






摘 要
该系统是一个将Python和数据分析相结合的实用应用系统。文章对系统应用设计的主要技术和相关框架进行了详细的说明,并给出了最终的结论分析。首先,使用Python来获取拉勾网中的招聘信息数据。其次,将收集到的数据存储在数据库中,并对结果数据进行再次清理和组织,最后进行可视化分析,以获得相应的统计图、招聘信息推荐等信息。设计该系统的目的是为了帮助求职者从复杂的招聘数据中直观地获取有价值的信息数据。Python可以为数据分析可视化提供思路,在体现数据价值方面发挥着重要作用。因此,在研究数据分析、可视化的过程中,我们可以看到Python具有重要的应用价值。
本系统采用的是 Python 语言,使用Flask框架开发,MySOL为数据库。功能包括公告管理,系统用户(管理员,注册用户),轮播图,资源管理(招聘资讯,资讯分类),模块管理(所在城市,学历要求,工作年限,招聘信息)等。有了本系统之后,可以在一定程度上解决招聘数据分析的专业性问题,明确当前招聘行业的状况,以及辅助分析未来招聘行业发展的趋势。本论文的研究为培养学生的数据处理能力和可视化分析能力奠定了基础。
关键词:拉勾网数据爬取与分析;Python语言;Flask框架;Mysql数据库
ABSTRACT
The system is a practical application system that combines Python with data analysis. This paper gives a detailed description of the main technologies and related frameworks of the system application design, and gives the final conclusion analysis. First of all, use Python to get the recruitment information data in the pull hook network. Secondly, the collected data is stored in the database, and the result data is cleaned and organized again, and finally visual analysis is carried out to obtain the corresponding statistical chart, recruitment information recommendation and other information. The purpose of the system is to help job seekers intuitively obtain valuable information from complex recruitment data. Python can provide ideas for data analysis visualization and plays an important role in reflecting the value of data. Therefore, in the process of data analysis and visualization, we can see that Python has important application value.
The system uses Python language, using Flask framework development, MySOL as the database. Functions include announcement management, system users (administrator, registered user), broadcast map, resource management (recruitment information, information classification), module management (city, education requirements, working years, recruitment information) and so on. With this system, we can solve the professional problems of recruitment data analysis to a certain extent, clarify the current situation of the recruitment industry, and assist in the analysis of the future development trend of the recruitment industry. The research of this paper lays a foundation for cultivating students' data processing ability and visual analysis ability.
Key words : pull hook web data crawling and analysis; Python language; Flask framework; Mysql database
1 绪论
1.1开发背景
随着国内互联网飞速的发展,用户已经越来越习惯于使用互联网传递信息,接收信息,利用互联网技术使得自己的生活更加便利,快捷。在这样一种大趋势下,网上人才招聘系统出现在了用户的眼前。网上人才招聘系统相对于传统的人才招聘,有以下几点优势:1.方便快捷。对于求职者来说,只要在互联网上向有意向的企业投递了个人简历,便可等候企业的通知信息;对于企业来说,只要点一下鼠标便可同意求职者的申请。2.选择多。由于招聘信息量丰富、使用网络招聘的人数基数大,在大量的职位数据库中,求职者对于适合职位的选择也就越多。3.费用少。对于求职者来说,节省了不少成本,如:交通费、简历制作费、通讯费等不少费用。除此之外,还有效地避免了招聘会现场异常拥挤、交流效果不尽如人意、选择职位盲目性大的问题。对于企业来说,节省了办理招聘会的各种费用。正是由于以上种种优势,越来越多的求职者选择网络求职成为自己的应聘方式。但目前招聘软件种类繁多,用户获取信息也需要多方查询甚是不变,也很难深入了解。
当代为数据的时代,一切研究都必将基于数据,也就是说,对于招聘的研究也不例外。因此选择对拉勾网招聘信息作为研究对象是我们可以选择的十分严谨的一种选项。也就是说,需要一款专业的拉勾网数据爬取与分析系统,以更直观的数据看到各种类型的招聘。因此,非常有必要设计、开发一个拉勾网数据爬取与分析系统。
1.2研究现状
人类社会已经进入大数据时代,大数据深刻改变着我们的工作和生活。随着互联网、移动互联网、社交网络等的迅猛发展,各种数量庞大、种类繁多、随时随地产生和更新的大数据,蕴含着前所未有的社会价值和商业价值。拉勾网作为国内知名的招聘网站、积攒了大量招聘数据为招聘行业分析提供了重要资源。
在国外,运用互联网进行人才招聘的企业和求职者不在少数,许多优秀的第三方人才招聘网站也脱颖而出。在美国,优秀的人才招聘网站主要有:1.Beyond.com:每月发布的职位达数十万个。2.Job.com:全美访问量最多的人才招聘网站。3.Monster.com:全球知名的第三方网络招聘服务公司。现在已经在全球二十多个国家设立分部或办事处,并且建立了22种不同语言的招聘网站。其已具备国际领先的网路服务经验,以及庞大的个人简历数据库。
在国内,也有越来越多的网络平台兴起开来,著名的有前程无忧、拉勾网、智联招聘、BOOS直聘、58同城等。据数据统计,2016年中国互联网招聘市场份额正在逐步增加。其中前程无忧占比29.7%,智联招聘占比26.5%,58、赶集合并后共同占比26.3%,其他厂商占比17.5%。与此同时,传统招聘网站的市场份额正在逐渐缩小,2016年,中国互联网招聘公司手机应用软件的使用用户规模达720万人之多,单日人均使用次数为5.5次,单日人均使用时长达15分钟,用户活跃度较去年同期有所增长,手机等移动端的发展趋势较好。许多国家的用户已经对网络招聘的方式深谙其道。网络招聘已经成为当代应届毕业生和职员求职应聘的首选方式。在未来,网络招聘会进一步的发展和完善,受到更多人的青睐。因此,网络招聘网站中的数据如果能得到有效利用将为招聘、应聘效率的提高提供数据支持。
1.3 内容安排
本文主要分为七部分,每部分的具体内容如下:
第一章:绪论。主要对拉勾网数据爬取与分析系统的研究背景、国内外研究现状和论文的研究内容及意义进行了阐述。
第二章:相关理论技术基础。本章主要对在系统开发过程中用到的系统理论和技术基础进行详细的介绍,从理论技术的层面对系统的开发设计与实现进行了描述。
第三章:需求分析。本章主要在对企业需求的基础上,对企业拉勾网数据爬取与分析系统的业务需求、功能需求和非功能性需求等三个方面进行详细的描述与具体设计设计。
第四章:系统设计。本章在第三章系统需求分析的基础上对本拉勾网数据爬取与分析系统的系统架构、功能架构、详细功能等进行了设计;同时,对本系统中需要用到的数据库进行了详细的设计。
第五章:系统实现。本章在以上分析设计的基础上对系统进行了具体的实现,并将部门功能进行了展示,为系统的后期测试打下基础。
第六章:系统测试。本章主要在系统设计与实现的基础上对系统的实用性进行了测试。
第七章:总结与展望。对本系统的分析、设计、实现过程以及系统的发展趋势进行了总结与展望。
2 相关理论与技术
2.1 B/S 架构
B/S结构(Browser/Server,浏览器/服务器模式),是WEB兴起后的一种网络结构模式,WEB浏览器是客户端最主要的应用软件。这种模式统一了客户端,将系统功能实现的核心部分集中到服务器上,简化了系统的开发、维护和使用。客户机上只要安装一个浏览器,如Chrome、Safari、Microsoft Edge、Netscape Navigator或Internet Explorer,服务器安装SQL Server、Oracle、MYSQL等数据库。浏览器通过Web Server同数据库进行数据交互。
B/S架构采取浏览器请求,服务器响应的工作模式。
用户可以通过浏览器去访问Internet上由Web服务器产生的文本、数据、图片、动画、视频点播和声音等信息;
而每一个Web服务器又可以通过各种方式与数据库服务器连接,大量的数据实际存放在数据库服务器中;
从Web服务器上下载程序到本地来执行,在下载过程中若遇到与数据库有关的指令,由Web服务器交给数据库服务器来解释执行,并返回给Web服务器,Web服务器又返回给用户。在这种结构中,将许许多多的网连接到一块,形成一个巨大的网,即全球网。而各个企业可以在此结构的基础上建立自己的Internet。
在 B/S 模式中,用户是通过浏览器针对许多分布于网络上的服务器进行请求访问的,浏览器的请求通过服务器进行处理,并将处理结果以及相应的信息返回给浏览器,其他的数据加工、请求全部都是由Web Server完成的。通过该框架结构以及植入于操作系统内部的浏览器,该结构已经成为了当今软件应用的主流结构模式。
B/S 架构体系如图2-1所示。
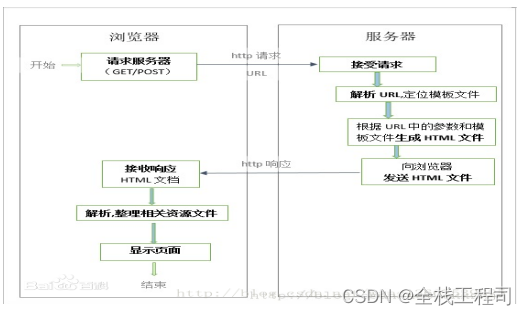
图2-1 B/S架构体系
2.2 Python编程语言
Python是一种开发语言,能够以直译的方式进行计算机语言,而且可以面向对象编程。它是由Guido van Rossum在十九世纪八十年代末研发出来,并且在九一年公开发行使用。Python有很多特点,比如有简洁的语法,清晰的语句,丰富的类库。正式由于这些优点,能够非常快速的和其他语言进行结合,来实现各种功能模块。很多人给它起了个外号叫“黏黏胶”语言。使用Python快速生成程序的原型,是现在很多程序员使用的方法。如果其中有比较特殊要求的地方,也非常方便的进行修改。
而且PyQt具有双证,为它能够跨平台运行(例如UNIX,微软和苹果的平台)提供了保证。
使用Python语言之前,要进行平台的安装,用户需要根据不同的平台,下载不同的版本,然后进行环境变量的配置,便可以进行运行。
Python 特点:
1.相对于其他计算机语言来说学习起来比较简单:Python的关键字较少,结构相对简单,语法简单,对于刚学编程语言的人来说更容易上手。
2.阅读起来也相对简单:Python代码结构简洁明了,并在定义上看起来也非常清晰,所以在阅读的过程中更加简单。
3.维护起来方便:Python的维护简单方便。
4.标准库特别广泛:Python的最大的最大优势是有非常多的库,而且是跨平台的,而且对系统的兼容性很好,比如在UNIX,Windows和Macintosh系统上都能够进行兼容。
5.具有方便的互动模式:有了互动模式的支持,开发者可以从代码就可以看到结果,这样开发者对程序的测试与调试,变的更方便。
6.可移植性好:Python可以跨平台运行。
7.扩展性非常好的:如果有关键的代码,你可以用特殊的语言进行编写,也能够在系统中调试运行。
2.3 Flask框架技术
Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。它可以很好地结合MVC模式进行开发,开发人员分工合作,小型团队在短时间内就可以完成功能丰富的中小型网站或Web服务的实现。另外,Flask还有很强的定制性,用户可以根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,其强大的插件库可以让用户实现个性化的网站定制,开发出功能强大的网站。
Flask是目前十分流行的web框架,采用Python编程语言来实现相关功能。它被称为微框架(microframework),“微”并不是意味着把整个Web应用放入到一个Python文件,微框架中的“微”是指Flask旨在保持代码简洁且易于扩展,Flask框架的主要特征是核心构成比较简单,但具有很强的扩展性和兼容性,程序员可以使用Python语言快速实现一个网站或Web服务。一般情况下,它不会指定数据库和模板引擎等对象,用户可以根据需要自己选择各种数据库。Flask自身不会提供表单验证功能,在项目实施过程中可以自由配置,从而为应用程序开发提供数据库抽象层基础组件,支持进行表单数据合法性验证、文件上传处理、用户身份认证和数据库集成等功能。Flask主要包括Werkzeug和Jinja2两个核心函数库,它们分别负责业务处理和安全方面的功能,这些基础函数为web项目开发过程提供了丰富的基础组件。Werkzeug库十分强大,功能比较完善,支持URL路由请求集成,一次可以响应多个用户的访问请求;支持Cookie和会话管理,通过身份缓存数据建立长久连接关系,并提高用户访问速度;支持交互式Javascript调试,提高用户体验;可以处理HTTP基本事务,快速响应客户端推送过来的访问请求。Jinja2库支持自动HTML转移功能,能够很好控制外部黑客的脚本攻击。系统运行速度很快,页面加载过程会将源码进行编译形成Python字节码,从而实现模板的高效运行;模板继承机制可以对模板内容进行修改和维护,为不同需求的用户提供相应的模板。目前Python的web框架有很多。除了Flask,还有django、Web2py等等。其中Django是目前Python的框架中使用度最高的。但是Django如同java的EJB(EnterpriseJavaBeansJavaEE服务器端组件模型)多被用于大型网站的开发,但对于大多数的小型网站的开发,使用SSH(Struts+Spring+Hibernat的一个JavaEE集成框架)就可以满足,和其他的轻量级框架相比较,Flask框架有很好的扩展性,这是其他Web框架不可替代的。
Flask的基本模式为在程序里将一个视图函数分配给一个URL,每当用户访问这个URL时,系统就会执行给该URL分配好的视图函数,获取函数的返回值并将其显示到浏览器上,其工作过程见图。

2.4 MySQL数据库
科技的进步,给日常带来许多便利:教室的投影器用到了虚拟成像技术,数码相机用到了光电检测技术,比如超市货物进出库的记录需要一个信息仓库。这个信息仓库就是数据库,而这次的智慧仓储数据分析系统也需要这项技术的支持。
用MySQL这个软件,是因为它能接受多个使用者访问,而且里面存在Archive等。它会先把数据进行分类,然后分别保存在表里,这样的特别操作就会提高数据管理系统自身的速度,让数据库能被灵活运用。MySQL的代码是公开的,而且允许别人二次编译升级。这个特点能够降低使用者的成本,再搭配合适的软件后形成一个良好的网站系统。虽然它有缺点,但是综合各方面来说,它是使用者的主流运用的对象。
2.5 本章小结
本章主要描述了在拉勾网数据爬取与分析系统的构建过程中用到的技术路线。主要有系统采用的架构、系统用到的核心技术和在系统搭建过程中用的数据存储技术,对系统的后期搭建提供有力的技术支撑。
3 系统需求分析
3.1 业务需求分析
拉勾网数据爬取与分析系统主要是通过爬取拉勾网招聘信息并进行数据分析,首先主要考虑的是系统功能软件,在具体设计的环节上,是不是能够较好的满足各类用户的基本功能需求,如果不能较好的满足用户需求,那么这个系统的存在是没有价值的。软件系统的非功能性求分析,从7个方面展开,一个是性能分析,针对系统;一个是安全分析,针对系统,一个是完整度分析,针对系统,一个是可维护分析,针对系统,一个是可扩展性分析,针对系统,一个是适应业务的性能分析。面对拉勾网数据爬取与分析系统存在的性能、安全、扩展、完整度等7个方面性能综合比对分析后发现,需要相应的非功能性需求分析。
3.2 功能需求分析
因此系统在开发的过程中根据目前类似系统运行情况将系统的需求分成以下功能构件:首页,公告管理,系统用户,轮播图,资源管理,所在城市,学历要求,工作年限,招聘信息。以上功能彼此相互协调,在信息上进行资源共享,达到提高工作效率,改善系统性能的目的。
3.3 本章小结
本章通过对拉勾网数据爬取与分析系统的业务需求进行认真分析,然后对拉勾网数据爬取与分析系统的功能进行了需求分析并给出了各个功能构件的用例图和用例描述,为后期系统的设计与实现打下坚实基础。
4 系统功能与数据库设计
根据需求分析的结果,需要对系统进行功能结构设计。本章主要是在系统需求分析的基础上实现了拉勾网数据爬取与分析系统的功能性结构设计和后台数据库设计。
4.1 系统功能总体设计
对于拉勾网数据爬取与分析系统,依据业务需求分析,系统前端部分基于MVVM模式进行开发,采用B/S模式,后端部分基于python的Flask框架进行开发。
前端部分:前端框架采用了比较流行的渐进式JavaScript框架Vue.js。使用Vue-Router和Vuex实现动态路由和全局状态管理,Ajax实现前后端通信,Element UI组件库使页面快速成型,项目前端通过栅格布局实现响应式,可适应PC端、平板端、手机端等不同屏幕大小尺寸的完美布局展示。后端部分:基于python语言以Flask作为开发框架,同时集成Redis,Echarts等相关技术。最终设计了系统的总体结构包图如图4-1所示。

图 4-1 系统总体结构包图
4.2 系统功能详细设计
用户在此模块可以查看管理员发布的招聘资讯,具体内容包括招聘资讯的封面,标题,正文等信息。在详情页面可以进行评论,收藏,点赞等操作。
(2)招聘信息
用户在此页面可以查看招聘信息的详细情况,包括职位名称,公司名称,所在城市,学历要求等信息,管理员对招聘信息进行维护管理。
(3)用户管理
用户在前台通过填写用户名,姓名,性别,手机,邮箱等个人信息进行注册,管理员对用户及管理员信息进行维护管理。
4.3 数据库设计
4.3.1 数据库概念设计
数据库是用来存放系统运行的数据信息的,本系统的数据库是通过对拉勾网数据爬取与分析系统的需求分析与功能流程分析的基础上,设计出本系统数据库的主要实体有:管理员,用户,招聘信息表,资讯表等基本实体,他们彼此之间相互联系。其对应的实体分别为:
(1)用户实体:实体图如图4-2所示。

图4-2 用户实体图
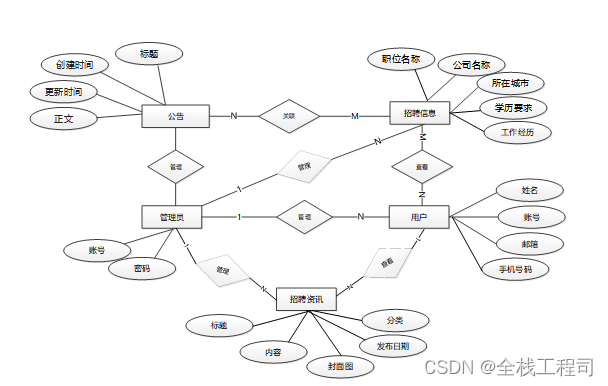
图4-11系统E-R图
4.3.2 数据库逻辑设计
系统中难免会涉及到大量的信息存储,为了更好的对信息进行管理需要用到数据库,可以将数据存放到数据表中。根据数据库的实体图可以设计出拉勾网数据爬取与分析系统的数据库逻辑结构。将数据库概念设计的E-R图转换为关系数据库。在关系数据库中,数据关系由数据表组成,但是表的结构表现在表的字段上。
表。
表access_token (登陆访问时长)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | token_id | int | 10 | 0 | N | Y | 临时访问牌ID | |
| 2 | token | varchar | 64 | 0 | Y | N | 临时访问牌 | |
| 3 | info | text | 65535 | 0 | Y | N | ||
| 4 | maxage | int | 10 | 0 | N | N | 2 | 最大寿命:默认2小时 |
| 5 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 6 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 7 | user_id | int | 10 | 0 | N | N | 0 | 用户编号: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | article_id | mediumint | 8 | 0 | N | Y | 文章id:[0,8388607] | |
| 2 | title | varchar | 125 | 0 | N | Y | 标题:[0,125]用于文章和html的title标签中 | |
| 3 | type | varchar | 64 | 0 | N | N | 0 | 文章分类:[0,1000]用来搜索指定类型的文章 |
| 4 | hits | int | 10 | 0 | N | N | 0 | 点击数:[0,1000000000]访问这篇文章的人次 |
| 5 | praise_len | int | 10 | 0 | N | N | 0 | 点赞数 |
| 6 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 7 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 8 | source | varchar | 255 | 0 | Y | N | 来源:[0,255]文章的出处 | |
| 9 | url | varchar | 255 | 0 | Y | N | 来源地址:[0,255]用于跳转到发布该文章的网站 | |
| 10 | tag | varchar | 255 | 0 | Y | N | 标签:[0,255]用于标注文章所属相关内容,多个标签用空格隔开 | |
| 11 | content | longtext | 2147483647 | 0 | Y | N | 正文:文章的主体内容 | |
| 12 | img | varchar | 255 | 0 | Y | N | 封面图 | |
| 13 | description | text | 65535 | 0 | Y | N | 文章描述 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | type_id | smallint | 5 | 0 | N | Y | 分类ID:[0,10000] | |
| 2 | display | smallint | 5 | 0 | N | N | 100 | 显示顺序:[0,1000]决定分类显示的先后顺序 |
| 3 | name | varchar | 16 | 0 | N | N | 分类名称:[2,16] | |
| 4 | father_id | smallint | 5 | 0 | N | N | 0 | 上级分类ID:[0,32767] |
| 5 | description | varchar | 255 | 0 | Y | N | 描述:[0,255]描述该分类的作用 | |
| 6 | icon | text | 65535 | 0 | Y | N | 分类图标: | |
| 7 | url | varchar | 255 | 0 | Y | N | 外链地址:[0,255]如果该分类是跳转到其他网站的情况下,就在该URL上设置 | |
| 8 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 9 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | auth_id | int | 10 | 0 | N | Y | 授权ID: | |
| 2 | user_group | varchar | 64 | 0 | Y | N | 用户组: | |
| 3 | mod_name | varchar | 64 | 0 | Y | N | 模块名: | |
| 4 | table_name | varchar | 64 | 0 | Y | N | 表名: | |
| 5 | page_title | varchar | 255 | 0 | Y | N | 页面标题: | |
| 6 | path | varchar | 255 | 0 | Y | N | 路由路径: | |
| 7 | position | varchar | 32 | 0 | Y | N | 位置: | |
| 8 | mode | varchar | 32 | 0 | N | N | _blank | 跳转方式: |
| 9 | add | tinyint | 3 | 0 | N | N | 1 | 是否可增加: |
| 10 | del | tinyint | 3 | 0 | N | N | 1 | 是否可删除: |
| 11 | set | tinyint | 3 | 0 | N | N | 1 | 是否可修改: |
| 12 | get | tinyint | 3 | 0 | N | N | 1 | 是否可查看: |
| 13 | field_add | text | 65535 | 0 | Y | N | 添加字段: | |
| 14 | field_set | text | 65535 | 0 | Y | N | 修改字段: | |
| 15 | field_get | text | 65535 | 0 | Y | N | 查询字段: | |
| 16 | table_nav_name | varchar | 500 | 0 | Y | N | 跨表导航名称: | |
| 17 | table_nav | varchar | 500 | 0 | Y | N | 跨表导航: | |
| 18 | option | text | 65535 | 0 | Y | N | 配置: | |
| 19 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 20 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | city_id | int | 10 | 0 | N | Y | 所在城市ID | |
| 2 | city | varchar | 64 | 0 | Y | N | 所在城市 | |
| 3 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 4 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 5 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | collect_id | int | 10 | 0 | N | Y | 收藏ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 收藏人ID: |
| 3 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 4 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 5 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 6 | title | varchar | 255 | 0 | Y | N | 标题: | |
| 7 | img | varchar | 255 | 0 | Y | N | 封面: | |
| 8 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 9 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | comment_id | int | 10 | 0 | N | Y | 评论ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 评论人ID: |
| 3 | reply_to_id | int | 10 | 0 | N | N | 0 | 回复评论ID:空为0 |
| 4 | content | longtext | 2147483647 | 0 | Y | N | 内容: | |
| 5 | nickname | varchar | 255 | 0 | Y | N | 昵称: | |
| 6 | avatar | varchar | 255 | 0 | Y | N | 头像地址:[0,255] | |
| 7 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 8 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 9 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 10 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 11 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
表educational_requirements (学历要求)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | educational_requirements_id | int | 10 | 0 | N | Y | 学历要求ID | |
| 2 | educational_requirements | varchar | 64 | 0 | Y | N | 学历要求 | |
| 3 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 4 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 5 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | hits_id | int | 10 | 0 | N | Y | 点赞ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 点赞人: |
| 3 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 4 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | notice_id | mediumint | 8 | 0 | N | Y | 公告id: | |
| 2 | title | varchar | 125 | 0 | N | N | 标题: | |
| 3 | content | longtext | 2147483647 | 0 | Y | N | 正文: | |
| 4 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 5 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | praise_id | int | 10 | 0 | N | Y | 点赞ID: | |
| 2 | user_id | int | 10 | 0 | N | N | 0 | 点赞人: |
| 3 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 4 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 8 | status | bit | 1 | 0 | N | N | 1 | 点赞状态:1为点赞,0已取消 |
表recruitment_information (招聘信息)
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | recruitment_information_id | int | 10 | 0 | N | Y | 招聘信息ID | |
| 2 | job_number | varchar | 64 | 0 | Y | N | 岗位编号 | |
| 3 | job_title | varchar | 64 | 0 | Y | N | 职位名称 | |
| 4 | corporate_name | varchar | 64 | 0 | Y | N | 公司名称 | |
| 5 | city | varchar | 64 | 0 | Y | N | 所在城市 | |
| 6 | educational_requirements | varchar | 64 | 0 | Y | N | 学历要求 | |
| 7 | hands_on_background | varchar | 64 | 0 | Y | N | 工作经验 | |
| 8 | work_location | varchar | 64 | 0 | Y | N | 工作地点 | |
| 9 | salary | varchar | 64 | 0 | Y | N | 薪资 | |
| 10 | years_of_work | varchar | 64 | 0 | Y | N | 工作年限 | |
| 11 | hits | int | 10 | 0 | N | N | 0 | 点击数 |
| 12 | praise_len | int | 10 | 0 | N | N | 0 | 点赞数 |
| 13 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 14 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 15 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | registered_users_id | int | 10 | 0 | N | Y | 注册用户ID | |
| 2 | user_name | varchar | 64 | 0 | Y | N | 用户姓名 | |
| 3 | user_gender | varchar | 64 | 0 | Y | N | 用户性别 | |
| 4 | examine_state | varchar | 16 | 0 | N | N | 已通过 | 审核状态 |
| 5 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 6 | user_id | int | 10 | 0 | N | N | 0 | 用户ID |
| 7 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 8 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | slides_id | int | 10 | 0 | N | Y | 轮播图ID: | |
| 2 | title | varchar | 64 | 0 | Y | N | 标题: | |
| 3 | content | varchar | 255 | 0 | Y | N | 内容: | |
| 4 | url | varchar | 255 | 0 | Y | N | 链接: | |
| 5 | img | varchar | 255 | 0 | Y | N | 轮播图: | |
| 6 | hits | int | 10 | 0 | N | N | 0 | 点击量: |
| 7 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 8 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | upload_id | int | 10 | 0 | N | Y | 上传ID | |
| 2 | name | varchar | 64 | 0 | Y | N | 文件名 | |
| 3 | path | varchar | 255 | 0 | Y | N | 访问路径 | |
| 4 | file | varchar | 255 | 0 | Y | N | 文件路径 | |
| 5 | display | varchar | 255 | 0 | Y | N | 显示顺序 | |
| 6 | father_id | int | 10 | 0 | Y | N | 0 | 父级ID |
| 7 | dir | varchar | 255 | 0 | Y | N | 文件夹 | |
| 8 | type | varchar | 32 | 0 | Y | N | 文件类型 |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | user_id | mediumint | 8 | 0 | N | Y | 用户ID:[0,8388607]用户获取其他与用户相关的数据 | |
| 2 | state | smallint | 5 | 0 | N | N | 1 | 账户状态:[0,10](1可用|2异常|3已冻结|4已注销) |
| 3 | user_group | varchar | 32 | 0 | Y | N | 所在用户组:[0,32767]决定用户身份和权限 | |
| 4 | login_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 上次登录时间: |
| 5 | phone | varchar | 11 | 0 | Y | N | 手机号码:[0,11]用户的手机号码,用于找回密码时或登录时 | |
| 6 | phone_state | smallint | 5 | 0 | N | N | 0 | 手机认证:[0,1](0未认证|1审核中|2已认证) |
| 7 | username | varchar | 16 | 0 | N | N | 用户名:[0,16]用户登录时所用的账户名称 | |
| 8 | nickname | varchar | 16 | 0 | Y | N | 昵称:[0,16] | |
| 9 | password | varchar | 64 | 0 | N | N | 密码:[0,32]用户登录所需的密码,由6-16位数字或英文组成 | |
| 10 | | varchar | 64 | 0 | Y | N | 邮箱:[0,64]用户的邮箱,用于找回密码时或登录时 | |
| 11 | email_state | smallint | 5 | 0 | N | N | 0 | 邮箱认证:[0,1](0未认证|1审核中|2已认证) |
| 12 | avatar | varchar | 255 | 0 | Y | N | 头像地址:[0,255] | |
| 13 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | group_id | mediumint | 8 | 0 | N | Y | 用户组ID:[0,8388607] | |
| 2 | display | smallint | 5 | 0 | N | N | 100 | 显示顺序:[0,1000] |
| 3 | name | varchar | 16 | 0 | N | N | 名称:[0,16] | |
| 4 | description | varchar | 255 | 0 | Y | N | 描述:[0,255]描述该用户组的特点或权限范围 | |
| 5 | source_table | varchar | 255 | 0 | Y | N | 来源表: | |
| 6 | source_field | varchar | 255 | 0 | Y | N | 来源字段: | |
| 7 | source_id | int | 10 | 0 | N | N | 0 | 来源ID: |
| 8 | register | smallint | 5 | 0 | Y | N | 0 | 注册位置: |
| 9 | create_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间: |
| 10 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间: |
| 编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 | 说明 |
| 1 | years_of_work_id | int | 10 | 0 | N | Y | 工作年限ID | |
| 2 | corporate_name | varchar | 64 | 0 | Y | N | 公司名称 | |
| 3 | years_of_work | int | 10 | 0 | Y | N | 0 | 工作年限 |
| 4 | recommend | int | 10 | 0 | N | N | 0 | 智能推荐 |
| 5 | create_time | datetime | 19 | 0 | N | N | CURRENT_TIMESTAMP | 创建时间 |
| 6 | update_time | timestamp | 19 | 0 | N | N | CURRENT_TIMESTAMP | 更新时间 |
4.4 本章小结
本章在前述业务流程的基础上对系统的功能进行了详细设计,并给出了部分功能的活动图,同时根据系统数据存储的要求对系统的数据库进行了详细的逻辑设计和物理设计,为系统的具体实现打下坚实的基础。
5 系统实现
5.1 登录模块的实现
该登录模块利用js进行设计,JavaScript函数CheckSubmit()对输入框是否为空进行验证,使用js的技术结合Mysql 2012数据库的查询语句进行登录信息的验证。首先从文本框中分别获得账号user_name和密码user_pw,使用Sql语句“select * from t_user where user_name=‘”+user_name+“’ and user_pw=‘”+user_pw+“’”将查询结果赋给rs结果集,若rs.next()返回值为空,表示数据库找不到该用户数据,若rs.next()返回值不为空,则显示登录成功,进入主界面。
用户登录流程图如下所示。

图 5-1用户登录界面
用户登录流程:用户只有输入正确的用户名和密码才会成功进入系统,用户输入
用户名密码后点击登录按钮,系统会进行校验该用户名是否存在,如果用户名与密码不匹配或者用户名不存在,则返回主界面。系统登录界面如下图所示。
图5-2系统登录界面
登录功能的逻辑代码如下所示。
/**
* 登录
* @param data
* @param httpServletRequest
* @return
*/
@PostMapping("login")
public Map<String, Object> login(@RequestBody Map<String, String> data, HttpServletRequest httpServletRequest) {
log.info("[执行登录接口]");
String username = data.get("username");
String email = data.get("email");
String phone = data.get("phone");
String password = data.get("password");
List resultList = null;
Map<String, String> map = new HashMap<>();
if(username != null && "".equals(username) == false){
map.put("username", username);
resultList = service.select(map, new HashMap<>()).getResultList();
}
else if(email != null && "".equals(email) == false){
map.put("email", email);
resultList = service.select(map, new HashMap<>()).getResultList();
}
else if(phone != null && "".equals(phone) == false){
map.put("phone", phone);
resultList = service.select(map, new HashMap<>()).getResultList();
}else{
return error(30000, "账号或密码不能为空");
}
if (resultList == null || password == null) {
return error(30000, "账号或密码不能为空");
}
//判断是否有这个用户
if (resultList.size()<=0){
return error(30000,"用户不存在");
}
User byUsername = (User) resultList.get(0);
Map<String, String> groupMap = new HashMap<>();
groupMap.put("name",byUsername.getUserGroup());
List groupList = userGroupService.select(groupMap, new HashMap<>()).getResultList();
if (groupList.size()<1){
return error(30000,"用户组不存在");
}
UserGroup userGroup = (UserGroup) groupList.get(0);
//查询用户审核状态
if (!StringUtils.isEmpty(userGroup.getSourceTable())){
String sql = "select examine_state from "+ userGroup.getSourceTable() +" WHERE user_id = " + byUsername.getUserId();
String res = String.valueOf(service.runCountSql(sql).getSingleResult());
if (res==null){
return error(30000,"用户不存在");
}
if (!res.equals("已通过")){
return error(30000,"该用户审核未通过");
}
}
登录成功后用户便进入到拉勾网数据爬取与分析系统主界面,在本界面中用户可以对系统的相应功能进行操作,本系统主要功能有首页,公告,招聘资讯,招聘信息,我的(我的账户,我的收藏,个人中心)。

图5-2 拉勾网数据爬取与分析系统主界面
5.2 招聘资讯模块
在此页面可查看招聘资讯的信息,包括封面,标题,正文等信息。在详情页面可以进行评论,收藏,点赞等操作。管理员对招聘资讯进行维护管理,具体功能有查询,重置,删除,添加等。如下图所示。

图5-3 招聘资讯主界面
图5-4 招聘资讯管理界面

图5-5 招聘资讯添加界面
5.3 招聘信息模块
在此页面可查看招聘信息,包括职位名称,公司名称,所在城市,学历要求等信息。在详情页面可以进行评论,收藏,点赞等操作。管理员对招聘信息进行维护管理,具体功能有查询,重置,删除,添加等。如下图所示。

图5-6 招聘信息主界面

图5-7 招聘信息详情主界面

图5-8 招聘信息管理界面
图5-9 招聘信息添加导入界面
5.3 用户管理模块
管理员在此页面可以查看用户信息,包括昵称,用户名,用户姓名,性别等信息,具体功能有查询,重置,删除,添加等。如下图所示。

图5-10用户管理界面
5.4 统计图模块
管理员在模块页面可以对招聘信息中的所在城市,学历要求,工作年限等信息进行维护,在此更新后后台首页中的统计图将自动同步。如下图所示。
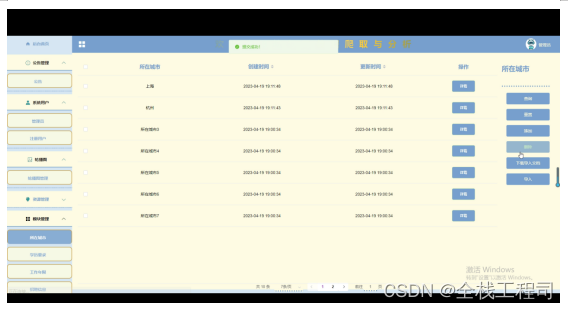
图5-11所在城市维护
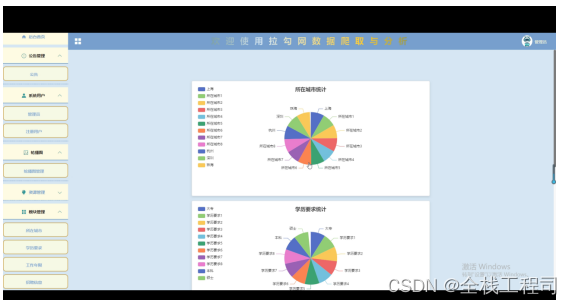
图5-12所在城市统计图
6 系统测试
6.1 测试概述
程序设计不能保证没有错误,这是一个开发过程,在错误或错误的过程中都是难以避免的。虽然这是不可避免的,但我们不能使这些错误始终存在于系统中,错误可能会造成无法估量的后果,如系统崩溃,安全信息泄露,系统无法正常启动等,为了避免这些问题,我们需要测试程序,再测试过程中发现问题,并纠正它们,从而使系统更长时间稳定成熟。本章的作用是发现这些问题,并对其进行修改,虽然耗时费力,但对于长期使用而言是非常重要和必要系统的开发。
软件在设计后必须进行测试,调试过程中使用的方法是软件测试方法。在开发新软件时,系统测试是检查软件是否合格的关键步骤,以及是否符合设计目标的参考。测试主要是查看软件中数据的准确性,正确的操作与否,以及操作的结果,还有哪些方面需要改进。
拉勾网数据爬取与分析系统的实现,对于系统中功能模块的实现及操作都必须通过测试进行来评判系统是否可以准确的实现。在多角色拉勾网数据爬取与分析系统正式上传使用之前必须做的一步就是系统测试,对于测试发现的错误及时修改处理,保证系统准确无误的供给用户使用。
6.2 测试配置
(1)测试环境
系统一旦开发完成以后就要对系统进行测试,在本测试过程中对系统的运行环境平台环境如表6-1所示.
表6-1 系统测试环境
| 环 境 | 配 置 | 备 注 |
| Web服务器(硬件) | 联想 CPU:2.0*2 内存:8G 硬盘:300GB | 100/1000M局域网卡 |
| 数据库服务器(硬件) | 联想 CPU:2.0*2 内存:16G 硬盘:500GB | 100/1000M局域网卡 |
| 操作系统(软件) | Windows XP或Windows 7及以上操作系统 | |
| Web服务器(软件) | JDK 7.0 Tomcat 8.0 | |
| 数据库服务器(软件) | SQL Server 2008 数据库 | |
| 客户机若干 | 联想家用电脑常规配置 | 满足基本的网络运行条件即可 |
(2)测试工具
在对本拉勾网数据爬取与分析系统进行功能测试时采用了当前流行的测试工具WinRunner;对系统进行性能测试时采用用户信息管理软件dRunner。这两款软件性能优越,操作简单,是进行测试的必备工具软件。
(3)测试流程
在对多角色拉勾网数据爬取与分析系统进行测试的时候在找到问题的情况下必须在第一时间找到解决问题的办法,不要存在侥幸的心理,这样才能让多角色拉勾网数据爬取与分析系统开发的质量可以过关,并且开发的周期会大大缩短,还有就是在测试时,不要出现重复性的错误,遇到一个错误问题,要将整个多角色拉勾网数据爬取与分析系统开发所牵扯的该问题都必须一一解决,提高多角色拉勾网数据爬取与分析系统平台的安全性、稳定性。
白盒测试与黑盒测试是测试中比较常用的两种方法。
①结构测试俗称白盒测试:这种测试是在对程序的处理过程与结构都有详尽谅解的前提下,顺从程序内部的逻辑而完成的系统测试,以确定系统中所有的通路都能够遵照设计要求正常工作,不出现任何偏差。
②功能测试又成黑盒测试:主要是针对程序功能能够按照设计正常实现的一种检测,在程序接口处进行,检测程序手法数据是否正常,与外部信息的交换是否完整。
6.3 测试用例
用户登录测试:
| 模块名称 | 测试用例 | 预期结果 | 实际结果 | 是否通过 |
| 登录模块 | 用户名:admin 密码:123 | 弹出错误提示,提示密码错误 | 弹出错误提示,提示密码错误 | 通过 |
| 登录模块 | 用户名:123 密码:admin | 弹出错误提示,提示用户名错误 | 弹出错误提示,提示用户名错误 | 通过 |
| 登录模块 | 用户名:admin 密码:admin | 管理员登录成功 | 管理员登录成功 | 通过 |
修改密码测试:
| 模块名称 | 测试用例 | 预期结果 | 实际结果 | 是否通过 |
| 修改密码模块 | 原密码:666 新密码:123 确认密码:123 | 弹出错误提示,提示原密码错误 | 弹出错误提示,提示原密码错误 | 通过 |
| 修改密码模块 | 原密码:admin 新密码:123 确认密码:333 | 弹出错误提示,提示确认密码不一致 | 弹出错误提示,提示确认密码不一致 | 通过 |
| 修改密码模块 | 原密码:admin 新密码:123 确认密码:123 | 密码修改成功 | 密码修改成功 | 通过 |
通过对功能的测试,多角色在线考试系统的基本功能都是可行的,不管是系统里面的功能,还是界面的设计都是可值得推广宣传的。
6.4 测试结果分析
通过对拉勾网数据爬取与分析系统的测试,测试结果表明本系统能够完全的完成之前对系统的的功能需求分析。本系统良好的操作界面和菜单功能设计能够给操作者提供良好的视觉效果,具备了简单、美观的界面设计效果,达到了系统设计的目的。
7 总结与展望
7.1总结
此时项目已经完成,即使实施的时间不是很长,但是这个过程中需要准备很长的一段时间去对系统设计开发所相关技术进行学习。在学习的过程中,我逐渐认识得到了我自身存在的一些不足。从该系统中,系统的分析和设计的调查数据,并且已经经历和努力了几个月,最终完成了系统。很显然,该系统仍有很多不成熟的地方,在系统设计过程中有许多技术缺陷存在。在设计的过程中也涉及到了很多自己无法解决的问题,主要通过咨询老师解决这些问题,对于毕业设计的圆满完成,需要感谢老师们的指导。系统的开发环境和配置都是可以自行安装的,系统使用Java开发工具,使用比较成熟的Mysql数据库进行对系统前台及后台的数据交互,根据技术语言对数据库,结合需求进行修改维护,可以使得系统运行更具有稳定性和安全性,从而完成实现系统的开发。
回顾毕业设计的整个过程,既付出汗水也收获了很多。虽然经历了各种各样的困难,自己的不断研究探索,系统的实现仍有不足之处。
在以后的学习及工作中,我仍然继续学习计算机方面的技术,让我在后期的平台开发中可以更好更快的实现需求功能。我相信我可以让更多的好工作,做出更大的贡献。
7.2 展望
在信息量爆炸的今天,数据分析及可视化系统早已得到广泛运用,满足数据分析需求,充分显示了其管理的优越性与可用性。
从本系统的开发设计与实现看,目前拉勾网数据爬取与分析系统还存在如下问题:
(1)如何将外部的招聘数据更加科学合理的进行共享,如何将后台数据库中的数据进行自动的优化仍有待解决。
(2)如何对拉勾网数据爬取与分析系统与大数据以及互联网相结合,实现信息的网络化和智能化仍需要研究。
在以后的工作学习中将对系统继续完善,对相应的问题进行优化、解决。
参考文献
[1]罗燕.基于Python对人工智能类招聘信息的爬取与分析[J].石家庄职业技术学院学报,2022,34(06):9-17.
[2]苏明焱.基于Python的招聘网站信息的爬取与数据分析[J].信息与电脑(理论版),2022,34(24):193-195.
[3]王小春,张鸿飞.以Python实现实验室学生信息管理系统[J].电脑编程技巧与维护,2022(10):117-118+166.DOI:10.16184/j.cnki.comprg.2022.10.046.
[4]裴丽丽.基于Selenium框架实现Boss直聘网数据爬取与分析[J].山西电子技术,2022(05):66-68+76.
[5]张嘉威,关成斌.基于Python和Selenium的智联招聘数据的爬取与分析[J].软件,2022,43(08):170-175.
[6]Hu Xi,Song Jialin,Chyr Jacqueline,Wan Jinping,Wang Xiaoyan,Du Jianqiang,Duan Junbo,Zhang Huqin,Zhou Xiaobo,Wu Xiaoming. APAview: A web-based platform for alternative polyadenylation analyses in hematological cancers[J]. Frontiers in Genetics,2022,13.
[7]刘秀丽.基于Python语言的好友管理系统的设计[J].现代信息科技,2022,6(15):6-10.DOI:10.19850/j.cnki.2096-4706.2022.15.002.
[8]何佳颖,朱豪,李沂霏,潘永平.基于python的作业文件管理系统[J].信息技术与信息化,2022(06):64-68.
[9]田胜男. 基于Flask的智能小区物业管理系统设计与实现[D].华东师范大学,2022.DOI:10.27149/d.cnki.ghdsu.2022.003638.
[10]张宁. 基于Flask框架的四六级英语学习系统的设计与实现[D].华东师范大学,2022.DOI:10.27149/d.cnki.ghdsu.2022.002537.
[11]贾宗星,冯倩.基于Python的拉勾网数据爬取与分析[J].计算机时代,2022(02):5-7+11.DOI:10.16644/j.cnki.cn33-1094/tp.2022.02.002.
[12]Rodríguez-Valenzuela Francisco Javier,González-Meza Omar Alejandro,González Gutiérrez Ana Gabriela,Bárcena-Soto Maximiliano,Larios-Durán Roxana,Casillas Norberto. Development of an Application in Python Language to Simulate Cyclic Voltammograms with Multiple Reaction Mechanisms.[J]. Electrochemical Society Transactions,2022,106(1).
[13]丁文浩,朱齐亮.基于Python的招聘数据爬取与分析[J].网络安全技术与应用,2022(01):43-45.
[14]汪邦博,胡必波,李满,刘丝雨,刘晓莉.基于Scrapy的大数据学情分析系统就业岗位数据爬取[J].电脑编程技巧与维护,2021(11):92-93+120.DOI:10.16184/j.cnki.comprg.2021.11.034.
[15]刘影.基于Python的房价数据爬取及可视化分析[J].信息与电脑(理论版),2021,33(18):188-190.
[16]Leandro Daniel Lau Alfonso,Sergio Suarez Guerra,Jose Luis Oropeza Rodriguez,Roberto Rodriguez Morales,Gustavo Asumu Mboro Nchama. Python Language Training System Based on MFCC, VQ, Variational Coefficient and KNTM Algorithm[J]. Mathematics and Computer Science,2021,6(2).
[17]文鹏,袁小艳.基于Python的招聘信息爬取和分析[J].信息与电脑(理论版),2021,33(09):65-67.
[18]Uzo Izuchukwu Uchenna,Ugboaja Samuel Gregory,Ugwu Nnaemeka Virginus,Obayi Adaora Angela,Chigbundu Kanu Enyioma,Nnamdi Johnson Ezeora,Okwueze Chisom Nneoma,Anigbogu Kenechukwu,Ihedioha Uchechi Michael. Exploring a Secured Socket Python Flask Framework in Real Time Communication System[J]. Asian Journal of Research in Computer Science,2021.
[19]Divya Peketi,Varma Mahesh,Ratna Mouli Uma,Srinivas,Garima,Nikhil,Vishistha. Web based optical character recognition application using flask and tesseract[J]. Materials Today: Proceedings,2021(prepublish).
[20]刘晓知.基于Python的招聘网站信息爬取与数据分析[J].电子测试,2020(12):75-76+110.DOI:10.16520/j.cnki.1000-8519.2020.12.027.
致 谢
系统的完成,如何实现的更好,其中付出的努力是很大的,这段时光将会终身难忘。首先要感谢我的指导老师,谢谢您在设计和论文中给我的指导。在您的细心指导下我才能快速的掌握系统的相关功能,在您的大力帮助下我才能将课本上的知识与自己的项目结合,真正的做到学以致用。感谢您经常牺牲自己的休息时间,利用其丰富的教学和项目经验对我进行指导。
感谢所有教过我的老师,为我倾注了大量的心血,正是你们的谆谆教诲、严谨教学才使我能顺利的完成学业,再此向你们表示深深的感谢。感谢我的同学们,对我的大力支持及帮助,正是你们不断的帮助、鼓励,给我带来了极大的动力,最终系统可以顺利的运行。我们在交流、谈论的这段时间,将是我未来的财富,我要深深地感谢你们。毕业在即,在今后的工作和生活中,我会铭记师长们的教诲、同学们的帮助,继续不懈努力和追求,来报答所有支持和帮助过我的人。














 3210
3210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









