







series结构
Series 结构,也称 Series 序列,是 Pandas 常用的数据结构之一,它是一种类似于-维数组的结构,由一组数据值(value)和组标签组成,其中标签与数据值具有对应关系。
标签不必是唯一的,但必须是可哈希类型。该对象既支持基于整数的索引,也支持基于标签的索引,并提供了许多方法来执行涉及索引的操作。ndarray的统计方法已被覆盖,以自动排除缺失的数据 目前表示为NaN)
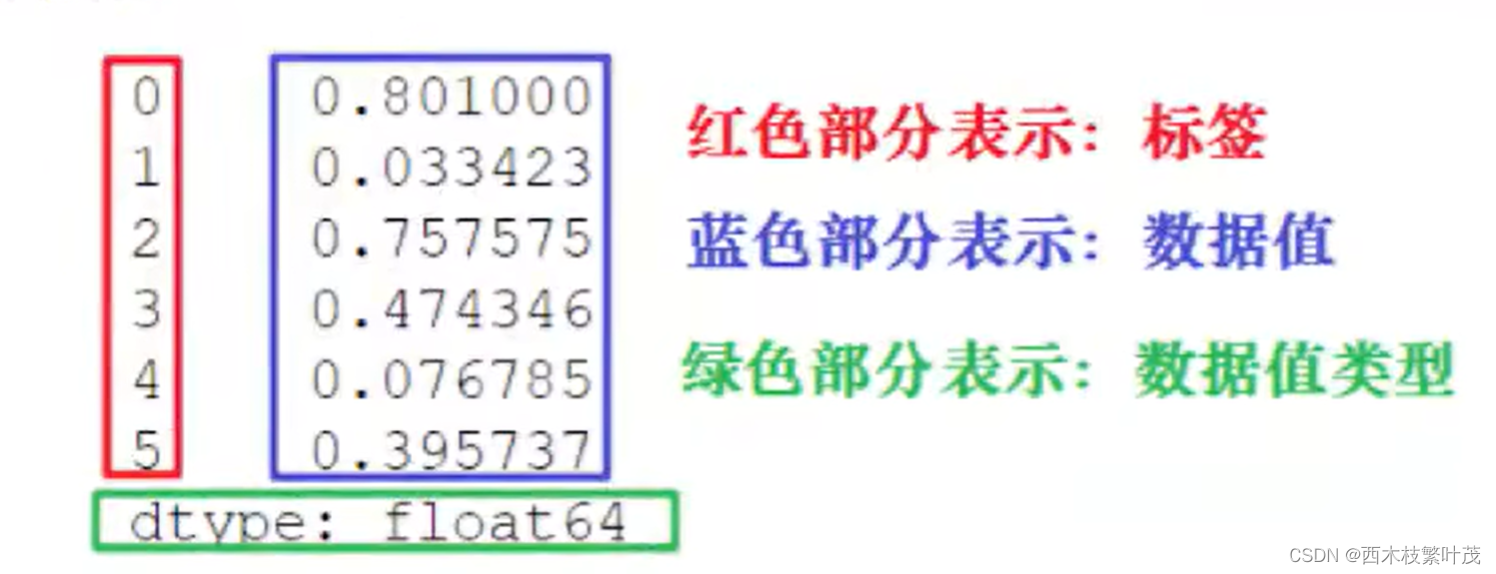
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Pyhon 对象等,它的标签默认为整数,从0开始依次递增。Series的结构图,如下所示:
创建
列表作为数据源创建Series
#列表作为数据源创建Series
import numpy as np
import pandas as pd #导入pandas 起个别名pd
ar_list = [3,10,3,4,5]
print(type(ar_list))
s1 = pd.Series(ar_list)
print(s1)
print(type(s1))

数组作为数据源
np_rand = np.arange(1,6)
s1 = pd.Series(np_rand)
s1

通过索引来取得对应的值
s1.index
结果是RangeIndex(start=0, stop=5, step=1) 代表开始,结束和步长
也可以转化为列表进行输出
list(s1.index)
[0, 1, 2, 3, 4] 输出的是索引值
s1[1] 结果是2
也可以通过索引更改值
s1[2]=50
s1

注意
举个例子 输出s1[-1],此时就会报错,这个是先找索引值的
但是如果按下面这样写的话就不会报错
s1[-1]=20
print(s1)

这样就直接把s1[-1]加进去了














 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









