







一、UDF(User Defined Function:用户定义函数)
Hive本身内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,同时也支持用户扩展UDF 函数来完成内置函数无法实现的操作。 官网API
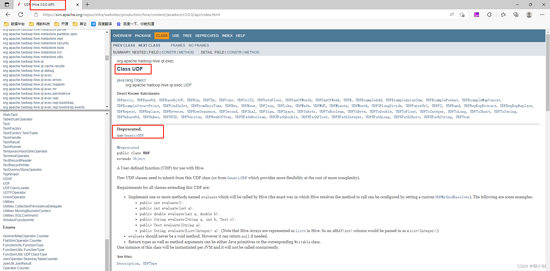
1.1、继承UDF函数
继承UDF类,实现简单,只需要重写evaluate方法(该方法必须返回String类型)读取和返回基本类型,但是在hive3.0版本中,已不建议使用该类,推荐使用 GenericUDF
1.1.1、pom.xml 引入hive执行包
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.0</version> </dependency>
1.1.2、MaskUDF 实现掩码函数
3.0开始已不建议使用:
源码:
package com.renxiaozhao.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.metadata.HiveException;
/**
* 掩码函数.
* @author rxz 20220808
*
*/
@SuppressWarnings("deprecation")
public class MaskUDF extends UDF {
private static final int MASK_LEFT = 0;//掩码从左至右标识
private static final int MASK_RIGHT = -1;//掩码从右至左标识
/**
* 掩码处理.
* @param input 掩码输入参数
* @param startIndex 掩码从左至右标识:0-掩码从左至右;-1-掩码从右至左;其他则按位截取,比如2-从第三位开始截取
* @param subIndex 掩码位数
* @return
* @throws HiveException
*/
public String evaluate(String input,Integer startIndex,Integer subIndex) throws HiveException {
//掩码处理
String append = "";
if (startIndex == MASK_LEFT || startIndex == MASK_RIGHT) {
for (int i = 0;i < subIndex;i++) {
append += "*";
}
} else {
for (int i = 0;i < (subIndex - startIndex);i++) {
append += "*";
}
}
if (startIndex == MASK_LEFT) {
return append + input.substring(subIndex);
} else if (startIndex == MASK_RIGHT) {
return input.substring(0, input.length() - subIndex) + append;
} else {
return input.substring(0,startIndex) + append + input.substring(subIndex);
}
}
//测试
public static void main(String[] args) {
String input = "18866866888";
String append = "";
for (int i = 0;i < (6 - 4);i++) {
append += "*";
}
System.out.println(input.substring(0,4) + append + input.substring(6));
}
}
1.1.3、打包放到hive环境
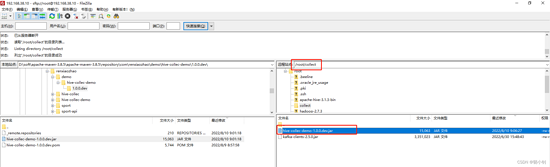
hive-env.sh配置jar包路径
将jar包放到 HIVE_AUX_JARS_PATH 对应的目录下(不再需要单独执行add jar …),重启hive
export HIVE_AUX_JARS_PATH=/root/collect
1.1.4、创建临时函数测试
create temporary function mask_udf as "com.renxiaozhao.udf.MaskUDF";
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9942
9942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









