






1.mysql的常用命令:
| show database | 显示所有数据库 |
| mysql -uroot -p | 连接数据库 |
| creat database 数据库名 | 创建数据库 要避免重复 |
| drop database 数据库名 | 删除数据库 |
| use 数据库名 | 使用数据库 |
2.列属性
2.1主键(primary key)
唯一标识表中的记录的一个或一组列称为主键
特点:不能重复,不能为空,一个表只有一个主键
作用:保证数据的完整性,加快查询速度
2.2自动增长(auto_inrement)
2.3唯一键(unique)
不能重复 可以为空,一个表可以有多个唯一键
2.4是否为空(null | not null)
2.5 默认值(default)
3.数据类型
3.1数值型
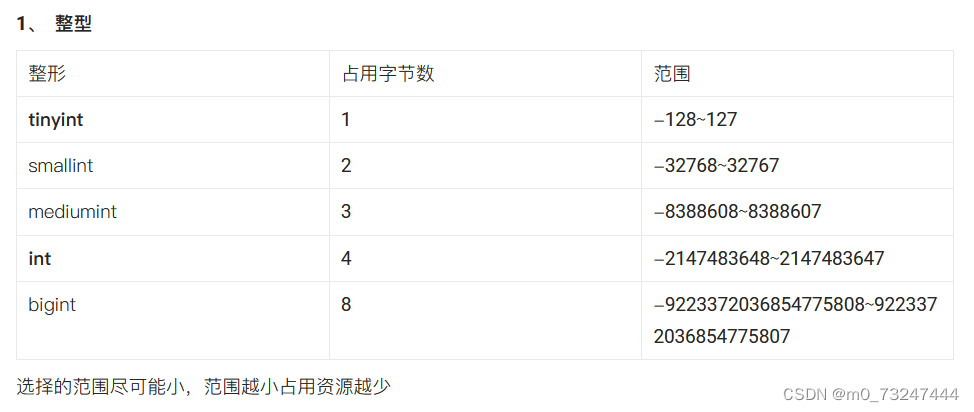
浮点型

3.2字符型
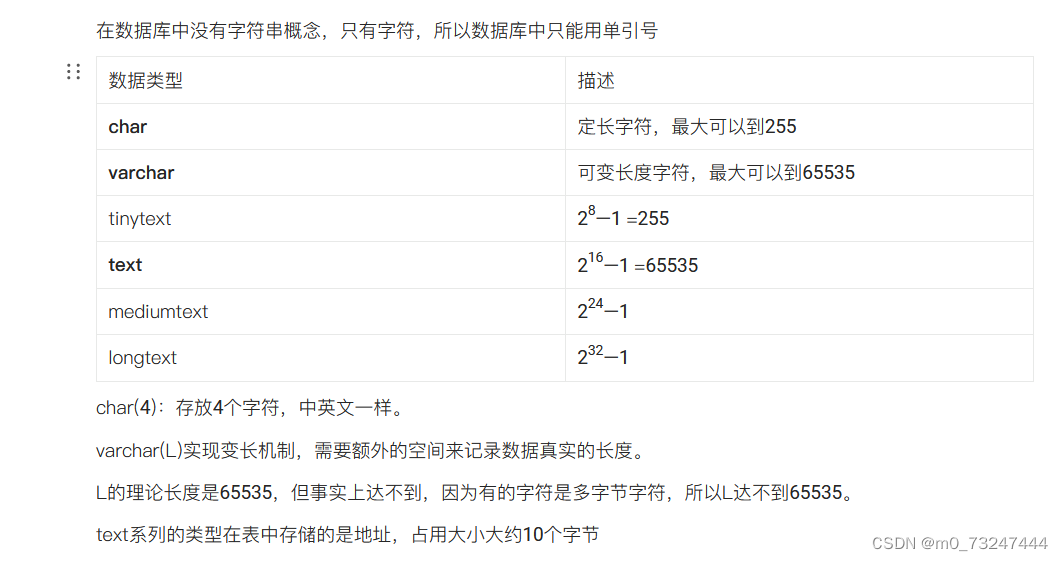
3.3枚举(enum)
从集合选择一个值作为数据(单选)
3.4日期时间型
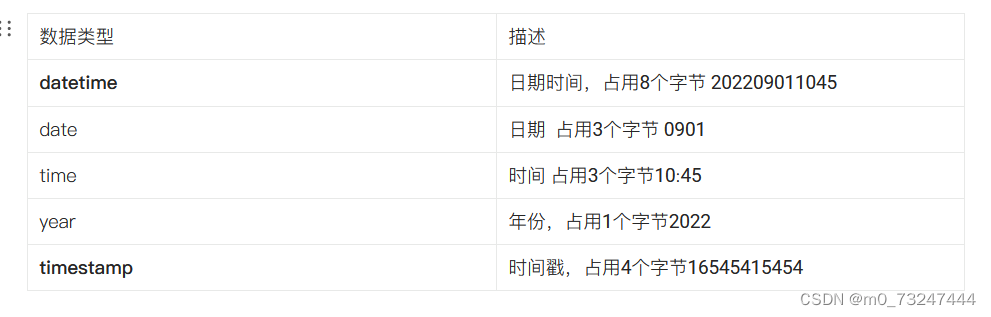 3.5练习题
3.5练习题

4.数据操作
4.1查询数据
select 列名 from 表名
-- 查询id字段的值
select id from stu;-- 查询id,stuname字段的值
select id,stuname from stu;、-- 查询所有字段的值
select * from stu;
4.2插入数据
语法:insert into 表名 values(值1,值2....)
-- 插入所有字段
insert into stu (id,stuname,sex,`add`) values (null,'tom','男','北京');-- 插入部分字段
insert into stu(stuname) values ('berry');-- 插入的字段和表的字段可以顺序不一致。但是插入字段名和插入的值一定要一一对应
insert into stu(sex,`add`,id,stuname) values ('女','上海',null,'ketty');-- 插入字段名可以省略
insert into stu values(null,'rose','女','重庆');1.插入字段名的数据和数据表中字段名的顺序可以不一致
2.插入值的个数,顺序必须和插入字段名的个数,顺序一致
3.如果插入的值的顺序和个数与表字段的顺序个数一致,插入字段可以省略
插入多条数据
insert into stu values ('xiaoming','男','四川'),('laowang','男','湖北');
4.3更新数据
语法 : update 表名 set 字段=值[where条件]
--将berry性别改为女
update stu set sex='女' where stuname='berry
--将编号是1号的学生性别改为女,地址改为上海
updata stu sex='女',add='上海'where id=1;
4.4删除数据
语法 :delete from 表名 where 条件
-- 删除1号学生
delete from stu where id=1;-- 删除名字是berry的学生
delete from stu where stuname='berry';-- 删除所有数据
delete from stu;
delete from 和truncate table的区别?
1、delete from 表:遍历表记录,一条一条的删除
2、truncate table:将原表销毁,再创建一个同结构的新表。就清空表而言,这种方法效率高。
删除分为物理删除(硬删除)和逻辑删除(软删除)
通过更新数据 来实现逻辑上的删除 实际上并未有删除
SELECT * from student where is_del = 0;
update student set is_del = 1 where id = 3;
4.5查询语句
语法:select [选项]列名[from表名][where条件][group by分组]
[order by排序][having条件][limit限制]
4.5.1字段表达式
-- 可以直接输出内容
select '锄禾日当午';
+------------+
| 锄禾日当午 |
+------------+
| 锄禾日当午 |
+------------+-- 表达式部分可以用函数
select rand();
+--------------------+
| rand() |
+--------------------+
| 0.6669325378415478 |
+--------------------+
1 row in set (0.00 sec)
通过as给字段取别名
mysql> select '锄禾日当午' as '标题'; -- 取别名
+------------+
| 标题 |
+------------+
| 锄禾日当午 |
+------------+
1 row in set (0.00 sec)-- 多学一招:as可以省略
mysql> select ch,math,ch+math '总分' from stu;
+------+------+------+
| ch | math | 总分 |
+------+------+------+
| 80 | NULL | NULL |
| 77 | 76 | 153 |
| 55 | 82 | 137 |
| NULL | 74 | NULL |
4.5.2 where 条件语句
where后面跟的是条件,在数据源中进行筛选。返回条件为真记录
MySQL支持的运算符
-- 比较运算符
> 大于
< 小于
>= 大于等于
<= 小于等于
= 等于
!= 不等于
-- 逻辑运算符
and 与
or 或
not 非
-- 其他
in | not in 字段的值在枚举范围内
between…and|not between…and 字段的值在数字范围内
is null | is not null 字段的值不为空
4.5.3 group by【分组查询】
将查询的结果分组,分组查询目的在于统计数据。
--查询男生和女生各自的平均分
select gender,avg(ch) from student GROUP BY gender
--查询男同学和女同学各有多少人
select gender, count(*) from student GROUP BY gender
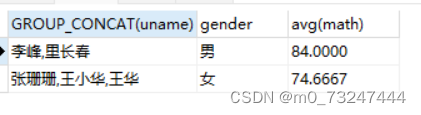
通过group_concat()函数将同一组的值连接起来显示
SELECT GROUP_CONCAT(uname),gender,avg(math) from student GROUP BY gender
多列分组
SELECT gender,address,avg(math) from student GROUP BY address,gender
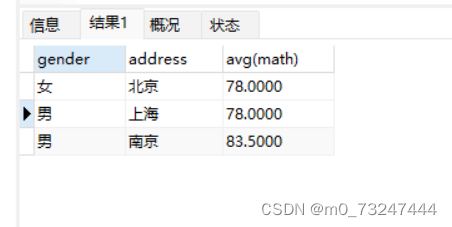
小结:
如果是分组查询,查询字段是分组字段和聚合函数
查询字段是普通函数字段,只取到第一个值
group_contact()将同一组的数据连接起来
4.5.4 having 条件
having :是在结果集上进行条件筛选
SELECT uname from student where gender='女'
SELECT uname from student having gender='女'
使用having报错 因为结果集中没有gender字段
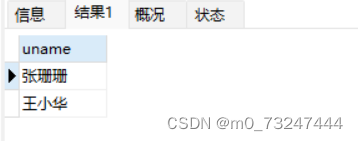
小结:having和where的区别
where 是对原始数据进行筛选的 having是对记录集进行筛选的
4.5.5 order by 排序
asc:升序【默认】
desc:降序
按照年龄排序
SELECT * from student ORDER BY age DESC
按照总分降序排序
select *,math+ch '总分' from student order by math+ch desc
如果年龄一样 按照ch降序排序
select * from student ORDER BY age,ch desc
4.5.6 limit
语法:limit【起始位置】,显示长度
--从第0个位置开始取,取3条记录
SELECT * from student limit 0,3
--从第2个位置开始取,取3条记录
SELECT * from student limit 2,3
起始位置可以省略 默认从0开始
--找出班级总分前3名
SELECT *,ch+math total from student order by(ch+math)desc limit 0,3
多学一招:limit 在update和delete语句也是可以使用的
--前3名语文加一分
UPDATE student set ch=ch+1 ORDER BY (ch+math) desc limit 3
--前3名删除
delete from student order by ch+math desc limit 3
4.5.7查询语句中的选项
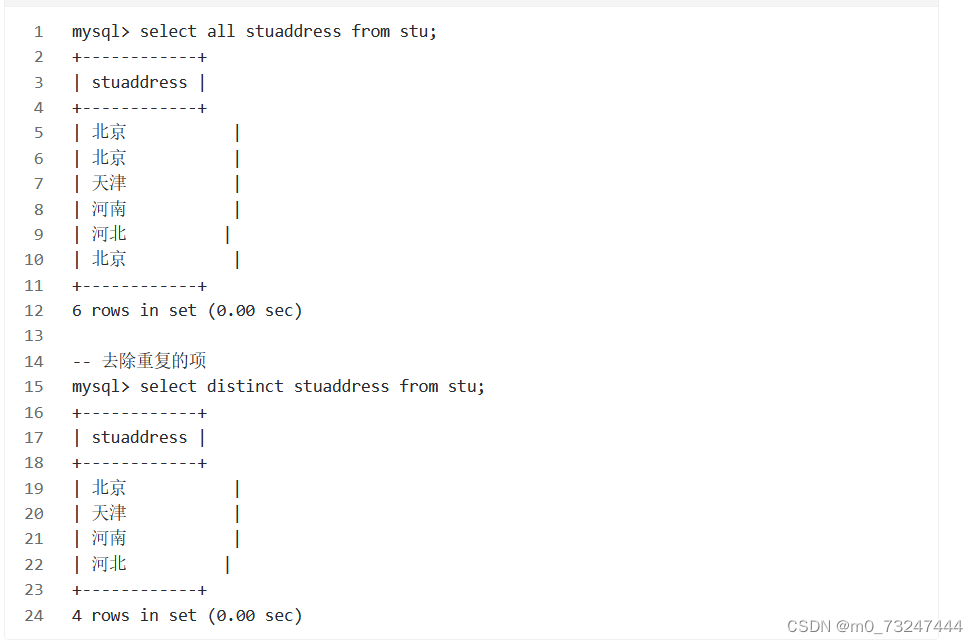
查询语句中的选项有两个
all:显示所有数据【默认】
distinct: 去除结果集中重复的数据
5.聚合函数
sum()求和
avg()求平均值
max()求最大值
min()求最小值
count()求记录数
子查询 就是把一个查询语句的结果,当初另外一个查询语句的条件
6.模糊查询
6.1通配符
- _[下划线]表示人一个字符
- %表示任意字符

6.2模糊查询(like)
模糊查询的条件不能用'=',要使用like

7.连表查询
7.1 left join左连接
select m.*,g.goodname gn from member m LEFT JOIN goods g on g.mid=m.id
7.2 right join右连接
select m.*,g.goodname gn from member m RIGHT JOIN goods g on g.mid=m.id
7.3inner join 内连接
select m.*,g.goodname gn from member m INNER JOIN goods g on g.mid=m.id















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









