






由于做模糊数学代码实现的博主太少,导致大学生们面对作业痛苦不堪,现在我准备将我的作业开放给大家参考。如果你觉得这个博文还不错的话,请点点赞支持一下~
层次聚类(Hierarchical Clustering)是一种常用的数据分析方法,它通过计算数据点之间的相似度来构建一个层次结构的聚类树。在层次聚类中,数据被分为不同的层次,从而形成一个由细到粗的聚类结构。这种方法不需要预先指定聚类的数量,而是生成一棵树状图(称为树状图或层次图),通过树状图可以观察数据点之间的层次关系。
层次聚类主要有两种策略:
-
凝聚方法(Agglomerative):这是一种自底向上的方法,开始时每个数据点都被视为一个单独的聚类,然后算法逐步找到最相似的聚类对并将它们合并,这个过程一直持续到所有数据点都被合并到一个聚类中,或者达到某个终止条件。
-
分裂方法(Divisive):与凝聚方法相反,分裂方法是自顶向下的。最开始将所有数据点视为一个大的聚类,然后逐步将聚类分裂成更小的聚类,直到每个数据点都是一个单独的聚类,或者达到某个终止条件。
想象你要为一群人组织一场派对,但是你希望每个人都能找到志同道合的朋友。你手头有一份客人名单,但是你不知道他们之间的关系。
在凝聚层次聚类中,你会这样开始:每个人最初都是自己一个小团体,就像每个人都独自站在派对的角落。然后,你开始观察,找出两个最有可能成为朋友的人,让他们一起聊天。如果他们聊得来,就把他们放在一起,形成一个小团体。接下来,你再找下一对可能的朋友,重复这个过程。随着时间的推移,这些小团体会逐渐合并成更大的团体,直到最后,可能所有的人都聚在一起,或者形成几个大团体,每个团体都有共同的兴趣和话题。
而在分裂层次聚类中,情况正好相反。你开始时把所有人都放在一个大团体里,就像是派对开始时大家都聚在一起。但是你注意到,不是所有人都在积极交谈。于是,你开始将那些不太参与的人分出去,让他们形成一个新的小团体。这个过程一直持续,直到每个人都找到了最适合自己的小团体。
在层次聚类中,聚类之间的距离可以通过多种方式来计算,例如最小距离、最大距离、平均距离等。选择不同的距离计算方法会影响聚类的结果。
层次聚类的优点包括:
- 不需要预先指定聚类数目。
- 能够发现数据的层次结构。
- 可以处理非球形的聚类。
缺点则包括:
- 计算复杂度较高,尤其是在数据量大的情况下。
- 对噪声和异常值比较敏感。
- 一旦合并或分裂,就不能调整。
可视化效果图:
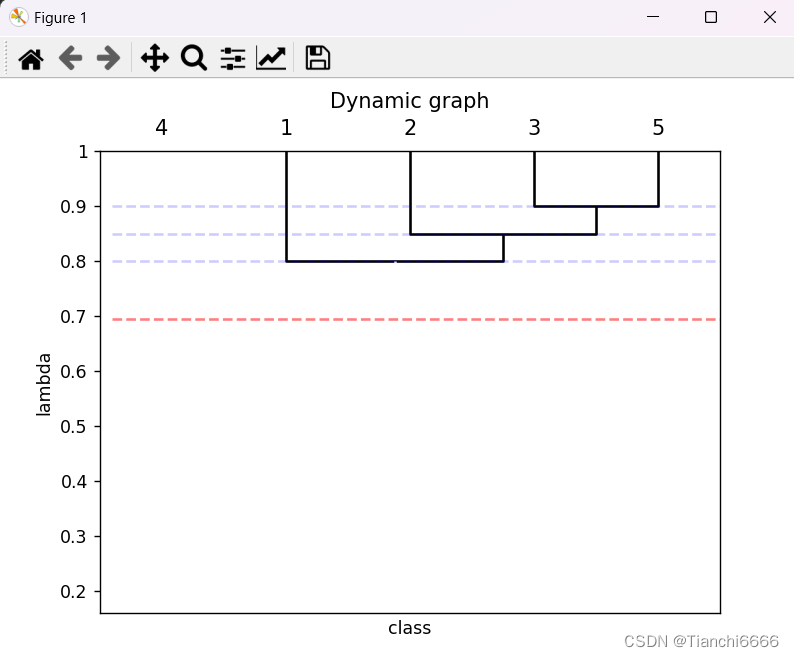
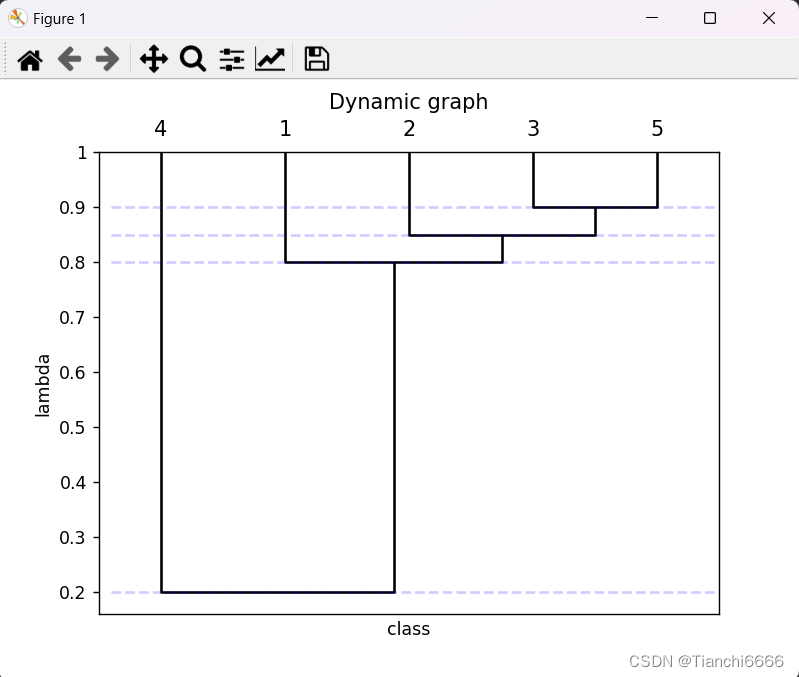
import numpy as np
import warnings
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from matplotlib.animation import FuncAnimation
warnings.filterwarnings("ignore")
# 定义F相似矩阵
matrix = np.array([[1, 0.4, 0.8, 0.5, 0.5],
[0.4, 1, 0.4, 0.4, 0.4],
[0.8, 0.4, 1, 0.5, 0.5],
[0.5, 0.4, 0.5, 1, 0.6],
[0.5, 0.4, 0.5, 0.6, 1]])
matrix = np.array([[1, 0.8, 0.6, 0.1, 0.2],
[0.8, 1, 0.8, 0.2, 0.85],
[0.6, 0.8, 1, 0, 0.9],
[0.1, 0.2, 0, 1, 0.1],
[0.2, 0.85, 0.9, 0.1, 1]])
# 平方法求传递闭包
def get_tR(r_matrix):
rows = r_matrix.shape[0] # 矩阵的行数
cols = r_matrix.shape[1] # 矩阵的列数
min_list = [] # 存储每次比较的最小值
new_mat = np.zeros((rows, cols), dtype='float') # 初始化新矩阵
for m in range(rows):
for n in range(cols):
min_list = [] # 清空最小值列表
now_row = r_matrix[m] # 当前行
for k in range(len(now_row)):
# 先取小,再取大
min_cell = min(r_matrix[m][k], r_matrix[:, n][k]) # 先取小
min_list.append(min_cell) # 添加到最小值列表
new_mat[m][n] = max(min_list) # 再取大,并赋值给新矩阵
return new_mat
# 求传递闭包矩阵T
t_r_matrix = matrix # 初始化T为F相似矩阵
i = 0 # 记录迭代次数
while True:
t_r_matrix = get_tR(t_r_matrix) # 对T进行平方法求传递闭包
if (t_r_matrix == matrix).all(): # 如果T不变,则停止迭代
break
else: # 否则更新T为新矩阵,并继续迭代
matrix = t_r_matrix
i = i + 1
# 求lambda值列表L
lambda_list = [] # 初始化L为空列表
for i in range(t_r_matrix.shape[0]):
for j in range(t_r_matrix.shape[1]):
lambda_list.append(t_r_matrix[i][j]) # 提取T中的所有元素到L中
lambda_list = list(set(lambda_list)) # 去重
lambda_list.sort() # 排序
# 403
# 按lambda截集进行动态聚类
def lambda_clustering(t_r_matrix):
rows = t_r_matrix.shape[0] # 矩阵的行数
cols = t_r_matrix.shape[1] # 矩阵的列数
result = [] # 返回的结果,存储每个lambda值对应的聚类结果和类别数目
# aa=[]
for i in range(len(lambda_list)): # 遍历每个lambda值
i = len(lambda_list) - i - 1
temp_matrix = np.zeros((rows, cols), dtype='float') # 初始化一个0-1矩阵
class_list = [] # 存储当前lambda值的聚类结果
mark_list = [] # 存储当前lambda值已经被分组的样本
for m in range(rows):
for n in range(cols):
if t_r_matrix[m][n] >= lambda_list[i]: # 如果T中的元素大于等于lambda值,则赋值为1
temp_matrix[m][n] = 1
# 对0-1矩阵进行行比较,得到聚类结果
for m in range(rows):
if (m + 1) in mark_list: # 如果当前样本已经被分组,则跳过
continue
now_class = [] # 存储当前样本所在的类别
now_class.append(m + 1) # 添加当前样本到类别中
mark_list.append(m + 1) # 添加当前样本到已分组的样本中
for n in range(m + 1, rows):
if (temp_matrix[m] == temp_matrix[n]).all(): # 如果两行相等,则表示两个样本属于同一类别
now_class.append(n + 1) # 添加另一个样本到类别中
mark_list.append(n + 1) # 添加另一个样本到已分组的样本中
# aa.append(mark_list)
class_list.append(now_class) # 添加当前类别到聚类结果中
# if mark_list not in aa:
# print(f"mark_list:{mark_list}")
# print(f"aa:{aa}")
result.append([lambda_list[i], class_list, len(class_list)]) # 添加当前lambda值对应的聚类结果和类别数目到结果中
return result
# 调用函数,得到动态聚类结果
result = lambda_clustering(t_r_matrix)
print(result)
# print(bb)
# 打印动态聚类结果
for item in result:
print(f"lambda = {item[0]}, 聚类结果为 {item[1]}, 可分为 {item[2]} 类")
lambda_list2 = []
new_label = []
x_label = result[-1][1][0].copy()
len_class = len(result[0][1])
for i in result:
if i != result[0]:
lambda_list2.append(i[0])
v = 0.01
# 提取聚类结果中,聚类的顺序bb
group = [i[1] for i in result]
aa = [[i] for i in x_label]
bb = []
for i in group:
for j in i:
if j not in aa:
bb.append(j)
aa.append(j)
# 复制原始bb
bb2 = []
for i in bb:
bb2.append([j for j in i])
# 将聚类后的元素序号做成一个字典
max_label = max(x_label) + 1
dict1 = {}
for i in range(len(bb)):
dict1[i] = max_label
max_label = max_label + 1
# 由bb构建一个Z矩阵
for i in range(len(bb)):
for j in range(i):
if bb[j][0] in bb[i]:
for h in bb[j]:
if h in bb[i]:
bb[i].remove(h)
bb[i].append(dict1[j])
Z = []
for i, b, l in zip(bb, lambda_list2, bb2):
guodu = []
for j in i:
guodu.append(float(j - 1))
guodu.append(float('%.2f' % (1 - b)))
guodu.append(float(len(l)))
Z.append(guodu)
# 自定义颜色函数
def color_func(k, threshold, size):
if Z[k - size][2] < threshold:
return 'black'
else:
return 'w'
# 创建一个空白图形
fig, ax = plt.subplots()
# 定义更新函数
def update(frame):
ax.clear()
threshold = frame
dendrogram(Z, labels=np.arange(1, len(x_label) + 1), orientation='bottom', above_threshold_color='w', color_threshold=threshold,
link_color_func=lambda k: color_func(k, threshold, len(x_label)))
for i in lambda_list2:
if frame >= 1 - i:
ax.plot([1, 60], [1 - i, 1 - i], linestyle='--', color='b', alpha=0.2)
ax.set_yticklabels([1, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2])
ax.plot([1, 60], [frame, frame], linestyle='--', color='r', alpha=0.5)
ax.set_xlabel('class')
ax.set_ylabel('lambda')
ax.set_title(f'Dynamic graph')
# 创建动画
thresholds = np.linspace(0, 1, 50) # 生成0到1的阈值范围
ani = FuncAnimation(fig, update, frames=thresholds, repeat=False)
ani.save('dynamic_animation2.gif', writer='pillow')
plt.show()















 2429
2429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









