
// 源地址:source 的 ziplist,跳过头部的固定字段,即 source 的第一个节点的首地址
// 拷贝的字节数:source 的 ziplist 第一个节点往后的所有数据。
memcpy(target + target_bytes - ZIPLIST_END_SIZE,
source + ZIPLIST_HEADER_SIZE,
source_bytes - ZIPLIST_HEADER_SIZE);
} else { // 参数 1 的 ziplist 节点个数小于等于参数 2 ziplist 的节点个数
// 将参数 2 的 ziplist 第一个节点往后的数据统统后移,保证参数 1 和参数 2 节点的相对顺序
// 目的地址:target 的起始地址 + 参数 1 ziplist 的总大小 - zlend 的大小
// 源地址:target 的起始地址 + 参数 2 头部固定字段的大小 (zlbytes zltail zllen)
// 移动的字节数:参数 2 ziplist 的总大小 - 参数 2 头部固定字段的大小 (zlbytes zltail zllen)
memmove(target + source_bytes - ZIPLIST_END_SIZE,
target + ZIPLIST_HEADER_SIZE,
target_bytes - ZIPLIST_HEADER_SIZE);
// 拷贝参数 2 的头部字段以及节点数据
memcpy(target, source, source_bytes - ZIPLIST_END_SIZE);
}
// 更新 zlbytes 字段
ZIPLIST_BYTES(target) = intrev32ifbe(zlbytes);
// 更新 zllen 字段
ZIPLIST_LENGTH(target) = intrev16ifbe(zllength);
// 更新 zltail 字段,更新方式不止下面写的一种,这应该时最简单,最好理解的一种吧
ZIPLIST_TAIL_OFFSET(target) = intrev32ifbe(
(first_bytes - ZIPLIST_END_SIZE) +
(second_offset - ZIPLIST_HEADER_SIZE));
// 级联更新,接收返回值
target = __ziplistCascadeUpdate(target, target+first_offset);
if (append) { // 参数 1 的 ziplist 节点个数大于参数 2 ziplist 的节点个数
zfree(*second); // 释放第二个 ziplist
*second = NULL;
*first = target; // 二级指针才能在函数内部修改外部实参
} else { // 参数 1 的 ziplist 节点个数小于等于参数 2 ziplist 的节点个数
zfree(*first); // 释放第一个 ziplist
*first = NULL;
*second = target;
}
return target; // 返回合并之后的 ziplist 的首地址
}
ziplistLen
- 函数功能:统计一个
ziplist的节点数量。 - 参数:
unsigned char *zl:需要统计节点数量的ziplist的首地址。
- 返回值:计算得到的
ziplist节点的数量。
unsigned int ziplistLen(unsigned char *zl) {
unsigned int len = 0;
if (intrev16ifbe(ZIPLIST_LENGTH(zl)) < UINT16_MAX) { // 节点数量小于 UINT16_MAX 说明不需要遍历 ziplist 来获取节点数量
len = intrev16ifbe(ZIPLIST_LENGTH(zl)); // 获取 ziplist 的节点数量
} else {
unsigned char *p = zl+ZIPLIST_HEADER_SIZE; // 找到第一个 ziplist 节点
while (*p != ZIP_END) { // 遍历 ziplist
p += zipRawEntryLength(p);
len++; // 越过一个节点,节点数量加 1
}
// 如果遍历得到的节点数量小于 UINT16_MAX 那么更新一下 zllen 字段,可能是可能怕有错误发生吧
if (len < UINT16_MAX) ZIPLIST_LENGTH(zl) = intrev16ifbe(len);
}
return len; // 返回计算得到的 ziplist 的节点数量
}
quicklistCreate
- 函数功能:创建一个空的
quicklist。 - 参数:无。
- 返回值:返回创建的
quicklist的首地址。
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
quicklist->bookmark_count = 0;
return quicklist;
}
quicklistNew
- 函数功能:创建一个空的
quicklist,自定义初始化fill字段,compress字段。 - 参数:
int fill:quicklistNode的最大填充因子。int compress:节点压缩配置。
- 返回值:返回创建的
quicklist的首地址。
quicklist *quicklistNew(int fill, int compress) {
quicklist *quicklist = quicklistCreate();
quicklistSetOptions(quicklist, fill, compress); // 设置 fill,compress 字段
return quicklist;
}
quicklistPushTail
- 函数功能:找到
quicklist的尾节点,向他的ziplist中尾插一个新元素。 - 参数:
quicklist *quicklist:待插入的quicklist的首地址。void *value:新插入元素的值。size_t sz:新插入元素的大小。
- 返回值:是否开辟新的
quicklistNode。1:开辟了新的quicklistNode。0:没有开辟新的quicklistNode。
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail; // quicklist 的尾节点
// 如果 quicklist->tail 可以插入新的 ziplist 节点
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL); // 向 quicklist->tail 的 ziplist 尾插
quicklistNodeUpdateSz(quicklist->tail); // 更新 quicklist->tail 的 sz 字段
} else { // quicklist->tail 不能插入新节点
quicklistNode *node = quicklistCreateNode(); // 创建一个新的 quicklistNode 节点
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL); // 创建一个新的 ziplist 节点并且将仅元素尾插到该 ziplist 中
quicklistNodeUpdateSz(node); // 更新新的 quicklistNode 的 sz 字段
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node); // 将这个新的节点插入到 quicklist->tail 节点的后面
}
quicklist->count++; // 更新 quicklist 的 count
quicklist->tail->count++;
return (orig_tail != quicklist->tail); // 判断是否开辟了新的 quicklistNode
}
quicklistIndex
-
函数功能:判断索引在
quicklist中是否有效。如果有效,则将该索引的ziplist信息保存到输出型参数quicklistEntry结构体中。 -
参数:
const quicklist *quicklist:quicklist的首地址。const long long idx:索引。quicklistEntry *entry:输出有效索引下的ziplist节点信息。
-
返回值:索引是否有效。
1:有效。0:无效。
typedef struct quicklistEntry
{
const quicklist *quicklist; // 所属的 quicklist
quicklistNode *node; // 所属的 quicklistNode
unsigned char *zi; // ziplist 节点的首地址
unsigned char *value; // 如果 ziplist 节点的数据是字符串,则将数据存储在这个字段中
long long longval; // 如果 ziplist 节点的数据是整数,则将数据存储在这个字段中
unsigned int sz; // 如果 ziplist 节点的数据是字符串,则存储该字符串的大小
int offset; // 存储该 ziplist 节点在整个 ziplist 中的偏移量,可正可负
} quicklistEntry;
int quicklistIndex(const quicklist *quicklist, const long long idx,
quicklistEntry *entry) {
quicklistNode *n;
unsigned long long accum = 0;
unsigned long long index;
int forward = idx < 0 ? 0 : 1; /* < 0 -> reverse, 0+ -> forward */
initEntry(entry);
entry->quicklist = quicklist; // 初始化 quicklist 属性
if (!forward) { // 将负的下标转换成正的保存到 index 变量中
index = (-idx) - 1;
n = quicklist->tail;
} else {
index = idx;
n = quicklist->head;
}
// 下标不能越界,小于 quicklist 的 ziplist 节点的总和
if (index >= quicklist->count)
return 0;
// 确定 idx 是在哪一个 quicklistNode
while (likely(n)) {
if ((accum + n->count) > index) {
break;
} else {
D("Skipping over (%p) %u at accum %lld", (void *)n, n->count,
accum);
accum += n->count; // 跳过一个 quiclistNode 的 ziplist 节点数
n = forward ? n->next : n->prev; // 根据 forward 确定遍历方向
}
}
// 如果指定的 idx 越界啦
if (!n)
return 0;
D("Found node: %p at accum %llu, idx %llu, sub+ %llu, sub- %llu", (void *)n,
accum, index, index - accum, (-index) - 1 + accum);
entry->node = n; // 初始化 node 字段
// 确定在 quicklistNode 的 ziplist 中的下标
if (forward) {
entry->offset = index - accum; // 设置 offset 字段,节点数量实际为 index + 1, 在节点中的下标 = index + 1 - accum - 1 = index - accum
} else {
// 节点数量实际为 index + 1, 在节点中的负下标(-1 表示倒数第一个节点嘛):-(index + 1 - accum) = (-index) - 1 + accum
entry->offset = (-index) - 1 + accum; // 设置 offset 字段,负数表示从右往左数
}
quicklistDecompressNodeForUse(entry->node); // 解压节点
entry->zi = ziplistIndex(entry->node->zl, entry->offset); // 获取对应下标的 ziplist 节点的首地址
ziplistGet(entry->zi, &entry->value, &entry->sz, &entry->longval);
/* The caller will use our result, so we don't re-compress here.
* The caller can recompress or delete the node as needed. */
return 1;
}
initEntry
宏功能:初始化 quicklistEntry 结构体。
#define initEntry(e) \
do { \
(e)->zi = (e)->value = NULL; \
(e)->longval = -123456789; \
(e)->quicklist = NULL; \
(e)->node = NULL; \
(e)->offset = 123456789; \
(e)->sz = 0; \
} while (0)
ziplistGet
-
函数功能:获取一个
ziplist节点存储的数据。如果节点的编码时字符串,那么顺便获取字符串的长度。 -
参数:
unsigned char *p:ziplist节点的首地址。unsigned char **sstr:字符串的首地址。unsigned int *slen:字符串的长度。long long *sval:整数值。
-
返回值:节点数据是否获取成功。
1:获取成功。0:获取失败。
typedef struct zlentry
{
unsigned int prevrawlensize; // prevlen 字段占用的字节数
unsigned int prevrawlen; // 前驱节点的字节数
unsigned int lensize; // encoding 字段占用的字节数
unsigned int len; // 存储数据占用的字节数
unsigned int headersize; // prevlen 占用的字节数 + encoding 字段占用的字节数
unsigned char encoding; // 编码方式
unsigned char *p; // 节点的首地址
} zlentry;
#define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK)
#define ZIP_STR_MASK 0xc0
unsigned int ziplistGet(unsigned char *p, unsigned char **sstr, unsigned int *slen, long long *sval) {
zlentry entry;
// 节点存在且有效才能获取节点数据
if (p == NULL || p[0] == ZIP_END) return 0;
if (sstr) *sstr = NULL;
zipEntry(p, &entry); // 用节点 p 初始化 entry 结构体
if (ZIP_IS_STR(entry.encoding)) { // 如果节点的编码是字符串
if (sstr) {
*slen = entry.len; // 设置 slen
*sstr = p+entry.headersize; // 设置 sstr
}
} else { // 节点的编码 整数
if (sval) {
*sval = zipLoadInteger(p+entry.headersize,entry.encoding); // 获取整数值,保存到 sval 中
}
}
return 1; // 获取成功
}
quicklistDelEntry
-
函数功能:删除
quicklist中的一个ziplist节点。 -
参数:
quicklistIter *iter:要删除的ziplist对应的迭代器。quicklistEntry *entry:要删除节点相关的信息。
-
返回值:无。
-
疑问:传入一个迭代器就已经能实现
ziplist节点的删除了,为什么还要传quicklistEntry这个结构体?
#define AL_START_HEAD 0
#define AL_START_TAIL 1
// C 语言版本的数据结构迭代器通过结构体来实现
typedef struct quicklistIter
{
const quicklist *quicklist; // 指向所属的 quicklist
quicklistNode *current; // 当前遍历到的 quicklistNode
unsigned char *zi; // 当前遍历到的 ziplist 节点的首地址
long offset; // 当前遍历到的 ziplist 节点的索引
int direction; // 迭代器的遍历方向,两种取值:AL_START_HEAD : head to tail AL_START_TAIL : tail to head
} quicklistIter;
typedef struct quicklistEntry
{
const quicklist *quicklist; // 所属的 quicklist
quicklistNode *node; // 所属的 quicklistNode
unsigned char *zi; // ziplist 节点的首地址
unsigned char *value; // 如果 ziplist 节点的数据是字符串,则将数据存储在这个字段中
long long longval; // 如果 ziplist 节点的数据是整数,则将数据存储在这个字段中
unsigned int sz; // 如果 ziplist 节点的数据是字符串,则存储该字符串的大小
int offset; // 存储该 ziplist 节点在整个 ziplist 中的偏移量,可正可负
} quicklistEntry;
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev; // 前驱节点
quicklistNode *next = entry->node->next; // 后继节点
// 删除 ziplist 节点
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
iter->zi = NULL; // 防止野指针
if (deleted_node) { // 如果要删除的 ziplist 节点所在的 quicklistNode 被删除了
if (iter->direction == AL_START_HEAD) { // 如果迭代器的遍历方向是 head to tail
iter->current = next; // 更新迭代器的 current 字段
iter->offset = 0; // 更新迭代器的 offset 字段
} else if (iter->direction == AL_START_TAIL) { // 如果迭代器的遍历方向是 tail to head
iter->current = prev;
iter->offset = -1;
}
}
// 如果要删除的 ziplist 节点所在的 quicklistNode 没有被删除,就啥都不用动,很方便
/* else if (!deleted_node), no changes needed.
* we already reset iter->zi above, and the existing iter->offset
* doesn't move again because:
* - [1, 2, 3] => delete offset 1 => [1, 3]: next element still offset 1
* - [1, 2, 3] => delete offset 0 => [2, 3]: next element still offset 0
* if we deleted the last element at offet N and now
* length of this ziplist is N-1, the next call into
* quicklistNext() will jump to the next node. */
}
quicklistDelIndex
-
函数功能:删除
quicklist中一个quicklistNode的ziplist节点。 -
参数:
quicklist *quicklist:quicklist首地址。quicklistNode *node:quicklistNode首地址。unsigned char **p:要删除的ziplist节点首地址。至于为什么是二级指针?类比vector中删除元素迭代器失效的问题。
-
返回值:是否删除
ziplist所在的quicklistNode。1:删除了ziplist所在的quicklistNode。0:没有删除ziplist所在的quicklistNode。
REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,
unsigned char **p) {
int gone = 0;
node->zl = ziplistDelete(node->zl, p); // 删除 ziplist 中的一个节点
node->count--; // 当前 quicklistNode 的 ziplist 节点数量减 1
if (node->count == 0) { // 如果节点中没有 ziplist 节点了
gone = 1;
__quicklistDelNode(quicklist, node); // 删除这个 quicklistNode
} else {
quicklistNodeUpdateSz(node); // 更新 sz 字段
}
quicklist->count--; // quicklist 总的 ziplist 节点数量减
return gone ? 1 : 0; // 是否删除了 quicklistNode
}
编码
ziplist 由于结构紧凑,能高效使用内存, 所以在 Redis 中被广泛使用, 可用于保存用 户列表、散列、有序集合等数据。
列表类型只有一种编码格式 OBJ_ENCODING_ QUICKLIST,使用 quicklist 存储数据 ( redisObject.ptr 指向 quicklist 结构)。
总结
ziplist是一种结构紧凑的数据结构,使用一块完整内存存储链表的所有数据。ziplist内的元素支持不同的编码格式,以最大限度地节省内存。quicklist通过切 分ziplist来提高插入、删除元素等操作的性能。- 链表的编码格式只有
OBJ_ENCODING_ QUICKLIST。
















 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











