






目录
- 视频出处:B站Frank
- 1. Academic
- 0-0.剖析数据结构的含义,数据结构的用途,区分数据结构与算法
- 1-0.内存,内存是如何保存不同数据类型的
- 1-1.int类型的范围是如何计算的?为什么会占用四个字节?四个字节为什么可以表示该范围?
- 2-0.Computational Analysis of algorithms计算机算法复杂度分析的基本含义
- 3-0.Big O notation复杂度标记符以及举例
- 3-1.复杂度对比函数图
- 4-0.Array
- 4-1.Static Array 复杂度分析
- 4-2.Dynamic Array扩容复杂度分析,剖析高级语言中的ArrayList原理,提及复杂度震荡的情况
- 5-0.Linked list与Singly linked list含义以及复杂度分析举例
- 5-1.Doubly linked list与Circular linked list含义以及复杂度分析举例
- 5-2.举例
- 6-0.Hash
- 6-1.Hash Table或Hash Map的原理与复杂度分析
- 7-0.Stack堆栈原理的实际用途与时间复杂度分析
- 8-0.Queue原理实际应用与时间复杂度分析(超简单)
- 9-0.Tree树的含义以及术语
视频出处:B站Frank
本篇为直面数据结构课程笔记(持续更新)
B站Frank
1. Academic

0-0.剖析数据结构的含义,数据结构的用途,区分数据结构与算法
- 数据结构(英语:Data Structure)是计算机中存储、组织数据的方式
上述关键词:1.数据 2.存储 3.组织
- 例如列表(List)是一种存储数据的方式
- 如下图所示,用于存储电话联系人的信息
| 电话联系人 |
|---|
| 张三 |
| 李四 |
| 王五 |
- 组织就是CRUD(增加Create、读取查询Retrieve、更新Update和删除Delete)例如添加电话联系人,查询电话联系人,修改电话联系人,删除电话联系人
综上,数据结构就是研究数据的存储和CRUD
但不同结构的CRUD是不相同的
- 如下图是一个快递柜,有行有列,看起来像一个“格子”,当然如果你学过语言,就会知道这个其实是二维数组
- [0][0]查询
- [0][0] = 0 ,[0][0] =1 修改
- 在动态数组中可增添容量(固定:静态数组,非固定:动态数组)
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 |
- 除此之外还有其他结构,如,队列,树,图,线性表(国际上其实不存在这个词,本质就是array数组)
数据结构和算法是两个完全不一样的东西
- 组织是数据结构中的一部分,算法则是研究组织数据结构的最优CRUD解,是研究如何高效、科学、优等组织,两者并不是从属关系、并列关系、相互影响的关系。
总结:
数据结构是研究有哪些组织的方式,在什么情况下怎么组织方式更好
算法的目的为了更好的组织数据结构
1-0.内存,内存是如何保存不同数据类型的
- 数据结构需要和内存进行串通,说白了数据结构接下来的内容都和内存息息相关
- 内存就是随机存取存储器(英语:Random Access Memony,缩写:RAM)是与CPU直接交换数据的内部存储器
内存条

- 内存就代表手机中的运行内存,如一个8 + 256G的手机,其中的8就是运行内存(后台和前台能同时运行多少APP)
- 在任务管理器中可以看到内存的实时状态

- 打开软件内存使用量就会增加,关闭就会减少

- 内存可以想象成一个巨大的网,可以理解为医院的住院部,每一个编号就代表每一个病房,住院部越大所能够容纳的病房就越多,相当于内存越大
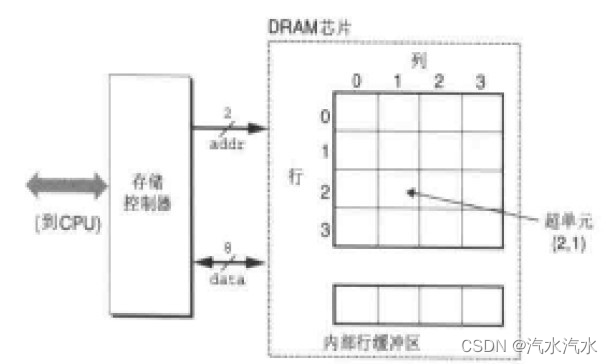
- 假设要存数字,int array = {1,2}(定义数组没写中括号,因为不同语言的定义不同)
- 第一个元素1,转换为二进制 0000 0001
- 为什么要写八位数字呢?因为计算机进行数据存储的基本单位是字节(byte),1 byte = 8 bit,最大能存入28
- int 类型大多数占四字节,在图中占四个格子,格子必须连续,就像同时有四个人一起来申请病房,并且还要求连号才可以,所以元素1的完整存储应该为0000 0000 0000 0000 0000 0000 0000 0001
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| 0000 0000 | 0000 0000 | 0000 0000 | 0000 0001 |
| 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 |
1-1.int类型的范围是如何计算的?为什么会占用四个字节?四个字节为什么可以表示该范围?
- int在不同的编程语言范围是不同的,在C/C++中取决于机器的字长(字长是CPU的主要技术指标之一,指的是CPU一次能并行处理的二进制位数)
- 32位的机器中,int类型是32位的,能表示232个数(包括正数和负数),一个字节占8位,4个字节占8*4=32位,所以int类型占用四个字节
- 同理在64位的机器中int类型是64位的,264,8*8=64,占八个字节
- Java中int类型也是32位的
- Python中int类型存储是无限的
2-0.Computational Analysis of algorithms计算机算法复杂度分析的基本含义
- 计算复杂性理论(Computational complexity theory)是理论计算机科学和数学的一个分支,它致力于将可计算问题根据它们本身的复杂性分类,以及将这些类别联系起来。一个可计算问题被认为是一个原则上可以用计算机解决的问题,亦即这个问题可以用一系列机械的数学步骤解决,例如算法。
- 算法复杂性分析(Algorithm complexity analysis)主要是针对运行该算法所需要的计算机资源的多少。当算法所需要的资源越多,该算法的复杂性越高;反之,当算法所需要的资源越少,算法的复杂性越低。
这里主要理解接下来的算法分析

- 算法分析(Analysis of algorithms)是对一个算法需要多少计算时间和存储空间作定量的分析。 算法(Algorithm)是解题的步骤,可以把算法定义成解一确定类问题的任意一种特殊的方法。在计算机科学中,算法要用计算机算法语言描述,算法代表用计算机解一类问题的精确、有效的方法
- 假设在上图中有三条路径去往downtown,怎么去选择一个最好的路径呢,我们要考虑两个为问题,一个是所消耗的时间,一个是所消耗的资源,两者都是有限度的并且取决于个人的条件,这就是复杂度分析(时间,资源)
我们再将这个案例放入内存概念中 - 时间指CRUD的速度,如要想将一个数组存入内存中,如何更快、更高效的做到呢
- 资源指内存的空间大小8G,16G,32G
- 相对于时间,我们称为时间复杂度
- 相对于资源,我们称为空间复杂度
- 时间复杂度和空间复杂度是数据结构与算法决定的
3-0.Big O notation复杂度标记符以及举例
- arr = [0,1,2,……,x]对这个数组进行CRUD,如arr [0] = 1
- 查找单个元素的值 arr[?],时间复杂度就是O(1),引入上述的病房案例,假设要查找6号病房病人的信息,马上就能得到它的数据,这个速度是一瞬间的,我们不需要考虑6号病房的人是谁,不管病房有多少,我们都可以直接通过病房号找到对应的信息
- 数组求和,将数组中每一个数据相加(数组遍历),时间复杂度就是O(n),医院每天早晨都要查房,医生要将每个病房的病人都要问一遍,有多少个病房就要问多少遍
- 当遍历一个一维数组时间复杂度为O(n),遍历一个二位数组就是O(n2)(遍历一维数组需要一个循环,遍历二位数组需要两个循环)
- 我们主要讨论时间复杂度,而不太关注空间复杂度
3-1.复杂度对比函数图

4-0.Array
-
其实在数据结构中并不存在线性表这个词,只是国内翻译为线性表(Linear List)
-
Linear List 在国际上不存在,它实际包含了Array和Linked List,而这个词(Linear List)的来源是这个两个数据结构,是两者的统筹
-
在维基百科是搜不到这个词的
但是会有Linear,Linked List,Array -
Linear
-
Linked List

-
Array

-
数据结构这个门课的目的不仅仅是要告诉我们有哪些数据结构,还要告诉我们数据结构的特点,以及他们背后的逻辑,还要分析时间和空间复杂度
-
我们需要了解数组,以及时间和空间复杂度,在内存中是怎样的
-
数组的下标是从0开始的,但是在某些语言是从1开始的,如Pascal,Delphi,这同样可以说明数据结构和语言没有关系
-
要定义一个int类型的数组(32位),int arr -> [1,2,3,4]
-
这个数组在创建的时候,它在内存中是怎样的,它是怎么存储的,以及插入,修改,删除的时候会发生什么变化,还要分析它CURD的时间复杂度和空间复杂度
-
首先分析数组是怎么插入到内存里的,我们需要找一块内容(必须是连在一起的)16个格子(一个格子八位数,32位每个数需要4个格子,总共4位数,需要16个格子),将数组中的数以二进制的形式(0000 0000 0000 0000 0000 0000 0000 0001,0000 0000 0000 0000 0000 0000 0000 0002……)存入内存中
-
比如我们要访问arr[0],首先要找到aar[0]的地址,再直接获取到数值
-
arr[1],我们只需要在arr[0]的地址加上4就行了
-
当查询数组中的某个值,只需要计算初始值的add + sizeof * n
4-1.Static Array 复杂度分析
- 一个数组[1,2,3,4]

- 通过index查询,时间复杂度O(1),arr[1] = 2
- 通过index修改,时间复杂度O(1),arr[1] = 6 -> [1,6,3,4]
- 数组无论如何都不能直接插入数据,数组内存地址是连续的,无法在内部分配空间,在数组前面和后面的内存也可能已经被占用了
- 想要打破这个规则,就需要重新找到新的区域,copy这份数组进行插入处理,再放入到更大的区域中,所以不管插入位置在哪,时间复杂度都是O(n)
- 但在不同的情况下,空间复杂度会有所不同,所以我们不考虑空间复杂度,我们先分析时间复杂度,当空间复杂度成为一个问题的时候我们才会考虑它
- 如果删除末尾元素,时间复杂度O(1),删除4的时候,并不会影响到1、2、3,它们的地址仍然是连续的
- 如果删除了1,有人会认为是时间复杂度是O(1),但其实是O(n),为什么呢?这是因为当删除了1,后面的2、3、4都需要往前挪动,将前面的内存补满
- 以上讲的就是静态数组,static array
4-2.Dynamic Array扩容复杂度分析,剖析高级语言中的ArrayList原理,提及复杂度震荡的情况
- 静态数组,是连续静态的、不可扩充的,若想要扩充大小,必须要copy一份,这时时间复杂度就为O(n)了
- 动态数组可以扩容,但不是扩容一个空间,而是扩容原来的一倍
[1,2,3,-,-,-],时间复杂度为O(1) O(1) O(1) O(n) O(1) O(1)
| 1 | 2 | 3 | - | - | - |
|---|---|---|---|---|---|
| O(1) | O(1) | O(1) | O(n) | O(1) | O(1) |
[1,2,3,4,5,6,-,-,-,-,-,-],时间复杂度为O(1) O(1) O(1) O(1) O(1) O(1) O(n) O(1) O(1) O(1) O(1) O(1)
| 1 | 2 | 3 | 4 | 5 | 6 | - | - | - | - | - | - |
|---|---|---|---|---|---|---|---|---|---|---|---|
| O(1) | O(1) | O(1) | O(1) | O(1) | O(1) | O(n) | O(1) | O(1) | O(1) | O(1) | O(1) |
- 当这个数越来越大趋向于N的时候,这个n的数就可以忽略不计
- 1+2+4+8+16+…+N
- O(1)+O(2)+O(4)+…+O(N),时间复杂度为O(n)
- N+N/2+N+4+…+1,级数收敛为2N

- 平坦分析,考虑一个随元素个数增加而增长的动态数组,比如Java的ArrayList或者C++的std::vector

- 扩容和缩容用的是同样的原理,就会出现复杂度震荡,每一次都会耗费O(n)的复杂度
5-0.Linked list与Singly linked list含义以及复杂度分析举例
- 在32位,int占用4字节,假设这里的每个格子抵4字节
- 将要存入一个数组[1,2,3,4],但是这里的内存并不连续(x表示已占用),没法创建一个这样的数组

- 那么可以使用下面的形式来存储数据

- 在数组中可以通过计算得到地址,但是在这种情况就不行了,所以需要记录位置以便访问
- 可以在前面一块区域存储数据,在下一个区域存储下一个位置
- 链表要开辟两块区域,值和下一个值的地址
- 如上图这样的,箭头指向一个方向的,就是单链表
- 1->2->3->4,开始的地方叫头节点,每一部分叫节点(node)

- 访问头部O(1),尾部O(n),中间的任意值O(n)
- 在头部插入O(1),1->2->3->4 =》0->1->2->3->4
- 在尾部插入O(n),需要先遍历到尾部再进行插入1->2->3->4=》1->2->3->4->5
- 在中间插入O(n),依然需要遍历找到指定位置1->2->3->4=》1->2->5->3->4
- 头部删除O(1),尾部删除O(n),中间删除O(n)
- 优点:插入和删除操作比较高效,因为在链表中进行这些操作只需要改变指针指向;链表大小可以动态扩展或缩小,因为每个节点只占用必要的内存空间;链表的元素可以在不同的内存位置上,不需要连续的内存空间
- 缺点:随机访问元素比较低效,因为在链表中访问元素需要从头开始遍历链表;链表占用的内存空间比数组多,因为每个节点都需要额外的指针来指向下一个节点
5-1.Doubly linked list与Circular linked list含义以及复杂度分析举例
-
单向链表只有一个指针

-
双向链表有两个指针


-
访问头部O(1),尾部O(1),中间O(n)
-
在头部或尾部插入O(1)
-
删除头部或尾部O(1)
-
中间插入和删除O(n)
-
搜索O(n)
-
双向链表在内存中的表示是这样的,并不是prev在最前面

-
双向链表的优点:
双向链表可以双向遍历,即从头到尾或者从尾到头遍历链表,这使得一些操作比单向链表更加高效;双向链表可以支持双向删除,即在已知某个节点的情况下,可以直接删除该节点,而无需像单向链表一样需要遍历查找该节点的前驱节点进行删除 -
双向链表的缺点:双向链表需要额外的空间存储指向前驱节点的指针,因此比单向链表更加占用空间;在插入和删除操作时需要维护前驱节点和后继节点的指针关系,因此需要更多的操作步骤和时间复杂度
循环链表

- 循环链表的优点:循环链表可以使得链表的首尾相连,这使得在某些场景下更加方便,比如轮询操作;循环链表可以避免遍历到链表末尾时需要重新从头开始遍历的情况,因为链表的末尾指向头节点
- 循环链表的缺点:循环链表的插入和删除操作相对于单向链表和双向链表更加复杂,因为需要处理头尾节点的指针关系;循环链表的遍历操作需要额外的判断条件来避免死循环的情况,因此可能会增加代码的复杂度
5-2.举例
- 链表会和栈和队列结合进行实际应用
- 在网页中会有前进和后退按钮,这实际上就是一个双向链表


- 播放列表也是可以用链表实现

6-0.Hash
-
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种数据的伪装

-
一个数x1,进行了计算后得到了y1,过程就是Hash function,结果称为Hash sum

-
例如(Are you kidding me)这个明文,通过相加字符的ASCII码,得到密文,这种加密的方式是由自己决定的
-
再例如(1 2 3 4 5)这个明文通过+1的方式进行加密,就得到了(2 3 4 5 6)这个密文
-
这种计算的方法叫Hash function,加密出来的内容叫密文,Hash function叫密钥
-
123 通过function可以查到 456,但是456无法通过fuction反推导出123,这种称为单向散列函数
-
这是因为单向散列函数是一种单向函数,它只能从输入计算出输出,而不能从输出计算出输入。这种单向性使得单向散列函数在密码学中非常有用,例如在密码存储和数字签名中

-
Hash碰撞是指两个不同的输入值在经过哈希函数计算后得到相同的输出值
-
例如,123 通过计算得到 456,789 通过计算得到 456,两串不同的数进行Hash function后得到了相同的数,这种就称为哈希碰撞
-
md5被破解是因为知道了function是什么,是怎么进行加密的
-
下载的iso镜像文件,会进行sha验证,算出的Hash sum 和官网一致就会发生碰撞,说明下载没问题
-
验证文件完整,网盘的秒传,都是哈希碰撞

6-1.Hash Table或Hash Map的原理与复杂度分析
- Hash map 是一种数据结构

- hello ->function-> addr
- hello通过一种计算(不用管是什么计算)得到地址,从而得到地址内的值
- 在高级语言中是==<key,value>==显示
- key通过计算得出addr地址,再将value存入,当下次需要查询value值,只需通过key计算就可以了,这种查询类似于index的查询,甚至比index更快,查询的速度取决于function的计算方式

- key1->function->value1,key2->function->value1,不同的key计算出相同的value,即发生哈希碰撞
- 发生哈希碰撞,可以使用链表将不同的数据分别存入

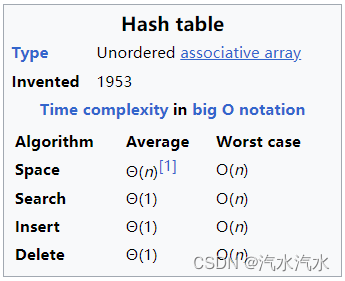
- Hash table的CRUD时间复杂度如下图,平均时间复杂度基本上都是O(1)
- 在最坏的情况下为什么都是O(n)呢,这跟发生哈希碰撞有关,发生哈希碰撞后我们需要创建链表,使得时间复杂度和链表时间复杂度类似
7-0.Stack堆栈原理的实际用途与时间复杂度分析
- 堆栈(stack)又称为栈或堆叠,是计算机科学中的一种抽象资料类型,只允许在有序的线性资料集合的一端(称为堆栈顶端,top)进行加入数据(push)和移除数据(pop)的运算。因而按照后进先出==(LIFO, Last In First Out)==的原理运作,堆栈常用一维数组或链表来实现。常与另一种有序的线性资料集合队列相提并论。

- 往上放盘子叫push,拿走盘子叫pop
- 不能直接拿最下的盘子,不然上面的盘子就会掉下来
- 最后进来的可以先出去,最先叠的盘子可以先被拿走
- 栈是先进后出的

- windows+v是剪切板

- 依次复制1,2,3,4,5,最后拷贝的在最上面,这就是栈的实际运用
- 类似的还有撤销功能,IDE的括号匹配,浏览器的历史记录
- 栈可以用数组实现
- [1,2,3]可以是个栈,但是栈必须从后面添加,从后面删除
- 栈的push和pop时间复杂度都是O(1)
- 查栈顶O(1),查中间O(n)
8-0.Queue原理实际应用与时间复杂度分析(超简单)
- 队列,又称为伫列(queue),计算机科学中的一种抽象资料类型,是先进先出(FIFO, First-In-First-Out)的线性表。在具体应用中通常用链表或者数组来实现。队列只允许在后端(称为rear)进行插入操作,在前端(称为front)进行删除操作

- 队列其实就是排队
- 队列是先进先出(栈是先进后出)

- 队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加(只允许删除最前面,追加后面的)
- 队列用链表来处理比较常见
- 不同的存储方法(数组和链表)时间复杂度会不一样

操作系统进程管理
- 操作系统维护了一组队列,表示系统中所有进程的当前状态。每个进程的PCB都根据它的状态加入到相应的队列中,当一个进程的状态发生变化时,它的PCB从一个状态队列中脱离出来,加入到另一个队列
缓存网络数据包
- 在 Linux 系统中,当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中。这个收包队列是一个先进先出(FIFO)的数据结构,它能够确保网络数据包按照到达的顺序进行处理
9-0.Tree树的含义以及术语
- 树是一种非线性数据结构,其中数据按照层级结构进行组织。它由一组节点连接而成,每个节点通过边或链接连接,其中每个节点可以具有零个或多个子节点,除根节点外,每个节点都有一个父节点。树结构通常用于表示分层数据,例如文件系统,XML文档,数据库等等

- 树就像是一个家谱
- root是根(树的根)
- p->q,q->a 是边(edge)
- a,b是siblings(兄弟),
- 这里每一个圆被称为节点
- parent 父节点,children 孩子节点
- subtree 相对于a的子树(e,f,g)
- leaf nodes 叶节点(最后一批的节点)
- 深度(高度从上往下数),高度(从下往上数 )














 1415
1415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









