






一、简介
逻辑回归(Logistic Regression)是一种广泛应用于统计学和机器学习领域的分类方法,尤其在二分类问题中表现突出。它预测的是一个事件发生的概率,即模型的输出是一个介于0和1之间的值,通常这个输出被解释为属于某个类别的概率。
注意:逻辑回归虽然名字中有回归二字,但是它不是回归算法,而是分类算法。
二、基本原理
分类的本质:在空间中找到一个决策边界来完成分类的决策
逻辑回归:线性回归可以预测连续值,但是不能解决分类问题,我们需要根据预测的结果判定其属于正类还是负类。逻辑回归模型通过一个线性函数将特征变量的线性组合映射到一个S型曲线(sigmoid function)上,从而得到一个概率值。
逻辑回归在二分类问题上表现出色,对于处理二分类问题。由于分成两类,我们便让其中一类标签为0,另一类为1。因此我们需要一个函数,对于输入的每一组数据,都能映射成0~1之间的数。并且如果函数值大于0.5,就判定属于1,否则属于0。而且函数中需要待定参数,通过利用样本训练,使得这个参数能够对训练集中的数据有很准确的预测。
1.线性预测
一个二分类问题给的条件:分类标签Y {0,1},特征自变量X{x1,x2,……,xn},需要根据我们现在手头上有的特征X来判别它应该是属于哪个类别(0还是1),因此我们需要找一个模型,即一个关于X的函数来得出分类结果(0或1)。
如果数据是有两个指标,可以用平面的点来表示数据,其中一个指标为x轴,另一个为y轴;从本质上来说,逻辑回归训练后的模型是平面的一条直线(p=2),或是平面(p=3),超平面(p>3)。并且这条线或平面把空间中的散点分成两半,属于同一类的数据大多数分布在曲线或平面的同一侧。
逻辑回归中,我们先找一个线性模型来由X预测Y
但是很明显,这样的函数图像是类似一条斜线,使用线性的函数来拟合规律后取阈值的办法是行不通的,行不通的原因在于拟合的函数太直,离群值(也叫异常值)对结果的影响过大。
并且,线性模型也难以达到我们想要的二分类(0或1)的取值。
通过求出函数z,线性回归便完成了使用输入的特征矩阵X得到了一组连续型的标签值y_pred的操作,接下来我们需要让这条直线变弯,并且将其控制在0~1之间,将特征变量的线性组合映射到一个S型曲线(sigmoid function)上,从而得到一个概率值。
2.sigmoid函数
Sigmoid函数是一种广泛应用于逻辑回归中的数学函数,它将任意实数映射到(0, 1)区间内,使其成为表示概率的理想选择。在逻辑回归中,Sigmoid函数用于将线性回归模型的输出转换为概率形式。
Sigmoid函数的数学表达式通常写作:
特点
平滑曲线:Sigmoid函数是一个平滑的S型曲线,它在 𝑧接近正无穷时趋近于1,在 𝑧 接近负无穷时趋近于0。
连续性:Sigmoid函数在整个实数域上都是连续的,这使得它在数学处理和优化算法中非常有用。
非线性:尽管Sigmoid函数看起来像是线性函数的简单扩展,但它实际上是一个非线性函数,这使得它能够用于非线性回归和分类问题。
中心在(0, 0.5):Sigmoid函数的中心点在(0, 0.5),这意味着当输入 𝑧=0 时,输出为0.5。
单调递增:Sigmoid函数在其定义域内是单调递增的,即随着 𝑧 的增加,𝜎(𝑧) 也增加。
图像
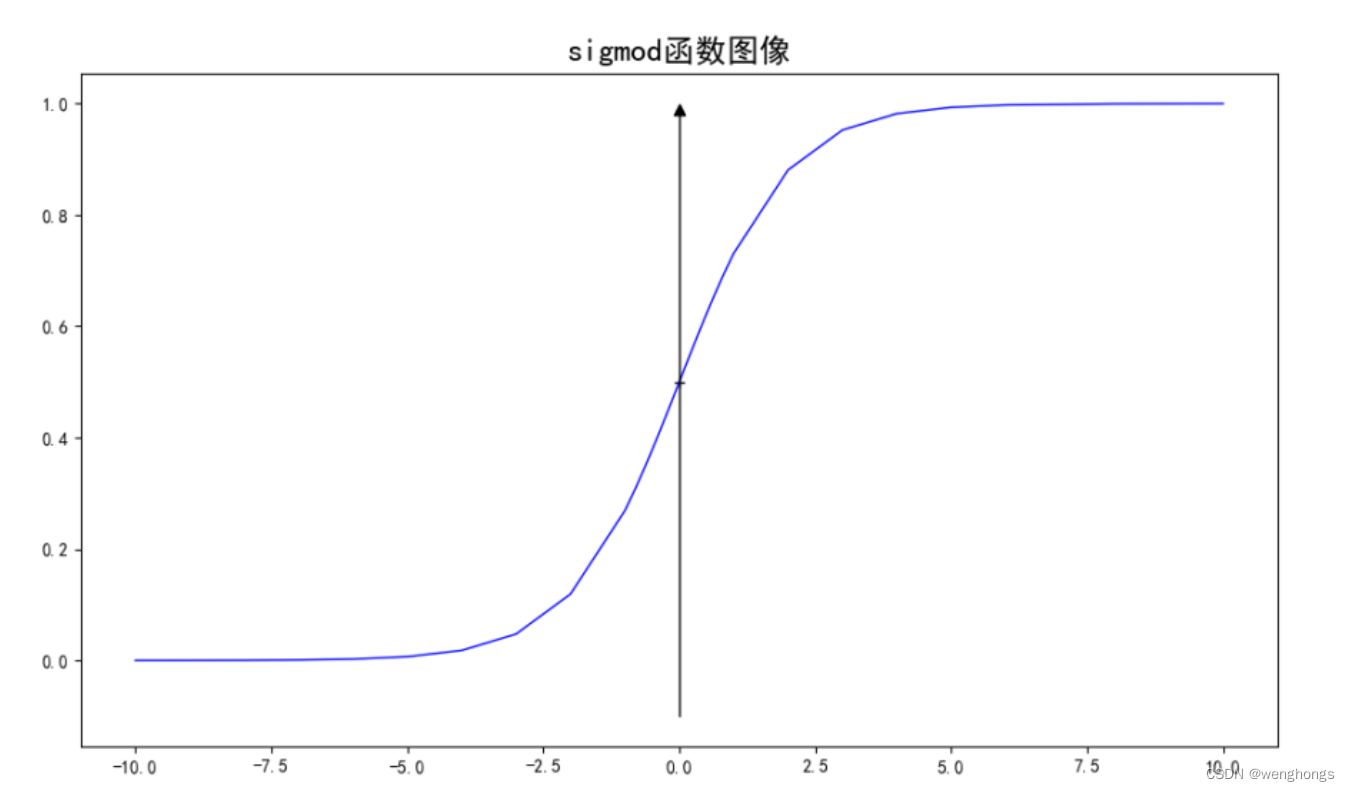
将线性模型的结果,投影到sigmoid函数上
![]()
三、求解参数
1.极大似然估计
极大似然估计是数理统计中参数估计的一种重要方法。其思想就是一个事件发生了,那么发生这个事件的概率就是最大的。对于样本i,其类别为。对于样本i,可以把看成是一种概率。yi对应是1时,概率是h(xi),即xi属于1的可能性;yi对应是0时,概率是1-h(xi),即xi属于0的可能性 。那么它构造极大似然函数
![]()
其中i从0到k是属于类别1的个数k,i从k+1到n是属于类别0的个数n-k。由于y是标签0或1,所以上面的式子也可以写成:
![]()
这样无论y是0还是1,其中始终有一项会变成0次方,也就是1,和第一个式子是等价的。
为了方便,我们对式子取对数。因为是求式子的最大值,可以转换成式子乘以负1,之后求最小值。同时对于n个数据,累加后值会很大,之后如果用梯度下降容易导致梯度爆炸。所以可以除以样本总数n。
![]()
求最小值方法很多,机器学习中常用梯度下降系列方法。也可以采用牛顿法,或是求导数为零时w的数值等。
2.梯度下降
梯度下降(Gradient Descent)是一种优化算法,用于最小化一个函数,通常用于机器学习中的参数优化问题。其基本思想是,从某个初始点开始,沿着函数的梯度(即导数)的反方向进行迭代搜索,每次迭代都会更新当前点的位置,直到找到一个局部最小值。如图,
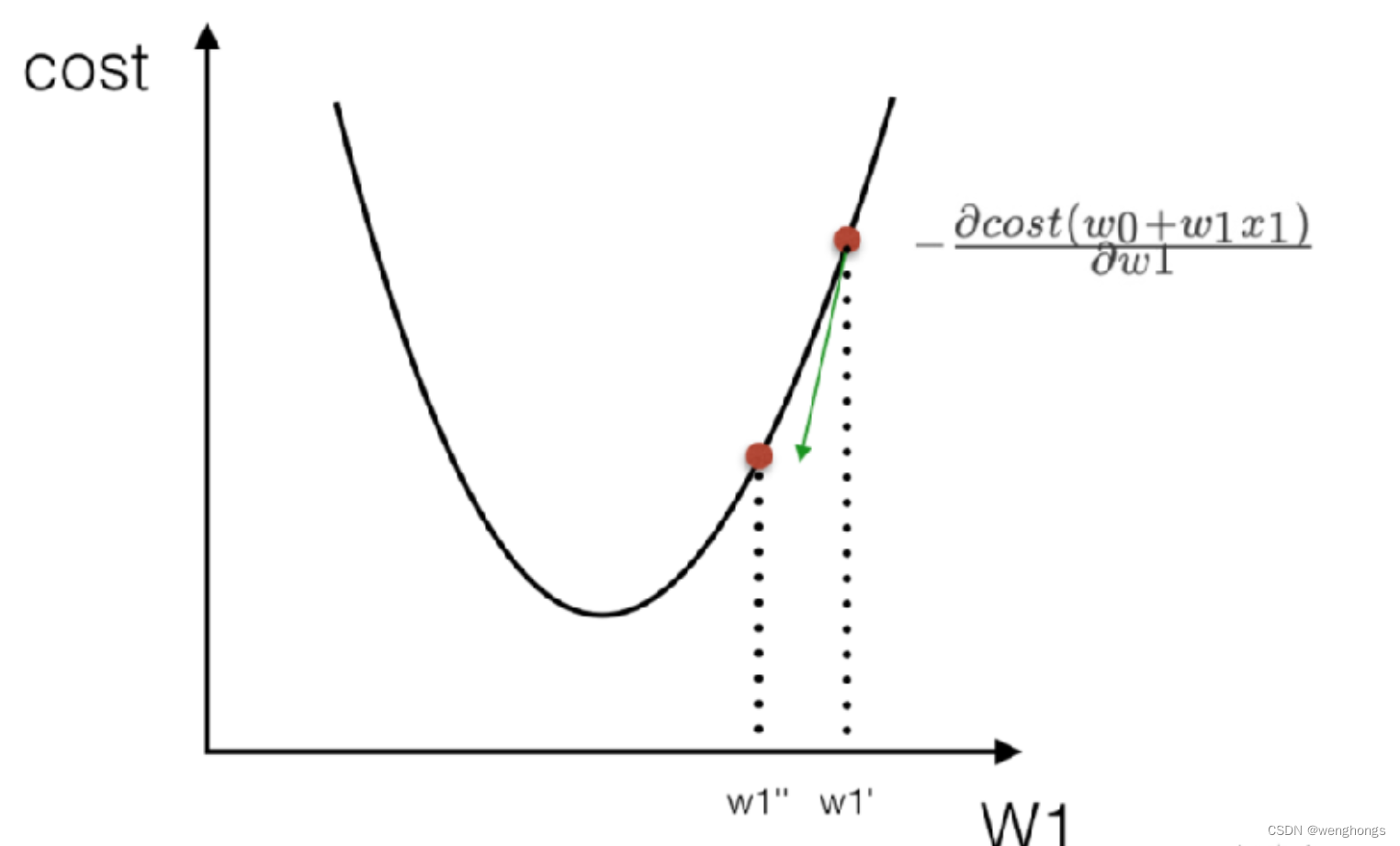
梯度下降算法的步骤通常包括:
- 初始化参数:选择一个初始点作为参数的起始值。
- 计算梯度:在当前参数的位置上计算目标函数的梯度,即导数。
- 更新参数:根据梯度和学习率(一个超参数,控制步长的大少)更新参数。
- 迭代:重复步骤2和3,直到满足停止条件,如梯度足够小、达到预定迭代次数或参数更新量很小。
四、代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 设置随机种子
seed_value = 2023
np.random.seed(seed_value)
# Sigmoid激活函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义逻辑回归算法
class LogisticRegression:
def __init__(self, learning_rate=0.003, iterations=100):
self.learning_rate = learning_rate # 学习率
self.iterations = iterations # 迭代次数
def fit(self, X, y):
# 初始化参数
self.weights = np.random.randn(X.shape[1])
self.bias = 0
# 梯度下降
for i in range(self.iterations):
# 计算sigmoid函数的预测值, y_hat = w * x + b
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
# 计算损失函数
loss = (-1 / len(X)) * np.sum(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
# 计算梯度
dw = (1 / len(X)) * np.dot(X.T, (y_hat - y))
db = (1 / len(X)) * np.sum(y_hat - y)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
# 打印损失函数值
if i % 10 == 0:
print(f"Loss after iteration {i}: {loss}")
# 预测
def predict(self, X):
y_hat = sigmoid(np.dot(X, self.weights) + self.bias)
y_hat[y_hat >= 0.5] = 1
y_hat[y_hat < 0.5] = 0
return y_hat
# 精度
def score(self, y_pred, y):
accuracy = (y_pred == y).sum() / len(y)
return accuracy
# 导入数据
iris = load_iris()
X = iris.data[:, :2]
y = (iris.target != 0) * 1
# 划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=seed_value)
# 训练模型
model = LogisticRegression(learning_rate=0.03, iterations=1000)
model.fit(X_train, y_train)
# 结果
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
score_train = model.score(y_train_pred, y_train)
score_test = model.score(y_test_pred, y_test)
print('训练集Accuracy: ', score_train)
print('测试集Accuracy: ', score_test)
# 可视化决策边界
x1_min, x1_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
x2_min, x2_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100), np.linspace(x2_min, x2_max, 100))
Z = model.predict(np.c_[xx1.ravel(), xx2.ravel()])
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")
plt.show()
















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









