







 本文介绍了如何通过特定软件将微信读书中的书籍下载到电脑,包括扫码登录、添加至书架、下载HTML格式文件并转换为PDF的过程,强调资源仅限学习和测试使用,非商业用途。
本文介绍了如何通过特定软件将微信读书中的书籍下载到电脑,包括扫码登录、添加至书架、下载HTML格式文件并转换为PDF的过程,强调资源仅限学习和测试使用,非商业用途。
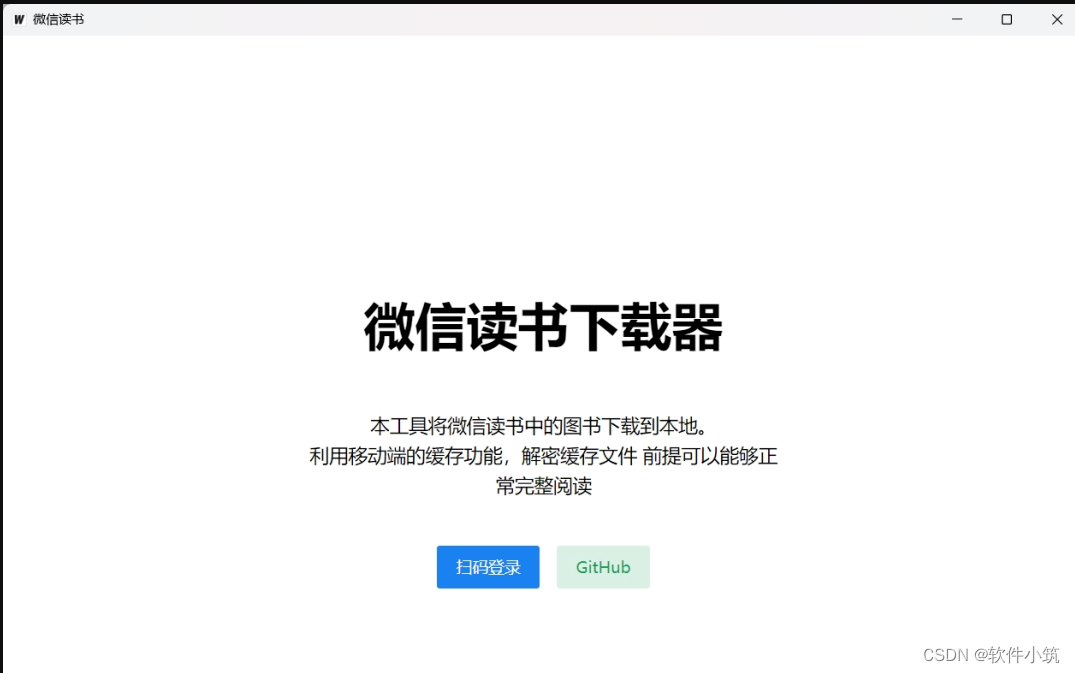
这个软件可将微信读书中的图书下载到电脑
需要进行扫码登录,使用微信或者微信读书扫码
微信读书在书架菜单栏,右上角点+加号。然后点网页版,去扫码登
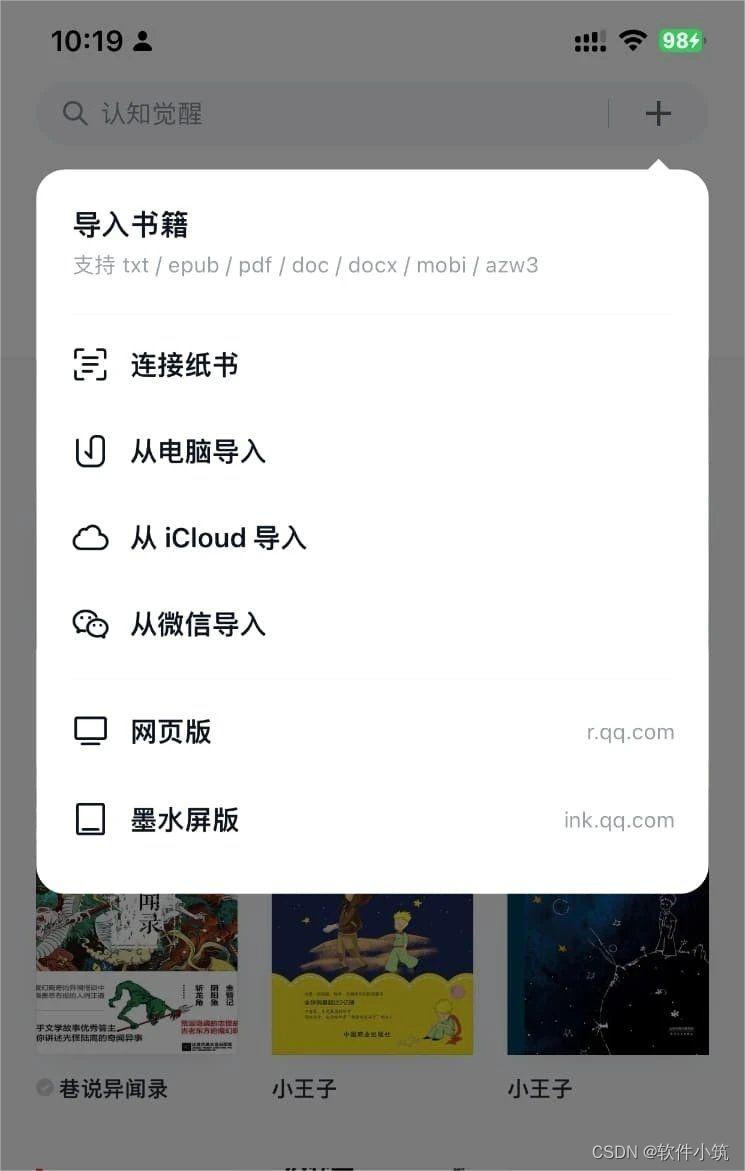
如果您微信读书书架里没有书,那下载不了,需要提前把书加入书架
加入书架后,点击那本书,弹出的对话框点击下载即可
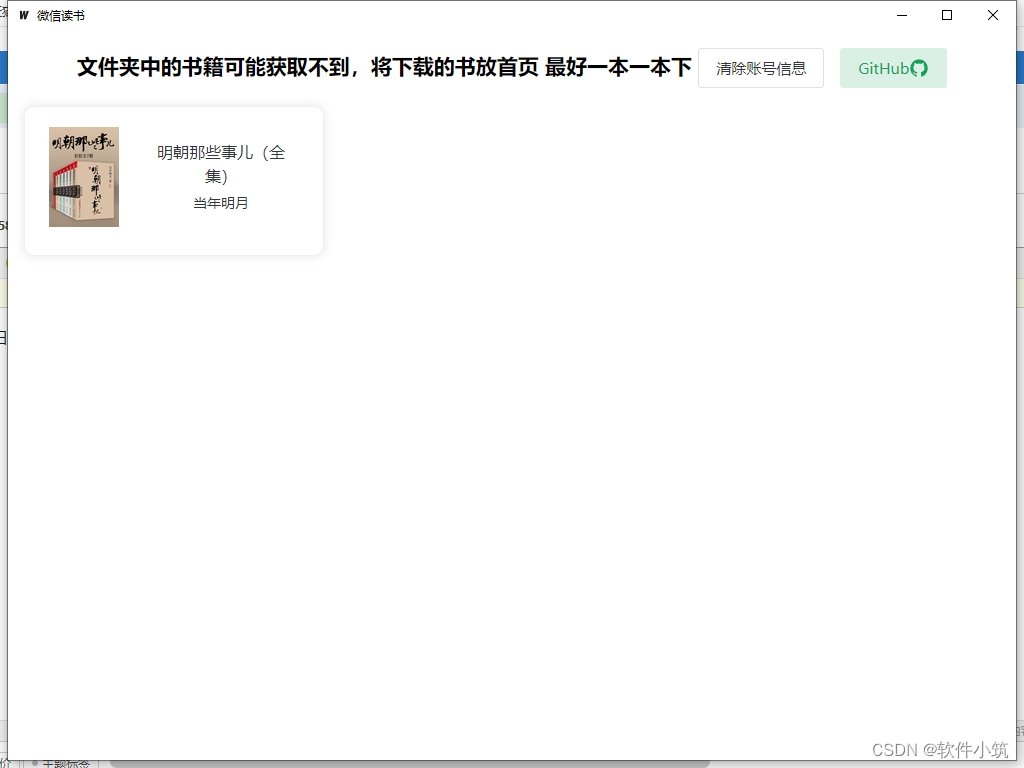
下载完成后提示这个
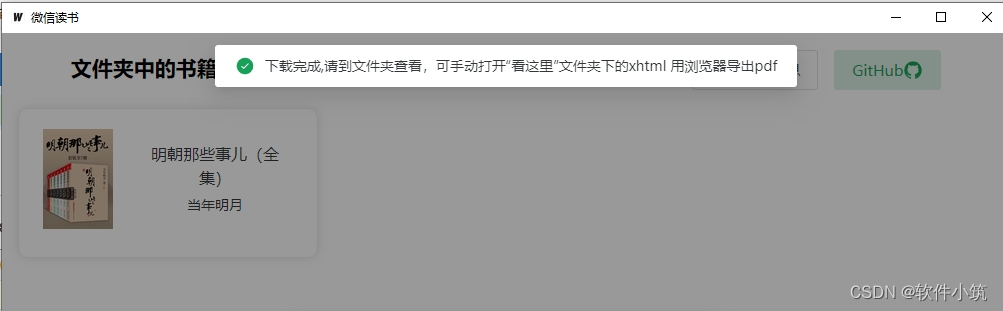
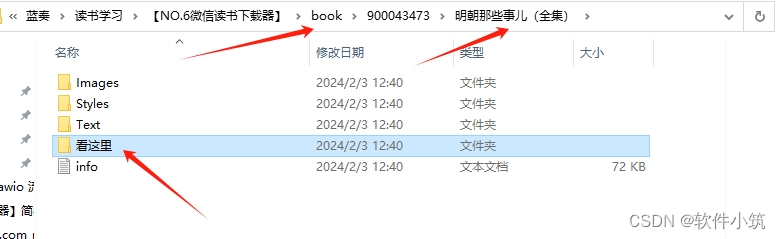
然后在软件同目录的文件夹有个book文件夹,书籍就在这

然后点击书籍名文件夹的“看这里”文件夹,下载的书是HTML格式的,就在这
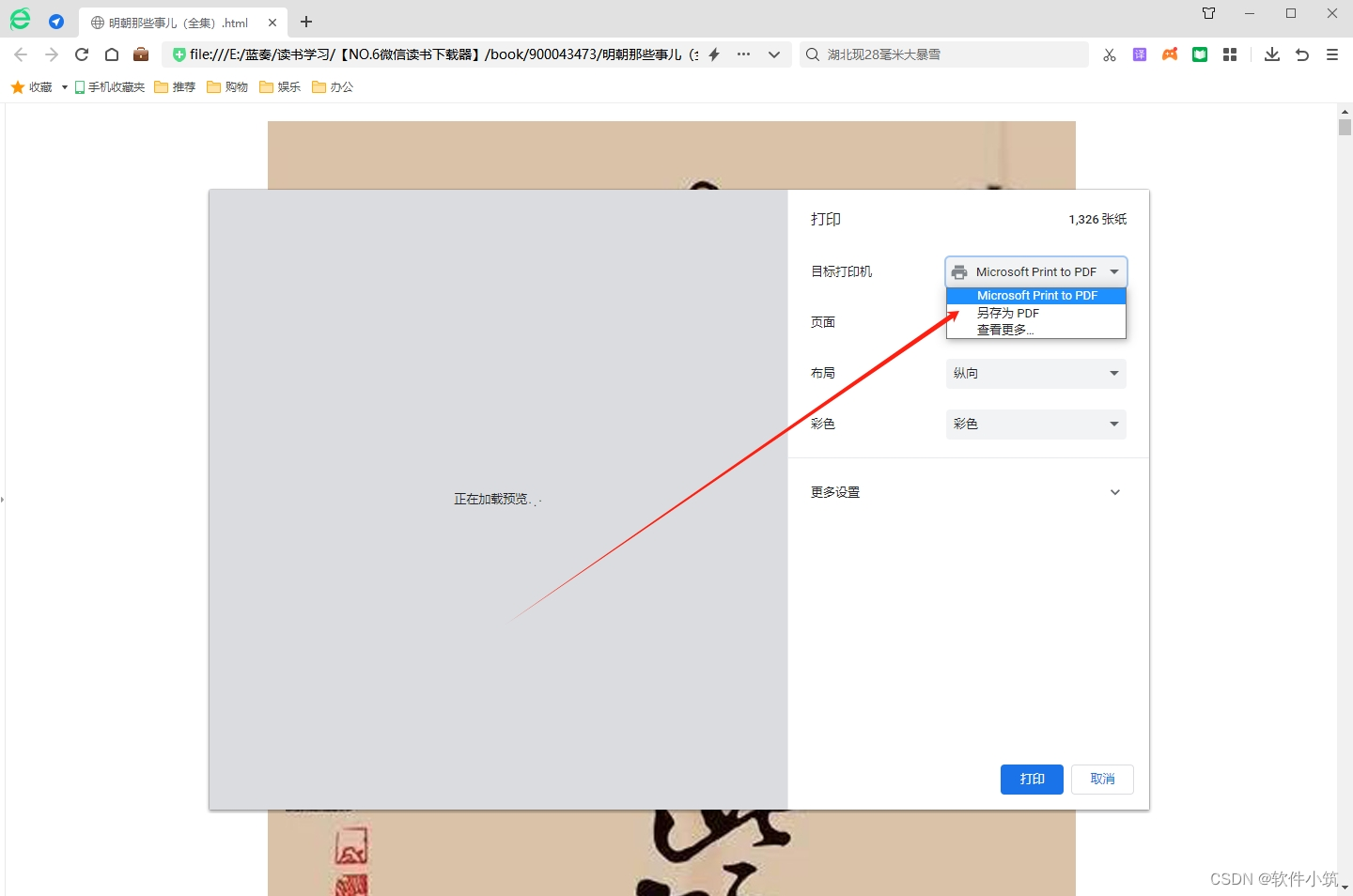
浏览器打开HTML文件,右击页面,点击打印,弹出的页面,目标打印机选择另存为PDF,就可以查看pdf格式的电子书了,
当然也可以找个HTML转pdf软件,转换下
下载的前提是可以能够正常完整阅读
资源来源于网络,免费分享仅供学习和测试使用,请勿用于商业用途,如有侵权请联系删除!
下载地址:点击查看


















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











