






 本文综述了深度学习在单声源和多声源定位中的应用,特别关注了室内环境下存在混响和噪声的场景。研究了基于神经网络架构、输入特征、输出策略和训练方法的文献,并展示了深度学习方法在克服传统方法局限上的优势,如提高DoA分类精度和减少角度误差。
本文综述了深度学习在单声源和多声源定位中的应用,特别关注了室内环境下存在混响和噪声的场景。研究了基于神经网络架构、输入特征、输出策略和训练方法的文献,并展示了深度学习方法在克服传统方法局限上的优势,如提高DoA分类精度和减少角度误差。
Abstract
This article is a survey of deep learning methods for single and multiple sound source localization, with a focus on sound source localization in indoor environments, where reverberation and diffuse noise are present. We provide an extensive topography of the neural network-based sound source localization literature in this context, organized according to the neural network architecture, the type of input features, the output strategy (classification or regression), the types of data used for model training and evaluation, and the model training strategy. Tables summarizing the literature survey are provided at the end of the paper, allowing a quick search of methods with a given set of target characteristics
翻译:
本文综述了用于单声源和多声源定位的深度学习方法,重点研究了存在混响和漫反射噪声的室内环境中的声源定位。在此背景下,我们提供了基于神经网络的声源定位文献的广泛地形,根据神经网络架构、输入特征类型、输出策略(分类或回归)、用于模型训练和评估的数据类型以及模型训练策略进行组织。在论文的末尾提供了总结文献调查的表格,允许快速搜索具有给定目标特征集的方法
I. Introduction
Sound source localization (SSL) is the problem of estimating the position of one or several sound sources relative to some arbitrary reference position, which is generally the position of the recording microphone array, based on the recorded multichannel acoustic signals. In most practical cases, SSL is simplified to the estimation of the sources’ direction of arrival (DoA), i.e., it focuses on the estimation of azimuth and elevation angles, without estimating the distance to the microphone array (therefore, unless otherwise specified, in this article we use the terms “SSL” and “DoA estimation” interchangeably). SSL has numerous practical applications—for instance, in source separation (e.g., Chazan et al, 2019), automatic speech recognition (ASR) (e.g., Lee et al, 2016), speech enhancement (e.g., Xenaki et al, 2018), human-robot interaction, (e.g., Li et al, 2016a), noise control, (e.g., Chiariotti et al, 2019), and room acoustic analysis (e.g., Amengual Garı et al, 2017). In this paper, we focus on sound sources in the audible range (typically speech and audio signals) in indoor (office or domestic) environments.
翻译:
声源定位(SSL)是根据记录的多通道声学信号,估计一个或多个声源相对于某个任意参考位置的位置的问题,该参考位置通常是录音麦克风阵列的位置。在大多数实际情况下,SSL被简化为估计声源的到达方向(DoA),即它侧重于估计方位角和俯仰角,而不估计到达麦克风阵列的距离(因此,除非另有说明,在本文中我们可以互换使用术语“SSL”和“DoA估计”)。SSL有许多实际应用,例如在声源分离中(例如Chazan等,2019年),自动语音识别(ASR)中(例如Lee等,2016年),语音增强中(例如Xenaki等,2018年),人机交互中(例如Li等,2016a),噪声控制中(例如Chiariotti等,2019年)以及房间声学分析中(例如Amengual Garı等,2017年)。在本文中,我们重点关注室内环境(办公室或家庭)中可听到的声源(通常是语音和音频信号)。
总结:
SSL是预测麦克风阵列相对于某个任意参考位置的的方位角与俯仰角
Although SSL is a long-standing and widely researched topic (Argentieri et al, 2015; Benesty et al, 2008; Brandstein and Ward, 2001; Cobos et al, 2017; DiBiase et al, 2001; Gerzon, 1992; Hickling et al, 1993; Knapp and Carter, 1976; Nehorai and Paldi, 1994), it remains a very challenging problem to date. Traditional SSL methods are based on signal/channel models and signal processing (SP) techniques. Although they have shown notable advances in the domain over the years, they are known to perform poorly in difficult yet common scenarios where noise, reverberation, and several simultaneously emitting sound sources may be present (Blandin et al, 2012; Evers et al, 2020). In the last decade, the potential of data-driven deep learning (DL) techniques for addressing such difficult scenarios has received an increasing interest. As a result, an increasing number of SSL systems based on deep neural networks (DNNs) have been proposed in recent years. Most of the reported works have indicated the superiority of DNN-based SSL methods over conventional (i.e., SP-based) SSL methods. For example, Chakrabarty and Habets (2017a) showed that, in low signal-to-noise ratio conditions, using a CNN led to a twofold increase in overall DoA classification accuracy compared to using the conventional method called steered response power with phase transform (SRP-PHAT) (see Sec. III). In Perotin et al (2018b), the authors were able to obtain a 25% increase in DoA classification accuracy when using a convolutional recurrent neural network (CRNN) over a method based on independent component analysis (ICA). Finally, Adavanne et al (2018) proved that employing a CRNN can reduce the average angular error by 50% in reverberant conditions compared to the conventional MUSIC algorithm (see Sec. III).
翻译:
尽管声源定位(SSL)是一个长期存在并且被广泛研究的课题(Argentieri等,2015年;Benesty等,2008年;Brandstein和Ward,2001年;Cobos等,2017年;DiBiase等,2001年;Gerzon,1992年;Hickling等,1993年;Knapp和Carter,1976年;Nehorai和Paldi,1994年),但到目前为止,它仍然是一个非常具有挑战性的问题。传统的SSL方法基于信号/通道模型和信号处理(SP)技术。尽管多年来它们在该领域取得了显著进展,但已知它们在噪声、混响以及可能存在多个同时发射声源的困难但常见的场景中表现不佳(Blandin等,2012年;Evers等,2020年)。在过去的十年中,数据驱动的深度学习(DL)技术在解决这些困难场景方面的潜力引起了越来越多的关注。因此,近年来提出了越来越多基于深度神经网络(DNNs)的SSL系统。大多数报道的研究表明,基于DNN的SSL方法优于传统(即基于SP的)SSL方法。例如,Chakrabarty和Habets(2017a年)表明,在低信噪比条件下,使用CNN相比使用传统方法称为相位转换(SRP-PHAT)可以将整体DoA分类准确性提高一倍(参见第III节)。在Perotin等(2018b年)中,作者使用卷积循环神经网络(CRNN)时,DoA分类准确性提高了25%,相比之下使用基于独立成分分析(ICA)的方法。最后,Adavanne等(2018年)证明了在混响条件下使用CRNN相比于传统的MUSIC算法(参见第III节)可以将平均角度误差降低50%。
总结:
传统算法在噪声、混响以及可能存在多个同时发射声源的困难但常见的场景中表现不佳
深度学习革新传统算法
This kind of result has further motivated the expansion of scientific papers on DL applied to SSL. In the meantime, there has been no comprehensive survey of the existing approaches, which would be very useful for researchers and practitioners in the domain. Although we can find reviews mostly focused on conventional methods, e.g., (Argentieri et al, 2015; Cobos et al, 2017; Evers et al, 2020; Gannot et al, 2019), to the best of our knowledge only a very few have explicitly targeted SSL with DL methods. Ahmad et al (2021) presented a short survey of several existing DL models and datasets for SSL before proposing a DL architecture of their own. Bianco et al (2019) and Purwins et al
(2019) presented an interesting overview of machine learning applied to various problems in audio and acoustics.Nevertheless, only a short portion of each of these two reviews is dedicated to SSL with DNNs.
翻译:
这种结果进一步激发了科学论文在DL应用于SSL领域的扩展。与此同时,尚未对现有方法进行全面的调查,这对该领域的研究人员和实践者将非常有用。尽管我们可以找到主要关注传统方法的评论,例如(Argentieri等,2015年;Cobos等,2017年;Evers等,2020年;Gannot等,2019年),但据我们所知,只有极少数论文明确针对DL方法的SSL进行了调查。Ahmad等人(2021年)在提出自己的DL架构之前,提出了对几种现有DL模型和SSL数据集的简要调查。Bianco等人(2019年)和Purwins等人(2019年)提供了机器学习应用于音频和声学各种问题的有趣概述。然而,这两篇评论中仅有一小部分专门致力于使用DNN进行SSL。
总结:
还没人系统写过深度学习在SSL中的综述
Aim of the paper
总结:
审查了2011年至2021年发表的156篇论文
由于存在大量不同配置的基于DNN的SSL论文,并且这些系统通常在不同的数据集上进行训练和评估,因此对这些贡献进行总结和评论将非常困难和繁琐,所以:
(1)对数据集也进行评价
(2)不会涉及多模态的模型
(3)将主要关注联合任务中的定位任务,即确定声音事件发生的位置
General principle of DL-based SSL
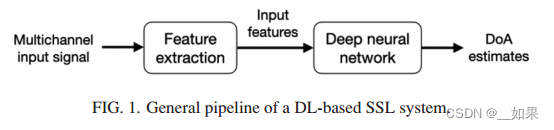
由麦克风阵列记录的信号由特征提取模块提供输入特征,这些输入特征被馈送到DNN中,DNN提供对源位置或DoA的估计
最近的趋势是跳过特征提取模块,直接向网络提供多通道原始数据
无论如何,设计这种SSL背后的两个基本原因如下:
(1)麦克风阵列收集由声源信号与不同麦克风之间的传播路径对应的房间脉冲响应进行卷积得到的混合信号
(2)DNN能很好地处理这些混合信号
II. ACOUSTIC ENVIRONMENT AND SOUND SOURCE CONFIGURATIONS
Multi-source localization is a much more difficult problem than single-source SSL. Current state-of-the-art DL-based methods address multi-source SSL in adverse environments. In this survey, we consider multi-source localization the scenario in which several sources overlap in time (i.e., they are simultaneously emitting), regardless of their type (e.g., there could be several speakers or several distinct sound events). The specific case of a multi-speaker conversation with or without speech overlap is strongly connected to the speaker diarization problem (“who speaks when?”) (Anguera et al, 2012; Park et al, 2021b; Tranter and Reynolds, 2006). Speaker localization, diarization, and (speech) source separation are intrinsically connected problems, as the information retrieved from solving each of them can be useful for addressing the others (Jenrungrot et al, 2020; Kounades-Bastian et al, 2017; Vincent et al, 2018).An investigation of these connections is beyond the scope of this survey.
翻译:
多源定位比单源声源定位问题更加困难。当前最先进的基于深度学习的方法可以解决恶劣环境下的多源声源定位问题。在这项调查中,我们将多源定位定义为多个声源在时间上重叠(即它们同时发射),而不考虑它们的类型(例如,可能有几个说话者或几个不同的声音事件)。具体来说,多说话者对话的情况,无论是否存在语音重叠,与说话者日程安排问题(“谁何时说话?”)密切相关。说话者定位、日程安排以及(语音)源分离是内在联系的问题,因为解决其中一个问题所获得的信息可以用于解决其他问题。这些联系的调查超出了本调查的范围。
总结:
额它这里的多声源定位是指什么?既然不考虑有几个说话者或几个不同的声音事件,那到底预测了个啥???
Source tracking is the problem of estimating the evolution of the sources’ position(s) over time, especially when the sources are mobile. In this survey paper, we do not address the problem of tracking on its own, which is usually done in a separate algorithm using the sequence of DoA estimates obtained by applying SSL on successive time windows (Vo et al, 2015). Still, several DL-based SSL systems have been shown to produce more accurate localization of moving sources when they were trained on a dataset that includes this type of source (Adavanne et al, 2019b; Diaz-Guerra et al, 2021b; Guirguis et al, 2020; He et al, 2021b). In other cases, as the number of real-world datasets with moving sources is limited and the simulation of signals with moving sources is cumbersome, a number of systems trained on static sources have been shown to retain fair to good performance for moving sources, e.g., (Grumiaux et al, 2021a; Opochinsky et al, 2021; Sundar et al, 2020).
翻译:
源追踪是在源移动时估计源位置随时间演变的问题。在这篇调查论文中,我们没有单独讨论追踪问题,通常可以使用应用在连续时间窗口上的DoA估计序列来完成(Vo等人,2015年)。然而,已经证明了几个基于深度学习的声源定位系统在训练集包含这种类型源的情况下,能够更准确地定位移动源(Adavanne等人,2019b年;Diaz-Guerra等人,2021b年;Guirguis等人,2020年;He等人,2021b年)。在其他情况下,由于具有移动源的真实世界数据集数量有限,而模拟带有移动源的信号是困难的,一些训练于静态源上的系统已被证明在移动源情况下保持了良好的性能,例如(Grumiaux等人,2021a年;Opochinsky等人,2021年;Sundar等人,2020年)。
总结:
已经做到了静态模型预测动态位置
III. CONVENTIONAL SSL METHODS
Before the advent of DL, a set of signal processing techniques were developed to address SSL. A detailed review of these techniques was made by DiBiase et al (2001). A review in the specific robotics context was made by Argentieri et al (2015). In this section, we briefly present the most common conventional SSL methods. As briefly stated in the introduction, the reason for this is twofold: first, conventional SSL methods are often used as baselines for DL-based methods; and second, many DL-based SSL methods use input features extracted with conventional methods (see Sec. V).
翻译:
在DL出现之前,开发了一套信号处理技术来处理SSL。DiBiase等人(2001)对这些技术进行了详细的回顾。Argentieri等人(2015)对特定的机器人环境进行了回顾。在本节中,我们简要介绍最常见的常规SSL方法。正如在介绍中简要说明的那样,这样做的原因有两个:首先,传统的SSL方法经常被用作基于dl的方法的基线;其次,许多基于dl的SSL方法使用传统方法提取的输入特征(参见第五节)。
总结:
学这个用来做特征工程
When the geometry of the microphone array is known, DoA estimation can be performed by estimating the timedifference of arrival (TDoA) of the sources between the microphones (Xu et al, 2013). The generalized cross correlation (CC) with phase transform (GCC-PHAT) is one of the most employed method when dealing with a 2-microphone array (Knapp and Carter, 1976). It is computed as the inverse Fourier transform of a weighted version of the crosspower spectrum (CPS) between the signals of the two microphones:
where Xi(f) are the N-point Fourier transform of the microphone signals xi(t), and X1(f)X2(f) is the CPS (* denotes the complex conjugate). The TDoA estimate is then obtained by finding the time delay between the microphone signals that maximizes the GCC-PHAT function,
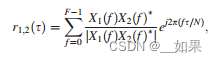
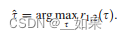
翻译:
当麦克风阵列的几何形状已知时,可以通过估计麦克风之间源的到达时间差(TDoA)来进行DoA估计(Xu et al ., 2013)。广义互相关(CC)与相位变换(gc - phat)是处理双麦克风阵列时最常用的方法之一(Knapp和Carter, 1976)。它被计算为两个麦克风信号间交叉功率谱(CPS)加权后的傅里叶反变换:
式中Xi(f)为麦克风信号Xi(t)的n点傅里叶变换,X1(f)X2(f)为CPS(*表示复共轭)。然后,通过寻找使GCC-PHAT功能最大化的麦克风信号之间的时间延迟来获得TDoA估计。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









