






层次聚类函数AgglomerativeClustering()
我们主要来讲解层次聚类的可视化画图和层次聚类后返回的children_属性,children_属性的理解需要借助可视化图形
1.层次聚类的可视化画图
1.1步骤:
step1:使用 make _ classification()函数创建一个二分类测试数据集
import numpy as np
from scipy.cluster.hierarchy import dendrogram
from sklearn.cluster import AgglomerativeClustering
X, _ = make_classification(n_samples=5, n_features=2, n_informative=2,
n_redundant=0, n_clusters_per_class=1, random_state=4)
step2:写plot_dendrogram函数,主要功能是计算linkage_matrix,作为用来画树状图的函数dendrogram()中的传入参数
def plot_dendrogram(model, **kwargs):
# 创建链接矩阵,然后绘制树状图
# 创建每个节点的样本计数
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # 叶子节点
else:
current_count += counts[child_idx-n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([model.children_, model.distances_,
counts]).astype(float)
print(linkage_matrix)
# 绘制相应的树状图
dendrogram(linkage_matrix, **kwargs)step3:定义层次分类算法,并训练,然后调用plot_dendrogram(model, truncate_mode='level', p=3)进行画图
# 设置 distance_threshold = 0 ,以确保我们计算的是完整的树
model = AgglomerativeClustering(distance_threshold=0, n_clusters=None)
model = model.fit(X)
plt.title('Hierarchical Clustering Dendrogram')
# 绘制树状图的前三个级别
plot_dendrogram(model, truncate_mode='level', p=3)
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.show()1.2 结果
由于make _ classification()创建数据集的时候只创建了5个数据,比较简单,层次分类树状图的结果如下:
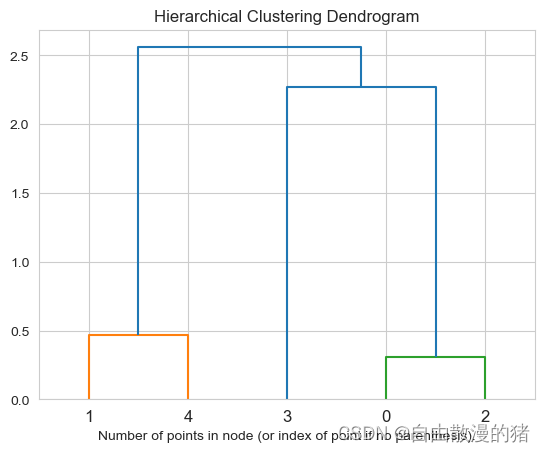
另外我在定义plot_dendrogram函数时,使用print(linkage_matrix)输出了用于画图的参数linkage_matrix,我们来看看这个值等于多少?
linkage_matrix=:
[[0. 2. 0.30715513 2. ] [1. 4. 0.47108264 2. ] [3. 5. 2.27391048 3. ] [6. 7. 2.55945507 5. ]]
以上就是结果,树形图两两相连就是两个点归一个类的意思,比如第0和第2个样本点归到一类,下一次迭代中第3个样本点加入了他们,和他们成为一类
2.children_属性的理解
仔细的朋友一定看到了,linkage_matrix是一个矩阵,如上,那么怎么来理解这个矩阵呢?从代码可以看出,这个矩阵由model.children_, model.distances_和 counts构成,
linkage_matrix = np.column_stack([model.children_, model.distances_, counts]).astype(float)我们依次来解释:
(1)model.children_:最难懂,如果单独输出model.children_,我们来看看是什么样子
array([[0, 2],
[1, 4],
[3, 5],
[6, 7]], dtype=int64)
英文的解释是这样的:

可以看到,如果[值1,值2 ]中的值小于样本数量,那表示他是叶子节点,也就是原始样本,之前没有参加过归类,数值代表原始样本的索引,如果大于或等于样本数量,那表示他不是叶子节点,他有下游子节点,也就是他是已经归类的结果,下游子节点可通过children_[值-样本数量]找到。
那么model.children_中的值可以看作每次合并成一类的动作,n个样本如果最终全部合并成一类,要经历n-1步。这里5个样本,全部合并成一类要经历4步,所以children_有4行,即4个合并步骤。
下面我们用例子来进一步解释(可以结合上文可视化图看):
本次案例中样本数n_samples=5
- [0,2]:都小于n_samples,那么都是叶子节点,之前没有归过类,所以直接第0,2样本归一类
- [1,4]:都小于n_samples,那么都是叶子节点,之前没有归过类,所以直接第1,4样本归一类
1.2结果图中清晰可见,0—2,1—4相连
- [3,5]:两个值和n_samples比大小,第一个值3<5 , 意思是第3个样本是叶子节点,之前没有归过类;第二个值5>=5,意思是他已经归过类,包含一部分节点,这个类位置在children_[5-5]=children_[0],即[0,2]。这一步就是把第3个样本和[0,2]归成一类。
1.2结果图中清晰可见,3与(0—2)相连
- [6,7]:两个值和n_samples比大小,两个值都大于等于n_samples,那么这次归并是两个已经归过类的类,归成一类,这两个类的位置在children_[6-5]=children_[1]和children_[7-5]=children_[2],即[1,4] 、[3,5]。这一步就是把[1,4] 、[3,5]归成一类
1.2结果图中清晰可见,(1—4)与(3—5(0—2))相连
综上来说,实际上children_ 的[ ]内的两个数值,可以理解为两个类归为一类的过程,每一个数字可以代表从没有归过类的叶子节点,也可以代表已经归过类的一个类
(2)model.distances_
顾名思义,是距离,两个类归为一类的时候,两个类之间的距离,例如:[0. 2. 0.30715513 2. ] ,0.30715513就代表第0,2样本之间的距离,再例如:[6. 7. 2.55945507 5. ],2.55945507就代表 (1,4 )和 (3 ,0 ,2)两个类之间的距离
顺便说一句,这里的距离计算方式有很多,看选择,例如可以质心、重心、均值等
(3)counts
这个是用代码敲出来计算的,计算的是两个类合并成一类后,包含多少节点,例如:[0. 2. 0.30715513 2. ],2.就代表第0 和2个样本合并后的类包含2个节点,再例如:[6. 7. 2.55945507 5. ],5.就代表(1,4 )和 (3 ,0 ,2)两个类合并成一个类后包含5个节点(样本点)
讲的还算清晰吧,当然linkage_matrix矩阵可以直接求(用某个函数),但是我对比了,其中代表children_这个属性的值理解和直接求model.children_的值再拼接有一点出入,查找子节点类别的时候,children_[值-样本数量-1] 而不是children_[值-样本数量]















 1583
1583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









