






大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
预训练RoBERTa笔记
为什么预训练?
这里使用一个比较形象的比喻:大模型(model)在它被实例化的瞬间,他就如同一个宝宝出生了!但是他的权重参数全部都是随机值。以至于你和宝宝(model)对话时,他会胡言乱语,哇哇大叫。

所以我们需要去对宝宝(model)进行训练,让他可以明白我们话语的意思,且做出正确的回复。
那怎么去调教一个宝宝(model) 呢?你总不能直接叫3岁的他直接去写代码吧。他都不知道你在嗦什么呢!

直接给答案:
模型训练:
1. 预训练(学习语义,它得知道你在说什么,弄懂是啥意思)
2. 指令微调(对于你说出的指令,可以做出好的回应,比如你叫他去唱、跳、rap、打篮球。它真就去做了,还做得很好。)
3. 强化学习(尽管宝宝已经长大为成人了,尽管你随我的指令完成得很好。但…我不喜欢你的语气,你像一个机器人,没有情感!我不爱你!我希望你说话更像人类!或者我温柔的女友,当然这也不是必要的啦hhh)
所以预训练的目的在于:让模型理解语义!
怎么预训练
每一个基于transformer衍生出的架构都有不同。
Bert模型基于原始encoder的自注意力区域进行了掩码的改进,RoBERTa又基于Bert再次做了创新。
我们今天预训练RoBERTa类的一种KantaiBERT!
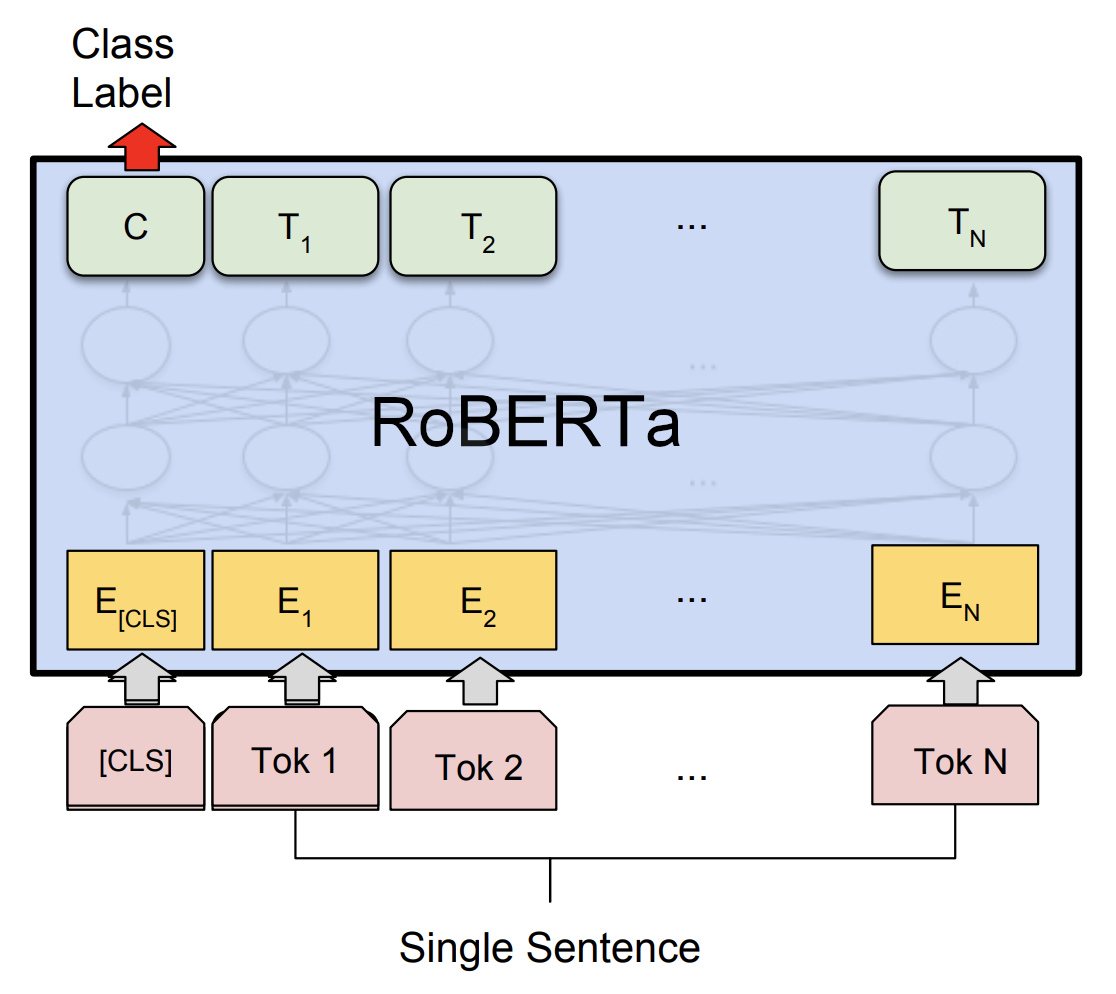
你要考虑怎么样训练这个宝宝(model),才能让他理解语义吧!
有人就发现,让宝宝(model)去**学习完形填空(掩码【mask】)**是个不错的方法!
训练策略:
随机对序列中的一个token进行掩码,让模型对掩码部分进行预测。
比如:
input:
the cat sit [MASK] the rug .
label:
the cat sit on the rug .
这里就是把on给遮住了,让模型看不到这个词,它只能通过理解上下文的方式来预测,这个被遮住的词是什么。以这种方式训练!
代码实战
下载数据集
!curl -L https://raw.githubusercontent.com/Denis2054/Transformers-for-NLP-2nd-Edition/master/Chapter04/kant.txt --output "kant.txt"
构建、保存分词器
利用我们刚刚下载的数据集,使用BPE算法去构建我们的词表,且添加特殊符号
#@title Step 3: Training a Tokenizer
# %%time
from pathlib import Path
from tokenizers import ByteLevelBPETokenizer
paths = [str(x) for x in Path(".").glob("**/*.txt")]
# Initialize a tokenizer
tokenizer = ByteLevelBPETokenizer()
# Customize training
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
查看tokenizer
tokenizer
Tokenizer(vocabulary_size=19296, model=ByteLevelBPE, add_prefix_space=False, lowercase=False, dropout=None, unicode_normalizer=None, continuing_subword_prefix=None, end_of_word_suffix=None, trim_offsets=False)
保存分词器,
#@title Step 4: Saving the files to disk
import os
token_dir = 'KantaiBERT'
if not os.path.exists(token_dir):
os.makedirs(token_dir)
tokenizer.save_model('KantaiBERT')
你可以观察到文件夹多了两个文件,分别记录了词的id以及子词合并记录
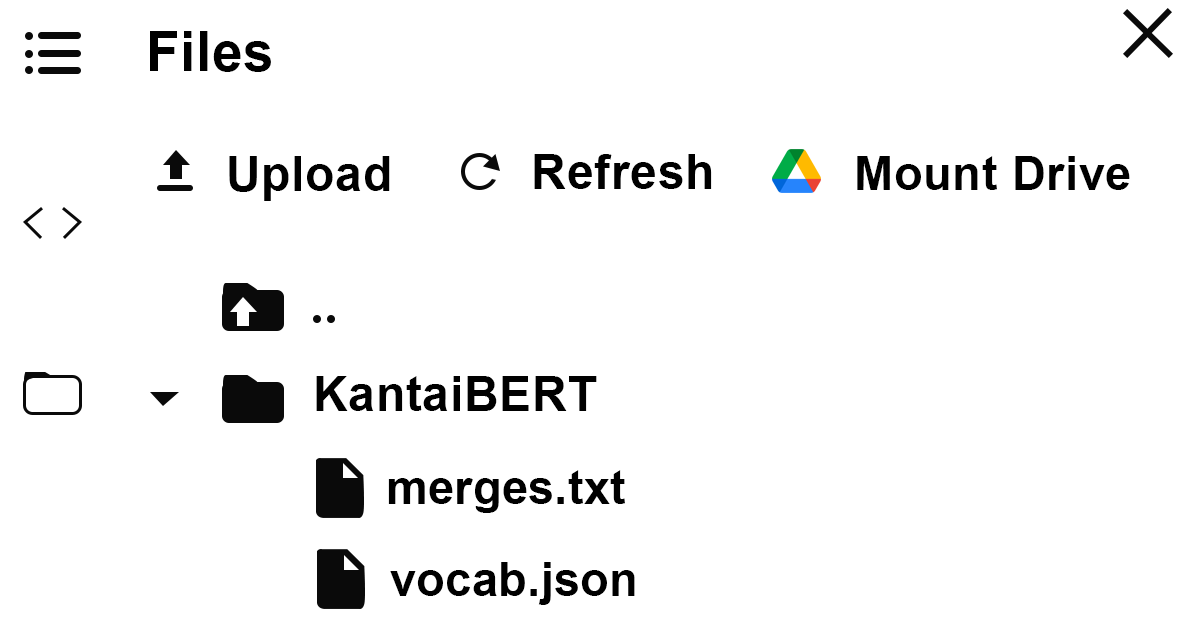
这就是我们把词编码后的代号id

加载分词器
加载之前构建好的分词器
#@title Step 5 Loading the Trained Tokenizer Files
from tokenizers.implementations import ByteLevelBPETokenizer
from tokenizers.processors import BertProcessing
tokenizer = ByteLevelBPETokenizer(
"./KantaiBERT/vocab.json",
"./KantaiBERT/merges.txt",
)
对分词器的编码加上特殊符号
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
tokenizer.enable_truncation(max_length=512)
检查结果:
tokenizer.encode("The Critique of Pure Reason.").tokens
result:
['<s>', 'The', 'ĠCritique', 'Ġof', 'ĠPure', 'ĠReason', '.', '</s>']
初始化模型
使用RobertaConfig的初始化模型配置
#@title Step 7: Defining the configuration of the Model
from transformers import RobertaConfig
config = RobertaConfig(
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1,
)
查看配置参数
print(config)
RobertaConfig {
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"classifier_dropout": null,
"eos_token_id": 2,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 6,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.44.0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 52000
}
使用配置参数构建模型
from transformers import RobertaForMaskedLM
model = RobertaForMaskedLM(config=config)
print(model)
预处理数据
这里使用LineByLineTextDataset对于数据进行切分
#@title Step 10: Building the Dataset
# %%time
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="./kant.txt",
block_size=128,
)
DataCollatorForLanguageModeling使用DataCollator包装,方便拿取数据
#@title Step 11: Defining a Data Collator
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15
)
检查结果:
example=data_collator(dataset.examples)
print(example['input_ids'][0],example['attention_mask'][0],example['labels'][0])
不出意外的话,结果会形如这样:
你会观察到元素原始的input_id中有一个‘4’,没错他就是此表中的【MASK】,同时在最下面的labels也指出被【MASK】的词id实际为2245.
(tensor([ 0, 803, 1123, 1156, 8937, 270, 487, 4, 270, 1410, 1270, 16, 379, 4555, 4032, 2, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1]),
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
tensor([-100, -100, -100, -100, -100, -100, -100, 2245, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100]))
确定训练参数的配置
构建好TrainingArguments,实例化Trainer
#@title Step 12: Initializing the Trainer
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./KantaiBERT",
overwrite_output_dir=True,
num_train_epochs=1,
per_device_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
开始训练
#@title Step 13: Pre-training the Model
# %%time
trainer.train()
保存模型
#@title Step 14: Saving the Final Model(+tokenizer + config) to disk
trainer.save_model("./KantaiBERT")
不出意外的话,你就会发现又多了几个文件!就是模型的权重!
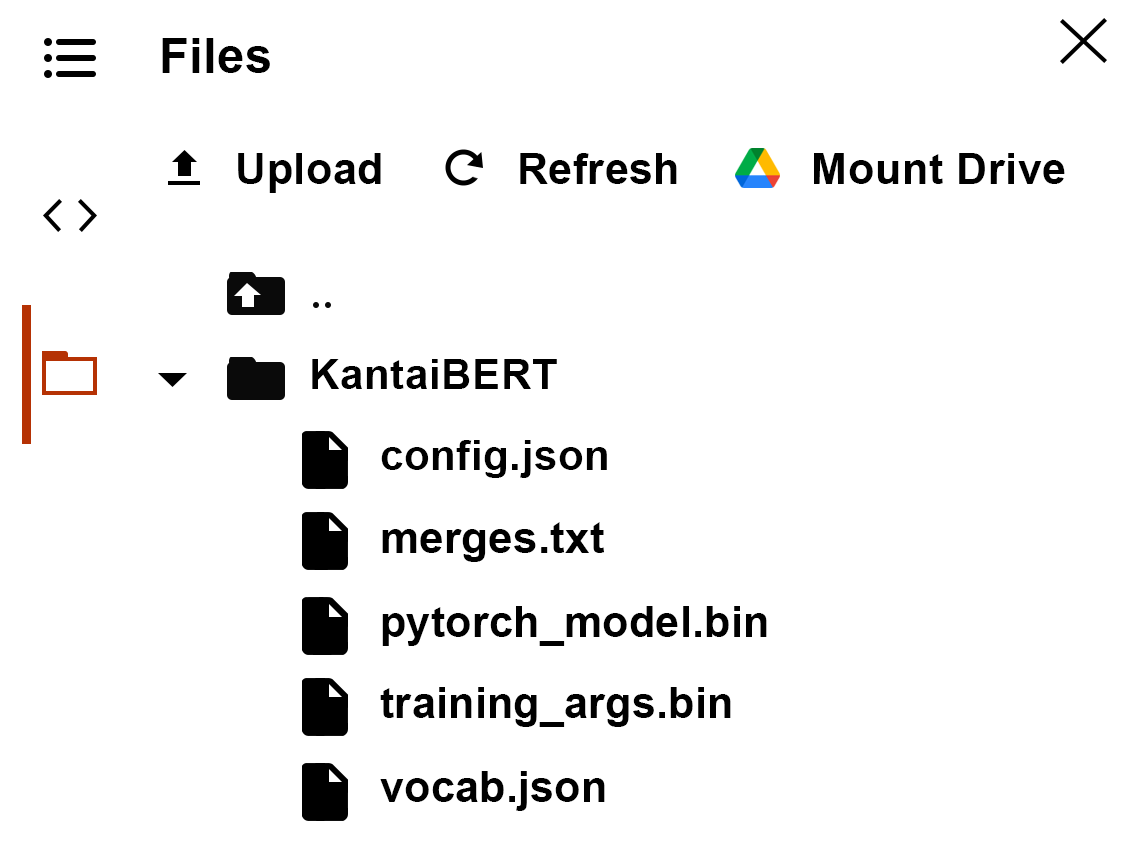
检查训练成果
#@title Step 15: Language Modeling with the FillMaskPipeline
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="./KantaiBERT",
tokenizer="./KantaiBERT"
)
这里使用mask掩码一个词,模型输出了top_5的预测
fill_mask("Human thinking involves human <mask>.")
[{'score': 0.04037218913435936,
'sequence': 'Human thinking involves human reason.',
'token': 393,
'token_str': ' reason'},
{'score': 0.016451537609100342,
'sequence': 'Human thinking involves human experience.',
'token': 531,
'token_str': ' experience'},
{'score': 0.009860575199127197,
'sequence': 'Human thinking involves human conceptions.',
'token': 605,
'token_str': ' conceptions'},
{'score': 0.009715848602354527,
'sequence': 'Human thinking involves human law.',
'token': 446,
'token_str': ' law'},
{'score': 0.008748612366616726,
'sequence': 'Human thinking involves human understanding.',
'token': 600,
'token_str': ' understanding'}]
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
找一群人一起走,慢慢变富。期待和同频 朋的 友一起蜕变!
加微信prophb















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









