







MySQL数据库的简单使用(基础篇)
学习说明
学习来源与:明日科技的《MySQL从入门到精通》
学习平台为Windows平台
MySQL命令说明:
MySQL命令和SQL Server命令一样,都是不区分大小写的,这里统一采用了小写形式,更方便阅读
文章划分
考虑到一篇文章太长了,分成了几篇文章来分别书写各部分内容,本部分内容为基础知识,为简单语句的使用
后半部分内容(存储过程、触发器、事务、索引、数据库备份、数据库安全性、数据库优化等)
点击跳转
三级模式的理解
三级模式指的是:模式、外模式、内模式
模式:(即空白表的结构,一个数据库只有一个模式)
数据的逻辑结构(数据项的名字、类型、取值范围等)
数据之间的联系
数据有关的安全性、完整性要求
外模式:(表建好了,拿去给应用程序用,添加了数据)
对于同一个模式下出来的表,不同外模式下,表会不一样,所以一个模式可以对应多个外模式
内模式:(一个数据库只有一个内模式)
是数据物理结构和存储方式的描述
是数据在数据库内部的表示方式,包括:
记录的存储方式(顺序、聚簇)
索引的组织方式( B+树、HASH索引)
数据是否压缩存储
数据是否加密
数据存储记录结构的规定—如定长/不定长、记录是否跨页存放等
二级映像
外模式/模式映像:
当模式改变时,DBA对外模式/模式映像作相应改变,使外模式保持不变;
应用程序是依据外模式编写的,应用程序不必修改,保证了数据与程序的逻辑独立性,简称数据的逻辑独立性
模式/内模式映像:
当数据库的存储结构改变了,DBA修改模式/内模式 映像,使模式保持不变;
模式不变,则应用程序不变,保证了数据与程序的 物理独立性,简称数据的物理独立性
独立性:
物理独立性
指用户的应用程序与存储在磁盘上的数据库中数据是相互独立的。当数据的物理存储改变了,应用程序不用改变
逻辑独立性
指用户的应用程序与数据库的逻辑结构是相互独立的。数据的逻辑结构改变了,用户程序也可以不变
安装及配置MySQL
安装 MySQL zip版本(即解压即可使用,不用安装程序),可以参考另一篇文章
https://blog.csdn.net/qq_59001784/article/details/124664127
安装MySQL,有很多版本,一般根据msi程序(即安装程序)直接下一步即可,再配置一下环境变量即可使用
下载链接:
链接:https://pan.baidu.com/s/1anTG-xLuGPkFxdqiZZVJyg
提取码:0925
安装教程在网上很多的,基本上按照下一步走即可
为了方便使用,一般都会再安装一个图形化界面,直接安装Navicat就行
下载链接:
链接:https://pan.baidu.com/s/1-VdbyZOu1Y8NEWbH7KveiQ
提取码:0925
-
环境变量的配置十分简单(比Java还简单,只需要加一下路径,即可在任意位置打开MySQL命令
在环境变量的path路径下加上文件目录即可 C:\software\mysql-5.6.24-winx64\bin //找到你们自己放的位置

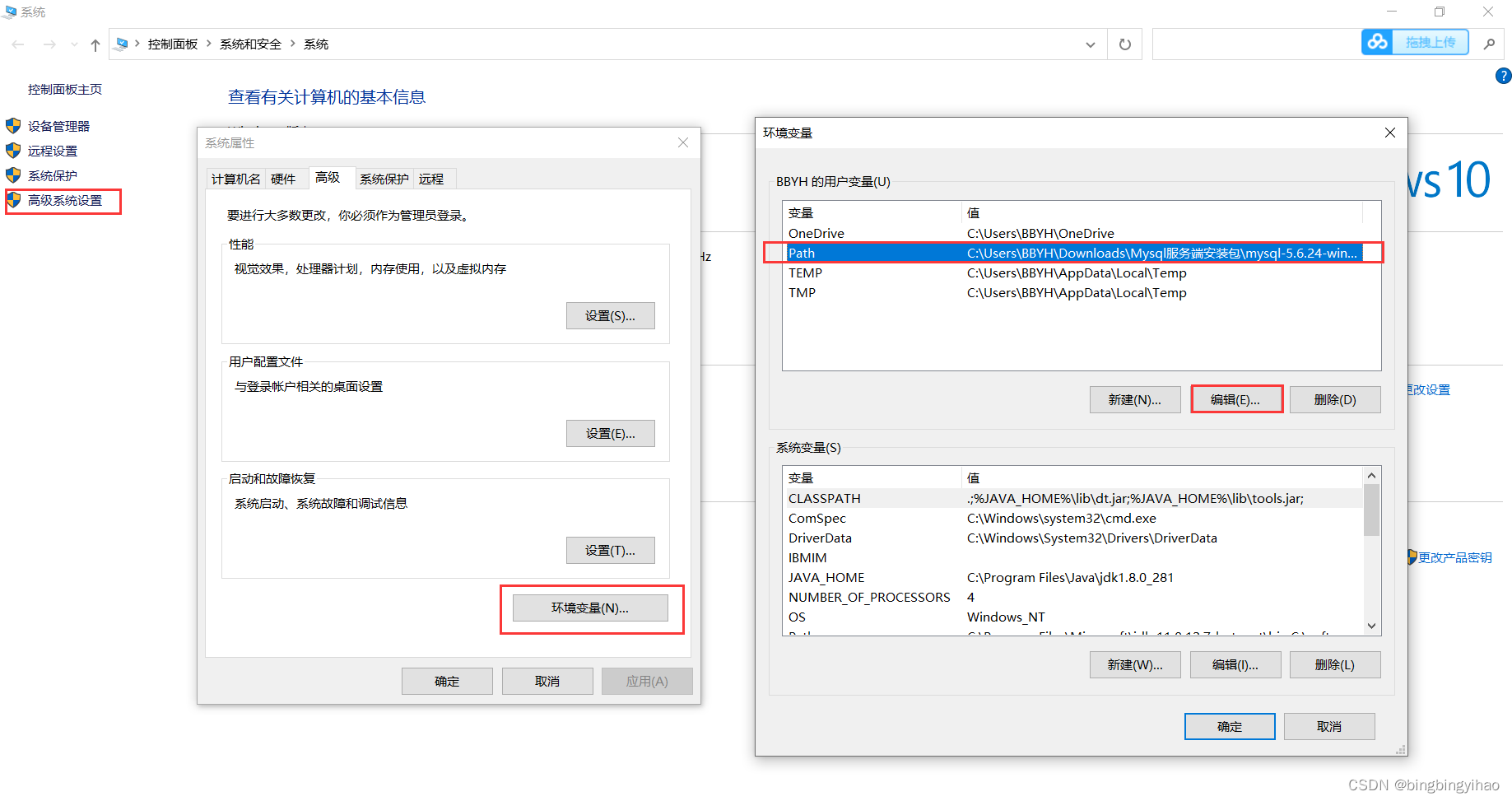
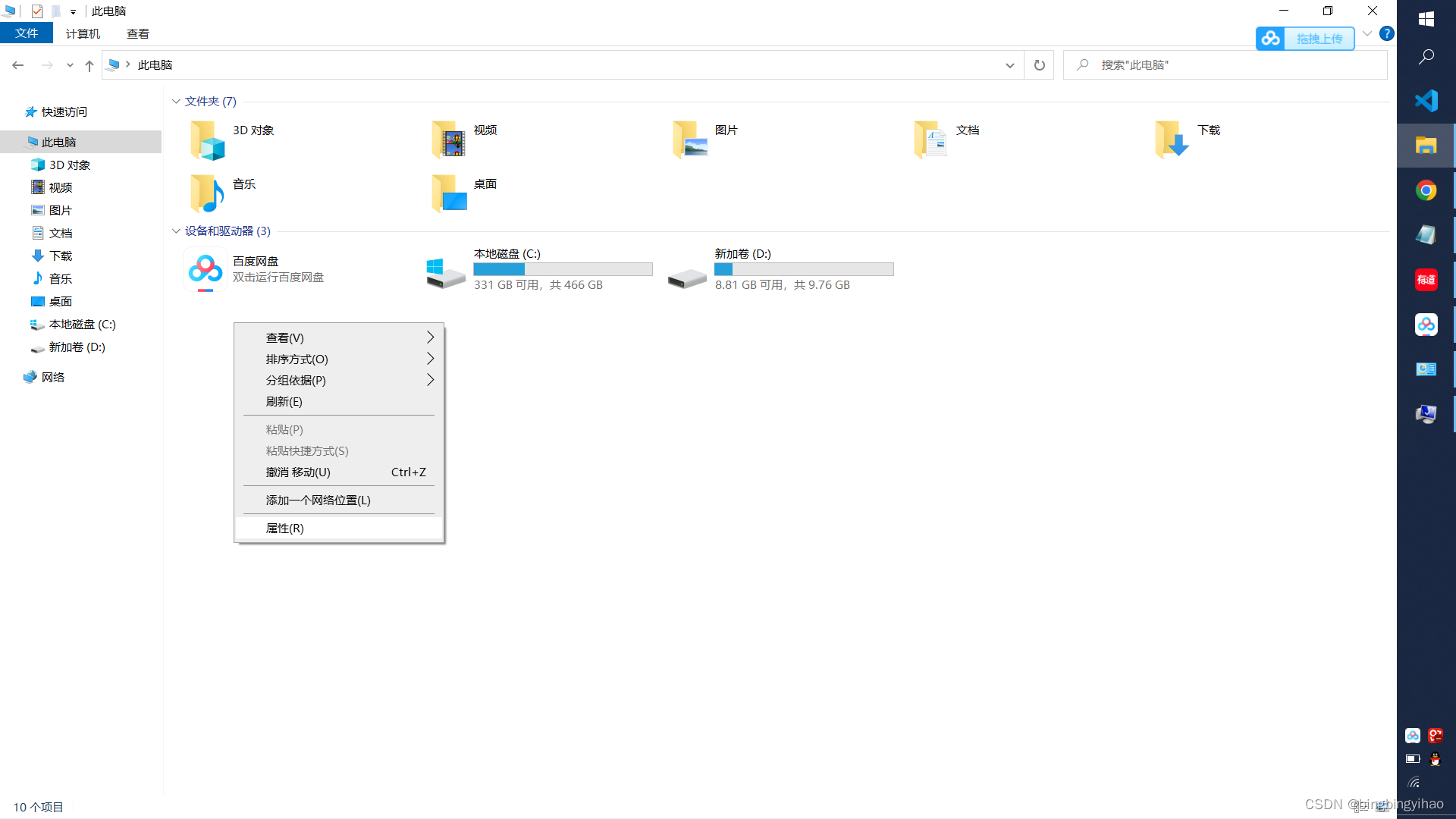
找到和打开环境变量设置的地方非常的简单:在此电脑目录下(即可以看到C盘、D盘的那个页面),点击右键选择属性即可,找到高级系统设置
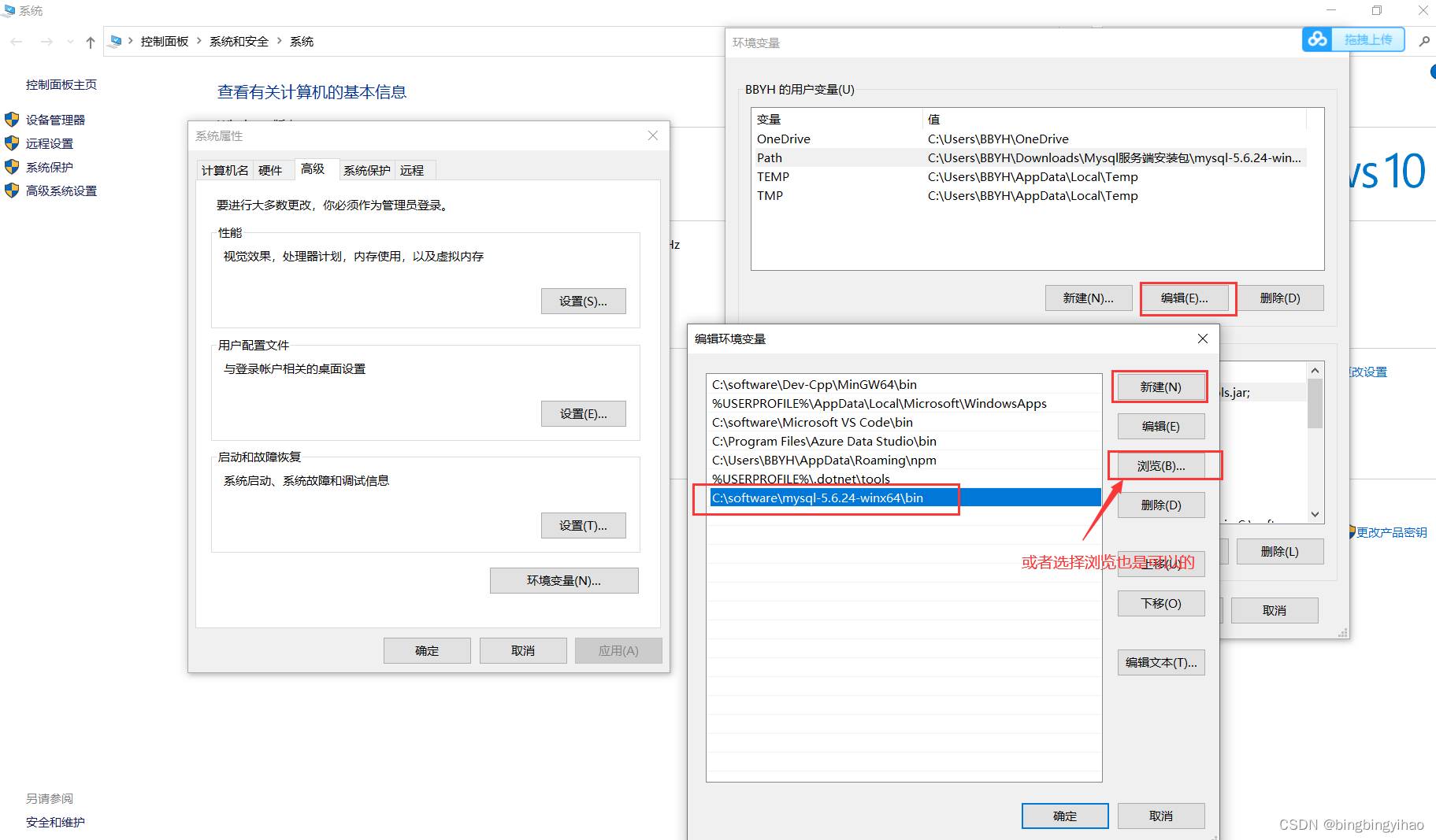
编辑,然后新建一个,直接将目录复制进去即可
然后一个个都确定,然后就可以发现mysql命令可以在任意目录下用了
-
原本是这样的
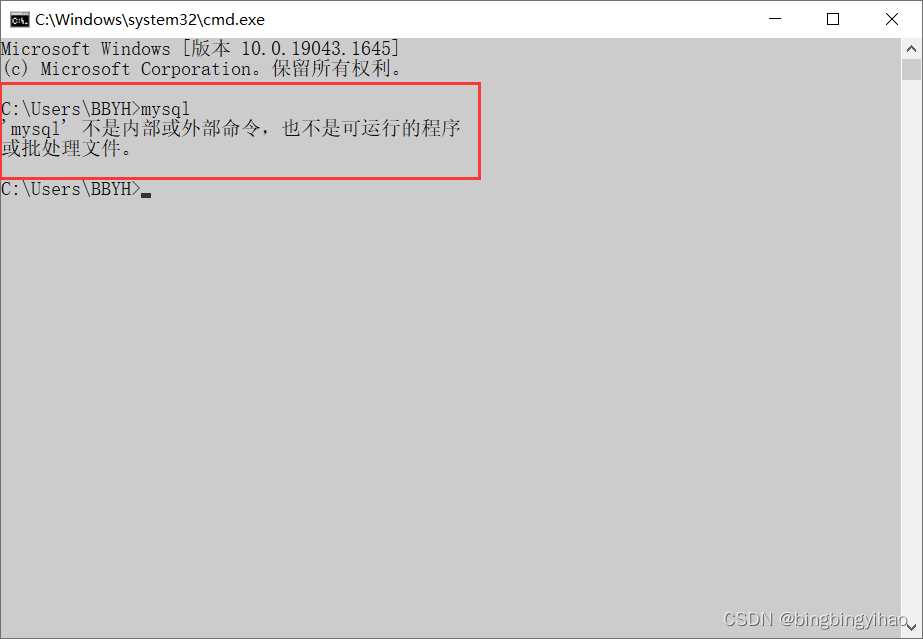
-
设置环境变量后(记得再次打开新的命令行窗口)(权限不够,提示你需要输入密码才能登录)
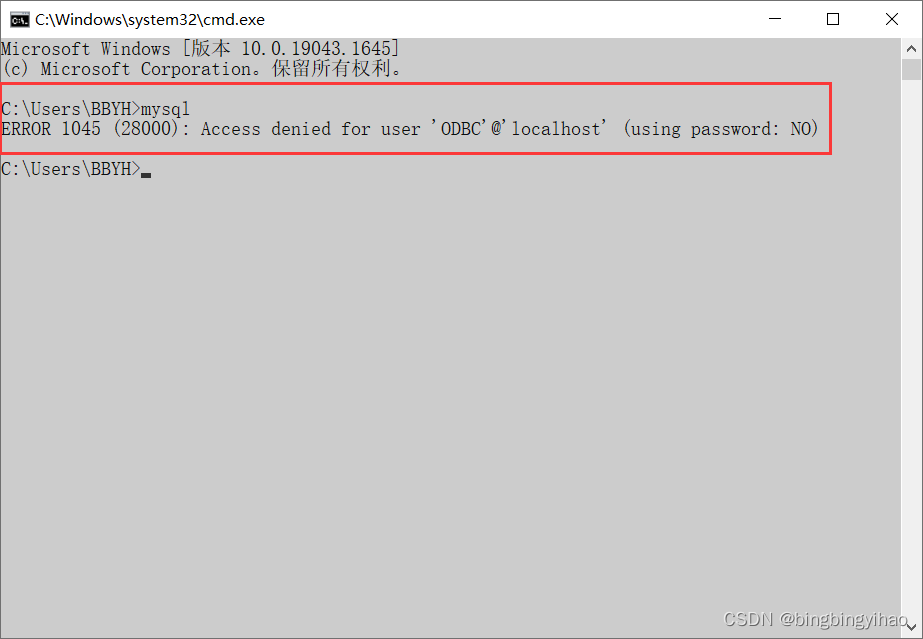
登录MySQL(Windows下)
如果设置了密码的话,则需要输入密码,没有设置密码的话,则不用输入
方法一:
直接使用:mysql -uroot -p(密码) //输入完按回车即可直接登录
方法二:
使用:mysql -uroot -p //输入完会弹出输入密码的一行,输入密码后可登录
注释:这个mysql -u root -p 是可以分开的,不用连在一起
如果是本机的话则 -h localhost 是默认的,不用输入,也可以选择IP进行输入
mysql -u root -h 127.0.0.1 -p
一般连接远程服务器则会使用IP进行连接
数据库操作
创建数据库:
create database if not exists test_db;
简洁形式:create database test_db;
查看数据库:
show databases like '%db%';
简洁形式:show databases;
删除数据库:
drop database if exists test_db;
简洁形式:drop database test_db;
数据库引擎
查看系统支持的数据库引擎:
show engines;
查看数据库引擎
show variables like '%storage_engine%';
各数据库引擎之间的区别(主要看常用的InnoDB、MyISAM、MEMORY)
MySQL执行外部的.sql文件
两种方式(相较来说第二种方式更为简洁)
直接在控制台未登录情况:(需要配置环境变量)(sql文件的位置会不同,可以自己修改,一般推荐不带中文,经测试,有中文也是没问题的)
注意:符合 "<" 不能写成 ">" ,不然会报错的,执行出错(自己的密码自己修改一下)
书写时,不能多空格,不能再句尾加分号
mysql -u root -p0925 < D:/test.sql //这样会显示说直接输入密码会被看到,安全性不高,所以可以采用下面这种方式
mysql -u root -p < D:/test.sql //输入完后按回车,会提示你要输入密码(当然如果有密码的话),这样安全性会高一些
已登录到MySQL内部
mysql -u root -p 登录之后,在MySQL的控制台下输入以下命令即可,这时是不需要输入密码的
source D:/test.sql;
test.sql文件内容如下
use test_db;
create table test_table(
id int auto_increment primary key
); -- 记住分号不能少,不然则会执行出错,MySQL是以分号作为语句结束的标识的,与SQL Server不同,没有分号,语句则无法执行
数据表的操作
查看表结构:(以下三个语句功能基本一致,当然最后一句更为简洁)
show columns from test_table;
describe test_table;
desc test_table;
创建表格:(需要先使用(选择)数据库,后续操作才更为简便)
use test_db;
create table if not exists test_table (
id int auto_increment primary key
);
简洁形式:
create table test_table (
id int auto_increment primary key
);
增加表格字段及修改字段类型:(增加新字段 username 及修改 ID 字段数据类型,修改类型后,
就自动将原本的自增性质删除了,猜测是因为char类型不能够进行数值计算)
alter table test_table add username varchar(10) not null, modify ID char(10);
更改字段名称:(将字段 username 改为 newUserName )
alter table test_table change column username newUserName varchar(20) not null;
删除字段:(删除 newUserName 字段)
alter table test_table drop newUserName;
修改表格名称:(两种方式)
alter table test_table rename as table_one;
rename table table_one to table_bbyh;
复制表格:(由一个表格直接创建新的一个表格,结构与原表格一样)
create table table_bbeh like table_bbyh; //只能创建结构,数据不会复制过去
create table table_bbsh as select * from table_bbyh; //会同时将数据复制过去
删除表格:
drop table if exists table_bbeh;
简洁形式:drop table table_bbeh;
支持的运算符
算术运算符:(括号内代表效果是一样的,书写形式不一样)
+
-
*
/(DIV):如果除数为 0 了,则计算结果为空值(NULL),写SQL语句的时候要注意
%(MOD)
比较运算符:(会在后续例子中用到一些运算符,MySQL里面的运算符使用和其他编程类语言很类似)
大多返回布尔值(符合则为1,不符合则为0)
=
>
<
>=
<=
!=(<>)
is null
is not null
between and
in
not in
like
not like
regexp //正则表达式的简单使用,与一般的JS正则表达式语法类似,可以看这篇文章
https://www.runoob.com/mysql/mysql-regexp.html
或者这篇:https://blog.csdn.net/qq_59001784/article/details/124664315
示例如下:(只演示了一些比较抽象的,其余常用的没有都演示)
注释:这里采用变量的方式进行演示,就没有采用 select 语句选择数据表中的内容了
(MySQL里面声明(定义)变量的方式还有通过declare的方式)
select 2+3;
select 1/2;
select 2/0;
select 20%6;
set @x = 8;
select @x between 2 and 10;
select @x in(1,2,3,4);
set @str = 'hello';
select @str regexp 'el';
set @str = 'hello el elo lo';
select @str regexp 'lo$';
select @str regexp '^hello';
select @str regexp 'o{1,2}';
逻辑运算符(与一般语言的逻辑运算符不同,因为有NULL值的存在)
运算规则如下:
&&(AND):所有数据不为0且不为空则返回1,存在0则返回0,不存在0存在NULL则返回NULL
||(OR):存在非0的数字则返回1,存在NULL则返回NULL,两个都为0则返回0
!(NOT):一元操作,原数据为非0数字则返回0,原数据为0则返回1,原数据为NULL则返回NULL
XOR:存在NULL则返回NULL,两个数都为0或都为非0的数则返回0,一个数为0,一个数为非0的数则返回1
示例如下:
-- &&运算
select 2 && 3;
select 0 && 3;
select 0 && NULL;
select NULL && 3;
select null && 3;
select NULL && NULL;
-- ||运算
select 4 || 3;
select 0 || 2;
select NULL || 2;
select NULL || NULL;
select NULL || 0;
select 0 || 0;
-- !运算
select !0;
select !2;
select !NULL;
-- XOR运算
select NULL XOR 3;
select NULL XOR NULL;
select NULL XOR 0;
select 1 XOR 3;
select 0 XOR 0;
select 1 XOR 0;
MySQL中函数及存储过程的基本格式代码
注意:函数和存储过程的参数需要用反引号 "`" 进行包裹,据说是MySQL的转义字符,不包裹则会报错
-- 函数的定义(创建)
CREATE DEFINER = CURRENT_USER FUNCTION TestFunc(`@x` integer)
RETURNS integer
BEGIN
#Routine body goes here... -- 这里面的内容为自己修改
CASE @x
WHEN 20 THEN
return 1;
WHEN 30 THEN
return 2;
ELSE
return 0;
END CASE;
END;
-- 存储过程的定义(创建)
create procedure TestPro(in `@x` INTEGER)
begin
#Routine body goes here... -- 这里面的内容为自己修改
CASE @x
WHEN 10 THEN
select 1 as result;
WHEN 20 THEN
select 2 as result;
ELSE
select 0 as result;
END CASE;
end
-- 函数的使用(需要注意的是要先对参数进行赋值,这里并不同别的语言一样是进行参数传值,
-- 和SQL Server也不一样,MySQL需要直接对参数进行赋值)
set @x = 2;
SELECT TestFunc(@x);
-- 函数的删除
drop function TestFunc;
-- 存储过程的使用
set @x = 1;
CALL TestPro(@x);
-- 存储过程的删除
drop PROCEDURE TestPro;
MySQL常用语句的使用(以及函数的定义与使用)
包括以下语句:(一般都用于函数和存储过程内)
if:介绍了三种使用形式,表达式、iFNULL、流程控制语句
case
while
loop
repeat
IF语句部分
if语句的使用:(MySQL里面有三种使用方式)
表达式:
IF(expr1,expr2,expr3),类似三元表达式,expr1为判断条件,成立则返回expr2,不成立则返回expr3
ifnull:
IFNULL(expr1,expr2),此时expr1为判断条件,expr1不为空则返回expr1,expr1为空则返回expr2
作为流程控制语句:(只能用在函数或存储过程中,当然在触发器里面也是可以用的)(这个当然最为复杂)
示例如下:
- 表达式的使用:(比较简单的,一般会结合变量使用)
set @x=10; -- 定义(赋值)一个变量
SELECT IF(@x%3=1,1,0) as result;
- IFNULL的使用:(一般这个会用在筛选条件时,为空则代表没有符合的条件,这里就用简单的表达式代替一下)
set @x=10;
select IFNULL((@x && NULL),3) as result;
set @x=10;
select IFNULL((@x || NULL),3) as result2;
- 作为流程控制语句:(这个最为复杂了,只能用在函数和存储过程中,所以这里简单讲解一下MySQL里面的函数和存储过程)(以下试验均在 Navicat 下进行,可能在Linux下会有不同的情况)
函数的定义:
函数的定义在Navicat里面是可以通过图形化界面得到一些提示的,
以下为示例代码,包括参数的使用(注意函数的参数,需要使用反引号进行包裹,不然会报错)
CREATE DEFINER = CURRENT_USER FUNCTION `TestFunc`(`@x` integer)
RETURNS integer
BEGIN
#Routine body goes here...
IF (@x>10) THEN
RETURN 1;
ELSE
RETURN 0;
END IF;
END;
函数的使用:
通过下面代码进行使用(需要注意的是直接使用 SELECT TestFunc(20); 是不会将参数传进去的)
需要先对参数进行赋值,这里已经不像是传值了,更像是修改参数的值
set @x = 2;
SELECT TestFunc(@x);
函数的删除:
直接采用 drop 语句即可删除:drop function TestFunc;
- 函数中使用if语句:(例子比较简陋,且是结合基本的表达式语句作为使用,肯定在用到查询语句之类更为复杂的SQL语句时会遇到新的问题,但这里也只做为讲解 if 语句的引导)
-- 创建函数
CREATE DEFINER = CURRENT_USER FUNCTION `TestFunc`(`@x` integer)
RETURNS integer
BEGIN
#Routine body goes here...
IF (@x>10) THEN
RETURN 1;
ELSE
RETURN 0;
END IF;
END;
-- 使用函数
set @x = 1;
select TestFunc(@x) as result;
set @x = 20;
select TestFunc(@x) as result;
-- 附注:创建函数时用到select语句的结果作为返回值时,需要先将结果赋值给变量,不然也会报错
-- 示例如下:(select语句的执行结果总感觉不能直接使用,应该也确实如此,算得上是一张表格了,但赋值却又可以,就很奇怪)
CREATE DEFINER = CURRENT_USER FUNCTION `TestFunc`(`@x` INTEGER)
RETURNS integer
BEGIN
#Routine body goes here...
set @result = (SELECT ID from test_table WHERE ID = @x);
RETURN @result;
END;
- 存储过程中 if 语句的使用(这里同样需要对参数进行反引号的包裹,然后在使用存储过程时,也需要先对参数进行赋值,不然则无法传值)
-- 存储过程的定义
create procedure TestPro(in `@x` INTEGER)
begin
select ID from test_table where ID = @x;
end
-- 存储过程的使用
set @x = 1;
CALL TestPro(@x);
-- 删除存储过程
DROP PROCEDURE TestPro;
-- 存储过程中 if 语句的使用如下:
create procedure TestPro(in `@x` INTEGER)
begin
IF (@x > 10) THEN
select 1 as result;
ELSE
select 0 as result;
END IF;
end
set @x = 2;
CALL TestPro(@x);
set @x = 20;
CALL TestPro(@x);
DROP PROCEDURE TestPro;
Case语句部分
Case语句,也是用在函数和存储过程中较多,有两种形式:
CASE case_value
WHEN when_value THEN
statement_list
ELSE
statement_list
END CASE;
CASE WHEN when_value THEN
statement_list
ELSE
statement_list
END CASE;
示例如下:
- 函数下Case语句的使用(就只写第一种用法吧,第二种用法我都不知道该咋用,很奇怪呀)
-- 创建函数
CREATE DEFINER = CURRENT_USER FUNCTION `TestFunc`(`@x` integer)
RETURNS integer
BEGIN
#Routine body goes here...
CASE @x
WHEN 20 THEN
return 1;
WHEN 30 THEN
return 2;
ELSE
return 0;
END CASE;
END;
-- 使用函数
set @x = 10;
select TestFunc(@x) as result;
set @x = 20;
select TestFunc(@x) as result;
set @x = 30;
select TestFunc(@x) as result;
-- 删除函数
drop FUNCTION TestFunc;
- 存储过程下的Case语句
-- 创建存储过程
create procedure TestPro(in `@x` INTEGER)
begin
CASE @x
WHEN 10 THEN
select 1 as result;
WHEN 20 THEN
select 2 as result;
ELSE
select 0 as result;
END CASE;
end
-- 删除存储过程
DROP PROCEDURE TestPro;
-- 使用存储过程
set @x = 20;
CALL TestPro(@x);
set @x = 10;
CALL TestPro(@x);
set @x = 1;
CALL TestPro(@x);
While语句部分
形式非常的简单,且只有一种形式:(都用于函数和存储过程内)
WHILE search_condition DO
statement_list
END WHILE;
示例如下:
- 函数中While语句的使用(这里写一个函数计算最简单的等差数列的前n项和)
CREATE DEFINER = CURRENT_USER FUNCTION TestFunc(`@x` integer)
RETURNS integer
BEGIN
#Routine body goes here...
set @result = 0;
WHILE @x > 0 DO
set @result = @result + @x; -- 需要注意的是每次赋值均需要使用set运算进行
set @x = @x - 1;
END WHILE;
return @result;
END;
drop function TestFunc;
set @x = 3;
SELECT TestFunc(@x);
set @x = 10;
SELECT TestFunc(@x);
- 存储过程中While的使用(和函数的功能一致,都是计算前n项和)
create procedure TestPro(in `@x` INTEGER)
begin
#Routine body goes here...
set @result = 0;
WHILE @x > 0 DO
set @result = @result + @x;
set @x = @x - 1;
END WHILE;
select @result as result;
end
drop PROCEDURE TestPro;
set @x = 3;
CALL TestPro(@x);
LOOP语句部分
LOOP语句,用于循环,一般和 if 语句共同使用,用在函数或存储过程中
基本格式:
label: LOOP
statement_list
IF exit_condition THEN
LEAVE label;
END IF;
END LOOP label; //这个地方的label表示可以省略,直接使用 END LOOP; 也行
- 函数中loop语句的使用(同样编写最简单的求前n项和)
CREATE DEFINER = CURRENT_USER FUNCTION TestFunc(`@x` integer)
RETURNS integer
BEGIN
set @result = 0;
#Routine body goes here...
testLoop: LOOP
set @result = @result + @x;
set @x = @x - 1;
IF @x = 0 THEN
LEAVE testLoop;
END IF;
END LOOP;
return @result;
END;
set @x = 10;
SELECT TestFunc(@x);
set @x = 3;
SELECT TestFunc(@x);
drop function TestFunc;
- 存储过程中loop的使用
create procedure TestPro(in `@x` INTEGER)
begin
#Routine body goes here...
set @result = 0;
testloop: LOOP
set @result = @result + @x;
set @x = @x - 1;
IF @x = 0 THEN
LEAVE testloop;
END IF;
END LOOP;
select @result as result;
end
set @x = 8;
CALL TestPro(@x);
drop PROCEDURE TestPro;
Repeat语句部分
基本的循环语句(形式较为简单)
格式如下:
REPEAT
statement_list
UNTIL search_condition END REPEAT;
示例如下:(都一样的哈,就写一个函数里面的就是了)
CREATE DEFINER = CURRENT_USER FUNCTION TestFunc(`@x` integer)
RETURNS integer
BEGIN
#Routine body goes here...
set @result = 0;
REPEAT
set @result = @result + @x;
set @x = @x - 1;
UNTIL @x = 0 END REPEAT;
return @result;
END;
set @x = 20;
SELECT TestFunc(@x);
drop function TestFunc;
MySQL增、删、改语句的介绍
MySQL的insert、update、delete语句和SQL Server区别不大,基本用法是一致的,这也是我们一般用得比较多的了
查看具体语句语法格式可以看这篇:https://blog.csdn.net/bingbingyihao/article/details/124463014
进行比对一番SQL Server的区别(它们的区别更多在于其他用法,这个通用的SQL语句基本的数据库都是一致的)
以下直接结合实例讲解:(需要先创建表格)
- insert语句格式
-- 创建表格语句
create table test_bbyh(
ID int auto_increment PRIMARY key,
username VARCHAR(10),
password VARCHAR(10)
)
-- 插入完整记录的数据
insert into test_bbyh values('1','BBYH','1234');
-- 插入几个字段(不完整的记录,当然也可以全部字段都加上,推荐这种写法,更加灵活)
insert into test_bbyh(ID, username) values('2','BBEH');
-- 插入时,如果设置了自动增加的字段,是可以不添加那个字段的,我们一般都采用这种方式,选择自增字段,防止主键冲突
insert into test_bbyh(username, password) values('BBYH','1234');
- update语句格式
-- 更新对应记录(一般通过主键进行定位,如果没有加上where限制,则全部都更新)
update test_bbyh set username = 'BBWH' where ID = '1';
-- 全部更新
update test_bbyh set username = 'BBQH';
- delete语句格式
-- 删除对应记录(一般通过逐渐进行定位,如果没有where限制则直接删除表格中的全部记录了)
delete from test_bbyh where ID = '2';
-- 删除整表(当然需要加一些数据,让结果更明显一些)
-- 添加数据部分(多添加几条)
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
-- 删除进行
delete from test_bbyh;
-- 会发现再次执行以下语句,进行插入数据时,自增主键的值并不会从 1 开始增加,而是沿着之前的值继续增加
insert into test_bbyh(username, password) values('BBYH','1234');
- truncate语句和delete语句的区别(前者会重置自增主键的值,后者则不会重置自增主键的值)
-- 添加一些记录(在上面创建的表格基础上进行操作)
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
-- 使用 delete from test_bbyh; 进行删除,会发现再次添加时主键没有被重置
delete from test_bbyh;
-- 添加一些记录(在上面创建的表格基础上进行操作)
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
-- 这次采用 truncate table test_bbyh; 进行清空表格,再次添加记录发现主键自增值被重置了
truncate table test_bbyh;
-- 添加一些记录(在上面创建的表格基础上进行操作)
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBYH','1234');
查询语句(select)的简单介绍
基本语句格式如下:
一般 having 结合 group by 一起使用
select * from test_bbyh
where ID > 4
group by username
-- 这里本来应该有 order by ID 的,但是我加上去它就报错,很奇怪
having ID < 10
limit 3;
常用查询句式:(下面只列举一些深入一些的用法,常用的字段查询都不容易忘记)
in
between-and
like
distinct
group by
单表查询
单表查询比较简单,可以结合之前的运算符进行使用
示例如下:(需要先创建表格和添加数据,就用之前的那个表格好了,再加点数据)
-- 创建表格
create table test_bbyh(
ID int auto_increment PRIMARY key,
username VARCHAR(10),
password VARCHAR(10)
)
-- 添加数据
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBEH','2345');
insert into test_bbyh(username, password) values('BBSH','3456');
insert into test_bbyh(username, password) values('BBWH','4567');
insert into test_bbyh(username, password) values('BBLH','0987');
insert into test_bbyh(username, password) values('1234','1234');
insert into test_bbyh(username, password) values('2345','2345');
insert into test_bbyh(username, password) values('BBSH','3456');
insert into test_bbyh(username, password) values('BBWH','4567');
insert into test_bbyh(username, password) values('BBLH','0987');
-- 进行查询
-- 带关键词 in 的查询
select * from test_bbyh where ID in(1, 2, 3, 4)
-- 使用 between and 的范围查询(可以发现是闭区间,两边端点都包括在内)
select * from test_bbyh where ID between 2 and 4;
-- 使用 like 的模糊查询(一般会使用 % 和 _ 进行匹配,%表示任意长度的字符串,_表示长度为一的任意字符串)
select * from test_bbyh where password like '%2%';
select * from test_bbyh where username like 'BB_H';
-- 使用 distinct 去除重复行
select distinct username from test_bbyh;
-- 如果想了解 distinct 去除重复的原理,需要改一下表格, distinct 只会去除完全一样的两行,所以有主键约束就看不出来了,表格改为如下:
-- 创建表格
create table test_bbyh(
ID int,
username VARCHAR(10),
password VARCHAR(10)
)
-- 添加数据
insert into test_bbyh(username, password) values('BBYH','1234');
insert into test_bbyh(username, password) values('BBEH','2345');
insert into test_bbyh(username, password) values('BBSH','3456');
insert into test_bbyh(username, password) values('BBWH','4567');
insert into test_bbyh(username, password) values('BBLH','0987');
insert into test_bbyh(username, password) values('1234','1234');
insert into test_bbyh(username, password) values('2345','2345');
insert into test_bbyh(username, password) values('BBSH','3456');
insert into test_bbyh(username, password) values('BBWH','4567');
insert into test_bbyh(username, password) values('BBLH','0987');
-- 使用 distinct 去除重复行,可以发现只会去除完全一致的两行
select distinct * from test_bbyh;
select distinct password, username from test_bbyh;
-- 使用 group by 进行分组
-- 单个字段(会有类似去除重复的效果,但肯定不一样,只是按照某个字段进行分组,去重复)
select * from test_bbyh group by username;
-- 多个字段进行分组(在后面写即可,只是这里的数据看不出来啥变化,因为通过第一个分组就已经分好了)
select * from test_bbyh group by username, ID, password;
select * from test_bbyh group by ID, password; -- 这个分组就很奇怪,而通过两个字段却记录还有很多,说明分组的底层原理不是一层层执行的
select * from test_bbyh group by ID; -- 通过一个字段进行分组时只剩下一条记录
聚合函数的介绍
下面列举一些常用的聚合函数,共有五个:(一般大写形式更好看)
count:计算记录行数
sum:求和
avg:求平均值
max:返回最大值
min:返回最小值
示例如下:(一般都是用于查询时候,用于筛选字段的)(用上面创建的表演示)
对于非int类型的字段进行数字计算时,如不能转化,则值默认为0,并不是所有的字母在这五个聚合函数中都不能转化
经测试发现,sum、avg函数计算时对单字母的字符串是不会转化的,而max和min则会一同比较了(下面细说具体的比较方式)
-- count 的使用
select *, count(*) as number from test_bbyh group by ID;
-- sum 的使用
-- (这里不太规范,一般都是对int类型的字段进行求和,这里对varchar类型的字段求和时,因为都是数字,所以可以自动转化,没有报错)
select *, sum(password) as number from test_bbyh group by ID;
-- avg的使用:
-- (同样不规范,也是需要对int或者数字类型字段进行操作的,这里自动转化了,如果是不能够转化为数字的,则该行的值默认为0,即没有值,但行数会被计算在内)
select avg(password) from test_bbyh;
-- max、min的使用
-- 它们的比较方法为字典排序,挨个字符比较,采用转化为ASCII码之后进行比较(指的是单个字符转化为ASCII码)
-- 但对于都是数字或者字母,这样的方式也能够比出大小(如果既有字母又有数字,则字母的ASCII码更大,于是比较则会出现问题)
select max(password) as result from test_bbyh;
select min(password) as result from test_bbyh;
连接查询
连接查询分为内连接和外连接:(和关系代数里面的自然连接与等值连接很类似,但不一样在,这里要求属性名称一致,和自然连接更像)
- 内连接介绍(需要创建表格,添加数据进行介绍)
-- 创建表格(选择非常经典的学生表与课程表进行演示)
create table test_one(
student_id varchar(10),
name varchar(10)
);
create table test_two(
course_id varchar(10),
student_id varchar(10),
course_name varchar(10)
);
-- 添加数据
insert into test_one values('001', 'BBYH');
insert into test_one values('002', 'BBEH');
insert into test_one values('003', 'BBSH');
insert into test_one values('005', 'BBWH');
insert into test_two values('c01', '001', 'C语言');
insert into test_two values('c02', '001', 'D语言');
insert into test_two values('c03', '001', 'E语言');
insert into test_two values('c04', '001', 'F语言');
insert into test_two values('c01', '002', 'C语言');
insert into test_two values('c02', '002', 'D语言');
insert into test_two values('c03', '002', 'E语言');
insert into test_two values('c04', '002', 'F语言');
insert into test_two values('c01', '003', 'C语言');
insert into test_two values('c02', '004', 'D语言');
insert into test_two values('c03', '003', 'E语言');
insert into test_two values('c04', '004', 'F语言');
-- 进行连接(即将两张表形成(汇总成)一张表,得到学生的选课信息)
select * from test_one, test_two where test_one.student_id = test_two.student_id;
-- 与如下语句效果是一致的
select * from test_one JOIN test_two on test_one.student_id = test_two.student_id;
- 外连接的介绍(包括左外、右外和全连接三种)(仍选用之前的学生和课程表格,但数据需要修改一下,方便观察结果)
-- 添加数据(在此之前用delete from test_one 来清空原来的记录)
insert into test_one values('001', 'BBYH');
insert into test_one values('002', 'BBEH');
insert into test_one values('005', 'BBWH');
insert into test_two values('c01', '001', 'C语言');
insert into test_two(student_id) values('001');
insert into test_two values('c01', '002', 'C语言');
insert into test_two(student_id) values('002');
insert into test_two values('c01', '003', 'C语言');
insert into test_two(student_id) values('003');
insert into test_two values('c02', '004', 'D语言');
insert into test_two values('c03', '003', 'E语言');
insert into test_two values('c04', '004', 'F语言');
-- 左外连接
select * from test_one LEFT JOIN test_two on test_one.student_id = test_two.student_id;
-- 右外连接(只与左外连接相差一个单词)
select * from test_one RIGHT JOIN test_two on test_one.student_id = test_two.student_id;
-- 全连接(由于MySQL不支持FULL JOIN,所以采用UNION进行代替)
select * from test_one LEFT JOIN test_two on test_one.student_id = test_two.student_id
UNION
select * from test_one RIGHT JOIN test_two on test_one.student_id = test_two.student_id;
子查询
子查询常分为以下几种情况:
in
比较运算符
exists:内层查询不返回查询记录,而是返回一个布尔值,为真则进行外层查询,为假则不进行外层查询
(内层查询到的结果如果存在记录,即记录行数至少一行,则为真,不存在记录则为假)
any:符合条件的任一个,即等价于数学上的 "存在"
all:全部条件都要符合,即等价于数学上的 "任意"
示例如下:(这边采用前面的学生和课程表格进行演示)
-- in 子查询
select * from test_two WHERE student_id in(select student_id from test_one);
-- 比较运算符子查询
select * from test_two WHERE student_id > (select MIN(student_id) from test_one);
select * from test_two WHERE student_id != (select student_id from test_one); -- 返回结果需要是一行,即一个结果,所以这里会报错
select * from test_two WHERE student_id != (select MIN(student_id) from test_one);
-- exists子查询
select * from test_two WHERE EXISTS (select student_id from test_one);
select * from test_two WHERE EXISTS (select student_id from test_one where student_id = '007');
select * from test_two WHERE EXISTS (select student_id from test_one where student_id = '001');
-- any子查询
select * from test_two WHERE student_id > ANY(select student_id from test_one);
-- all子查询
select * from test_one WHERE student_id > ALL(select student_id from test_two);
以上介绍了MySQL的基本语句的使用,后续会介绍更高级的用法。
之前内容中提到的函数和存储过程,在后面也会再次进行详细介绍
编写时间:2022-05-05
为表和字段取别名
取别名非常简单
表格则跟在后面写即可
字段则采用 as 进行修饰
示例如下:
-- 创建测试表格
create table test_rename(
ID int,
username VARCHAR(10)
)
-- 取别名
select ID as test_id, username as name from test_rename test;
-- 表格取别名这样容易观察些
insert into test_rename values('001','BBYH');
insert into test_rename values('002','BBEH');
select ID , username from test_rename test where test.username = 'BBYH';
使用正则表达式进行
这里面正则表达式的用法和JS很像,可以参考这篇文章了解一下常用正则表达式的结构
https://blog.csdn.net/qq_59001784/article/details/124664315
使用示例如下
-- 创建测试表格
create table test_rename(
ID int,
username VARCHAR(10)
)
-- 插入一些数据
insert into test_rename values('001','BBYH');
insert into test_rename values('002','BBEH');
-- 使用正则表达式
select * from test_rename where username regexp 'Y+';
select * from test_rename where username regexp 'Y*';
select * from test_rename where username regexp 'B{1,3}';
select * from test_rename where username regexp 'B{1}';
select * from test_rename where username regexp 'B{3}';














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









