







目录
N不清空当前模式空间,然后读入下一行 以\n分隔两行,两行一个输出
sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下一行,执行下一个循环。如果没有使用诸如“D”的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非使用重定向存储输出或-i。
功能:主要用来自动编辑一个或多个文件,简化对文件的反复操作。
语法
sed 选项 【sed命令】 【输入文件】
可以操作多个文件
sed语句:指整体表达式
输入文件:可以是文本,也可以是标准输入
sed软件:指首个sed执行器
sed软件执行流程图

模式空间和保持空间
Sed软件有两个内置的存储空间
模式空间(pattern space):是sed软件从文件读取一行文本然后存入的缓冲区,然后命令操作模式空间的内容。
保持空间(hold space):是sed软件另外一个缓冲区,用来存放临时数据。Sed可以交换保持空间和模式空间的数据,但是不能在保持空间上执行普通的sed命令。
初始情况,模式空间和保持空间都是没有内容的。每次循环读取数据的过程中,模式空间的原内容都会被清空写入新的内容,但保持空间的内容保持不变,不会在循环中被删除,除非使用sed命令操作保持空间。
- h:将模式空间中的内容覆盖至保持空间中
- H:将模式空间中的内容追加至保持空间中
- g:从保持空间取出数据覆盖至模式空间
- G:从保持空间取出数据追加至模式空间
- x:将模式空间中的内容与保持空间中的内容进行互换
- n:读取匹配到的行的下一行覆盖至模式空间
- N:读取匹配到的行的下一行追加至模式空间
- d:删除模式空间中的行
- D:删除当前模式空间开端到\n的内容(不再传至标准输出),放弃之后的命令,但是对剩余模式空间重新执行sed

模式空间
n清空当前模式空间,然后读入下一行
读入101遇到n被清空然后读入102 一次循环完成,然后读入103遇到n被清空然后读入104...
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
[root@rhel8 xiaopi]$sed -n 'p' 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
#清空当前模式空间,不进行打印,直接进入下一个模式空间循环
[root@rhel8 xiaopi]$sed -n 'n;p' 1.txt
102,pibo,CEO
104,bobo,CFO
#加数字则表示清空第2行当前模式空间,不进行打印,直接进入下一个模式空间循环
[root@rhel8 xiaopi]$sed -n '2n;p' 1.txt
101,xiaopi,CTO
103,pipi,COO
104,bobo,CFO
105,cc
[root@rhel8 xiaopi]$sed -n '3n;p' 1.txt
101,xiaopi,CTO
102,pibo,CEO
104,bobo,CFO
105,cc
N不清空当前模式空间,然后读入下一行 以\n分隔两行,两行一个输出
[root@rhel8 xiaopi]$sed 'N' 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
[root@rhel8 xiaopi]$sed '=' 1.txt | sed 'N'
1
101,xiaopi,CTO
2
102,pibo,CEO
3
103,pipi,COO
4
104,bobo,CFO
5
105,cc
[root@rhel8 xiaopi]$sed -n 'N;l' 1.txt
101,xiaopi,CTO\n102,pibo,CEO$
103,pipi,COO\n104,bobo,CFO$
#标记行号,随后将\n替换为空格
[root@rhel8 xiaopi]$sed '=' 1.txt | sed 'N;s#\n# #'
1 101,xiaopi,CTO
2 102,pibo,CEO
3 103,pipi,COO
4 104,bobo,CFO
5 105,cc
#相当于第一行和第二行进行合并,中间以\n字符连接,可以将其替换成别的字符
[root@rhel8 xiaopi]$vim 2.txt
[root@rhel8 xiaopi]$cat 2.txt
abc1234
hfkdjhf
abc2345
fahdhfu
abc3456
gadgsag
abc4567
fjldkjf
[root@rhel8 xiaopi]$sed 'N;s#\n#=#' 2.txt
abc1234=hfkdjhf
abc2345=fahdhfu
abc3456=gadgsag
abc4567=fjldkjf模拟其他命令
#cat
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
[root@rhel8 xiaopi]$sed '' 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
[root@rhel8 xiaopi]$sed -n 'p' 1.txt
[root@rhel8 xiaopi]$sed 'n' 1.txt
[root@rhel8 xiaopi]$sed 'N' 1.txt
[root@rhel8 xiaopi]$sed 's# # #' 1.txt
#grep
#grep -n,会显示行号和字符标红
[root@rhel8 xiaopi]$grep -n ao 1.txt
1:101,xiaopi,CTO
[root@rhel8 xiaopi]$sed -n '/ao/p' 1.txt
101,xiaopi,CTO
[root@rhel8 xiaopi]$sed -n '/ao/ !p' 1.txt
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
#head
[root@rhel8 xiaopi]$sed -n '1,2p' 1.txt
101,xiaopi,CTO
102,pibo,CEO
[root@rhel8 xiaopi]$sed '3,$d' 1.txt
101,xiaopi,CTO
102,pibo,CEO
[root@rhel8 xiaopi]$sed '2q' 1.txt
101,xiaopi,CTO
102,pibo,CEO
#wc
[root@rhel8 xiaopi]$sed -n '$=' 1.txt
5指定地址范围
n1[,n2]{sed command}
10{sed command} #对第10行进行操作
10,20{sed command} #对第10-20行进行操作
10,+20{sed command} #对第十行后面的二十行进行操作,也就是10-30行
1~2{sed command} #以1为首,以2为间隔的奇数行,1 3 5 7 9
2~2{sed command} #以2为首,以2为间隔的奇数行,2 4 6 8 10
10,${sed command} #第十行到最后一行
还支持匹配正则表达式
/xiaopi/{sed command} #匹配xiaopi这一行执行操作
/xiaopi/,+20{sed command} #匹配xiaopi这一行后的20行执行操作
/xiaopi/,/pibo/{sed command} #匹配xiaopi这一行到pibo这一行直接的内容执行操作
10,/xiaopi/{sed command} #从第十行到含有xiaopi的那一行
常用选项
- -n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
- -e:多点编辑,对每行处理时,可以有多个script
- -f:把script写到文档中,在执行sed时,-f指定文件路径;如果有多个script,换行写入
- -r:支持扩展的正则表达式
- -i:直接将处理的结果写入文件
- -i.bak:在将处理的结果写入文件之前备份一份
编辑命令
- d:删除模式空间匹配的行,并立即启用下一轮循环
- p:打印当前模式空间内容,追加到默认输出之后
- a:在指定行后面追加文本,支持使用\n实现多行追加
- i:在行前面插入文本,支持使用\n实现多行追加
- c:替换行为单行或多行文本,支持使用\n实现多行追加
- w:保存模式匹配的行至指定文件
- r:读取指定文件的文本至模式空间中匹配到的行后
- =:为模式空间中的行打印行号
- !:模式空间中匹配行取反处理
- s///:查找替换,支持使用其它分隔符,如:s@@@,s###;
-
- 加g表示行内全局替换;仅是命令的标志,不是命令本身
- 在替换时,可以加一下命令,实现大小写转换
- \l:把下个字符转换成小写。
- \L:把replacement字母转换成小写,直到\U或\E出现。
- \u:把下个字符转换成大写。
- \U:把replacement字母转换成大写,直到\L或\E出现。
- \E:停止以\L或\U开始的大小写转换
增删改查操作
1.1. 增
a:在指定行后面追加文本,支持使用\n实现多行追加
i:在行前面插入文本,支持使用\n实现多行追加
1.1.1. 单行增加
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
#i选项表示在第二行前面增加
#默认表示不替换文本,加选项-i才替换文本内容
[root@rhel8 xiaopi]$sed '2i 4,xiaopi' 1.txt
1,xiao
4,xiaopi
2,pi
3,bo
#a选项表示在第二行后面增加
[root@rhel8 xiaopi]$sed '2a 4,xiaopi' 1.txt
1,xiao
2,pi
4,xiaopi
3,bo1.1.2. 多行增加
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$sed '2i 4,xiaopi\n5,pibo' 1.txt
1,xiao
4,xiaopi
5,pibo
2,pi
3,bo
或
使用\换行
[root@rhel8 xiaopi]$sed '2i 4,xiaopi\
>n5,pibo' 1.txt
1,xiao
4,xiaopi
5,pibo
2,pi
3,bo1.2. 删
d:删除模式空间匹配的行,并立即启用下一轮循环
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
#不加行号,默认删除所有文本
[root@rhel8 xiaopi]$sed 'd' 1.txt
[root@rhel8 xiaopi]$sed '2d' 1.txt
1,xiao
3,bo
#删除范围,例如2-3行
[root@rhel8 xiaopi]$sed '2,3d' 1.txt
1,xiao
[root@rhel8 xiaopi]$sed '/pi/d' 1.txt
1,xiao
3,bo1.3. 改
sed '[地址范围|模式范围] s#[被替换的字符串]#[替换的字符串]#[替换标志]' 输入文件
1.3.1. 替换标志
- g全局标志
- 数字标志1,2,3...,512(1<=N<=512) 当数字标志为1时,可以默认不写
- 打印p
- 写w
- 忽略大小写i
- 执行命令标志e
[root@rhel8 xiaopi]$cat num.txt
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
#Ms 表示对第M行进行操作
[root@rhel8 xiaopi]$sed '2s#1#0#' num.txt
1 1 1 1
0 1 1 1
1 1 1 1
1 1 1 1
#若无g标志,则默认替换第一个字符串
#加g标志,则会对第M行全部的含有1的字符串进行修改
[root@rhel8 xiaopi]$sed '2s#1#0#g' num.txt
1 1 1 1
0 0 0 0
1 1 1 1
1 1 1 1
#Ms Ng 数字标志表示对第M行第N个字符串进行操作
[root@rhel8 xiaopi]$sed '2s#1#0#3' num.txt
1 1 1 1
1 1 0 1
1 1 1 1
1 1 1 1
#数字标志加g标志,会对数字标志后的所有含有1的字符串进行修改
[root@rhel8 xiaopi]$sed '2s#1#0#2g' num.txt
1 1 1 1
1 0 0 0
1 1 1 1
1 1 1 1
[root@rhel8 xiaopi]$sed '2,3s#1#0#2g' num.txt
1 1 1 1
1 0 0 0
1 0 0 0
1 1 1 1
#不加行数范围则默认针对所有行
[root@rhel8 xiaopi]$sed 's#1#0#2g' num.txt
1 0 0 0
1 0 0 0
1 0 0 0
1 0 0 0
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3.bo
[root@rhel8 xiaopi]$sed 's#pi#pipi# w outfile.txt' 1.txt
1,xiao
2,pipi
3.bo
[root@rhel8 xiaopi]$cat outfile.txt
2,pipi
[root@rhel8 xiaopi]$sed 's#pi#pipi#w outfile.txt' 1.txt
1,xiao
2,pipi
3.bo
[root@rhel8 xiaopi]$cat outfile.txt
2,pipi
#加上“;”变成执行两个命令
#表示修改后再进行另存为
[root@rhel8 xiaopi]$sed 's#pi#pipi#;w outfile.txt' 1.txt
1,xiao
2,pipi
3.bo
[root@rhel8 xiaopi]$cat outfile.txt
1,xiao
2,pipi
3.bo
#加i选项可以忽略大小写
[root@rhel8 xiaopi]$sed 's#Pi#pipi#' 1.txt
1,xiao
2,pi
3.bo
[root@rhel8 xiaopi]$sed 's#Pi#pipi#i' 1.txt
1,xiao
2,pipi
3.bo
#将模式空间的任何内容当做bash命令执行
#注意需要带空格
[root@rhel8 xiaopi]$vim 1.txt
[root@rhel8 xiaopi]$cat 1.txt
/etc/shadow
/etc/passwd
[root@rhel8 xiaopi]$sed 's#^#ls -lh #g' 1.txt
ls -lh /etc/shadow
ls -lh /etc/passwd
[root@rhel8 xiaopi]$sed 's#^#ls -lh #e' 1.txt
----------. 1 root root 802 6月 19 10:32 /etc/shadow
-rw-r--r--. 1 root root 1.2K 6月 19 10:32 /etc/passwd
\l:把下个字符转换成小写。
\L:把replacement字母转换成小写,直到\U或\E出现。
\u:把下个字符转换成大写。
\U:把replacement字母转换成大写,直到\L或\E出现。
\E:停止以\L或\U开始的大小写转换
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
[root@rhel8 xiaopi]$sed -r 's#(.*),(.*),(.*)#\L\3,\E\1,\U\2#g' 1.txt
cto,101,XIAOPI
ceo,102,PIBO
coo,103,PIPI
cfo,104,BOBO1.3.2. 特殊字符
1.3.2.1. 特殊符号= 表示获取行号
[root@rhel8 xiaopi]$sed '=' 1.txt
1
101,xiaopi,CTO
2
102,pibo,CEO
3
103,pipi,COO
4
104,bobo,CFO
[root@rhel8 xiaopi]$sed '/pipi/=' 1.txt
101,xiaopi,CTO
102,pibo,CEO
3
103,pipi,COO
104,bobo,CFO
[root@rhel8 xiaopi]$cat -n 1.txt
1 101,xiaopi,CTO
2 102,pibo,CEO
3 103,pipi,COO
4 104,bobo,CFO
1.3.2.2. {}的用法
#如果不加的话,后面打印行号的命令就会对所有行执行
[root@rhel8 xiaopi]$sed -n '2,3p;=' 1.txt
1
102,pibo,CEO
2
103,pipi,COO
3
4
#如果加上大括号{},则会先执行前面的命令,然后再执行后面的命令(相当于乘法分配律)
[root@rhel8 xiaopi]$sed -n '2,3{p;=}' 1.txt
102,pibo,CEO
2
103,pipi,COO
31.3.2.3. 打印不可见字符l,(是英文字母l)
[root@rhel8 xiaopi]$vim 1.txt
[root@rhel8 xiaopi]$cat 1.txt
101, xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
[root@rhel8 xiaopi]$sed -n 'l' 1.txt
101, xiaopi,CTO$
$
102,pibo,CEO$
103,pipi,COO$
104,bobo,CFO$1.3.2.4. 转换字符y
[root@rhel8 xiaopi]$vim 1.txt
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
原文均无发生改变
方法1
[root@rhel8 xiaopi]$tr 'abc' 'ABC' < 1.txt
101,xiAopi,CTO
102,piBo,CEO
103,pipi,COO
104,BoBo,CFO
105,CC
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
方法2
[root@rhel8 xiaopi]$sed 'y#abc#ABC#' 1.txt
101,xiAopi,CTO
102,piBo,CEO
103,pipi,COO
104,BoBo,CFO
105,CC
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
1.3.2.5. 退出sed命令字符q
[root@rhel8 xiaopi]$sed 'q' 1.txt
101,xiaopi,CTO
[root@rhel8 xiaopi]$sed '3q' 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
注:不可以范围执行
[root@rhel8 xiaopi]$sed '3q;p' 1.txt
101,xiaopi,CTO
101,xiaopi,CTO
102,pibo,CEO
102,pibo,CEO
103,pipi,COO1.3.2.6. 从文件读取字符r
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
[root@rhel8 xiaopi]$cat num.txt
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
#可以规定行号
[root@rhel8 xiaopi]$sed '3r num.txt' 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
104,bobo,CFO
105,cc
#相当于合并两个文件
[root@rhel8 xiaopi]$sed '$r num.txt' 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
105,cc
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
[root@rhel8 xiaopi]$sed 'r num.txt' 1.txt
101,xiaopi,CTO
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
102,pibo,CEO
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
103,pipi,COO
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
104,bobo,CFO
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
105,cc
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 11.3.2.7. 一条sed语句执行多个命令
例:将第三行后的内容删除,并将剩下的内容中10换为01
[root@rhel8 xiaopi]$cat 1.txt
101,xiaopi,CTO
102,pibo,CEO
103,pipi,COO
104,bobo,CFO
方法1
[root@rhel8 xiaopi]$sed '3,$d' 1.txt | sed 's#10#01#g'
011,xiaopi,CTO
012,pibo,CEO
或
方法2
[root@rhel8 xiaopi]$sed '3,$d;s#10#01#g' 1.txt
011,xiaopi,CTO
012,pibo,CEO
或
方法3
[root@rhel8 xiaopi]$sed -e '3,$d' -e 's#10#01#g' 1.txt
011,xiaopi,CTO
012,pibo,CEO
或
方法4
#如果一行命令执行不完的话,可以写成文件
-f:把script写到文档中,在执行sed时,-f指定文件路径;如果有多个script,换行写入
[root@rhel8 xiaopi]$vim 1.sed
[root@rhel8 xiaopi]$cat 1.sed
3,$d
s#10#01#g
[root@rhel8 xiaopi]$sed -f 1.sed 1.txt
011,xiaopi,CTO
012,pibo,CEO
1.3.2.8. 取出文件中1 3 4 行内容
[root@rhel8 xiaopi]$sed -n '1p;3p;4p' 1.txt
101,xiaopi,CTO
103,pipi,COO
104,bobo,CFO1.3.3. 按行替换
c:替换行为单行或多行文本,支持使用\n实现多行追加
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
#将第二行替换
[root@rhel8 xiaopi]$sed '2c 4,xiaopi' 1.txt
1,xiao
4,xiaopi
3,bo
[root@rhel8 xiaopi]$sed '2c 4,xiaopi\n' 1.txt
1,xiao
4,xiaopi
3,bo
[root@rhel8 xiaopi]$sed '2,3c 4,xiaopi\n' 1.txt
1,xiao
4,xiaopi
1.3.4. 文本替换
s///:查找替换,支持使用其它分隔符,如:s@@@,s###;
加g表示行内全局替换;仅是命令的标志,不是命令本身
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$sed 's#bo#bobo#g' 1.txt
1,xiao
2,pi
3,bobo
#也可以加数字固定行号
[root@rhel8 xiaopi]$sed '3s#bo#bobo#g' 1.txt
1,xiao
2,pi
3,bobo
[root@rhel8 xiaopi]$cat 2.txt
a
b
a
[root@rhel8 xiaopi]$x=a
[root@rhel8 xiaopi]$y=b
[root@rhel8 xiaopi]$echo $x $y
a b
[root@rhel8 xiaopi]$sed 's#$x#$y#g' 2.txt
a
b
a
#不成立,是由于单引号是强引,会去掉变量的含义
[root@rhel8 xiaopi]$sed s#$x#$y#g 2.txt
b
b
b
或
#eval可以先将变量解析出来,然后执行
[root@rhel8 xiaopi]$eval sed 's#$x#$y#g' 2.txt
b
b
b1.3.5. 分组替换
[root@rhel8 xiaopi]$echo I am oldboy teacher. | sed 's#^.*am \([a-z].*\) tea.*$#\1#g'
oldboy
#.*代表正则表达式中的任意字符
[root@rhel8 xiaopi]$echo I am oldboy teacher. | sed 's#I \(.*\) \([a-z].*\) tea.*$#\1\2#g'
amoldboy
[root@rhel8 xiaopi]$echo I am oldboy teacher. | sed 's#I \(.*\) \([a-z].*\) tea.*$#\1#g'
am
[root@rhel8 xiaopi]$echo I am oldboy teacher. | sed 's#I \(.*\) \([a-z].*\) \(.*\)a.*$#\1\n\2\n\3#g'
am
oldboy
te
#\1表示从前往后第一个\(.*\)被全部替换的词1.3.6. 特殊符号
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$sed 's#o#--&--#g' 1.txt
1,xia--o--
2,pi
3,b--o--
#加行号固定修改这一行
[root@rhel8 xiaopi]$sed '1s#o#--&--#g' 1.txt
1,xia--o--
2,pi
3,bo
#加选项-r,支持正则扩展表达式
[root@rhel8 xiaopi]$sed -r 's#(.*)#--&--#g' 1.txt
--1,xiao--
--2,pi--
--3,bo--
[root@rhel8 xiaopi]$ls
stu_123_1_fin.jpg
stu_123_2_fin.jpg
stu_123_3_fin.jpg
[root@rhel8 xiaopi]$ls *.jpg|sed -r 's#(.*)_fin.*#mv & \1.jpg#g'
stu_123_1.jpg
stu_123_2.jpg
stu_123_3.jpg
#仅在模式空间进行展示,未执行,如需执行加bash即可
[root@rhel8 xiaopi]$ls *.jpg|sed -r 's#(.*)_fin.*#mv & \1.jpg#g'|bash1.4. 查
p:打印当前模式空间内容,追加到默认输出之后
通常与-n选项一起使用
-n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
#默认追加打印,选定行后对第二行追加再打印一行
#增加-n 选项后,打印出第二行的内容
[root@rhel8 xiaopi]$sed '2p' 1.txt
1,xiao
2,pi
2,pi
3,bo
[root@rhel8 xiaopi]$sed -n '2p' 1.txt
2,pi
[root@rhel8 xiaopi]$sed -n '1,2p' 1.txt
1,xiao
2,pi
[root@rhel8 xiaopi]$sed -n 'p' 1.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$sed -n '/a/,2p' 1.txt
1,xiao
2,pi
[root@rhel8 xiaopi]$sed '' 1.txt
1,xiao
2,pi
3,bo选项详解
-i:直接将处理的结果写入文件
[root@rhel8 xiaopi]$ls
1.txt
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
#在后面增加.ori会进行备份文件,备份的文件名称:源文件名.ori
[root@rhel8 xiaopi]$sed -ri.ori 's#(.*)#--&---#g' 1.txt
[root@rhel8 xiaopi]$cat 1.txt
--1,xiao---
--2,pi---
--3,bo---
[root@rhel8 xiaopi]$cat 1.txt.ori
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$ls
1.txt 1.txt.ori
#将原文件还原
[root@rhel8 xiaopi]$cat 1.txt.ori > 1.txt
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bow:保存模式匹配的行至指定文件,另存文件
[root@rhel8 xiaopi]$sed 'w outfile.txt' 1.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$cat outfile.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
#先修改再另存为
[root@rhel8 xiaopi]$sed 's#2#4#g w outfile.txt' 1.txt
1,xiao
4,pi
3,bo
[root@rhel8 xiaopi]$cat 1.txt
1,xiao
2,pi
3,bo
[root@rhel8 xiaopi]$cat outfile.txt
4,piuniq
uniq命令用于检查及删除文本文件中重复出现的行列。
语法
uniq [options] [file1 [file2] ]
uniq从已经排好序的文本文件file1中删除重复行,输出到标注输出或file2.常作为过滤器,配合管道使用
在使用uniq命令之前,必须确保操作的文本文件已经做过sort排序。若不带参数运行uniq,将删除重复的行。
参数:
- -c或--count 在每列旁边显示该行重复出现的次数。
- -d或--repeated 仅显示重复出现的行列。
- -f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
- -s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
- -u或--unique 仅显示出一次的行列。
- -w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
- --help 显示帮助。
- --version 显示版本信息。
- [输入文件] 指定已排序好的文本文件。
- [输出文件] 指定输出的文件。
a、只对相邻的相同行内容去重
[root@rhel8 xiaopi]$cat num.txt
10.0.0.9
10.0.0.8
10.0.0.7
10.0.0.7
10.0.0.8
10.0.0.8
10.0.0.9
[root@rhel8 xiaopi]$uniq num.txt
10.0.0.9
10.0.0.8
10.0.0.7
10.0.0.8
10.0.0.9b、sort命令让重复行相邻
#-u, --unique
# with -c, check for strict ordering; without -c, output only the
# first of an equal run
[root@rhel8 xiaopi]$sort -u num.txt
10.0.0.7
10.0.0.8
10.0.0.9c、uniq通过sort配合完全去重:让重复行相邻
[root@rhel8 xiaopi]$sort num.txt | uniq
10.0.0.7
10.0.0.8
10.0.0.9d、去重计数
[root@rhel8 xiaopi]$sort num.txt | uniq -c
2 10.0.0.7
3 10.0.0.8
2 10.0.0.9
#无排序结果
[root@rhel8 xiaopi]$uniq -c num.txt
1 10.0.0.9
1 10.0.0.8
2 10.0.0.7
2 10.0.0.8
1 10.0.0.9例题:
[root@rhel8 xiaopi]$cat web.txt
http://www.google.com
http://www.baidu.com
http://www.sina.com
http://www.bjtu.edu.cn
http://www.codeproject.com
http://www.csdn.com
http://www.sohu.com
http://www.yahoo.com
http://mail.163.com
http://www.bjtu.edu.cn
http://www.codeproject.com
http://www.csdn.com
http://www.sohu.com
http://www.yahoo.com
http://mail.163.com
http://www.codeproject.com
http://www.csdn.com
http://www.sohu.com
http://www.yahoo.com
http://mail.163.com
http://www.qq.com
http://www.hao123.com
http://www.163.com
http://youku.com
http://taobao/com
http://www.bjtu.edu.cn
http://www.codeproject.com
http://www.csdn.com
http://www.sohu.com
http://www.yahoo.com
http://mail.163.com
http://www.codeproject.com
http://www.csdn.com
http://www.sohu.com
http://www.yahoo.com
http://mail.163.com
http://www.qq.com
http://www.hao123.com
http://www.163.com
http://youku.com
http://taobao/com
[root@rhel8 xiaopi]$cut -d / -f3 web.txt|sort -r|uniq -c
或
[root@rhel8 xiaopi]$awk -F / '{print $3}' web.txt|sort|uniq -c|sort -r
或
[root@rhel8 xiaopi]$awk -F "/" '{S[$3]=S[$3]+1}END{for(k in S) print k,S[k]}' web.txt
a=a+1
这种情况可以写成
a++或a+=1
[root@rhel8 xiaopi]$awk -F "/" '{S[$3]++}END{for(k in S) print k,S[k]}' web.txt | sort -rn -k2|head 10sort
sort命令是一个用于对文本文件进行排序的工具。它可以按照指定的排序规则对文件中的行进行排序,并输出排序后的结果。sort命令默认按照字典顺序对文本行进行排序,但也可以根据需要进行自定义排序
语法
sort [选项] [文件]
选项是用于指定排序规则和其他参数的选项,文件是要排序的输入文件。
常用命令选项
- -b,--ignore-leading-blanks:忽略每行前面的空格字符。
- -d,--dictionary-order:只考虑空白区域和字母字符。
- -f,--ignore-case:忽略字母大小写。
- -g,--general-numeric-sort:根据一般数值大小进行排序。
- -i,--ignore-nonprinting:只考虑可打印字符。
- -M,--month-sort:按照月份进行排序。
- -h,--human-numeric-sort:使用易读性数字进行排序(例如:2K、1G)。
- -n,--numeric-sort:根据数值大小进行排序。
- -R,--random-sort:根据随机哈希排序。
- --random-source=文件:从指定文件中获取随机字节。
- -r,--reverse:逆序输出排序结果。
- --sort=WORD:按照指定的格式进行排序,可选的格式有:一般数字(-g)、高可读性数字(-h)、月份(-M)、数字(-n)、随机(-R)、版本(-V)。
- -V,--version-sort:在文本内进行自然版本排序。
其他命令选项
- --batch-size=NMERGE:一次最多合并NMERGE个输入;如果输入更多,则使用临时文件。
- -c,--check,--check=diagnose-first:检查输入是否已排序,若已有序则不进行操作。
- -C,--check=quiet,--check=silent:类似-c,但不报告第一个无序行。
- --compress-program=程序:使用指定程序压缩临时文件;使用该程序的-d参数解压缩文件。
- --debug:为用于排序的行添加注释,并将有可能有问题的用法输出到标准错误输出。
- --files0-from=文件:从指定文件读取以NUL终止的名称,如果该文件被指定为"-"则从标准输入读文件名。
- -k,--key=KEYDEF:通过键定义进行排序。指定第几列或第几列的第几个字符
- -m,--merge:合并已经排序的文件,不进行排序操作。
- -o,--output=文件:将结果写入到文件而非标准输出。
- -s,--stable:禁用last-resort比较以稳定比较算法。
- -S,--buffer-size=大小:指定主内存缓存大小。
- -t,--field-separator=分隔符:使用指定的分隔符代替非空格到空格的转换,默认空格
- -T,--temporary-directory=目录:使用指定目录而非$TMPDIR或/tmp作为临时目录,可用多个选项指定多个目录。
- --parallel=N:将同时运行的排序数改变为N。
- -u,--unique:配合-c,严格校验排序;不配合-c,则只输出一次排序结果。
- -z,--zero-terminated:以0字节而非新行作为行尾标志。
- --help:显示此帮助信息并退出。
- --version:显示版本信息并退出。
默认对整行排序,可以用-t指定分隔符,-k1,分隔符之后的第一列排序
-k 字段,字段 #用逗号来分割字段
-k 1,1 #表示以逗号分割字段,第一个字段开始排序到第一个字段结束
-k 1.1,3.3 #用点分割字符,表示第一个字段的第一个字符开始排序到第三个字段的第三个字符结束
sort -t. -k3.1,3.1nr -k4.1,4.3nr web.txt示例1:按照字典顺序排序
对文件file.txt中的行按照字典顺序进行排序,并输出排序结果。
sort file.txt示例2:按照数值大小排序
对文件file.txt中的行按照数值大小进行排序,并输出排序结果。
sort -n file.txt示例3:按照指定字段排序
对文件file.txt中的行按照第二个字段进行排序,并输出排序结果。
sort -k 2 file.txt示例4:以逆序排序
对文件file.txt中的行按照字典顺序进行逆序排序,并输出排序结果。
sort -r file.txt示例5:使用其他选项进行排序
使用-h选项对文件file.txt中的行按照易读性数字进行排序,并输出排序结果。
sort -h file.txtawk
awk是一种处理文本文件的编程语言,文件的每行数据都被称为记录,默认以空格或制表符为分隔符,每条记录被分成若干字段(列),awk每次从文件中读取一条记录
语法
awk [选项] ‘[条件]{动作} 条件{动作} ...' 文件名
内置变量

语法说明
#格式说明
NR 行
NR== 等于行
NR>= 大于等于行
NR<= 小于等于
NR>=N&&NR<=M 从N行到M行
awk的其他内置变量如下。
FILENAME:当前文件名
===================awk在数据输入时,的一个分隔符===================
FS:字段分隔符,默认是空格和制表符。
Input field separator variable.输入字段分隔符变量。
RS:行分隔符,用于分割每一行,默认是换行符。
Record Separator variable,行分隔符变量
============awk处理完毕后,打印的数据格式,分隔符=================
OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。
Output Field Separator Variable,输出字段分隔符变量
ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行(\n)符。
Output Record Separator Variable,输出记录分隔符变量
[242-yuchao-class01 root ~]#awk -v RS='\n' '{print $0}' test_awk.log
cc01 cc02 cc03 cc04 cc05
cc06 cc07 cc08 cc09 cc10
cc11 cc12 cc13 cc14 cc15
cc16 cc17 cc18 cc19 cc20
cc21 cc22 cc23 cc24 cc25
cc26 cc27 cc28 cc29 cc30
cc31 cc32 cc33 cc34 cc35
cc36 cc37 cc38 cc39 cc40
cc41 cc42 cc43 cc44 cc45
cc46 cc47 cc48 cc49 cc50
[242-yuchao-class01 root ~]#awk -v RS=' ' '{print $0}' test_awk.log
cc01
cc02
cc03
要求修改每一个数据之间的分隔符,改为#号
$1 ,$2 是字段之间的逗号“,”和OFS对应
[242-yuchao-class01 root ~]#awk -v OFS='#' '{print $1,$2,$3,$4,$5}' test_awk.log
cc01#cc02#cc03#cc04#cc05
cc06#cc07#cc08#cc09#cc10
cc11#cc12#cc13#cc14#cc15
cc16#cc17#cc18#cc19#cc20
cc21#cc22#cc23#cc24#cc25
cc26#cc27#cc28#cc29#cc30
cc31#cc32#cc33#cc34#cc35
cc36#cc37#cc38#cc39#cc40
cc41#cc42#cc43#cc44#cc45
cc46#cc47#cc48#cc49#cc50
### 修改/etc/passwd的格式
修改原本用户信息的冒号分隔符、改为`---`
提取出 root、家目录、登录解释器
[root@130 ~]#head -5 /etc/passwd | awk 'BEGIN { FS=":" } { OFS="---" } {print $1,$(NF-1),$NF}'
root---/root---/bin/bash
bin---/bin---/sbin/nologin
daemon---/sbin---/sbin/nologin
adm---/var/adm---/sbin/nologin
lp---/var/spool/lpd---/sbin/nologin
或
head -5 /etc/passwd|awk -v FS=':' -v OFS='---' 'NR==1{print $1, $(NF-1),$NF}' 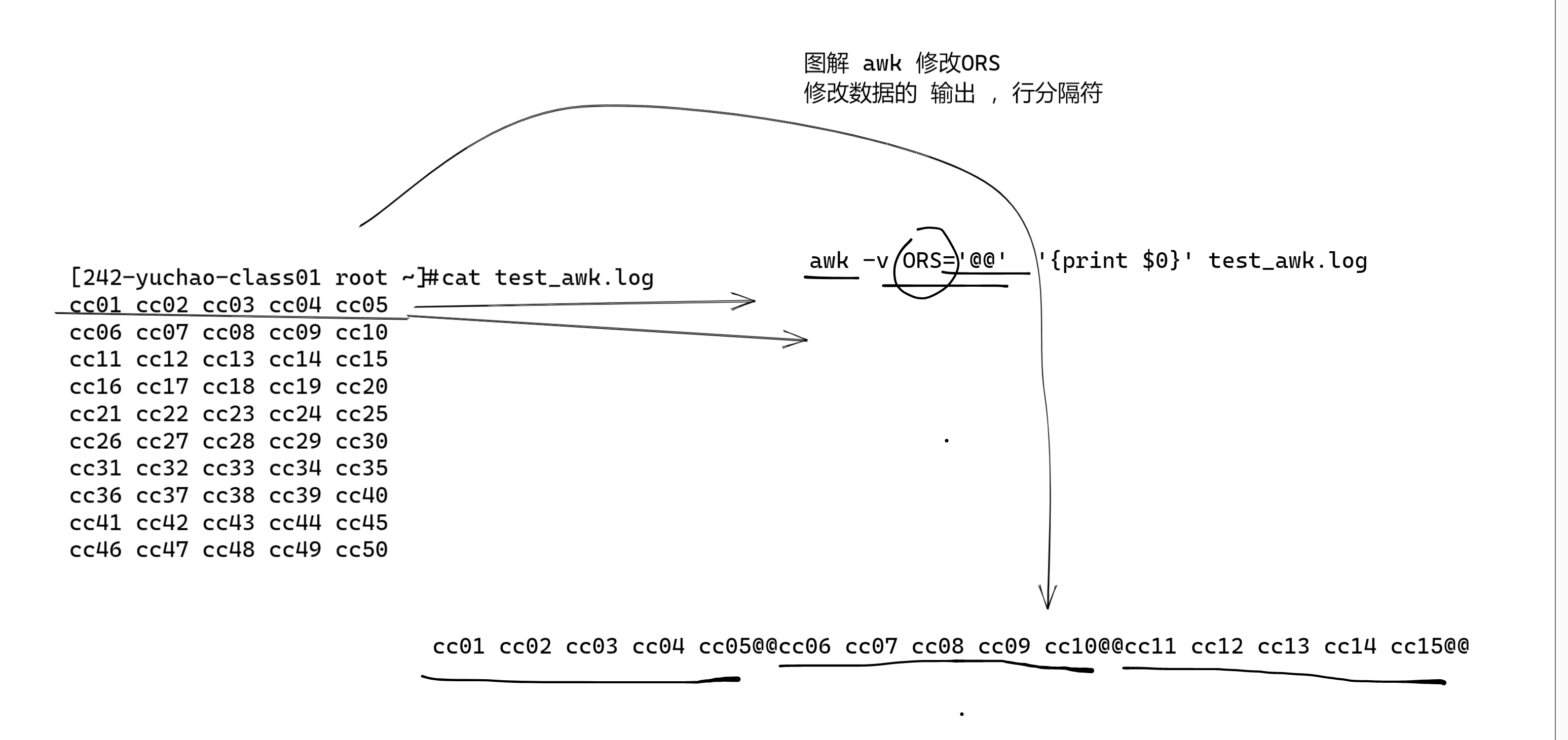
BEGIN模式
- BEGIN模式作用是在awk开始读取文件行数据、之前就先执行,一般用于预定义一些操作,比如数据的表头格式化等。
- BEGIN后面必须跟上action动作
语法
awk 'BEGIN{print "你好"}{print $0}'
[root@130 ~]#awk 'BEGIN{print "你好"}{print $0}' english.log
你好
I have a dog, it is lovely, it is called Mimi. Every time I go home from school, Mimi always cruising around me, I will go to the kitchen to get a piece of meat to it, it lay on the floor to eat. My legs and then jump to bark "Wang "called, so I picked up Mimi, it is the opportunity to lick my hand, making me laugh.I like Mimi, like puppies.
#先打印“你好”,然后进行处理打印文本内容END{} 特殊模式
- END是awk读取完所有的文件后,再执行END模块,一般用来总结、格式化打印一个结果
- END仅会在awk所有行数据处理完毕后,执行END动作。
BEGIN{} 用于awk执行之前的操作
END{} awk所有行数据处理完毕后,做什么事
语法
awk 'BEGIN{print "你好 "} 模式 {动作} END{print "awk完事了"}'
[root@130 ~]#awk 'BEGIN{print "你好"}{print $0}END{print "awk完事了"}' english.log
你好
I have a dog, it is lovely, it is called Mimi. Every time I go home from school, Mimi always cruising around me, I will go to the kitchen to get a piece of meat to it, it lay on the floor to eat. My legs and then jump to bark "Wang "called, so I picked up Mimi, it is the opportunity to lick my hand, making me laugh.I like Mimi, like puppies.
awk完事了
实践
/etc/passwd
1.打印第二行的信息
awk 'NR==2{print $2}' /etc/passwd
2.输出第二行到结尾的所有行,带上行号
awk 'NR>=2{print NR,$0}' /etc/passwd
3.输出2到5行的内容,包括行号
awk 'NR>=2&&NR<=5{print NR,$0}' /etc/passwd
4.输出第3行、第11行的内容,包括行号
awk 'NR==3||NR==11{print NR,$0}' /etc/passwd
5.找到root用户到adm用户的内容,包括行号
[root@130 ~]#awk '/^root/,/^adm/{print NR,$0}' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
6.打印用户名和解释器
[root@130 ~]#awk 'BEGIN { FS=":" } {print $1,$NF}' /etc/passwd
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
ftp /sbin/nologin
nobody /sbin/nologin
systemd-network /sbin/nologin
dbus /sbin/nologin
polkitd /sbin/nologin
sshd /sbin/nologin
postfix /sbin/nologin
chrony /sbin/nologin
[root@130 ~]#awk 'BEGIN { FS=":" } {print $1,$NF}' /etc/passwd | column -t
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
ftp /sbin/nologin
nobody /sbin/nologin
systemd-network /sbin/nologin
dbus /sbin/nologin
polkitd /sbin/nologin
sshd /sbin/nologin
postfix /sbin/nologin
chrony /sbin/nologin
7.打印出允许登录的用户,结尾是bash的行
awk -v FS=':' '/bash$/{print $1}' /etc/passwd
8.awk截取IP地址的几种方法
[root@nfs-31 ~]#ifconfig eth1 |awk -v FS='[a-zA-Z]+' 'NR==2{print $2}'
172.16.1.31
[root@nfs-31 ~]#
[root@nfs-31 ~]#
[root@nfs-31 ~]#ifconfig eth1 |awk 'NR==2{print $2}'
172.16.1.31
[root@nfs-31 ~]#ifconfig eth1 |awk '/inet\s/{print $2}'
172.16.1.31
# 换成ip 命令
[root@nfs-31 ~]#ip addr show eth1 | awk -v FS='[ /]*' 'NR==3{print $3}'
172.16.1.31
[root@nfs-31 ~]#ip addr show eth1 | awk -v FS='[ /]+' 'NR==3{print $3}'
172.16.1.31
[root@nfs-31 ~]#ip addr show eth1 |awk -F '[ /]*' 'NR==3{print $3}'
172.16.1.31
[root@nfs-31 ~]#ip addr show eth1 |awk -F '[ /]+' 'NR==3{print $3}'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









